Table of contents
For example, when executing the following query statement:
mysql> select * from T where ID=10;
Schematic diagram of the basic architecture of MySQL
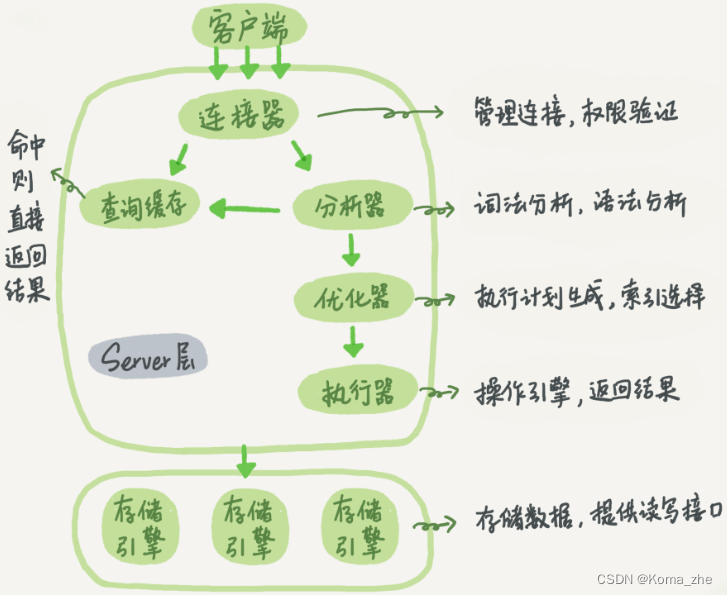
MySQL can be divided into two parts : Server layer and storage engine layer .
The Server layer includes connectors, query caches, analyzers, optimizers, executors, etc., covering most of MySQL's core service functions, as well as all built-in functions (such as date, time, mathematics and encryption functions, etc.), all across storage engines All functions are implemented in this layer, such as stored procedures, triggers, views, etc.
The storage engine layer is responsible for data storage and retrieval. Its architectural model is plug-in and supports multiple storage engines such as InnoDB, MyISAM, and Memory. The most commonly used storage engine now is InnoDB, which has become the default storage engine since MySQL 5.5.5. When creating create tablea table, if you do not specify the engine type, InnoDB will be used by default. create tableUse engine=memory, in the statement to specify the use of the memory engine to create the table. Different storage engines share a server layer , which is the part from connector to executor.
Connector
The connector is responsible for establishing a connection with the client, obtaining permissions, maintaining and managing the connection. The connection command is generally written like this:
mysql -h$ip -P$port -u$user -p
in the connection command mysqlis a client tool used to establish a connection with the server. After completing the classic TCP handshake, the connector will begin to authenticate the identity. This time, the username and password you entered will be used.
- If the username or password is incorrect, an "Access denied for user" error will be reported, and then the client program will end execution.
- If the username and password authentication is passed, the connector will check the permissions table to find out the permissions you have. After that, the permission judgment logic in this connection will depend on the permissions read at this time.
This means that after a user successfully establishes a connection, even if you use the administrator account to modify the user's permissions, it will not affect the permissions of the existing connection. After the modification is completed, only new connections will use the new permission settings.
After the connection is completed, if there is no subsequent action, the connection will be in an idle state, show processlistwhich can be seen in the command. The line whose Command column displays "Sleep" indicates that there is an idle connection in the system.

If the client is inactive for too long, the connector will automatically disconnect it. This time is wait_timeoutcontrolled by parameter, the default value is 8 hours. After disconnecting, if the client sends a request again, it will receive an error reminder: Lost connection to MySQL server during query. If you want to continue at this time, you need to reconnect and then execute the request.
In the database, a long connection means that after the connection is successful, if the client continues to make requests, the same connection will always be used. A short connection means that the connection is disconnected after a few queries are executed, and a new one is re-established for the next query. It is recommended to minimize the action of establishing a connection during use, that is, try to use long connections.
After all long connections are used , sometimes the memory occupied by MySQL increases very quickly. This is because the memory temporarily used by MySQL during execution is managed in the connection object. These resources will be released when the connection is disconnected. Therefore, if long connections accumulate, they may occupy too much memory and be forcibly killed by the system (OOM). Judging from the phenomenon, MySQL restarts abnormally .
