I gave a report at the Flash Memory Summit a few days ago. Many friends wanted to talk about it again, so I sorted it out.
2023 : Latest development and trend analysis of generative AI and storage (Part 1)
Chen Xuefei, storage committee member of Shanghai Computer Federation
The craze of generative AI has swept the world in a short period of time, and it has quickly emerged in an unstoppable trend. At a certain period of time, it seemed that "except for the IT industry, everyone is an AI expert". It’s been more than half a year since this round of nationwide AI craze broke out in full swing. After the initial fireworks have dissipated, what will the situation be like now?
1 . Countdown to the collapse of unicorn OpenAI? !

In August 2023, the Indian media Analytics India Magazine published a report claiming that OpenAI may go bankrupt by the end of 2024 for three reasons: rapid loss of users after peaking, high operating costs of US$700,000 per day, and open source competitors such as Llama2 strong pressure. (The 11 billion Microsoft investment should be able to shatter this rumor. Based on the annual operating cost of 250 million, it can still support it for 40 years, but the premise is that Microsoft’s investment has indeed been received and there are no withdrawal conditions such as performance appraisals). At the same time, the saying "ChatGPT has become stupid" has also been circulated on the Internet. Some users said that the feedback given by AI is not as amazing as it was at the beginning. Sometimes there are some fallacies buried in the answers, and sometimes it is even so serious that industry users think it is "impossible". use". In addition, compared with GPT-3.5, some people believe that GPT-4 does not bring about a qualitative improvement in accuracy. According to experts from the regulatory evaluation agency News Guard, it has actually declined, especially the ability to identify false information. Finally, whether it is GPT-3.5 or GPT-4, privacy protection technology has not made significant progress, and this is also an important issue that cannot be avoided in large-scale applications.

Figure 1: OpenAI monthly user visits
2. Does the large model reach the ceiling?
Some industry experts believe that by GPT-4, the current large models may have reached the end of their growth. Technically speaking, there are two problems that are unavoidable: First, the exhaustion of corpus is an important reason. "These are the only outstanding resources created in human history." Although the total amount of network data of various UGC and MGC is still increasing at all times. However, most of them do not bring new information. Instead, they are filled with a large amount of useless and even misleading information, making it difficult to find true insights. Regardless of OpenAI, Google or Meta, there is no fundamental difference in quantity or quality in the data corpus used to train large models. The second is the technical limitation of the model itself. Simply pursuing scale improvement seems to have diminishing effectiveness. Yann LeCun, chief artificial intelligence scientist at Meta, proposed: "The generative artificial intelligence technology behind ChatGPT has entered a dead end, and there are too many limitations to overcome it." breakthrough". Even if GPT-5 appears, it will not bring about disruptive evolution. This Turing Award winner from France is the father of CNN and one of the three giants of deep learning. He may also be one of the people who knows the most about AI on the planet. But there are also many players that continue to insist on growing in scale. For example, Google plans to release the next-generation large model Gemini in the fall. It is said that the number of parameters will double.
3. How fierce is the competitive landscape?
The competition for the head of general large models is very fierce. First, Google launched the challenge with LaMDA, PaLM, and PaLM 2, and then Meta’s Llama 2. OpenAI’s strong competitors have always been there, and there is no obvious gap in performance in all aspects. . Although the company has Open in its name, due to various pressures, OpenAI chose to provide services in a closed-source and fee-based manner. Meta quickly launched an effective attack using open source and customizable tools, which forced OpenAI to It was announced that GPT-3.5 supports customization, and some tests have shown that the fine-tuned GPT-3.5 Turbo version can even surpass GPT-4 in some tasks.
In May 2023, Google internal documents were leaked, "We have no moat, and neither does OpenAI." Two months later, an analysis material in July 23 pointed out that GPT-4 is technically replicable. In the future, China and the United States Major Internet companies and leading AI companies in both countries will be able to build models that are the same as or even better than GPT-4.
OpenAI trained GPT-4 with a FLOPS of about 2.15e25. It was trained on about 25,000 A100s for three months (and then fine-tuned for another 6 months), and the utilization rate was between 32% and 36%. The cloud infrastructure used by OpenAI for training costs about US$1 per A100 hours. Based on this calculation, the training cost alone is approximately US$63 million. This is a high threshold for small companies, and it does not take into account whether they can build such a large-scale hardware facility, including the continued shortage of GPU cards and data center resources.
