Today, a friend was chatting. There are many machine learning algorithms, and each algorithm has its own characteristics. And in different scenarios, different algorithm models can bring into play their respective advantages.
Today, I gave a rough summary of common and commonly used algorithm models. Including its branches and the advantages and disadvantages of each branch.
The algorithms involved are:
-
return
-
regularization algorithm
-
Ensemble algorithm
-
Decision tree algorithm
-
Support Vector Machines
-
Dimensionality reduction algorithm
-
Clustering Algorithm
-
Bayesian algorithm
-
Artificial neural networks
-
deep learning
Interested friends can like and forward it so that more friends can see it.
Technology Exchange
Technology must be shared and communicated, and it is not recommended to work behind closed doors. One person can go very fast, and a group of people can go further.
This article is shared and recommended by fans, as well as interview materials and technical exchange improvements. All can be obtained by joining the communication group. The group has more than 2,000 members. The best way to add comments is: source + direction of interest, so as to find like-minded friends.
Method ①, add WeChat account: pythoner666, remarks: from CSDN + add group
Method ②, search public account on WeChat: Python learning and data mining, background reply: add group
return
Regression algorithms are a class of supervised learning algorithms used to predict continuous numerical outputs.
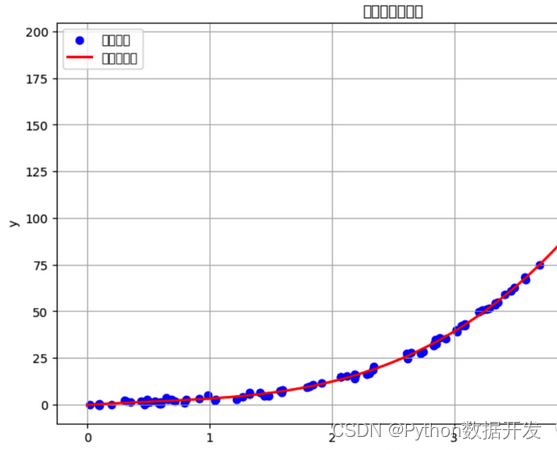
Predict one or more target variables based on input features. There are many branches and variants of regression algorithms, each with its own unique advantages and disadvantages.
1. Linear Regression
-
advantage:
-
Simple and easy to explain.
-
It is computationally efficient and suitable for large-scale data sets.
-
Works well when there is a linear relationship between features and targets.
-
shortcoming:
-
Unable to handle non-linear relationships.
-
Sensitive to outliers.
-
Linear regression assumptions need to be met (such as linear relationship, normal distribution of residuals, etc.).
2. Polynomial Regression
-
advantage:
-
Non-linear relationships between features and targets can be captured.
-
Relatively simple to implement.
-
shortcoming:
-
It is possible to overfit the data, especially with higher order polynomials.
-
The appropriate polynomial order needs to be chosen.
3. Ridge Regression
-
advantage:
-
Can solve multicollinearity problem.
-
Insensitive to outliers.
-
shortcoming:
-
Not suitable for feature selection, all features are considered.
-
Parameters need to be adjusted.
4. Lasso Regression
-
advantage:
-
Can be used for feature selection, tending to push the coefficients of unimportant features to zero.
-
Can solve multicollinearity problem.
-
shortcoming:
-
For high-dimensional data, fewer features may be selected.
-
Regularization parameters need to be adjusted.
5. Elastic Net Regression
-
advantage:
-
It combines the advantages of ridge regression and Lasso regression.
-
Can cope with multicollinearity and feature selection.
-
shortcoming:
-
Two regularization parameters need to be adjusted.
6. Logistic Regression :
-
advantage:
-
Used for binary classification problems and widely used in classification tasks.
-
The output can be interpreted as probabilities.
-
shortcoming:
-
Only suitable for binary classification problems.
-
May not work well for complex nonlinear problems.
7. Decision Tree Regression
-
advantage:
-
Able to handle non-linear relationships.
-
No feature scaling of the data is required.
-
Results are easy to visualize and interpret.
-
shortcoming:
-
Easy to overfit.
-
Sensitive to noise in data.
-
Unstable, small data changes may result in different tree structures.
8. Random Forest Regression
-
advantage:
-
Reduces the risk of overfitting in decision tree regression.
-
Able to handle high-dimensional data.
