Master the use of Spark advanced operators in code

Similarity analysis
What the three functions have in common is the Transformation operator. Lazy operator.
Difference analysis
The map function processes data one by one, that is, the input parameters of map must contain one piece of data and other parameters you need to pass.
The mapPartitions function processes partition data together. In other words, the input of the mapPartitions function is an "iterator" composed of all the data of a partition. Then the function can process them one by one, and then output all the results according to the iterator. It can also be used in combination with yield for better results.
RDD's mapPartitions is a variant of map, both of which can perform parallel processing of partitions.
The main difference between the two is the different granularity of the call: the input transformation function of map is applied to each element in the RDD, while the input function of mapPartitions is applied to each partition.
The mapPartitionsWithIndex function is actually not much different from the mapPartitions function, because the mapPartitionsWithIndex function is called behind mapPartitions, but one parameter is closed. The function mapPartitionsWithIndex can get the partition index number;
Suppose an RDD has 10 elements, divided into 3 partitions. If you use the map method, the input function in the map will be called 10 times; if you use the mapPartitions method, its input function will be called only 3 times, once for each partition.
mapPartitionsWithIndex operates with partition subscripts.
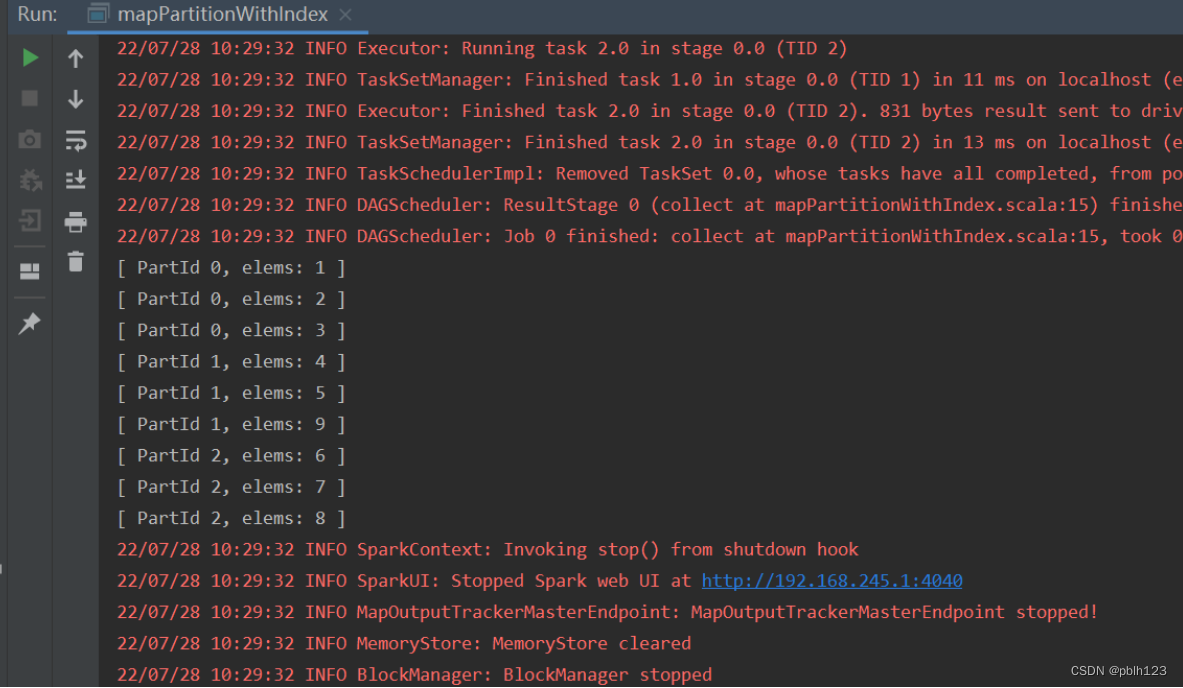
1、mapPartitionWithIndex
import org.apache.spark.{SparkConf,SparkContext}
object mapPartitionWithIndex {
def getPartInfo:(Int,Iterator[Int]) => Iterator[String] = (index:Int,iter:Iterator[Int]) =>{
iter.map(x =>"[ PartId " + index +", elems: " + x + " ]")
}
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("RddMapPartitionsWithIndexDemo")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(List(1,2,3,4,5,9,6,7,8),numSlices =3 )
val rdd2 = rdd1.mapPartitionsWithIndex(getPartInfo)
rdd2.collect().foreach(println)
}
}
2、aggregate
First we create an RDD
scala> val rdd1 = sc.parallelize(1 to 5)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[4] at parallelize at <console>:24
scala> rdd1.collect
warning: there was one feature warning; re-run with -feature for details
res24: Array[Int] = Array(1, 2, 3, 4, 5)
This RDD has only 1 shard, containing 5 pieces of data: 1, 2, 3, 4, 5.
Then let's apply the aggregate method.