- Disconnect long connections regularly . After using it for a period of time, or after the program determines that a large query that takes up memory has been executed, the connection is disconnected, and then the query is required and then reconnected.
- If you are using MySQL 5.7 or newer, you can reinitialize the connection resources
mysql_reset_connectionby executing each time after performing a relatively large operation . This process does not require reconnection and permission verification, but will restore the connection to the state when it was just created.
Query cache
After the connection is established, you can execute the select statement. The execution logic will come to: query cache.
After MySQL gets a query request, it will first go to the query cache to see if this statement has been executed before. Previously executed statements and their results may be key-valuecached directly in memory in the form of pairs. keyIt is the query statement and valuethe result of the query. If the query can be found directly in this cachekey , then this valuewill be returned directly to the client.
If the statement is not in the query cache , the execution phase continues. After the execution is completed, the execution results will be stored in the query cache. If the query hits the cache, MySQL can directly return the result without performing subsequent complex operations, which is very efficient.
Query cache failures are very frequent . As long as there is an update to a table , all query caches on this table will be cleared unless your business has a static table that will only be updated for a long time.
MySQL provides this " use on demand " approach. The parameters can be query_cache_typeset DEMANDso that the query cache is not used for the default SQL statements . For statements that you are sure you want to use the query cache, you can SQL_CACHEspecify it explicitly, like the following statement:
mysql> select SQL_CACHE * from T where ID=10;
Note : MySQL version 8.0 directly deletes the entire query cache function, which means that this function is completely missing from 8.0.
Analyzer
If the query cache is not hit, the actual execution of the statement begins. First, MySQL needs to parse the SQL statement.
The analyzer will first do " lexical analysis ". Then do " grammatical analysis ". Based on the results of lexical analysis, the syntax analyzer will determine whether the SQL statement you entered satisfies MySQL syntax based on grammatical rules. If the statement is incorrect, you will receive You have an error in your SQL syntaxan error reminder of " ".
optimizer
Before execution begins, it must be processed by the optimizer .
The optimizer determines which index to use when there are multiple indexes in the table ; or when a statement has a **multi-table association (join)**, it determines the connection order of each table . For example:
mysql> select * from t1 join t2 using(ID) where t1.c=10 and t2.d=20;
- You can first retrieve the ID of the record c=10 from table t1, then associate it to table t2 based on the ID, and then determine whether d in t2 is equal to 20.
- You can also first take out the ID of the record d=20 from table t2, then associate it to t1 based on the ID, and then determine whether c in t1 is equal to 10.
The logical results of the two execution methods are the same, but the execution efficiency will be different, and the role of the optimizer is to decide which solution to use. After the optimizer phase is completed, the execution plan of this statement is determined , and then enters the executor phase.
Actuator
When starting the execution, you must first determine whether you have permission to execute the query on table T. If not, an error of no permission will be returned, as shown below (if the query cache is hit, when the query cache returns the results, do Permission verification. The query will also be called before the optimizer to precheckverify permissions)
mysql> select * from T where ID=10;
ERROR 1142 (42000): SELECT command denied to user 'b'@'localhost' for table 'T'
If you have permission, open the table and continue execution. When a table is opened, the executor will use the interface provided by the engine based on the table's engine definition .
For example, in the table T in the example, ID does not have an index, then the execution flow of the executor is as follows:
- Call the InnoDB engine interface to get the first row of this table and determine whether the ID is 10. If not, skip it. If so, store this row in the result set.
- Call the engine interface to get the "next row" and repeat the same judgment logic until the last row of the table is fetched.
- The executor returns a record set composed of all rows that meet the conditions during the above traversal process to the client as a result set .
For tables with indexes, the execution logic is similar. The first call is the " get the first line that meets the condition " interface, and then it loops to get the " next line that meets the condition " interface. These interfaces have been defined in the engine.