-
shortcoming:
-
Some interpretability is lost.
-
Difficulty adjusting model parameters.
When choosing a regression algorithm, you need to decide which algorithm is most suitable based on the nature of the data and the requirements of the problem. Often, experimentation and model tuning are required to determine the best regression model.
regularization algorithm
Regularization algorithms are techniques used to reduce the risk of overfitting of machine learning models.
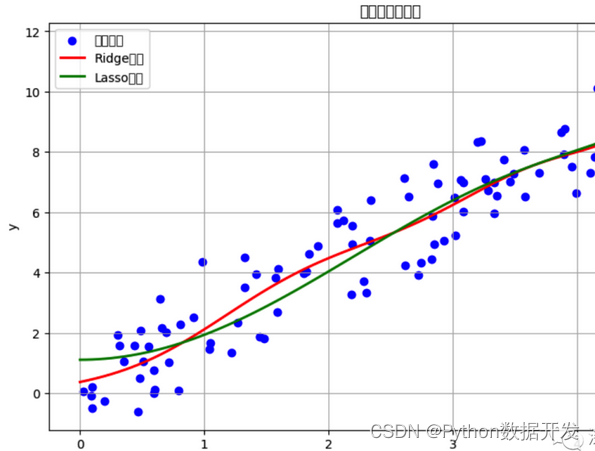
Limit the size of model parameters by introducing an additional penalty term in the model's loss function. There are many branches and variants of regularization. Here are some common branches of regularization algorithms and their advantages and disadvantages:
1. L1 regularization (Lasso regularization)
-
Advantages :
-
Can be used for feature selection to push the coefficients of unimportant features to zero.
-
Can solve multicollinearity problem.
-
Disadvantages :
-
For high-dimensional data, fewer features may be selected.
-
Regularization parameters need to be adjusted.
2. L2 regularization (ridge regularization)
-
Advantages :
-
Can solve multicollinearity problem.
-
Insensitive to outliers.
-
Disadvantages :
-
Not suitable for feature selection, all features are considered.
-
Parameters need to be adjusted.
3. Elastic Net regularization (Elastic Net regularization)
-
Advantages :
-
It combines the advantages of L1 and L2 regularization and can deal with multicollinearity and feature selection.
-
Two regularization parameters can be adjusted to balance the effects of L1 and L2 regularization.
-
Disadvantages :
-
Two regularization parameters need to be adjusted.
4. Dropout regularization (for neural networks)
-
Advantages :
-
Overfitting of a neural network can be reduced by randomly disabling neurons during training.
-
No additional parameter adjustments are required.
-
Disadvantages :
-
When inferring, missing neurons need to be taken into account, increasing the computational cost.
-
More training iterations may be required.
5. Bayesian Ridge and Lasso return
-
Advantages :
-
Bayesian thinking is introduced to provide uncertainty estimates of parameters.
-
Regularization parameters can be determined automatically.
-
Disadvantages :
-
The computational cost is high, especially for large data sets.
-
Not suitable for all types of problems.
6. Early Stopping
-
Advantages :
-
Overfitting of a neural network can be reduced by monitoring performance on the validation set.
-
Simple and easy to use, no additional parameter adjustments are required.
-
Disadvantages :
-
The timing to stop training needs to be carefully chosen, as stopping too early may lead to underfitting.
7. Data enhancement
-
Advantages :
-
By increasing the diversity of training data, the risk of model overfitting can be reduced.
-
Suitable for image classification and other fields.
-
Disadvantages :
-
Increased training data generation and management costs.
The choice of regularization method often depends on the nature of the data, the requirements of the problem, and the complexity of the algorithm. In practical applications, it is usually necessary to determine the most appropriate regularization strategy through experiments and parameter adjustments.
Ensemble algorithm
Ensemble algorithm is a technique that combines multiple weak learners (usually base models) into a strong learner.
