Article directory

1. Abstract
SAM is becoming a fundamental step for many advanced tasks, such as image segmentation, image subtitles, and image editing. However, its huge computational cost prevents its wider application in industry scenarios. The calculations mainly come from the Transformer architecture of high-resolution input.

The researchers proposed a comparably accelerated alternative for this basic task . By reformulating the task into segment generation and hinting , we find that conventional CNN detectors with instance segmentation branches also perform well on this task. Specifically, we convert this task into a well-studied instance segmentation task and directly train existing instance segmentation methods using only 1/50 of the SA-1B dataset released by the SAM authors. Using our approach, we achieve comparable performance to the SAM approach at 50x runtime speedup. We give sufficient experimental results to prove its effectiveness.


2. Background introduction
SAM is regarded as a landmark vision-based model. It can segment any object in an image, guided by a variety of possible user interaction prompts. SAM leverages the Transformer model trained on the extensive SA-1B dataset, which enables it to expertly handle a variety of scenes and objects. SAM opens the door to an exciting new mission called Segment Anything. This mission, due to its generalizability and potential, has all the conditions to become the cornerstone of future broad vision missions.
However, despite these advances and promising results of SAM and subsequent models in handling any task in the market segment, its practical application remains challenging. The outstanding issue is the massive computational resource requirements associated with the Transformer (ViT) model, the main part of the SAM architecture. Compared with convolutional techniques, ViT stands out for its heavy computational resource requirements, which poses obstacles to its practical deployment, especially in real-time applications. This limitation therefore hinders the progress and potential of SA missions.
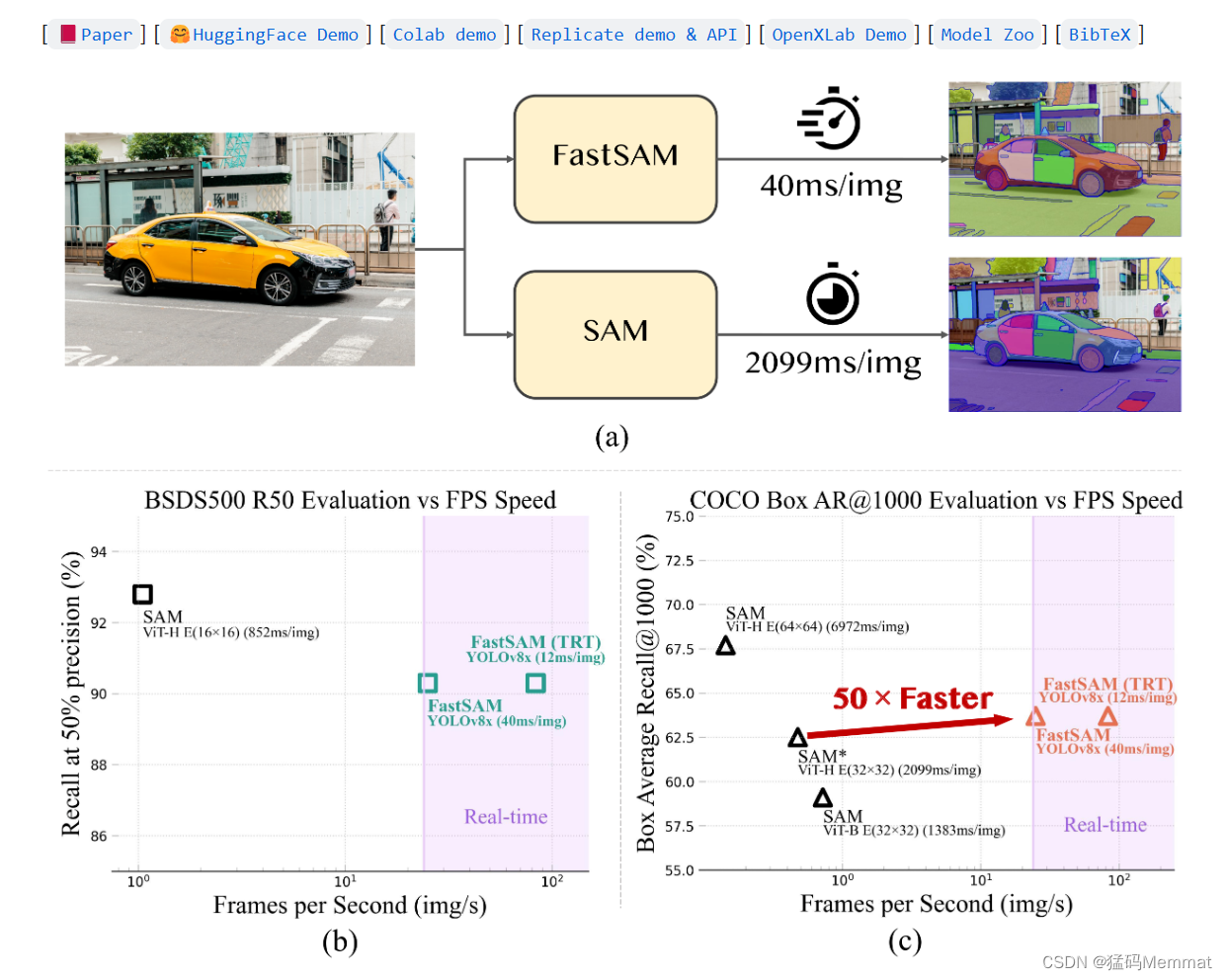



In response to the industrial demand for real-time segmentation of SAM, this paper designs a real-time solution for SA tasks, FastSAM. We decouple the SA task into two consecutive stages, namely all-instance segmentation and prompt-guided selection. The first stage is based on the implementation of a convolutional neural network (CNN) detector. It generates segmentation masks for all instances in the image. Then in the second stage, the region of interest corresponding to the prompt is output. By leveraging the computational efficiency of CNNs, we demonstrate that real-time segmentation of any model is achievable without compromising performance quality. We hope that the proposed method will facilitate industrial applications for the fundamental task of segmenting anything.
