Table of contents
1. Program to implement Figure 6-1 and observe the characteristics
import numpy as np
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# https://blog.csdn.net/weixin_39228381/article/details/108511882
def func(x, y):
return x * x / 20 + y * y
def paint_loss_func():
x = np.linspace(-50, 50, 100) # x的绘制范围是-50到50,从改区间均匀取100个数
y = np.linspace(-50, 50, 100) # y的绘制范围是-50到50,从改区间均匀取100个数
X, Y = np.meshgrid(x, y)
Z = func(X, Y)
fig = plt.figure() # figsize=(10, 10))
ax = Axes3D(fig)
plt.xlabel('x')
plt.ylabel('y')
ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap='rainbow')
plt.show()
paint_loss_func()
Running results:
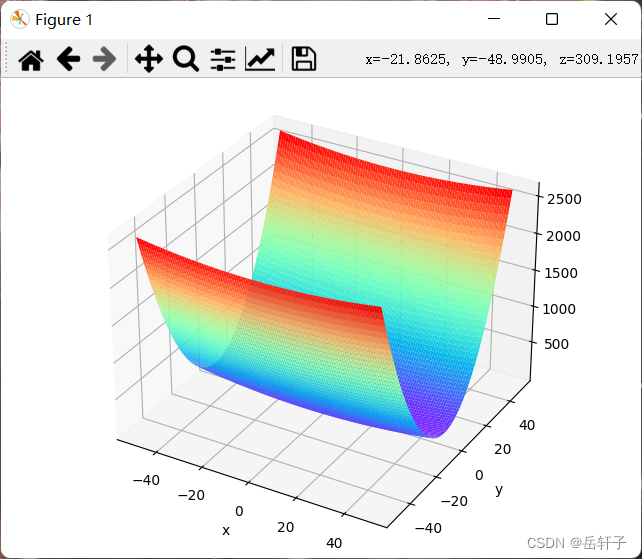
Features: There is a global minimum and it is a "bowl"-shaped function extending in the x-axis direction.
2. Observe the gradient direction
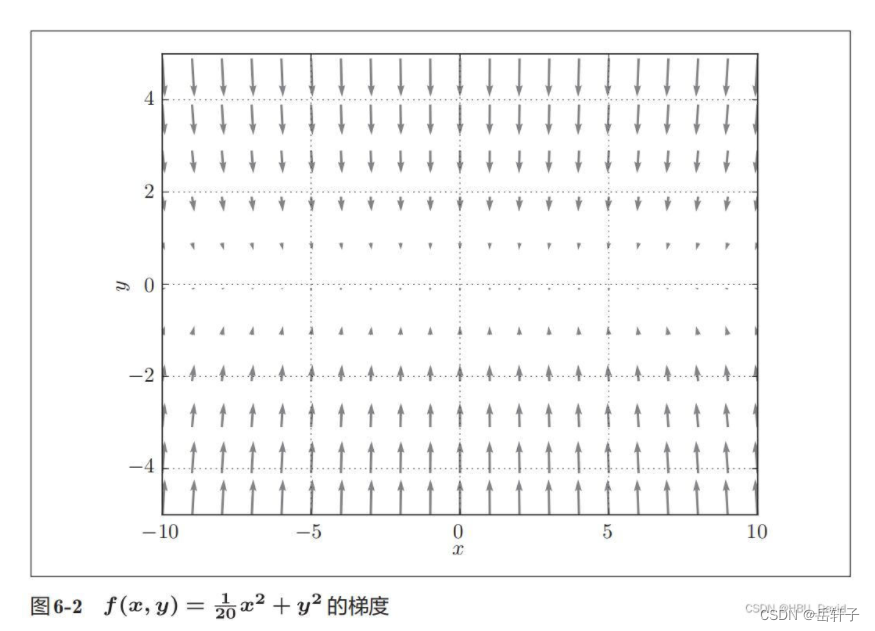
Features: The gradient in the Y-axis direction is large, and the gradient in the X-axis direction is small; the gradients at many positions do not point to the minimum position (0,0)
3. Write code to implement the algorithm and visualize the trajectory
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict
class SGD:
"""随机梯度下降法(Stochastic Gradient Descent)"""
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
class Momentum:
"""Momentum SGD"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {
}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
params[key] += self.v[key]
class Nesterov:
"""Nesterov's Accelerated Gradient (http://arxiv.org/abs/1212.0901)"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {
}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] *= self.momentum
self.v[key] -= self.lr * grads[key]
params[key] += self.momentum * self.momentum * self.v[key]
params[key] -= (1 + self.momentum) * self.lr * grads[key]
class AdaGrad:
"""AdaGrad"""