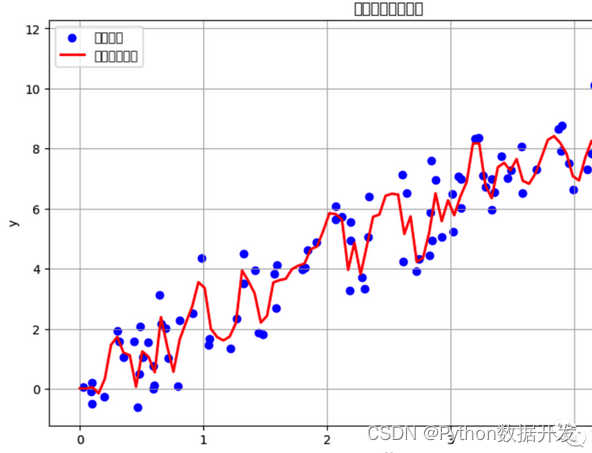
Ensemble algorithms can improve model performance and robustness by combining predictions from multiple models.
1、Bagging(Bootstrap Aggregating)
-
Advantages :
-
It reduces the variance of the model and reduces the risk of overfitting.
-
Parallel processing, suitable for large-scale data.
-
Disadvantages :
-
Not suitable for handling highly skewed class distributions.
-
Difficulty interpreting predictions from combined models.
2. Random Forest
-
Advantages :
-
Based on Bagging, the variance is reduced.
-
Able to handle high-dimensional data and large-scale features.
-
Provides feature importance assessment.
-
Disadvantages :
-
It is difficult to tune a large number of hyperparameters.
-
Sensitive to noise and outliers.
3、Boosting
-
Advantages :
-
Enhanced model accuracy.
-
Ability to automatically adjust the weights of weak learners.
-
Suitable for imbalanced class distributions.
-
Disadvantages :
-
Sensitive to noisy data.
-
Training time may be longer.
-
AdaBoost (Adaptive Boosting) :
-
Advantages: Ability to handle high-dimensional data and large-scale features, low sensitivity to outliers.
-
Disadvantages: Sensitive to noise and outliers.
-
Gradient Boosting :
-
Advantages: Provides high prediction performance and is relatively stable to noise and outliers.
-
Disadvantages: Multiple hyperparameters need to be adjusted.
-
XGBoost (Extreme Gradient Boosting) and LightGBM (Lightweight Gradient Boosting Machine) : Both are variants of the gradient boosting algorithm, which are efficient and scalable.
4、Stacking
-
Advantages :
-
Multiple models of different types can be combined.
-
Provides higher prediction performance.
-
Disadvantages :
-
More computing resources and data are required.
-
The complexity is higher and the adjustment of hyperparameters is more difficult.
5. Voting
-
Advantages :
-
Simple to use and easy to implement.
-
Ability to combine multiple models of different types.
-
Disadvantages :
-
The performance requirements for weak learners are relatively high.
-
The weight of each model is not considered.
6. Deep learning integration
-
Advantages :
-
The powerful representation capabilities of neural network models can be exploited.
-
Various integration methods are provided, such as voting, stacking, etc.
-
Disadvantages :
-
Training takes a long time and requires a lot of computing resources.
-
Hyperparameter tuning is more complex.
The choice of an appropriate ensemble algorithm often depends on the nature of the data, the requirements of the problem, and the availability of computing resources. In practical applications, experimentation and model tuning are often required to determine the ensemble method best suited to a specific problem.
Decision tree algorithm
The decision tree algorithm is a supervised learning algorithm based on a tree structure and is used for classification and regression tasks.
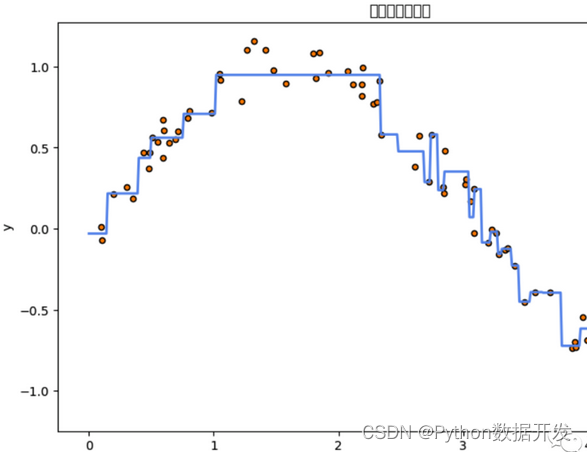
It builds a tree structure through a series of splits, with each internal node representing a feature test and each leaf node representing a category or numerical output.
1、ID3 (Iterative Dichotomiser 3)
-
Advantages :
-
Simple to understand and the resulting tree is easy to interpret.
-
Ability to handle classification tasks.