However, Moore's Law in the IT industry has not completely expired. The passage of time will still bring higher performance and lower costs. In the second half of 2023, the cloud infrastructure with better performance H100 as the main force will already have higher Cost-effectiveness, calculated at US$2/H100 hours, the same scale of pre-training can be performed on approximately 8,192 H100s and only takes 55 days to complete. In this way, the cost is reduced to US$21.5 million, which is approximately 1/3 of the forerunner OpenAI. .
By the end of 23, it is estimated that at least 9 companies will have clusters of the same size or above (for example, Meta will have more than 100,000 H100s by the end of December), and competitors are already eyeing it. If you have to look for OpenAI's moat, there may be three points to consider: feedback from real users, the industry's top engineering talents, and its current industry-recognized leadership position.
From a personal analysis, I think the competitive situation of the general large model will be very similar to the search engine years ago. Although it may not necessarily be a strict winner-takes-all situation, it is not far away. Most of the last remaining general large-model players in the market are just a few giants: a leader that can give the most accurate answers and the strongest capabilities, and no more than three chasers. The latter may only be of greater significance to users. Just multiple options. Of course, industry large models or vertical large models are another matter, and will not be discussed here for the time being.
4. AI development trajectory: sharpening three swords in ten years
Starting from the breakthrough of computer graphics recognition technology in 2012, to Alpha GO in 2016, and then to the emergence of ChatGPT at the end of 2022, AI technology has moved from small data and small models to the era of big data, big models and large computing power.

After 10 years, we have started from weak artificial intelligence that can only complete specific tasks, and are getting closer and closer to strong artificial intelligence. From deep convolutional neural network technology to deep reinforcement learning to large models, from perception to decision-making to generation and action, the industry Nowadays, a new term "intelligent agent" is used to refer to AI.
Today's large models are very close to strong artificial intelligence (also called general artificial intelligence, AGI), which has multiple capabilities and is even close to theoretical full capabilities. Assuming that it can continue to develop smoothly, the next stage of super artificial intelligence can theoretically surpass the current level of human beings and reach the boundary that has never been touched. The unknown will bring fear. How will humans get along with it then? When I attended the World Artificial Intelligence Conference in 2019, I heard another Turing Award winner, Professor Raj Reddy of CMU, propose a model: GAT (Comprehensive Intelligent Assistant). His idea is to let super artificial intelligence assist cutting-edge scientific breakthroughs, and then teach us new knowledge, thus assisting the progress of human civilization. He hopes that the final development will be as he wishes.
5. Large model framework and basic process
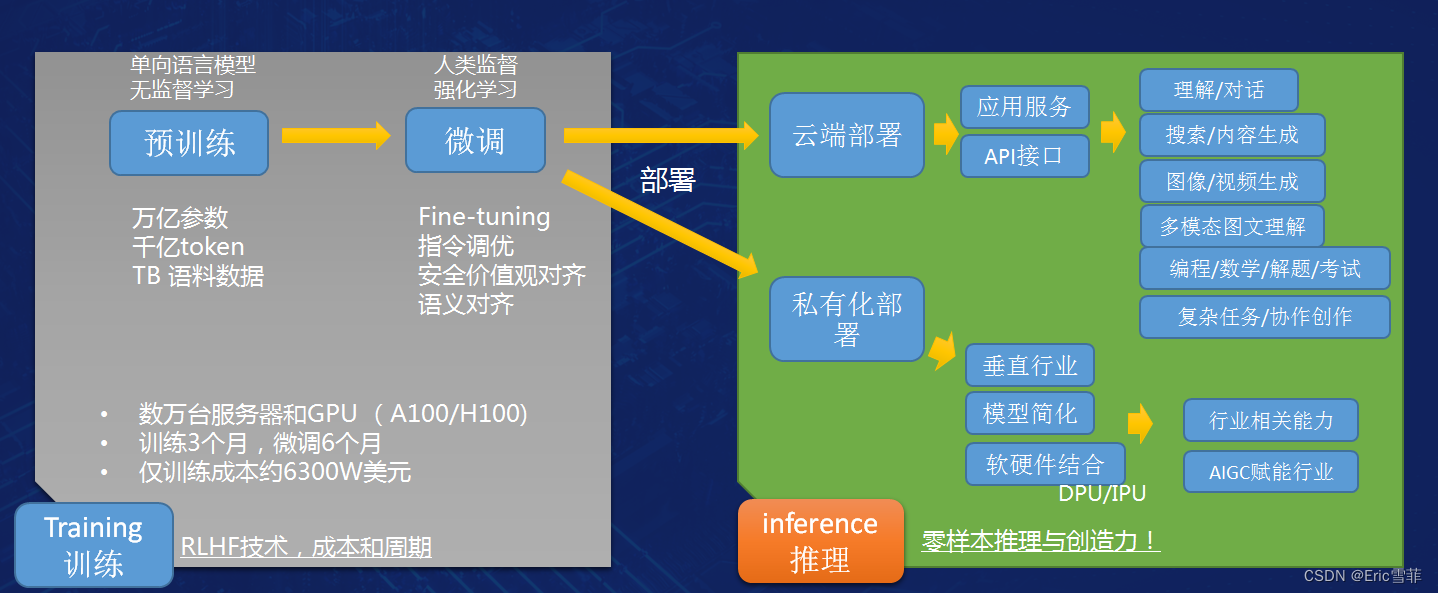
Large models require three elements, software algorithms, huge GPU clusters and data sets for training, followed by a lot of engineering work. If you do not consider the data collection and data cleaning in the early preparation stage, building a large model can be roughly divided into two steps: training and inference (work): forming comprehensive capabilities through effective training, and then providing them to users in the inference stage (including The chat application ChatGPT answers various questions and provides various help).