Our proposed FastSAM is based on YOLOv8-seg [16], an object detector equipped with an instance segmentation branch, which utilizes the YOLACT [4] method. We also adopted the extensive SA-1B dataset released by SAM. By directly training this CNN detector on only 2% (1/50) of the SA-1B dataset, it achieves performance comparable to SAM but with significantly reduced computational and resource requirements, enabling real-time applications. We also apply it to multiple downstream segmentation tasks to demonstrate its generalization performance. On the target proposal task [13] on MS COCO, we achieve 63.7 under AR1000, which is 1.2 points better than SAM under 32 × 32 point prompt input, but runs 50 times faster on a single NVIDIA RTX 3090.
Real-time segmentation models are valuable for industrial applications. It can be applied to many scenarios. The proposed method not only provides a new and practical solution to a large number of vision tasks, but is also very fast, dozens or hundreds of times faster than CRRE. It also provides new views on large model architectures for general vision tasks. We believe that for specific tasks, specific models can still achieve better efficiency and accuracy trade-offs. Our approach then demonstrates the feasibility of a path that can significantly reduce computational effort by introducing artificial priors before the structure, in the sense of model compression. Our contributions can be summarized as follows:
- A novel CNN-based solution for real-time SA tasks is introduced that significantly reduces computational requirements while maintaining competitive performance.
- This work presents the first study of applying CNN detectors to SA tasks, providing insights into the potential of lightweight CNN models in complex vision tasks.
- A comparative evaluation of the proposed method and SAM on multiple benchmarks can provide insights into the advantages and disadvantages of this method in the field of SA.
2.0.1 TensorRT
Introduction to TensorRT : https://blog.csdn.net/weixin_42111770/article/details/114336102
Several ways to convert pytorch model (.pth) to tensorrt model (.engine) : https://blog.csdn.net/qq_39056987/article/details/124588857
2.0.2 Zero-Shot
ZSLearning hopes that our model can classify categories it has never seen before, so that the machine can have reasoning capabilities and achieve true intelligence. Zero-shot refers to not learning once for the category objects to be classified.
A definition of zero-shot: use the training set data to train the model so that the model can classify the objects in the test set, but there is no intersection between the training set category and the test set category; during this period, it is necessary to use the description of the category to establish the training set and The connection between the test sets makes the model effective.
Introduction to Zero-shot : https://blog.csdn.net/gary101818/article/details/129108491
In machine learning, large amounts of training data are often required to train a model so that it can accurately recognize and classify new inputs. However, in the real world, obtaining large-scale labeled datasets can be expensive and time-consuming. Therefore, techniques such as zero-shot learning, one-shot learning, and few-shot learning emerged to solve this problem.