-
Disadvantages :
-
Limited handling of numeric attributes and missing values.
-
It is prone to overfitting and the generated tree may be very deep.
2、C4.5
-
Advantages :
-
Can handle classification and regression tasks.
-
Able to handle numeric attributes and missing values.
-
Use information gain for feature selection when generating trees, which is more robust.
-
Disadvantages :
-
Sensitive to noise and outliers.
-
The resulting tree may be too complex and requires pruning to reduce the risk of overfitting.
3、CART (Classification and Regression Trees)
-
Advantages :
-
Can handle classification and regression tasks.
-
There is good support for numeric attributes and missing values.
-
Use Gini impurity or mean square error for feature selection, which is more flexible.
-
Disadvantages :
-
The resulting tree may be deep and require pruning to avoid overfitting.
4. Random Forest
-
Advantages :
-
Based on decision trees, the risk of overfitting of decision trees is reduced.
-
Able to handle high-dimensional data and large-scale features.
-
Provides feature importance assessment.
-
Disadvantages :
-
It is difficult to tune a large number of hyperparameters.
-
Sensitive to noise and outliers.
5. Gradient Boosting Trees
-
Advantages :
-
Provides high prediction performance and is relatively stable to noise and outliers.
-
Suitable for regression and classification tasks.
-
Different loss functions can be used.
-
Disadvantages :
-
Several hyperparameters need to be tuned.
-
Training time may be longer.
6. XGBoost (Extreme Gradient Boosting) and LightGBM (Lightweight Gradient Boosting Machine)
- These are efficient implementations of gradient boosted trees that are highly scalable and performant.
7. Multi-output Trees
-
Advantages :
-
Able to handle multi-output (multi-objective) problems.
-
Multiple related target variables can be predicted.
-
Disadvantages :
-
A large amount of data is required to train efficient multi-output trees.
Choosing an appropriate decision tree algorithm often depends on the nature of the data, the requirements of the problem, and the complexity of the model. In practical applications, it is usually necessary to determine the most appropriate decision tree algorithm through experiments and model tuning. One of the advantages of decision tree algorithms is that the models they produce are easy to visualize and interpret.
Support Vector Machines
Support Vector Machine (SVM) is a powerful supervised learning algorithm used for classification and regression tasks.
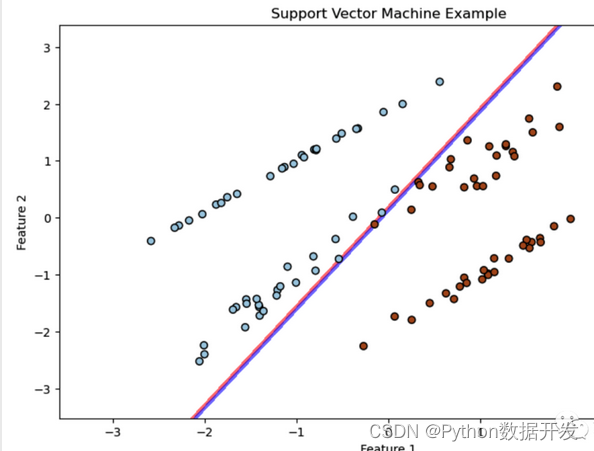
Separate data into different classes or fit a regression function by finding the optimal hyperplane.
1. Linear support vector machine
-
Advantages :
-
Effective in high-dimensional space and suitable for high-dimensional data.
-
It can be extended to nonlinear problems by choosing different kernel functions.
-
Has strong generalization ability.
-
Disadvantages :
-
Sensitive to large-scale data sets and number of features.
-
Sensitive to noise and outliers.
2. Nonlinear support vector machine
-
Advantages :
-
Can handle nonlinear problems.
-
By choosing an appropriate kernel function, it can be adapted to different types of data.
-
Disadvantages :
-
For complex nonlinear relationships, it may be necessary to choose appropriate kernel functions and parameters.
-
The computational complexity is high, especially for large data sets.
3. Multi-category support vector machine
-
Advantages :
-
Can handle multi-category classification problems.
-
Commonly used methods include One-vs-One and One-vs-Rest strategies.
-
Disadvantages :
-
In one-to-one strategy, multiple classifiers need to be built.
-
In one-to-many strategies, class imbalance problems may arise.
4. Kernel function support vector machine
-
Advantages :
-
Able to handle non-linear problems.