Sorted in order of complexity from easy to difficult, the capabilities of large models include understanding, dialogue, search, text content generation, image and video generation, multi-modal graphics and text understanding, as well as subject examinations, programming, complex task completion, and Assist humans in various types of complex creations.
The first training phase is usually divided into pre-training and subsequent fine-tuning phases, with OpenAI as the observation object. Until GPT-4, the data used in the pre-training phase is mainly based on a large amount of text information. In the supervised learning method, a model with up to 1.8 trillion parameters is input for training. As mentioned above, OpenAI used 25,000 A100 cards and 3 months to complete the training, followed by 6 months of fine-tuning work. Needs to be done.
Fine-tuning technology is mostly used in the fine-tuning phase, and an important link is RLHF (Reinforcement Learning with Human Feedback), which is reinforcement learning based on human feedback. RLHF solves a core problem of generative models, how to make the output of artificial intelligence models consistent with human common sense, cognition, needs, and values. Simply put, it is to correct the three views on AI, eliminate deviance, and solve the so-called "large model illusion" problem.
The completion of the above training phase is basically 80% done. Next, we need to consider different deployment methods and continue to optimize based on later user feedback. OpenAI adopts cloud deployment and provides ChatGPT users with direct access to application interfaces and integrable API interfaces. Other third parties such as Microsoft can integrate through APIs and call large models in their own software or cloud services to provide users with different capabilities. and applications such as Copilot (recently, "well-known Internet celebrity mathematician" Terence Tao has made an impression on how easy to use the VSCode plug-in + Copilot was. GPT4 was also great to help him program in the past), and domestic manufacturers such as Baidu that lay out general large-scale cloud models also provide APIs Integrated mode. In addition, some domestic manufacturers are more willing to choose privatized deployment for vertical industries, usually with less than a few dozen nodes, providing only one or two types of AI assistance capabilities for specific industries, so that the model can be simplified and does not have to be large and comprehensive. Therefore, you will see many domestic manufacturers claiming that they have released many large models, which are usually "small models" for vertical industries. Strictly speaking, they still fall into the category of weak artificial intelligence. This type of application is not only small in scale, but can also be combined with software and hardware and deployed to the edge. It is an easier-to-implement AI-empowered industry model and is also a segmented track targeted by a large number of startups.
6. Frontier trends in generative AI technology
After understanding the basic framework, let’s take a look at the latest trends in the industry.
The current round of AI technology development is basically as follows: CNN –> RNN->LSTM->RNN/LSTM +Attention -> Transformer. (For example, in the field of typical AI application machine translation, several important stages are: Simple RNN - > Contextualize RNN -> Contextualized RNN with attention -> Transformer)
At present, the mainstream large models in the industry are basically developed under the Transformer framework. It was a technology proposed in 2017, and the currently popular GPT is the abbreviation of Generative Pre-traning Transformer. It can be seen from the name that it has evolved a step further in technology. In addition to adding pre-training technology, another outstanding feature I observed is "horizontal expansion"

After years of development, the scale of the model has expanded rapidly, and depth calculation has gradually become "width calculation". Looking back at the ResNet-50 model popular in the industry in 2016, it only uses a neural network structure of about 50 layers and is supplemented by 20 million parameters. For training and inference; the industry-recognized best large model GPT-4 in 2023 uses 1.8 trillion parameters, while the number of neural network layers has only increased to 120 layers. The number of layers (depth) is only slightly more than doubled, but the number of parameters has increased by 900,000 times, which directly leads to a sharp expansion in the number (width) of cluster nodes. GPT-4 has used more than 20,000 GPU cards to complete the calculations required for training, so the industry joked that depth calculations have expanded into width calculations. (Note: B is 1 billion, so Transformer uses 110 million parameters, GPT-3 uses 175 billion parameters, and two popular domestic models, 65B and 130B, have 65 billion and 130 billion parameters respectively)
7. Five concerns about big models in 2023
The first is the size of the model .