Zero-shot learning is a method that can learn new categories without any samples. Typically, a model can only recognize categories it has seen in the training set. But through zero-shot learning, the model can use some auxiliary information to make inferences and generalize to never-seen categories. These auxiliary information can be semantic descriptions, attributes, or other prior knowledge about the categories.
One-shot learning is a method that only requires one sample to learn new categories. This method attempts to classify by learning the similarities between samples. For example, when we only have a picture of a lion, one-shot learning can help us correctly classify new lion images.
Few-Shot Learning is a method between zero-shot learning and one-shot learning. It allows the model to learn new categories with a limited number of examples. Compared with zero-shot learning, few-shot learning provides more training data, but it is still relatively small. This enables the model to learn new categories from a small number of examples and accurately classify new inputs.
Introduction to the concept of Zero-Shot, One-Shot, and Few-Shot Learning : https://blog.csdn.net/weixin_42010722/article/details/131182669
3. Framework details (Methodology)
3.1 Overview
The figure below gives an overview of the proposed FastSAM method. The method consists of two stages, namely all-instance segmentation (ais) and prompt-guided selection (pgs). The first stage is the foundation, and the second stage is essentially task-oriented post-processing. Unlike end-to-end transformers, the holistic approach introduces many human priors that match the visual segmentation task, such as local connections of convolutions and receptive field-related object allocation strategies. This allows it to be tailored to visual segmentation tasks and converge faster on a smaller number of parameters.
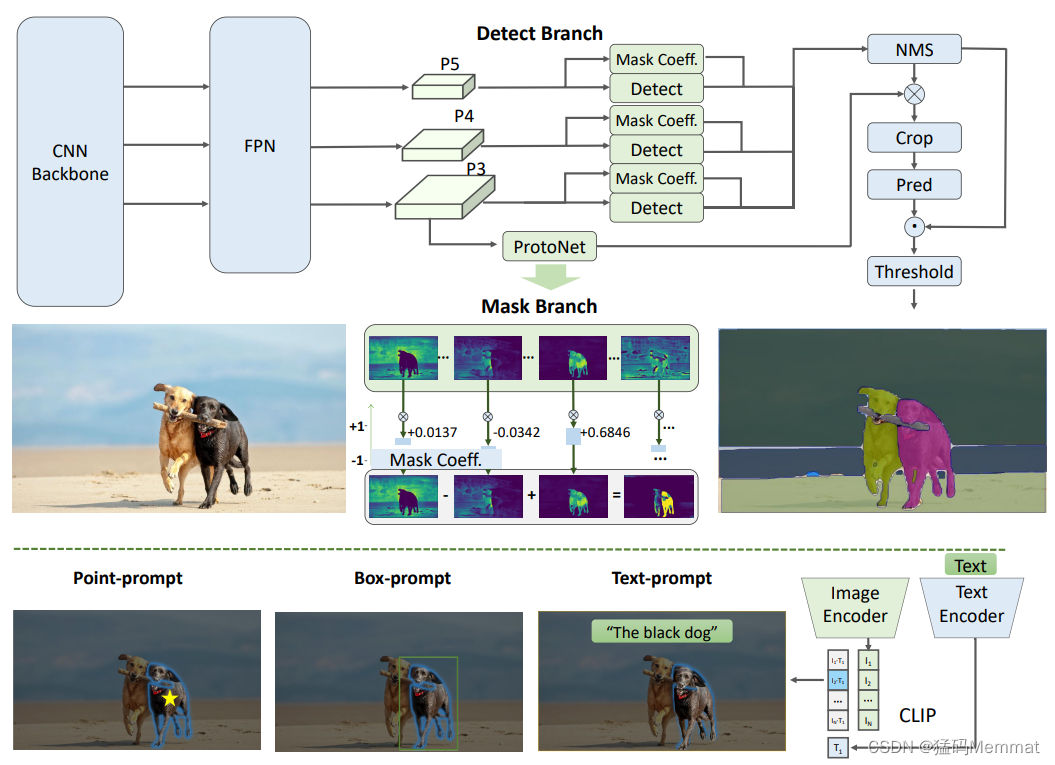
The detection branch outputs categories and bounding boxes, while the segmentation branch outputs k prototypes (default 32 in FastSAM) and k mask coefficients. Segmentation and detection tasks are computed in parallel. The segmentation branch inputs high-resolution feature maps that preserve spatial details and also contain semantic information. This map is processed through a convolutional layer, amplified, and then output as a mask through two more convolutional layers. Mask coefficient, similar to the classification branch of the detector, ranges between -1 and 1. Instance segmentation results are obtained by multiplying the mask coefficients with the prototype and then adding them.