-
Radial basis functions (RBF) are often used as kernel functions.
-
Suitable for complex data distribution.
-
Disadvantages :
-
Appropriate kernel functions and related parameters need to be selected.
-
For high-dimensional data, there may be a risk of overfitting.
5. Sparse support vector machine
-
Advantages :
-
Sparsity is introduced, with only a few support vectors contributing to the model.
-
Can improve model training and inference speed.
-
Disadvantages :
-
Not suitable for all types of data and may not work well for some data distributions.
6. Kernel Bayesian Support Vector Machine
-
Advantages :
-
It combines the kernel method and the Bayesian method, with probabilistic inference capabilities.
-
Suitable for small samples and high-dimensional data.
-
Disadvantages :
-
The computational complexity is high and may not be suitable for large-scale data sets.
7. Imbalanced category support vector machine
-
Advantages :
-
Specifically designed to handle class imbalance problems.
-
Balance the impact of different categories by adjusting category weights.
-
Disadvantages :
-
The weight parameters need to be adjusted.
-
For extremely imbalanced data sets, other methods may be needed.
The selection of an appropriate SVM algorithm often depends on the nature of the data, the requirements of the problem, and the availability of computing resources. SVM generally performs well on small to medium-sized data sets, but may require more computing resources on large-scale data sets. Additionally, attention needs to be paid to tuning the hyperparameters for optimal performance.
Dimensionality reduction algorithm
Dimensionality reduction algorithms are a class of techniques used to reduce the dimensionality of data.
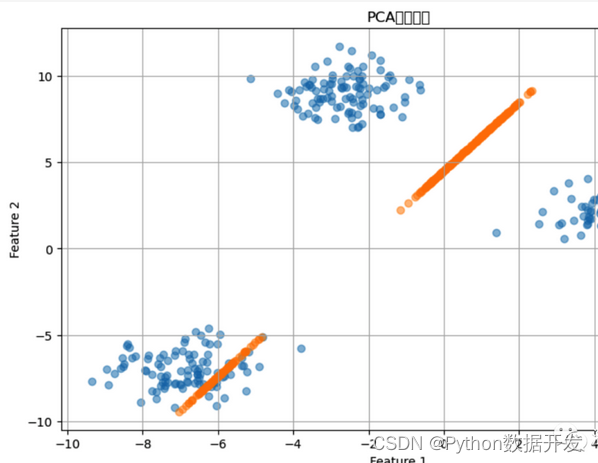
The main goal is to reduce the number of features while retaining key features of the data.
1. Principal Component Analysis (PCA, Principal Component Analysis)
-
Advantages :
-
One of the most commonly used dimensionality reduction methods, easy to understand and implement.
-
Capture the main directions of change in the data.
-
The number of features can be reduced by linear transformation.
-
Disadvantages :
-
Dimensionality reduction may not be effective for data with non-linear relationships.
-
Category information is not considered.
2. Linear Discriminant Analysis (LDA, Linear Discriminant Analysis)
-
Advantages :
-
Similar to PCA, but considering category information, it is suitable for classification problems.
-
The number of features can be reduced and classification performance improved through linear transformation.
-
Disadvantages :
-
The dimensionality reduction effect may be limited for nonlinear problems.
-
Only suitable for classification problems.
3. t-Distributed Stochastic Neighbor Embedding (t-SNE, t-Distributed Stochastic Neighbor Embedding)
-
Advantages :
-
Nonlinear dimensionality reduction methods that can capture complex structures in data.
-
Suitable for visualizing high-dimensional data.
-
Disadvantages :
-
The computational complexity is high and it is not suitable for large-scale data.
-
May cause unstable results between runs.
4. Autoencoder
-
Advantages :
-
Nonlinear dimensionality reduction method can learn the nonlinear characteristics of data.
-
Suitable for unsupervised learning tasks.
-
Disadvantages :
-
The training complexity is high and requires a large amount of data.
-
Sensitive to the choice of hyperparameters.
5. Independent Component Analysis (ICA, Independent Component Analysis)
-
Advantages :
-
Suitable for problems where source signals are independent of each other, such as signal processing.
-
Can be used for blind source separation.
-
Disadvantages :
-
The assumptions for the data are relatively high and the independence assumption needs to be met.