When you think about the size of a large model, you'll see different measures: number of parameters, number of tokens, amount of data, and training cluster size. These concepts are all related to each other. First of all, the increase in the number of parameters is due to the evolution of software algorithms, which leads to the horizontal expansion of the architecture, and the number of nodes in the training cluster naturally increases significantly. After the architecture is expanded, more data sets can be used for training; token is a meta-segmentation of training data. When the amount of training data increases, the number of tokens will also increase, but it is not necessarily a linear relationship. Therefore, these four elements can measure and reflect the model scale from different dimensions.
By the second half of 2023, as mentioned earlier, the industry already has two views on the effects of blindly increasing scale: Some experts and companies believe that the diminishing marginal utility is obvious. For example, Meta believes that its The performance of the LLaMA 13 billion parameter version is already better than that of GPT-3 (175 billion parameters), and some smaller models in the industry, based on tens of billions or even billions of parameters, perform well and do not have to expand to hundreds of billions and trillions. That scale. The analysis document for GPT-4 in July also pointed out that after the parameter scale was expanded by more than 10 times compared to GPT-3, the problem of significant decline in large cluster utilization occurred. The industry used the term "bubble" to describe some The phenomenon that the GPU is not working at full capacity to catch fish, due to the phenomenon of "idling" of some computing power, has increased the cost of inference by about three times. This has also provided new material for critics of high energy consumption of AI represented by Musk.
The second focus is how to achieve better multi-dimensional parallelism .
Generative AI is a typical parallel computing application, and the higher the degree of parallelism, the more advantageous it is. Therefore, it is necessary to increase the degree of parallelism from multiple dimensions. Currently, multi-dimensional parallelism includes three parallel technologies: data parallelism, tensor parallelism and pipeline parallelism.
Data parallelism is relatively simple. One copy of the data is too large, so it is divided into multiple copies and placed on multiple computing nodes, allowing multiple GPUs to perform parallel calculations at the same time.
Tensor parallelism can be simply understood as a large model cannot fit on a single card, so it is cut open and multiple GPUs are used to speed up the process. The disadvantage of tensor parallelism is that the communication overhead in the middle is too high. The core idea of the widespread use of two-dimensional and three-dimensional tensor parallelism is to replace global serialization with more local serialization, and exchange more local communication for global communication, thereby reducing communication costs and improve efficiency. Nvidia's Jen-Hsun Huang also mentioned in his GTC 2021 speech that all tensor parallelism should be placed in the server to avoid cross-server communication overhead, which is not worth the gain. (Note: Tensor calculation is an important computing feature of large models. Tensor is a mathematical concept that is encountered in multilinear algebra. It has applications in physics and engineering. It can perform some mathematical operations, such as inner product. , the reduction and the multiplication of the matrix (the matrix is the second-order tensor, the vector is the first-order tensor, and the zero-order tensor is the scalar.) You can also perform slice extraction matrices, etc.)
The advantage of a tensor is that it is multi-dimensional and can contain more data in a tensor, making calculations more efficient.
Pipeline parallelism requires some clever trade-offs. It needs to consider the relationship between the number of layers and the number of GPUs. Some experts mentioned a metaphor. GPUs are like engineering teams. The task is to build many buildings. Each building has many layers. The number of pipeline layers is equivalent to floor number. 15 engineering teams build 1,000 buildings, and the theoretical parallelism can reach 15, making every GPU busy and eliminating fishing. Therefore, the trick to improving parallel efficiency is to increase the batch size and increase the ratio between the number of pipeline layers and the GPU.
It was pointed out in the GPT-4 analysis data in July that GPT-4 uses 8-channel tensor parallelism + 15-channel pipeline parallelism. One reason is that it is limited by the current situation of the GPU card’s maximum 8-channel NVlink. Another reason may be the A100’s 40GB video memory quantity.
Among the three parallel technologies, tensor parallelism is currently a focus of the industry. If it can be improved, it will bring greater help. In July 2023, Google announced the open source tensor computing library TensorNetwork and its API, claiming that the acceleration effect on GPU is a hundred times that of CPU. I believe many people in the industry are already trying it, but I haven’t seen any analysis or reports on the actual results.
The third focus is the mixed expert model (MoE) .