from fastsam import FastSAM, FastSAMPrompt
model = FastSAM('./weights/FastSAM.pt')
IMAGE_PATH = './images/dogs.jpg'
DEVICE = 'cpu'
everything_results = model(IMAGE_PATH, device=DEVICE, retina_masks=True, imgsz=1024, conf=0.4, iou=0.9,)
prompt_process = FastSAMPrompt(IMAGE_PATH, everything_results, device=DEVICE)
# everything prompt
ann = prompt_process.everything_prompt()
# bbox default shape [0,0,0,0] -> [x1,y1,x2,y2]
ann = prompt_process.box_prompt(bbox=[[200, 200, 300, 300]])
# text prompt
ann = prompt_process.text_prompt(text='a photo of a dog')
# point prompt
# points default [[0,0]] [[x1,y1],[x2,y2]]
# point_label default [0] [1,0] 0:background, 1:foreground
ann = prompt_process.point_prompt(points=[[620, 360]], pointlabel=[1])
prompt_process.plot(annotations=ann,output_path='./output/dog.jpg',)
3.2 All-instance Segmentation

3.3 Prompt-guided Selection
After successfully segmenting all objects or regions in an image using YOLOv8, the second stage of the task of segmenting any object is to use various cues to identify specific objects of interest. It mainly involves the use of point prompts, box prompts and text prompts.
The Point prompt consists of matching selected points with various masks obtained from the first stage. The goal is to determine the mask where the point lies. Similar to SAM, we use front ground/background points as cues in our method. In situations where foreground points are located in multiple masks, background points can be exploited to filter out masks that are irrelevant to the task at hand. By using a set of foreground/background points we are able to select multiple masks within the area of interest. These masks will be combined into a single mask to completely mark the object of interest. Additionally, we utilize morphological operations to improve the performance of mask merging.
Box promptThe box prompt involves performing an Intersection over Union (IoU) matching between the selected box and the bounding box corresponding to the various masks in the first stage. The aim is to identify the mask with the highest IoU score with the selected box, thereby selecting the object of interest.
Text promptIn the case of text prompts, the corresponding text embedding of the text is extracted using the CLIP model. The corresponding image embedding is then determined and matched to the intrinsic features of each mask using a similarity measure. The mask with the highest similarity score to the image embedding of the text prompt is then selected.
By carefully implementing these cue-guided selection techniques, FastSAM can reliably select specific objects of interest from segmented images. The above method provides an effective method to complete any segmentation task in real time, thereby greatly improving the practicality of the YOLOv8 model in complex image segmentation tasks. A more efficient on-the-fly guided selection technique is left for future exploration.
3.3.1 CLIP
clip.py
import hashlib
import os
import urllib
import warnings
from typing import Any, Union, List
from pkg_resources import packaging
import torch
from PIL import Image
from torchvision.transforms import Compose, Resize, CenterCrop, ToTensor, Normalize
from tqdm import tqdm
from .model import build_model
from .simple_tokenizer import SimpleTokenizer as _Tokenizer
try:
from torchvision.transforms import InterpolationMode
BICUBIC = InterpolationMode.BICUBIC
except ImportError:
BICUBIC = Image.BICUBIC
if packaging.version.parse(torch.__version__) < packaging.version.parse("1.7.1"):
warnings.warn("PyTorch version 1.7.1 or higher is recommended")
__all__ = ["available_models", "load", "tokenize"]
_tokenizer = _Tokenizer()
_MODELS = {
"RN50": "https://openaipublic.azureedge.net/clip/models/afeb0e10f9e5a86da6080e35cf09123aca3b358a0c3e3b6c78a7b63bc04b6762/RN50.pt",
"RN101": "https://openaipublic.azureedge.net/clip/models/8fa8567bab74a42d41c5915025a8e4538c3bdbe8804a470a72f30b0d94fab599/RN101.pt",
"RN50x4": "https://openaipublic.azureedge.net/clip/models/7e526bd135e493cef0776de27d5f42653e6b4c8bf9e0f653bb11773263205fdd/RN50x4.pt",