6. Feature Selection
-
Advantages :
-
Instead of dimensionality reduction, select the most important features.
-
The interpretability of the original features is preserved.
-
Disadvantages :
-
Some information may be missing.
-
Feature selection methods need to be chosen carefully.
7. Kernel method dimensionality reduction
-
Advantages :
-
Able to handle non-linear data.
-
The data is mapped into a high-dimensional space through kernel techniques, and then dimensionality reduction is performed in this space.
-
Disadvantages :
-
The computational complexity is high, especially for large-scale data.
-
The kernel function needs to be chosen carefully.
Choosing an appropriate dimensionality reduction method often depends on the nature of the data, the requirements of the problem, and the availability of computing resources. Dimensionality reduction helps reduce data dimensions and remove redundant features, but there is a trade-off between dimensionality reduction and information loss. Different dimensionality reduction methods are suitable for different problems and data types.
Clustering Algorithm
Clustering algorithms are a class of unsupervised learning algorithms used to group data into similar clusters or groups.
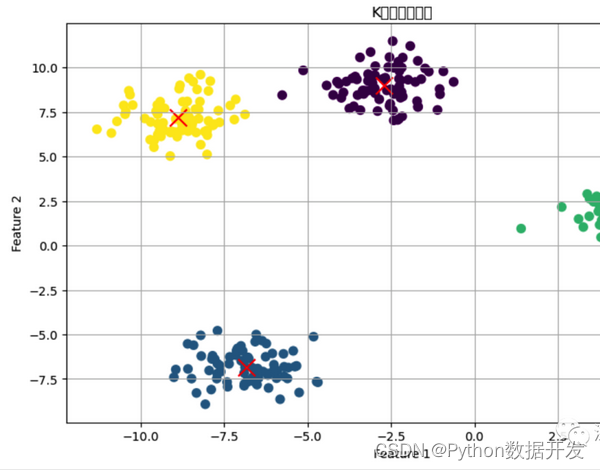
There are many branches and variants of clustering. Here are some common branches of clustering algorithms and their advantages and disadvantages:
1. K-Means Clustering
-
Advantages :
-
Simple to understand and easy to implement.
-
Suitable for large-scale data.
-
Faster and suitable for many applications.
-
Disadvantages :
-
The number of clusters K needs to be specified in advance.
-
Sensitive to the choice of initial cluster centers.
-
Sensitive to outliers and noise.
-
Suitable for convex clusters.
2. Hierarchical Clustering
-
Advantages :
-
There is no need to specify the number of clusters in advance.
-
A hierarchical cluster structure can be generated.
-
Suitable for irregularly shaped clusters.
-
Disadvantages :
-
The computational complexity is high and it is not suitable for large-scale data.
-
Results are less interpretable.
3. Density-Based Clustering
-
Advantages :
-
Ability to discover clusters of arbitrary shapes.
-
Relatively robust to noise and outliers.
-
There is no need to specify the number of clusters in advance.
-
Disadvantages :
-
Sensitive to the choice of parameters.
-
Not suitable for situations where data densities vary greatly.
4. Spectral Clustering
-
Advantages :
-
Ability to discover clusters of arbitrary shapes.
-
Suitable for irregularly shaped clusters.
-
Not affected by the choice of initial cluster centers.
-
Disadvantages :
-
The computational complexity is high and it is not suitable for large-scale data.
-
The similarity matrix and number of clusters need to be chosen carefully.
5、DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
-
Advantages :
-
Ability to automatically discover clusters of arbitrary shapes.
-
Relatively robust to noise and outliers.
-
There is no need to specify the number of clusters in advance.
-
Disadvantages :
-
For high-dimensional data, special attention needs to be paid to parameter selection.
-
May not work well when data densities vary greatly.
6. EM clustering (Expectation-Maximization Clustering)
-
Advantages :
-
Suitable for mixture models, clusters of probability distributions can be discovered.
-
Suitable for situations where the data has missing values.
-
Disadvantages :
-
Sensitive to the choice of initial parameters.
-
For high-dimensional data, special attention needs to be paid to parameter selection.
7. Fuzzy Clustering
-
Advantages :
-
Ability to assign each data point to multiple clusters, taking into account data uncertainty.
-
Suitable for fuzzy classification problems.
-
Disadvantages :
-
The computational complexity is high.
-
Results are less interpretable.