Before using aggregate, we should first define two functions to be used as input parameters for aggregate.
scala>
// Entering paste mode (ctrl-D to finish)
def pfun1(p1: Int, p2: Int): Int = {
p1 * p2
}
// Exiting paste mode, now interpreting.
pfun1: (p1: Int, p2: Int)Int
scala>
scala>
// Entering paste mode (ctrl-D to finish)
def pfun2(p3: Int, p4: Int): Int = {
p3 + p4
}
// Exiting paste mode, now interpreting.
pfun2: (p3: Int, p4: Int)Int
scala>
Then comes the second function. No more explanation.
Then we can finally start applying our aggregate method.
scala> rdd1.aggregate(3)(pfun1, pfun2)
res25: Int = 363
scala>
The output is 363 ! How is this result calculated?
First, our zeroValue, the initial value, is 3 . Then through the introduction in the above section, we know that the pfun1 function will be applied first . Because our RDD has only one shard, there will only be one pfun1 function call in the entire operation process. Its calculation process is as follows:
First, use the initial value 3 as the parameter p1 of pfun1, and then use the first value in the RDD, that is, 1, as the parameter p2 of pfun1. From this we can get the first calculated value as 3 * 1 = 3 . Then the result 3 is passed in as the p1 parameter, and the second value in the RDD, 2, is passed in as p2, and the second calculation result is 3 * 2 = 6 . By analogy, after the entire pfun1 function is executed, the result obtained is 3 * 1 * 2 * 3 * 4 * 5 = 360 . The application process of pfun1 is a bit like "sliding calculation in RDD".
After the first parameter function pfun1 of the aggregate method is executed, we get the result value 360. Therefore, at this time, the execution of the second parameter function pfun2 will begin.
The execution process of pfun2 is similar to that of pfun1. ZeroValue is also passed in as the parameter of the first operation. Here, zeroValue, which is 3, is passed in as the p3 parameter, and then the result 360 of pfun1 is passed in as the p4 parameter. , the calculated result is 363. Because pfun1 has only one result value, the entire aggregate process is calculated, and the final result value is 363 .
import org.apache.spark.{SparkConf, SparkContext}
object RddAggregateDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("RddDemos")
val sc = new SparkContext(conf)
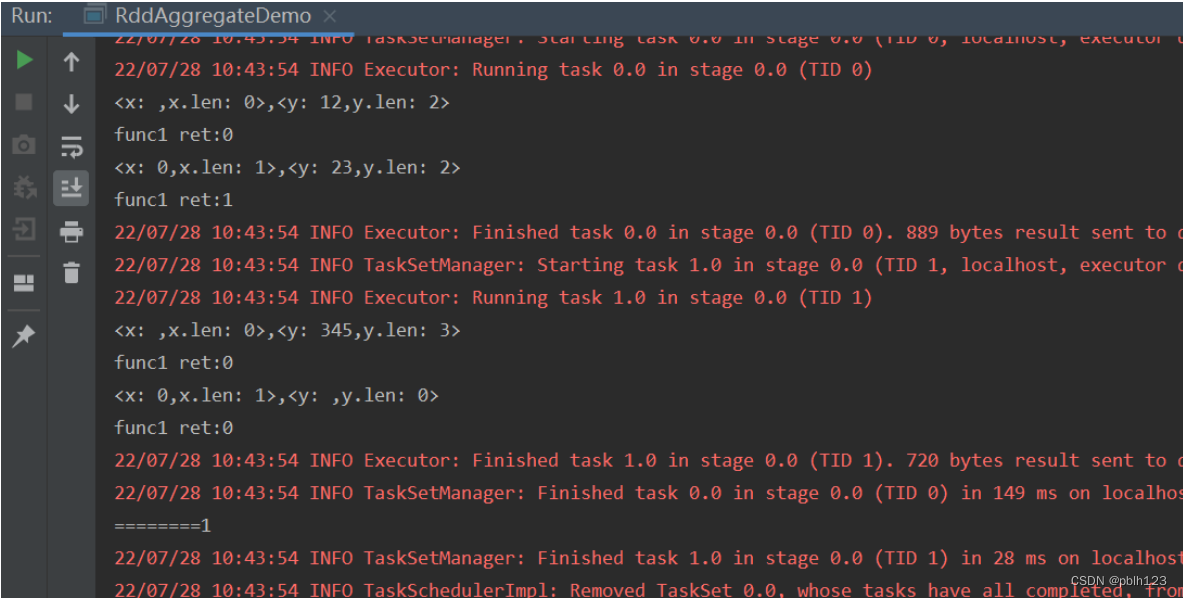
val rdd1 = sc.parallelize(List("12","23","345",""),numSlices = 2)
//下面代码等价与rdd1.aggregate("")(x+y) => math.min(x.length,y.length)),(x,y)=>x+y))
val result = rdd1.aggregate("")(func1,func2)
println(result)
}
//(x,y)=>math.min(x.Length,y.length)
def func1:(String,String) => String =(x:String,y:String) =>{
println("<x: " + x + ",x.len: " + x.length + ">,<y: " + y +",y.len: " + y.length + ">")
val ret =math.min(x.length,y.length).toString
println("func1 ret:" +ret)
ret
}
//(x+y) => x+y
def func2:(String,String)=>String=(x:String,y:String) =>{
println("========" +(x+y))
x+y
}
}
3、aggregateByKey
Create an RDD via a scala collection in a parallelized manner
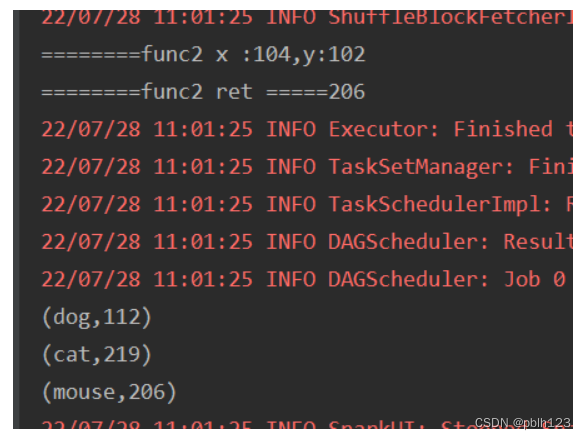