Unlike individual large models, including OpenAI, both Google and Microsoft use this new architecture. The basic idea of MoE is to combine multiple relatively small models, each becoming an expert in a certain part, and jointly provide external reasoning services. Only one or two models are used in each inference, which can effectively reduce the number of parameters and resources during inference. For example, Google's GlaM model uses a total of 1.2 trillion parameters, with 64 small neural networks inside. Only 2 are used during inference, which accounts for 8% of the parameters and 8% of the energy consumption. Analysis material from July showed that GPT-4 used 16 expert models, each with 1.1 trillion parameters. The reason why the number of expert models is much smaller than the theoretical optimal value of 64~128 is because OpenAI experts believe that too many expert models will hinder generalization and make it difficult to converge, which is detrimental to the goal of building a general-purpose large model.
In addition to the field of general large models, some vertical large models are also using the same idea, but using another term "large model routing". For example, when applying large models in low code, the concept of "routing" will be introduced with reference to Web programming. Many "small models" are created according to different scenarios and capabilities. For example, some models only make tables, and some models make charts, and the functions are split. When used, it will be decided based on the user's needs which "small models" are called, in what order, and finally complete the entire task. Although the nouns used are different, the design ideas are very similar.
When it comes to reasoning, "low-latency reasoning" has been clearly proposed as a term concept. It requires that the input and output response time be limited to an acceptable range. The model must output a certain number of tokens per second. As a user, humans need 30 tokens/ s is acceptable. In addition, considering that one call is one inference, the cost must also be controlled. The latest practice of inference optimization is "speculative sampling/decoding", which uses a small model to "draft" to generate N tokens, and then let the large model evaluate them. If they are acceptable, they will be used directly, and if they are not acceptable, they will be modified. This method can achieve exponential acceleration and reduce reasoning costs. It is said that both GPT-4 and Gemini, Google's next-generation large model expected to be released this fall, use this method, and Google has published relevant papers.
The fourth is the issue of memory management optimization .
Large models consume a lot of memory. The basic technology for the evolution of large models is the Transformer framework. First, parameters and gradients need to be placed in memory for calculation. Taking training GPT as an example, if calculated based on 1 trillion parameters, even if single precision is used, each parameter occupies 4 bytes, and the parameters alone will occupy 4T of memory, and the gradient will also occupy 4T of memory. Coupled with the core mechanism attention in this famous framework, it will produce exponential amplification on this base, and the total theoretical memory requirement will reach the PB level.
At present, there are some solutions in the memory optimization industry. The basic ideas usually have two directions. One is to reduce the memory overhead in software algorithms as much as possible, and the other is to minimize the movement of data, including between CPU and GPU, and between CPU and NVme hardware. .
The fifth focus is visual multimodality .
According to material analysis, OpenAI originally wanted to use visual model training from scratch in GPT-4, but due to various reasons, it finally took a step back. After first using text pre-training, it then used about 2 trillion tokens for fine-tuning . , forming the multi-modal capabilities of GPT-4 .
The next-generation model "GPT-5" plans to train the visual model from scratch. The data used to train the multi-modal model includes: "joint data" (LaTeX/text), web page screenshots, YouTube videos (sampling frames, and Run Whisper to obtain subtitles), the training data will contain a large amount of unstructured data. A rough estimate is that each token is 600 bytes, and the scale will be 150 times that of text.
OpenAI hopes that the next generation of successfully trained "autonomous agents" will not only have the capabilities of GPT4, but also be able to read web pages, transcribe content in images and videos, and also generate images and audio independently. (Not only Hollywood screenwriters, but also editors, editors, and post-producers are joining the protest now)
In addition to its application prospects, using visual data for training has the potential to produce a fundamental change.
So far, language and text are still the basic corpus for training general-purpose large models. All information obtained by GPT is still trapped in the "boundary of language." According to the famous assertion of the philosopher Wittgenstein, "The boundary of language is the boundary of thought." "For large models, language information limits them to the world of logic and text, making it impossible to perceive objective facts, and may lead to the philosophical illusion of a "brain in a vat". In comparison, static picture data can provide spatial structure information, while video data itself also contains temporal structure information. This information can help GPT further learn deeper basic rules such as causality, opening up a larger space of possibilities.
Of course, there is already the problem of "model phantom" based on textual corpus, which is the so-called "serious nonsense" situation that cannot be completely eliminated. From the current research, it seems that the problem of visual multi-modal phantom is more serious, and the parameters are more complex. Larger models such as the Lalma2 are more severely affected than smaller models such as the 7B. How to reduce phantoms more effectively is still an unsolved problem in the industry.
That’s it for AI. Let’s talk about storage later.
(to be continued)
2023.9