The choice of an appropriate clustering method often depends on the nature of the data, the requirements of the problem, and the availability of computing resources. Clustering algorithms can be used for a variety of applications such as data exploration, pattern discovery, and anomaly detection, but they need to be selected and adjusted according to specific situations.
Bayesian algorithm
Bayesian algorithm is a type of statistical method based on Bayes' theorem, which is used to deal with uncertainty and probabilistic inference. It has multiple branches and variants. Here are some common branches of Bayesian algorithm and their advantages and disadvantages:
1. Naive Bayes
-
Advantages :
-
Simple, easy to understand and implement.
-
Performs well on small-scale data and high-dimensional data.
-
Can be used for tasks such as classification and text classification.
-
Disadvantages :
-
Based on strong feature independence assumptions, it may not be applicable to data with complex associations.
-
Sensitive to imbalanced data and noisy data.
2. Bayesian Networks
-
Advantages :
-
Ability to represent and reason about complex probabilistic relationships and dependencies.
-
Supports handling of incomplete and missing data.
-
Suitable for domain modeling and decision support systems.
-
Disadvantages :
-
Learning and parameter estimation of model structures can be complex.
-
For large-scale data and high-dimensional data, the computational cost may be higher.
3. Gaussian Processes
-
Advantages :
-
Ability to model nonlinear relationships and uncertainty.
-
Confidence interval estimates are provided.
-
Suitable for regression and classification tasks.
-
Disadvantages :
-
The computational complexity is high and it is not suitable for large-scale data.
-
Appropriate kernel functions and hyperparameters need to be selected.
4. Bayesian Optimization
-
Advantages :
-
Used to optimize black-box functions, such as hyperparameter tuning.
-
Ability to find optimal solutions in a small number of iterations.
-
Suitable for complex and expensive optimization problems.
-
Disadvantages :
-
The computational cost is relatively high.
-
Careful selection of priors and sampling strategies is required.
5. Variational Bayesian Methods
-
Advantages :
-
Parameter estimation and inference for probabilistic models.
-
Can be used to process large-scale data sets.
-
A framework for approximate inference is provided.
-
Disadvantages :
-
Approximate extrapolation may introduce estimation errors.
-
Model selection and parameter selection require caution.
6. Bayesian Deep Learning
-
Advantages :
-
A combination of deep learning and Bayesian methods provides uncertainty estimates.
-
Suitable for small sample learning and model uncertainty modeling.
-
Disadvantages :
-
The computational complexity is high and the training time is long.
-
Hyperparameter adjustment is complex.
Bayesian methods have wide applications in dealing with uncertainty, probabilistic modeling, optimization, and pattern recognition, but different branches are suitable for different types of problems and data. The choice of an appropriate Bayesian method often depends on the requirements of the problem and the availability of computational resources.
Artificial neural networks
Artificial Neural Networks (ANNs) are machine learning models inspired by the structure of the human brain.
Used to handle a variety of tasks, including classification, regression, image processing, and natural language processing.
1. Feedforward Neural Networks (FNNs)
-
Advantages :
-
Suitable for a variety of tasks, including classification and regression.
-
It has strong representation ability and can capture complex nonlinear relationships.
-
Provides a foundation for deep learning problems.
-
Disadvantages :
-
For small sample data, overfitting is prone to occur.
-
A large amount of labeled data is required for training.
2. Convolutional Neural Networks (CNNs)
-
Advantages :
-
Specifically designed for image processing and computer vision tasks.
-
Effectively capture local features in images through convolutional layers.
-
Has translation invariance.
-
Disadvantages :
-
Large-scale labeled image data is required for training.
-
The performance may not be as good as feedforward neural networks on tasks in other domains.
3. Recurrent Neural Networks (RNNs)
-
Advantages :
-
Suitable for sequence data such as natural language processing and time series analysis.
-
It has a loop connection and can handle sequence data of variable length.
-
Has the ability to remember and capture time dependencies.
-
Disadvantages :
-
The vanishing gradient problem causes performance degradation for long sequences.
-
The computational complexity is high and it is not suitable for large-scale data and deep networks.
4. Long Short-Term Memory (LSTM)
-
Advantages :
-
Solve the vanishing gradient problem of RNN.
-
Suitable for modeling long sequences.
-
It has achieved remarkable success in fields such as natural language processing.
