AIGC's wind has finally reached the field of speech generation recently. In the video above, "Stefanie Sun" covers Jay Chou's "Qili Xiang". The song is sung by AI, not Stefanie herself. The core technology behind it comes from voice conversion, not voice cloning as we talked about before.
Voice conversion
Voice conversion, voice conversion, referred to as VC. Simply put, it is to convert one person's voice into another person's voice, retaining the content of speaking or singing. It can be seen that the input of the model is audio, unlike the TTS task, where the input is text. Generally, VC tasks include the following three modules, the content encoder that extracts information from audio, and the commonly used feature PPG. Now there are also self-supervised models to extract features such as Hubert; the second model is the acoustic model. This layer mainly combines audio features. The information is further encoded into acoustic features, such as mel features; in the third module, the vocoder upsamples the acoustic features into audio.
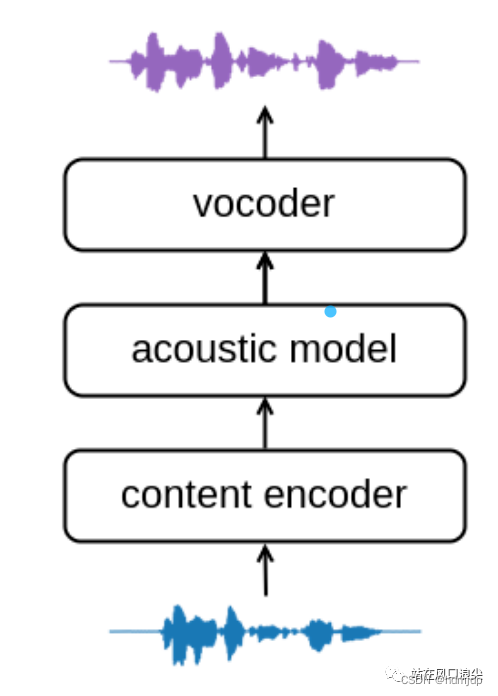
Sound conversion so-vits-svc based on hubert and vits
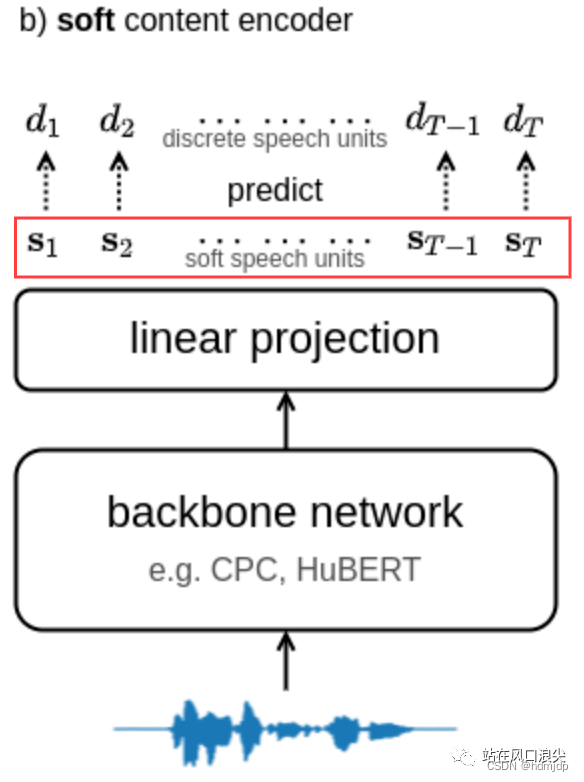
The following introduces the core technology behind AI Stefanie Sun, the full name of so-vits-svc is SoftVC VITS Singing Voice Conversion. This technology was modified by a sound enthusiast based on softVC and vits. The core change is to replace the previous PPG with hubert's soft encoding, and then send the information to vits. The soft hubert encoding can effectively remove speaker information while retaining content information. The essence is the output of a certain layer of the network, but some constraints are added during training to weaken the speaker information. The red line in the picture below is the soft content encoding.