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {
}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class RMSprop:
"""RMSprop"""
def __init__(self, lr=0.01, decay_rate=0.99):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {
}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class Adam:
"""Adam (http://arxiv.org/abs/1412.6980v8)"""
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {
}, {
}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2 ** self.iter) / (1.0 - self.beta1 ** self.iter)
for key in params.keys():
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key] ** 2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
def f(x, y):
return x ** 2 / 20.0 + y ** 2
def df(x, y):
return x / 10.0, 2.0 * y
init_pos = (-7.0, 2.0)
params = {
}
params['x'], params['y'] = init_pos[0], init_pos[1]
grads = {
}
grads['x'], grads['y'] = 0, 0
optimizers = OrderedDict()
optimizers["SGD"] = SGD(lr=0.95)
optimizers["Momentum"] = Momentum(lr=0.1)
optimizers["AdaGrad"] = AdaGrad(lr=1.5)
optimizers["Adam"] = Adam(lr=0.3)
idx = 1
for key in optimizers:
optimizer = optimizers[key]
x_history = []
y_history = []
params['x'], params['y'] = init_pos[0], init_pos[1]
for i in range(30):
x_history.append(params['x'])
y_history.append(params['y'])
grads['x'], grads['y'] = df(params['x'], params['y'])
optimizer.update(params, grads)
x = np.arange(-10, 10, 0.01)
y = np.arange(-5, 5, 0.01)
X, Y = np.meshgrid(x, y)
Z = f(X, Y)
# for simple contour line
mask = Z > 7
Z[mask] = 0
# plot
plt.subplot(2, 2, idx)
idx += 1
plt.plot(x_history, y_history, 'o-', color="red")
plt.contour(X, Y, Z) # 绘制等高线
plt.ylim(-10, 10)
plt.xlim(-10, 10)
plt.plot(0, 0, '+')
plt.title(key)
plt.xlabel("x")
plt.ylabel("y")
plt.subplots_adjust(wspace=0, hspace=0) # 调整子图间距
plt.show()
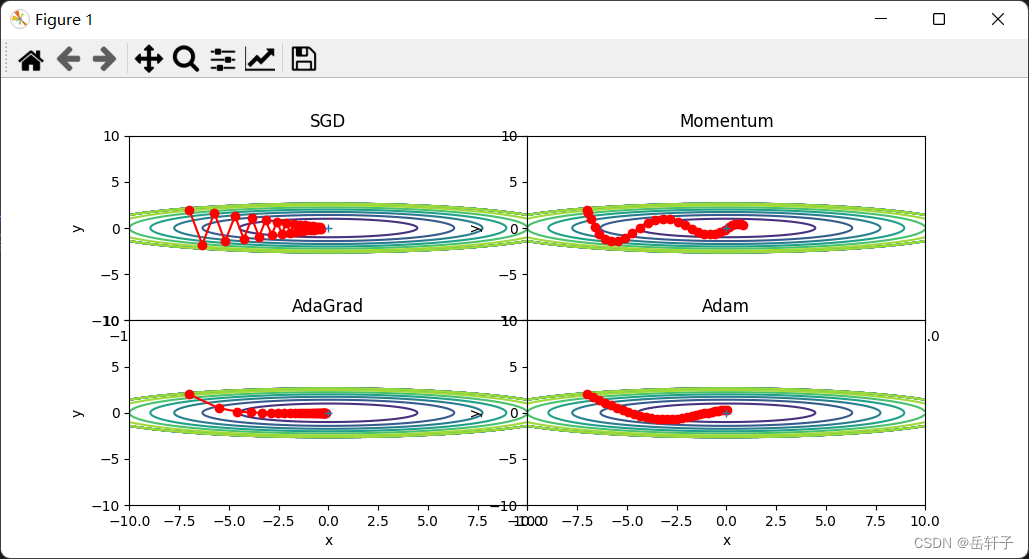
The order of convergence effects is AdaGrad, Adam, Momentum, and SGD.