You will see a field in the slow query log of the database , indicating how many rows were scannedrows_examined during the execution of this statement . This value is accumulated every time the executor calls the engine to obtain a data row. In some scenarios, the executor is called once and multiple rows are scanned inside the engine, so the number of rows scanned by the engine and rows_examined are not exactly the same.
Important log module: redo log
Starting with the update statement, the following is the creation statement of this table. This table has a primary key ID and an integer field c
mysql> create table T(ID int primary key, c int);
If you want to add 1 to the value of the row ID=2
mysql> update T set c=c+1 where ID=2;
If every update operation needs to be written to the disk, and the disk must find the corresponding record before updating, the IO cost and search cost of the entire process will be very high. In order to solve this problem, MySQL uses an idea similar to the hotel shopkeeper's pink board to improve update efficiency.
The whole process of the cooperation between the pink board and the ledger is actually WALa technology often mentioned in MySQL. WALIts full name is that Write-Ahead Loggingits key point is to write the log first and then write to the disk , that is, write the pink board first and then write Ledger .
When a record needs to be updated, the InnoDB engine will first write the record to the redo log ( pink board ) and update the memory. At this time, the update is completed. At the same time, the InnoDB engine will update the operation record to the disk at the appropriate time , and this update is often done when the system is relatively idle, just like what the shopkeeper does after closing.
But if there are a lot of credit accounts on a certain day and the pink board is full , the shopkeeper will have to put down what he is doing, update some of the credit records in the pink board to the ledger, and then erase these records from the pink board to prepare for Keep new accounts to make room. InnoDB's redo log has a fixed size. For example, it can be configured as a set of 4 files, and the size of each file is 1GB. Then this " pink board " can record a total of 4GB operations. Start writing from the beginning, write to the end, then go back to the beginning and write in a loop.

write posIt is the position of the current record. It moves backward while writing. After writing to the end of file No. 3, it returns to the beginning of file No. 0. checkpointIt is the current position to be erased, and it also moves forward and circulates. Before erasing the record, the record must be updated to the data file.
write poscheckpointBetween and is the empty part of the " pink board " that can be used to record new operations . If it catches up , it means that the "pink board" is full, and no new updates can be performed at this time. You have to stop and erase some records first to push it forward.write poscheckpointcheckpoint
With redo log , InnoDB can ensure that even if the database restarts abnormally, previously submitted records will not be lost. This capability is called crash-safe . ( crash-safe : As long as the credit record is recorded on the pink board or written on the ledger, even if the shopkeeper forgets it later, such as suddenly suspending business for a few days, after resuming business, he can still clarify the credit account through the data in the ledger and pink board)
innodb_flush_log_at_trx_commit1When this parameter is set to , it means that the redo log of each transaction is directly persisted to the disk. This ensures that data will not be lost after MySQL restarts abnormally.
Important log module: binlog
The " pink board " redo log is a log unique to the InnoDB engine , and the server layer also has its own log, called binlog (archived log) .
Initially, there was no InnoDB engine in MySQL. MySQL's own engine is MyISAM, but MyISAM does not have crash-safe capabilities, and binlog logs can only be used for archiving. InnoDB was introduced to MySQL in the form of a plug-in by another company. Since relying only on binlog does not have crash-safe capabilities, InnoDB uses another log system, that is, redo log, to achieve crash-safe capabilities.
These two logs have the following three differences.
- The redo log is unique to the InnoDB engine ; the binlog is implemented by the Server layer of MySQL and can be used by all engines.
- Redo log is a physical log , which records "what modifications were made on a certain data page"; binlog is a logical log , which records the original logic of the statement, such as "add 1 to the c field of the row with ID=2" .
- The redo log is written in a loop , and the space will always be used up; the binlog can be written additionally . "Append writing" means that after the binlog file reaches a certain size, it will switch to the next one and will not overwrite the previous log.
The internal flow of the executor and the InnoDB engine when executing this simple update statement.
- The executor first looks to the engine to get
ID=2this line. ID is the primary key , and the engine directly uses tree search to find this row. If the data page where the row with ID=2 is located is already in the memory, it will be returned directly to the executor; otherwise, it needs to be read into the memory from the disk first and then returned. - The executor gets the row data given by the engine, adds 1 to this value, for example, it used to be N, but now it is N+1, gets a new row of data, and then calls the engine interface to write this new row of data.