-
Disadvantages :
-
The computational complexity is high.
-
A large amount of data is required to train deep LSTM networks.
5. Gated Recurrent Unit (GRU)
-
Advantages :
-
Similar to LSTM, but with fewer parameters and lower computational complexity.
-
The performance is comparable to LSTM on some tasks.
-
Disadvantages :
-
For some complex tasks, the performance may not be as good as LSTM.
6. Self-attention model (Transformer)
-
Advantages :
-
Suitable for tasks such as natural language processing and sequence modeling.
-
It can be parallelized and has high computational efficiency.
-
Excellent performance on large-scale data and deep models.
-
Disadvantages :
-
Large-scale data is required for training.
-
Relatively new model and may not be suitable for all tasks.
7. Generative Adversarial Networks (GANs)
-
Advantages :
-
Used to generate data and images, and perform unsupervised learning.
-
Generate high-quality samples.
-
It has achieved remarkable success in areas such as image generation and style transfer.
-
Disadvantages :
-
The training complexity is high and the stability is poor, so the hyperparameters need to be adjusted carefully.
-
For some tasks, there may be mode crash issues.
Choosing an appropriate neural network architecture often depends on the nature of the problem, the type of data, and the availability of computing resources. Neural networks have achieved remarkable success in a variety of fields, but there are also challenges in training and tuning.
deep learning
Deep learning is a branch of machine learning based on deep neural networks and used to solve various complex tasks.
1. Convolutional Neural Networks (CNNs)
-
Advantages :
-
For image processing and computer vision tasks including image classification, object detection and image segmentation.
-
Effectively capture local features in images through convolutional layers.
-
Has translation invariance.
-
Disadvantages :
-
Large-scale labeled image data is required for training.
-
The performance may not be as good as feedforward neural networks on tasks in other domains.
2. Recurrent Neural Networks (RNNs)
-
Advantages :
-
Suitable for sequence data such as natural language processing and time series analysis.
-
It has a loop connection and can handle sequence data of variable length.
-
Has the ability to remember and capture time dependencies.
-
Disadvantages :
-
The vanishing gradient problem causes performance degradation for long sequences.
-
The computational complexity is high and it is not suitable for large-scale data and deep networks.
3. Long Short-Term Memory (LSTM)
-
Advantages :
-
Solve the vanishing gradient problem of RNN.
-
Suitable for modeling long sequences.
-
It has achieved remarkable success in fields such as natural language processing.
-
Disadvantages :
-
The computational complexity is high.
-
A large amount of data is required to train deep LSTM networks.
4. Gated Recurrent Unit (GRU)
-
Advantages :
-
Similar to LSTM, but with fewer parameters and lower computational complexity.
-
The performance is comparable to LSTM on some tasks.
-
Disadvantages :
-
For some complex tasks, the performance may not be as good as LSTM.
5. Self-attention model (Transformer)
-
Advantages :
-
Suitable for tasks such as natural language processing and sequence modeling.
-
It can be parallelized and has high computational efficiency.
-
Excellent performance on large-scale data and deep models.
-
Disadvantages :
-
Large-scale data is required for training.
-
Relatively new model and may not be suitable for all tasks.
6. Generative Adversarial Networks (GANs)
-
Advantages :
-
Used to generate data and images, and perform unsupervised learning.
-
Generate high-quality samples.
-
It has achieved remarkable success in areas such as image generation and style transfer.
-
Disadvantages :
-
The training complexity is high and the stability is poor, so the hyperparameters need to be adjusted carefully.
-
For some tasks, there may be mode crash issues.
7. Autoencoder
-
Advantages :
-
Used for feature learning, dimensionality reduction and denoising.
-
Suitable for unsupervised learning tasks.
-
Disadvantages :
-
The training complexity is high and requires a large amount of data.
-
Sensitive to the choice of hyperparameters.
Deep learning has achieved remarkable success in a variety of fields, but training and tuning deep neural networks often requires large-scale data and computing resources. Choosing an appropriate deep learning algorithm often depends on the nature of the problem, the type of data, and the availability of computing resources. The design and tuning of deep learning models is a complex task that needs to be handled with care.
at last
Today we introduce some core advantages and disadvantages of the algorithm.
In addition, more presentation methods and usage techniques can be obtained from official documents and experienced in actual combat!
Friends who like it can collect it, like it, and forward it!