A guy named Jack Cook turned the macOS Sonoma beta upside down and found out a lot of fresh information.
This article is reprinted with the authorization of AI New Media Qubit (public account ID: QbitAI). Please contact the source for reprinting.
The "secret" of Apple's Transformer has been revealed by enthusiasts.
In the wave of large models, even if you are as conservative as Apple, you must mention "Transformer" at every press conference.
For example, at this year's WWDC, Apple announced that new versions of iOS and macOS will have built-in Transformer language models to provide input methods with text prediction capabilities.

Apple officials did not reveal any more information, but technology enthusiasts can’t sit still.
A guy named Jack Cook turned the macOS Sonoma beta upside down and found out a lot of fresh information:
- In terms of model architecture, Cook believes that Apple’s language model is more based on GPT-2 .
- In terms of tokenizers, emoticons are very prominent.
Let’s take a look at more details.
Based on GPT-2 architecture
First, let’s review what functions Apple’s Transformer-based language model can implement on iPhone, MacBook and other devices.
Mainly reflected in the input method. Apple's own input method, supported by the language model, can realize word prediction and error correction functions.
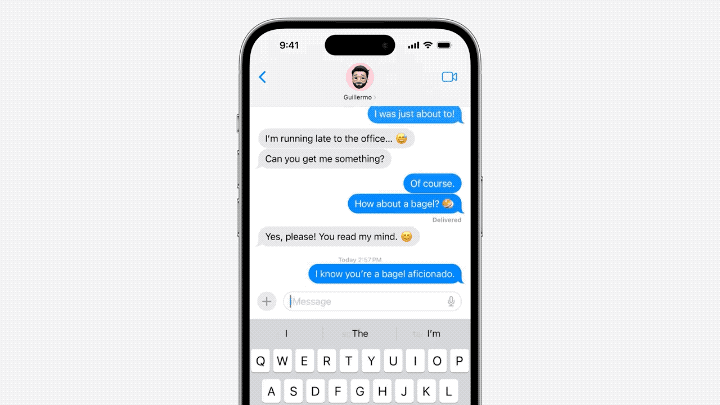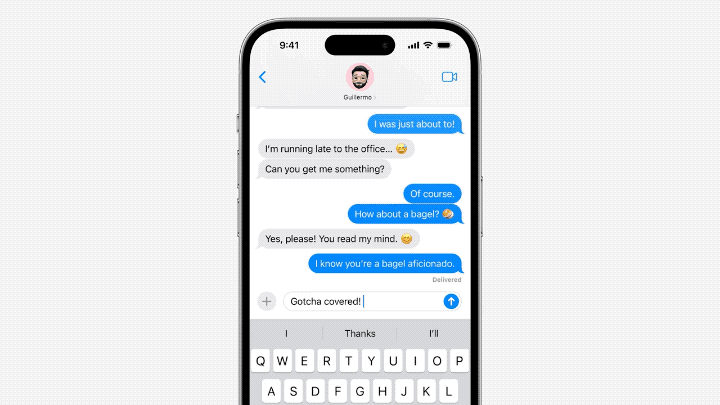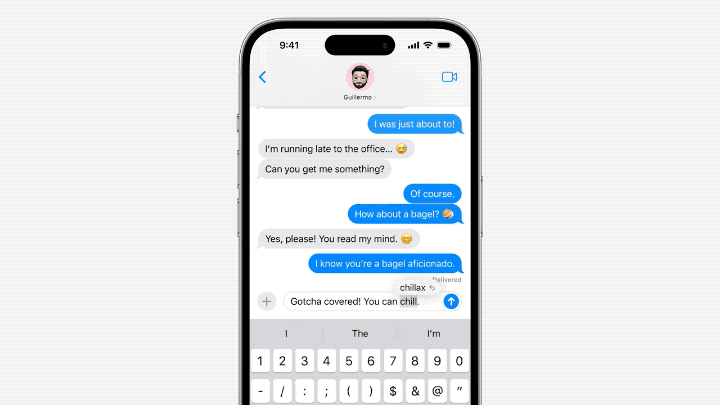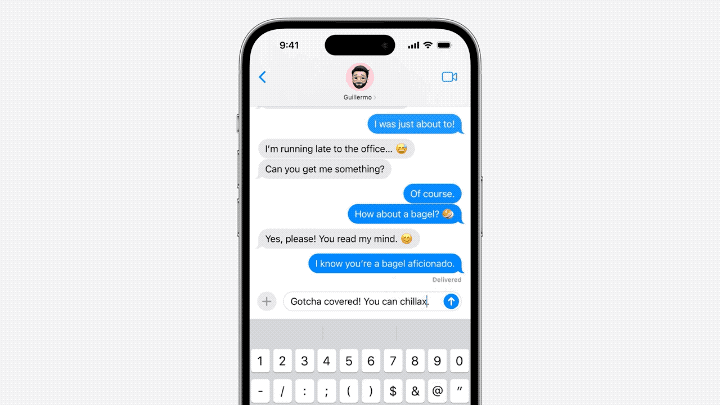
Brother Jack Cook tested it specifically and found that this function mainly implements prediction of single words.

