This article will be divided into the following four parts to introduce the data warehouse architecture and model design method of Alibaba DataWorks:
-
Technical architecture selection
-
Data Warehouse Hierarchy
-
data model
-
Hierarchical Call Specification
01 Technical architecture selection
The tutorial itself uses Alibaba Cloud MaxCompute as an example. In fact, the process and methodology are common.
Before designing the data model, it is necessary to complete the selection of the technical architecture first. In this tutorial, Alibaba Cloud big data product MaxCompute is used together with DataWorks to complete the overall 数据建模和研发流程.
The complete technical architecture diagram is shown in the figure below:

Among them, the data integration of DataWorks is responsible for completing data collection and basic ETL [the basic platform for data collection and ETL can be built based on open source related technical components]. MaxCompute serves as an offline computing engine throughout the big data development process . DataWorks includes a series of functions including data development, data quality, data security, and data management .
02 Data Warehouse Layering
In Alibaba's data system, we propose to divide the data warehouse into three layers , from bottom to top: 数据引入层(ODS,Operation Data Store),数据公共层(CDM,Common Data Model) and 数据应用层(ADS,Application Data Service).
The layering of the data warehouse and the purpose of each layer are shown in the following figure:

-
Data introduction layer ODS (Operation Data Store) : store unprocessed raw data to the data warehouse system, and the structure is consistent with the source system, yes
数据仓库的数据准备区. Mainly complete the duties of importing basic data to MaxCompute, and record the historical changes of basic data. -
The data public layer CDM (Common Data Model, also known as the common data model layer) , including
DIM维度表、DWD和DWS, is processed from the data of the ODS layer. It mainly completes data processing and integration, establishes consistent dimensions, builds reusable detailed fact tables for analysis and statistics, and summarizes indicators of public granularity.
-
Common Dimension Layer (DIM) : Based on the concept of dimensional modeling, establish a consistent dimension for the entire enterprise. Reduce the risk of inconsistent data calculation caliber and algorithms. The tables in the common dimension layer are usually also called logical dimension tables, and dimensions and dimension logical tables are usually in one-to-one correspondence.
-
Public Summary Granularity Fact Layer (DWS) : With the subject object of analysis as the modeling driver, based on the upper-level application and product index requirements, build a public granularity summary indicator fact table, and physicalize the model by means of a wide table. Construct statistical indicators with naming conventions and consistent caliber, provide public indicators for the upper layer, and establish summary wide tables and detailed fact tables.
The tables of the public summary granularity fact layer are usually also called summary logical tables, which are used to store derived indicator data. -
Detail-grained fact layer (DWD) : With the business process as the modeling driver, based on the characteristics of each specific business process, build the most fine-grained detail-level fact table. Some important dimension attribute fields of the detailed fact table can be appropriately redundant in combination with the data usage characteristics of the enterprise, that is, wide table processing. Tables in the fine-grained fact layer are also commonly referred to as logical fact tables.
-
Data application layer ADS (Application Data Service) : stores personalized statistical index data of data products. Generated according to CDM and ODS layer processing.