scala> val pairRdd = sc.parallelize(List((“cat”,2),(“cat”,5),(“mouse”,4),(“cat”,12),(“dog”,12),(“mouse”,2)),2)
pairRdd This RDD has two areas. One area stores:
(“cat”,2),(“cat”,5),(“mouse”,4)
Stored in another partition is:
(“cat”,12),(“dog”,12),(“mouse”,2)
Then, execute the following statement
scala > pairRdd.aggregateByKey(100)(math.max(_ , _), _ + _ ).collect
result:
res0: Array[(String,Int)] = Array((dog,100),(cat,200),(mouse,200)
The following is a detailed explanation of the principle of executing the above statement:
aggregateByKey means: aggregate according to key
Step 1: Put the data with the same key in each partition together
Partition one
(“cat”,(2,5)),(“mouse”,4)
Partition 2
(“cat”,12),(“dog”,12),(“mouse”,2)
Step 2: Find the local maximum value
Apply the first function passed in to each partition, math.max(_, _). The function of this function is to find the maximum value of each key in each partition.
At this time, special attention should be paid to the 100 in aggregateByKe(100)(math.max(_, _),_+_), which is actually an initial value.
When finding the maximum value in partition one, 100 will be added to the value of each key. At this time, each partition will look like the following
Partition one
(“cat”,(2,5,100)),(“mouse”,(4,100))
Then after finding the maximum value it becomes:
(“cat”,100), (“mouse”,100)
Partition 2
(“cat”,(12,100)),(“dog”,(12.100)),(“mouse”,(2,100))
After finding the maximum value, it becomes:
(“cat”,100),(“dog”,100),(“mouse”,100)
Step 3: Overall aggregation
The results of the previous step are further synthesized. At this time, 100 will no longer participate.
The final result is:
(dog,100),(cat,200),(mouse,200)
The same Key values in PairRDD are aggregated, and a neutral initial value is also used during the aggregation process. Similar to the aggregate function, the type of the return value of aggregateByKey does not need to be consistent with the type of value in the RDD. Because aggregateByKey performs an aggregation operation on values in the same Key, the final type returned by the aggregateByKey' function is still PairRDD. The corresponding result is the Key and the aggregated value, while the aggregate function directly returns a non-RDD result.
import org.apache.spark.{SparkConf, SparkContext}
object RddAggregateByKeyDemo {
def main(args: Array[String]): Unit = {
val conf =new SparkConf().setMaster("local").setAppName("RddAggregateByKeyDemo")
val sc = new SparkContext(conf)
val pairRDD = sc.parallelize(List(("cat",2),("cat",5),("mouse",4),("cat",12),("dog",12),("mouse",2)),numSlices = 2)
val rdd = pairRDD.aggregateByKey(100)(func2,func2)
val resultArray = rdd.collect
resultArray.foreach(println)
sc.stop()
}
def func2(index:Int,iter:Iterator[(String,Int)]):Iterator[String] = {
iter.map(x=>"[partID:" + index + ",val: " +x +"]")
}
//(x,y)=>math.max(x+y)
def func1:(Int,Int) => Int =(x:Int,y:Int) =>{
println("<x: " + x + "," +",y:"+ y + ">")
val ret =math.max(x,y)
println("func1 max:" +ret)
ret
}
//(x+y) => x+y
def func2:(Int,Int)=>Int=(x:Int,y:Int) =>{
println("========func2 x :" + x + ",y:"+y)
println("========func2 ret =====" +(x+y))
x+y
}
}