Table of contents
What should you know about a crawler?
1. Basic execution process of Scrapy
2.1Scrapy framework installation
(1) Introduction to crawler framework components
2.3.1 Create and write crawler files under spiders, the code is as follows
2.4 Terminal running crawler program
2.4.1 Need to enter the crawler framework directory cd spiderTest
2.4.2 Command execution crawler program
2. python learning suggestions
Preface
This article is for beginners. I will use the simplest illustrations and cases to help you understand python crawlers!
You need to download the PyCharm editor in advance.
In the Internet field, crawlers generally refer to related technologies that capture data on the web pages of many public websites.
If you want to get started with Python crawlers, you first need to solve four problems:
- Familiar with python programming
- Learn about HTML
- Understand the basic principles of web crawling
- Learn to use python crawler library
What should you know about a crawler?
Web crawlers are actually called network data collection , which is easier to understand.
It is to request data (HTML form) from the network server through programming, and then parse the HTML to extract the data you want.
It can be summarized into four major steps:
- Get HTML data based on url
- Parse HTML and obtain target information
- Storing data
- Repeat step one
This will involve databases, web servers, HTTP protocols, HTML, data science, network security, image processing, etc. But for beginners, you don’t need to master so much.
To make a long story short, let me introduce you to crawlers. If you are a novice or a novice crawler, I believe this knowledge will be enlightening for you!
1. Basic execution process of Scrapy
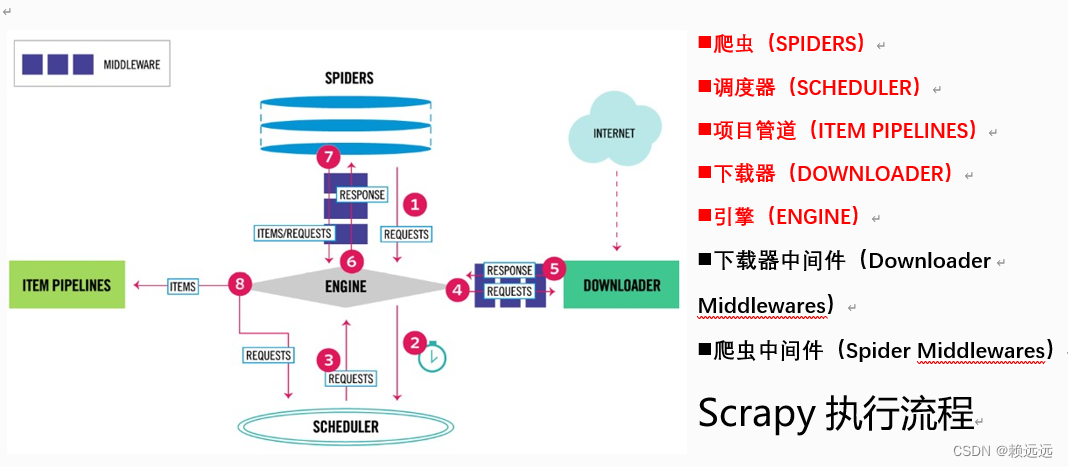
Step 1: The crawler (Spider) uses the URL (the URL of the page to be crawled) to construct a request (Request) object and submits it to the engine (Engine). If the request needs to be disguised as a browser or a proxy IP is set, it can be set in the crawler middleware first and then sent to the engine.
Step 2: The engine arranges the request to the scheduler, and the scheduler determines the execution order according to the priority of the request.
Step 3: The engine obtains the request to be executed from the scheduler.
Step 4: The engine sends the request to the downloader download page through the downloader middleware.
Step 5: After the page completes downloading, the downloader will generate a response object and send it to the engine. The downloaded data will be saved in the response object.
Step 6: After the engine receives the response object from the downloader, it sends it to the crawler (Spider) for processing through the crawler middleware.
Step 7: The crawler sends the extracted data entity (Item) and the new request (the link to the following page) to the engine.
Step 8: The engine sends the Items obtained from the crawler to Item Pipelines, which implement functions such as data persistence. At the same time, new requests are sent to the scheduler, and the execution is repeated from step 2 until there are no more requests in the scheduler and the engine closes the website.
Scrapy component summary