- The engine updates this new row of data into the memory and records the update operation into the redo log . At this time, the redo log is in
preparestate. Then inform the executor that the execution is completed and the transaction can be submitted at any time. - The executor generates a binlog of this operation and writes the binlog to disk.
- The executor calls the engine's commit transaction interface, and the engine changes the redo log just written to the commit (
commit) state, and the update is completed.
The execution flow chart of the update statement. The light box in the figure indicates that it is executed inside InnoDB , and the dark box indicates that it is executed in the executor .
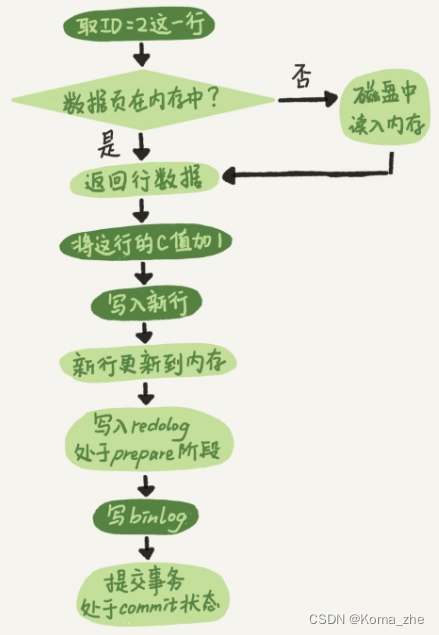
The last three steps seem a bit "convoluted". The writing of redo log is divided into two steps: prepareand commit. This is the " two-phase commit ".
sync_binlog1When this parameter is set to , it means that the binlog of each transaction is persisted to disk. This ensures that the binlog will not be lost after MySQL restarts abnormally.
When updating, redo log and binlog are submitted in two stages.
Two-phase commit is to make the logic between the two logs consistent .
When you need to restore to a specified second, for example, at two o'clock in the afternoon one day, you find that a table was accidentally deleted at noon, and you need to retrieve the data, you can do this:
- First, find the most recent full backup. If you are lucky, it may be a backup from last night. Restore from this backup to the temporary database.
- Then, starting from the backup time point, take out the backup binlog in sequence and replay it to the moment before the table was accidentally deleted at noon.
Why logs require "two-phase commit":
Since redo log and binlog are two independent logics, if two-stage submission is not used, either the redo log must be written first and then the binlog , or the reverse order must be adopted. What will be the problem. Assume that the value of field c in the current row with ID=2 is 0, and suppose that during the execution of the update statement, after the first log is written, a crash occurs before the second log is written. What will happen:
-
Write redo log first and then binlog . Suppose that the MySQL process restarts abnormally when the redo log is written but before the binlog is written. As we said before, after the redo log is written, even if the system crashes, the data can still be restored, so the value of c in this line after recovery is 1.
However, since the binlog crashed before it was finished, this statement was not recorded in the binlog at this time. Therefore, when the log is backed up later, this statement will not be included in the saved binlog.
If you need to use this binlog to restore the temporary library, because the binlog of this statement is lost, the temporary library will not be updated this time. The value of c in the restored row is 0, which is different from the value of the original library. -
Write binlog first and then redo log . If there is a crash after the binlog is written, since the redo log has not been written yet, the transaction will be invalid after the crash recovery, so the value of c in this line is 0. But the log "Change c from 0 to 1" has been recorded in the binlog. Therefore, when binlog is used to restore later, one more transaction will come out. The value of c in the restored row is 1, which is different from the value in the original database.
It can be seen that if " two-phase commit " is not used , the state of the database may be inconsistent with the state of the library restored using its log .
When it is necessary to expand the capacity, that is, when it is necessary to build more backup databases to increase the read capacity of the system , the common practice now is to use full backup and apply binlog to achieve this. This "inconsistency" will lead to online problems . Inconsistency between master and slave databases .
Simply put, both redo log and binlog can be used to represent the commit status of a transaction, and two-phase commit is to keep the two states logically consistent.