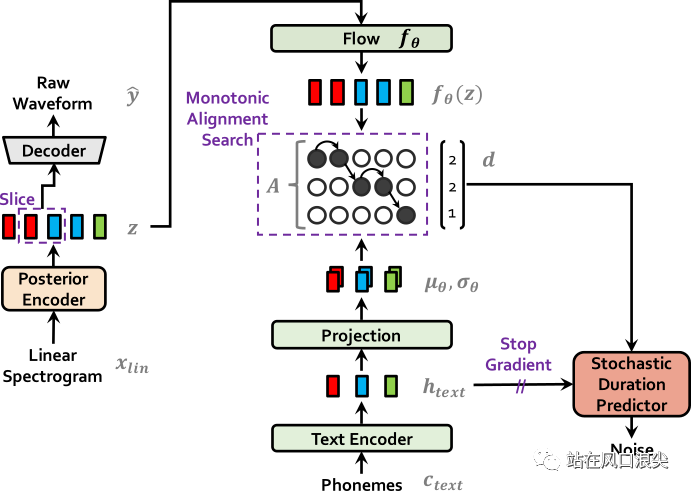
Vits is a very important model in TTS. This model binds the acoustic model and vocoder into a training framework, eliminating the need to train multiple times. VITS uses FLOW to introduce amplitude spectrum as posterior information, and uses MAS to automatically align phoneme durations. The training goal of the model is to directly learn the distribution of the latent variable z from the text. The flow model is reversible during inference. Synthesize WAV directly from text. The reasoning is that no posterior encoder is needed.
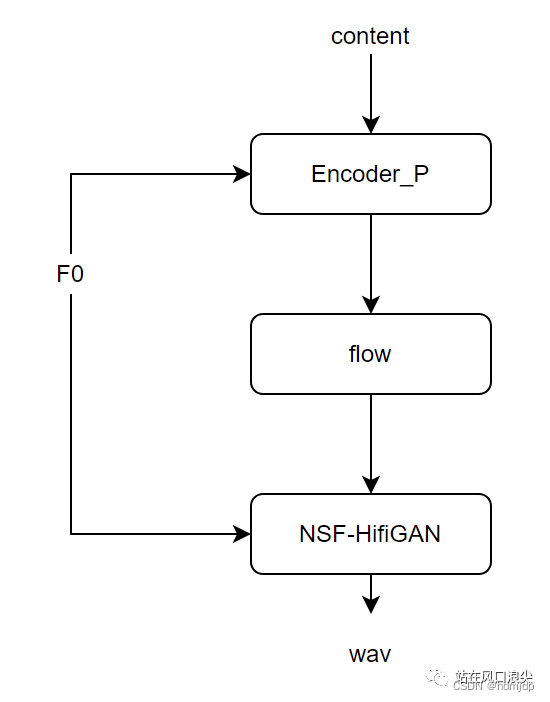
In so-vits-svc, the phonemes in vits become hubert features. Since the hubert encoding length has a fixed proportional relationship with the acoustic feature length, no duration model or MAS is needed; the task model in VC becomes simpler. Of course, since the f0 of a song lasts longer in the frequency spectrum and is more difficult to model than the f0 of a human voice, the author explicitly introduced f0 into vits.
Customization process
To customize an AI Stefanie Sun, there are tutorials on github and a GUI is written to make it easier to operate. Let’s briefly talk about the process:
- Get Stefanie Sun's songs, about 1 hour. Through the vocal analysis program, the accompaniment and background are removed, leaving only the acapella audio (dry sound);
- Feature preprocessing, extracting f0 and hubert features, and amplitude spectrum spec;
- Load the base model, finetune the above features and audio wav to obtain the final inference model;
- When reasoning, you also need to input audio. For example, using Jay Chou's "Qili Xiang", you first separate the vocals, obtain the dry sound, and send it as input to the VC model to obtain the a cappella audio of "Qili Xiang" sung by Stefanie Sun. Finally, the accompaniment and a cappella The audio is mixed to get an AI cover song.
https://github.com/voicepaw/so-vits-svc-fork
Please follow vx official account
Standing on the cusp of the storm