After having a preliminary understanding of the crawler components and implementation process, let's implement a simple crawler! ! !
2. Implementation of Scrapy
Our practice this time uses the development tool PyCharm to operate, with the purpose of crawling every document title under http://woodenrobot.me
Mainly divided into 4 steps:

2.1Scrapy framework installation
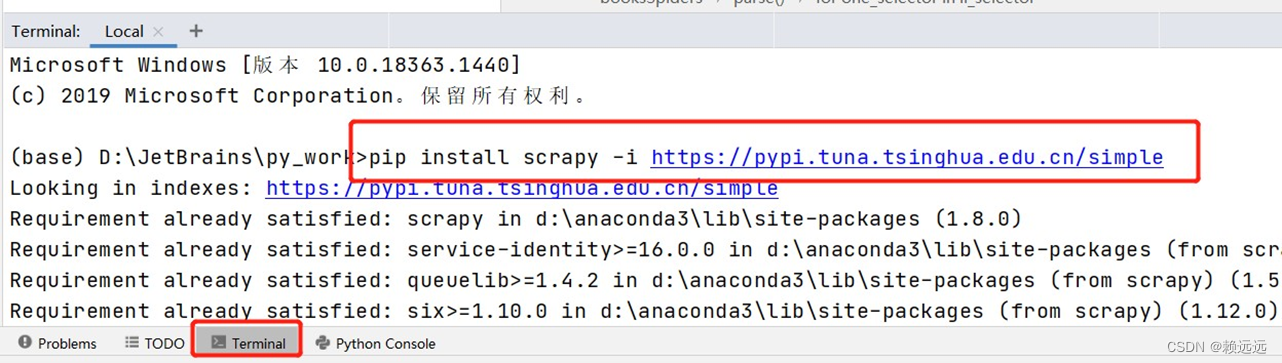
Download the crawler framework and enter the command in the terminal (you can directly enter pip install scrapy to download, but it will be very slow. We choose to download from domestic mirror sources):
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple
After installation, verify whether the installation is successful. Create a .py file and enter the following code:
import scrapy
print(scrapy.version_info)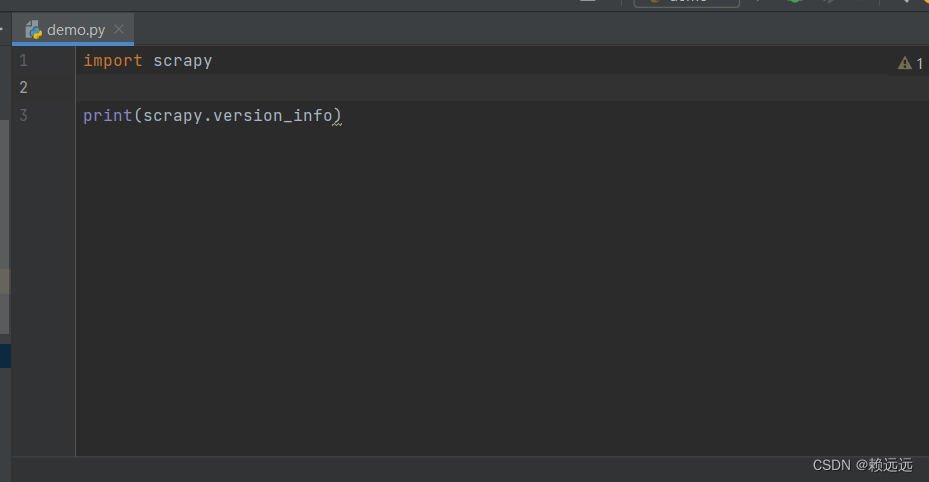
result:

2.2 Create project
(1) Introduction to crawler framework components

(2) Run the create framework command on the console (spiderTest is the name of the framework directory, defined as needed)
scrapy startproject spiderTest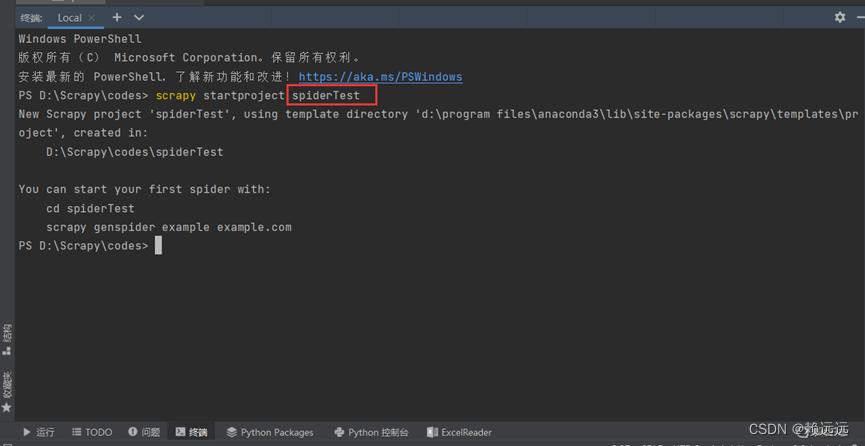
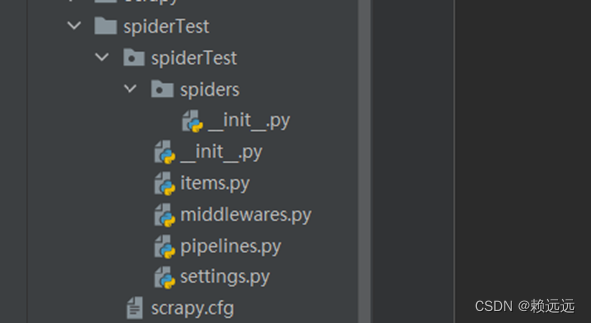
The directory frame is automatically generated after running
2.3 Write a crawler program
Spider class introduction

The crawler program we write needs to inherit the Spider class
2.3.1 Create and write crawler files under spiders, the code is as follows
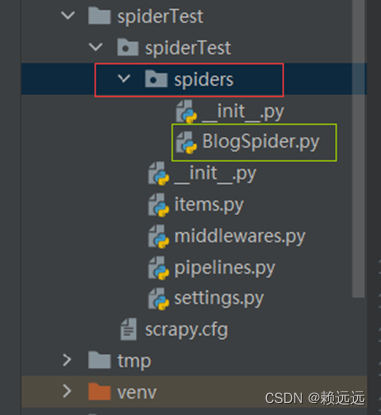
from scrapy.spiders import Spider
# BologSpider继承Spider类
class BlogSpider(Spider):
#爬虫的名称
name = 'test'
# 获取一个博客的url
start_urls = ['http://woodenrobot.me']
def parse(self, response,):
# 根据标题的xpath路径,提取出标题元素
title = response.xpath("//a[@class = 'post-title-link']/text()").getall() #getall()获取所有元素,返回列表
title_one = response.xpath("//a[@class = 'post-title-link']/text()").get() # get()获取第一个元素
# 便利title列表元素并输出
for title1 in title:
print(title1)
# 输出获取的一个元素
print(title_one)
2.4 Terminal running crawler program
2.4.1 Need to enter the crawler framework directory cd spiderTest