4. Analyze the above picture and explain the principle (optional)
1) Why does SGD follow a "zigzag" pattern? Why are other algorithms smoother?
This is because the changes in the image are not uniform, so when the y direction changes greatly, the x direction changes very little, and we can only search in a roundabout way, which is very inefficient.
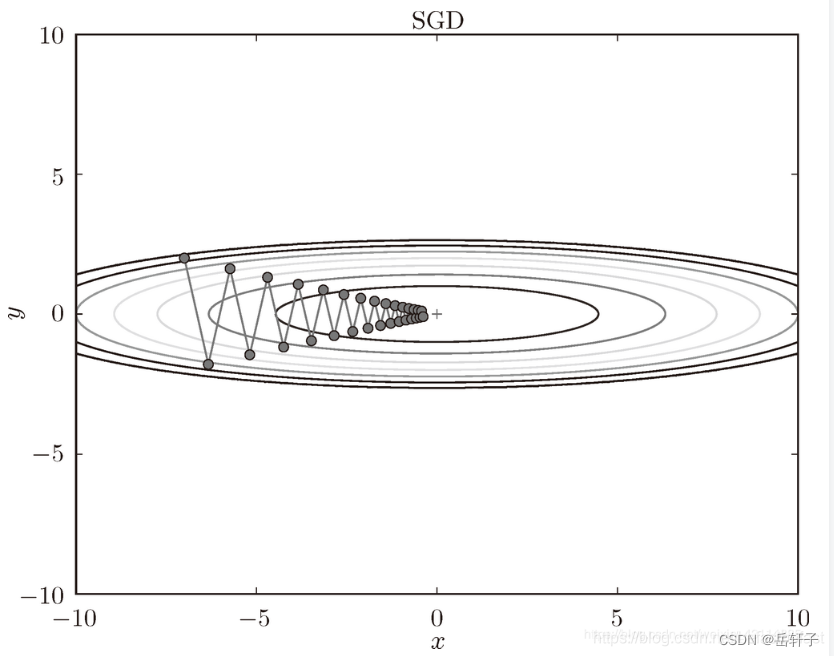
2) How are Momentum and AdaGrad’s improvements to SGD reflected? speed? direction? What is reflected in the picture?
SGD
SGD is one of the most common optimization methods in deep learning. Although it is the most commonly used optimization method, it has many common problems.
The learning rate is difficult to determine. If it is chosen too small, the convergence speed will be very slow. If it is too large, the loss function will continue to oscillate or even deviate from the minimum value. The learning rate of each parameter is the same. If the data is sparse, features with low frequency are expected to be updated larger. The reason why deep neural networks are difficult to train is not because it is easy to enter the local minimum, but because the learning process is easy to enter the saddle surface. In this area, the gradient values in all directions are almost 0.
Momentum(momentum)
Momentum draws on the concept of momentum in physics, that is, the gradients of previous times will also participate in the calculation. In order to represent momentum, a new variable V is introduced. V is the accumulation of previous gradients, but there will be a certain attenuation at each round. Its characteristic is that it can accelerate learning when the front and rear gradient directions are inconsistent, and it can suppress oscillation when the front and rear gradient directions are consistent.

Adagrad
In the above-mentioned optimization algorithm, the step sizes of parameters are all the same, so can different step sizes be set for different constants? For parameters with large gradients, set a small step size, and for parameters with small gradients, set a large step size. step length. Just like on a gentle slope, we can move forward in long steps, but on a steep slope, we need to move forward in small steps. Adagrad refers to this idea.