△Source: Jack Cook blog post
The model sometimes predicts multiple upcoming words, but this is limited to situations where the semantics of the sentence are very obvious, similar to the auto-complete function in Gmail.

△Source: Jack Cook blog post
So where exactly is this model installed? After some in-depth digging, Brother Cook determined:
I found the predictive text model in /System/Library/LinguisticData/RequiredAssets_en.bundle/AssetData/en.lm/unilm.bundle.
Because:
- Many files in unilm.bundle do not exist in macOS Ventura (13.5) and only appear in the new version of macOS Sonoma beta (14.0).
- There is a sp.dat file in unilm.bundle, which can be found in both Ventura and Sonoma beta, but the Sonoma beta version has been updated with a set of tokens that obviously look like a tokenizer.
- The number of tokens in sp.dat matches the two files in unilm.bundle - unilm_joint_cpu.espresso.shape and unilm_joint_ane.espresso.shape. These two files describe the shape of each layer in the Espresso/CoreML model.
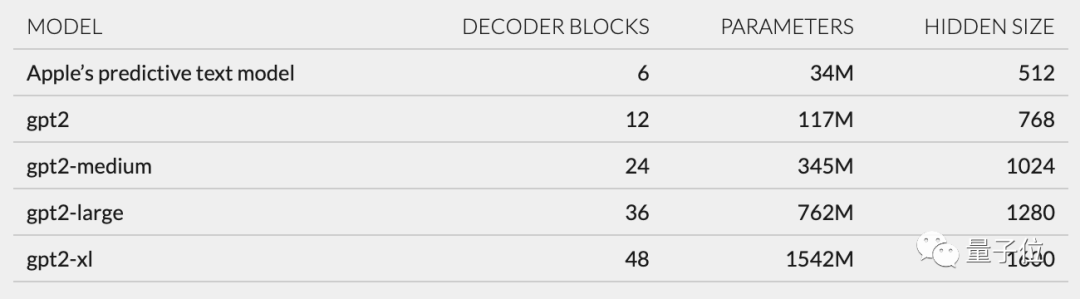
Furthermore, based on the network structure described in unilm_joint_cpu, I speculated that the Apple model is based on the GPT-2 architecture:
It mainly includes token embeddings, position encoding, decoder block and output layer. Each decoder block has words like gpt2_transformer_layer_3d.
△Source: Jack Cook blog post
Based on the size of each layer, I also speculated that the Apple model has approximately 34 million parameters and the hidden layer size is 512. That is, it is smaller than the smallest version of GPT-2.
I believe this is mainly because Apple wants a model that consumes less power but can run quickly and frequently.
Apple's official statement at WWDC is that "every time a key is clicked, the iPhone will run the model once."
However, this also means that this text prediction model is not very good at continuing sentences or paragraphs completely.

△Source: Jack Cook blog post
In addition to the model architecture, Cook also dug up information about the tokenizer.
He found a set of 15,000 tokens in unilm.bundle/sp.dat. It is worth noting that it contains 100 emojis .
Cook reveals the secrets of Cook
Although this Cook is not a cook, my blog post still attracted a lot of attention as soon as it was published.

Based on his findings, netizens enthusiastically discussed Apple's approach to balancing user experience and cutting-edge technology applications.

Back to Jack Cook himself, he graduated from MIT with a bachelor's degree and a master's degree in computer science, and is currently studying for a master's degree in Internet social sciences from Oxford University.
Previously, he interned at NVIDIA, focusing on the research of language models such as BERT. He is also a senior research and development engineer for natural language processing at The New York Times.