2.4.2 Command execution crawler program
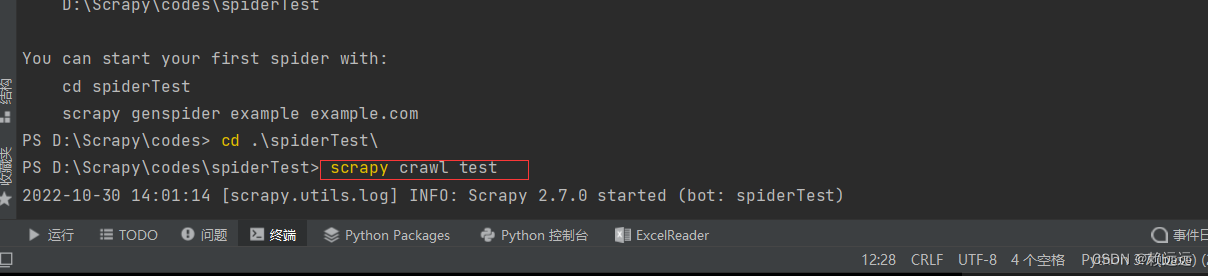
Get results
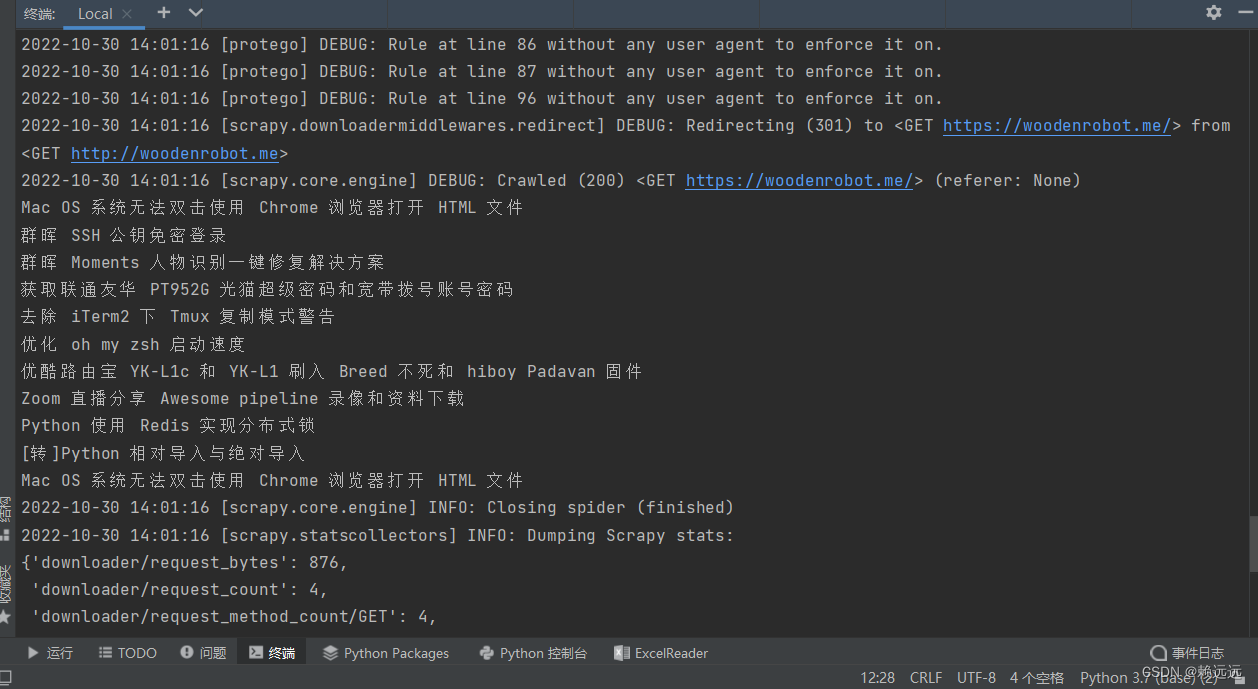
3. Conclusion
1. Summary
At this point you should have a preliminary concept of crawling web page data, but if you want to truly learn to write advanced crawler programs, you still need to learn a lot of knowledge.
One thing that needs to be mentioned is that if you don’t know how to use the developer tools to locate and crawl the title of the web page (as shown below), you need to learn the positioning of web page elements. You can learn it in a few minutes . This is also what you must master when learning to crawl. , not much expansion here.

2. python learning suggestions
If you don't know python, you need to learn python, which is a very easy language (compared to other languages) first.
The basic syntax of programming languages is nothing more than data types, data structures, operators, logical structures, functions, file IO, error handling, etc. It may be boring to learn but it is not difficult.
When you are just getting started with crawlers, you don't even need to learn python classes, multi-threading, modules and other slightly difficult content. Find a textbook or online tutorial for beginners, spend more than ten days, and you will have a 30-40% understanding of the basics of Python. At this time, you can play with crawlers!
Of course, the premise is that you must type the code carefully in these ten days and chew on the grammatical logic repeatedly. For example, the core things such as lists, dictionaries, strings, if statements, for loops, etc. must be familiar by heart and hands.
You can go to Nuke.com to practice online. This python introductory question sheet will guide you in great detail from the very beginning Hello World to practical tasks, data analysis, and machine learning, which functions you should use and how you should input and output.