"RN50x16": "https://openaipublic.azureedge.net/clip/models/52378b407f34354e150460fe41077663dd5b39c54cd0bfd2b27167a4a06ec9aa/RN50x16.pt",
"RN50x64": "https://openaipublic.azureedge.net/clip/models/be1cfb55d75a9666199fb2206c106743da0f6468c9d327f3e0d0a543a9919d9c/RN50x64.pt",
"ViT-B/32": "https://openaipublic.azureedge.net/clip/models/40d365715913c9da98579312b702a82c18be219cc2a73407c4526f58eba950af/ViT-B-32.pt",
"ViT-B/16": "https://openaipublic.azureedge.net/clip/models/5806e77cd80f8b59890b7e101eabd078d9fb84e6937f9e85e4ecb61988df416f/ViT-B-16.pt",
"ViT-L/14": "https://openaipublic.azureedge.net/clip/models/b8cca3fd41ae0c99ba7e8951adf17d267cdb84cd88be6f7c2e0eca1737a03836/ViT-L-14.pt",
"ViT-L/14@336px": "https://openaipublic.azureedge.net/clip/models/3035c92b350959924f9f00213499208652fc7ea050643e8b385c2dac08641f02/ViT-L-14-336px.pt",
}
def _download(url: str, root: str):
os.makedirs(root, exist_ok=True)
filename = os.path.basename(url)
expected_sha256 = url.split("/")[-2]
download_target = os.path.join(root, filename)
if os.path.exists(download_target) and not os.path.isfile(download_target):
raise RuntimeError(f"{
download_target} exists and is not a regular file")
if os.path.isfile(download_target):
if hashlib.sha256(open(download_target, "rb").read()).hexdigest() == expected_sha256:
return download_target
else:
warnings.warn(f"{
download_target} exists, but the SHA256 checksum does not match; re-downloading the file")
with urllib.request.urlopen(url) as source, open(download_target, "wb") as output:
with tqdm(total=int(source.info().get("Content-Length")), ncols=80, unit='iB', unit_scale=True, unit_divisor=1024) as loop:
while True:
buffer = source.read(8192)
if not buffer:
break
output.write(buffer)
loop.update(len(buffer))
if hashlib.sha256(open(download_target, "rb").read()).hexdigest() != expected_sha256:
raise RuntimeError("Model has been downloaded but the SHA256 checksum does not not match")
return download_target
def _convert_image_to_rgb(image):
return image.convert("RGB")
def _transform(n_px):
return Compose([
Resize(n_px, interpolation=BICUBIC),
CenterCrop(n_px),
_convert_image_to_rgb,
ToTensor(),
Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)),
])
def available_models() -> List[str]:
"""Returns the names of available CLIP models"""
return list(_MODELS.keys())
def load(name: str, device: Union[str, torch.device] = "cuda" if torch.cuda.is_available() else "cpu", jit: bool = False, download_root: str = None):
"""Load a CLIP model
Parameters
----------
name : str
A model name listed by `clip.available_models()`, or the path to a model checkpoint containing the state_dict
device : Union[str, torch.device]
The device to put the loaded model
jit : bool
Whether to load the optimized JIT model or more hackable non-JIT model (default).
download_root: str
path to download the model files; by default, it uses "~/.cache/clip"
Returns
-------
model : torch.nn.Module
The CLIP model
preprocess : Callable[[PIL.Image], torch.Tensor]
A torchvision transform that converts a PIL image into a tensor that the returned model can take as its input
"""
if name in _MODELS:
model_path = _download(_MODELS[name], download_root or os.path.expanduser("~/.cache/clip"))
elif os.path.isfile(name):
model_path = name
else:
raise RuntimeError(f"Model {
name} not found; available models = {
available_models()}")
with open(model_path, 'rb') as opened_file:
try:
# loading JIT archive
model = torch.jit.load(opened_file, map_location=device if jit else "cpu").eval()
state_dict = None
except RuntimeError:
# loading saved state dict
if jit:
warnings.warn(f"File {
model_path} is not a JIT archive. Loading as a state dict instead")
jit = False
state_dict = torch.load(opened_file, map_location="cpu")
if not jit:
model = build_model(state_dict or model.state_dict()).to(device)
if str(device) == "cpu":
model.float()
return model, _transform(model.visual.input_resolution)
# patch the device names
device_holder = torch.jit.trace(lambda: torch.ones([]).to(torch.device(device)), example_inputs=[])
device_node = [n for n in device_holder.graph.findAllNodes(