The data classification architecture is divided into three parts at the ODS layer: . The overall data classification structure is shown in the following figure:数据准备区、离线数据和准实时数据区
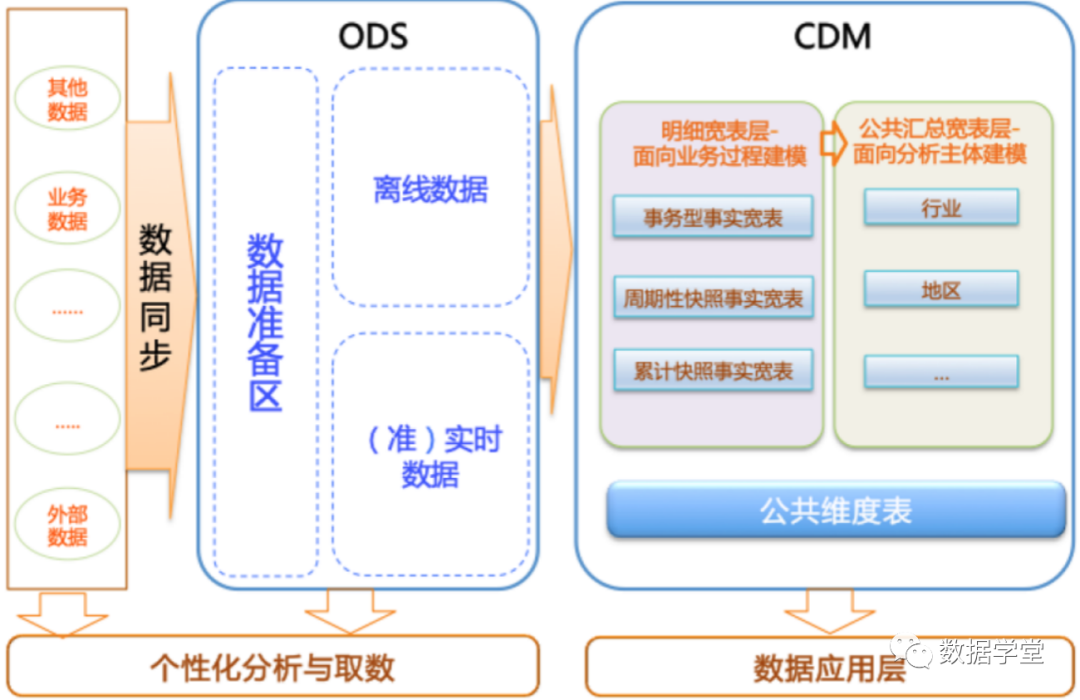
In this tutorial, from 交易数据系统的数据the passage DataWorks数据集成, 同步到数据仓库的ODS层. After data development, a wide range of facts is formed, and then public summarization is carried out with dimensions such as commodities and regions.
The overall data flow is shown in the figure below:
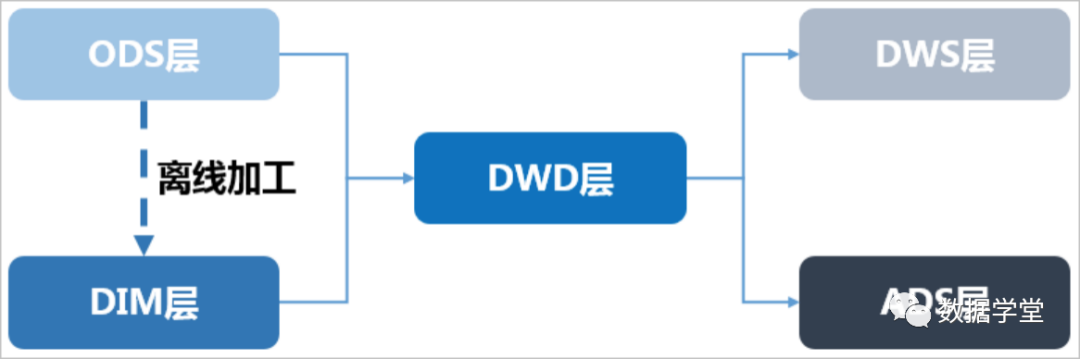
Among them, the ETL (Extract, Transform, and Load) processing from the ODS layer to the DIM layer is performed in MaxCompute, and will be synchronized to all storage systems after the processing is completed. The ODS layer and DWD layer will be placed in the data middleware for downstream subscriptions. The data of the DWS layer and the ADS layer are usually landed in the online storage system , and the downstream is used in the form of interface calls .
03 Data Model
1. Data introduction layer (ODS)
Stored in the ODS layer 从业务系统获取的最原始的数据, it is the source data of other upper layer data. The data in the business data system is usually very detailed data, accumulated over a long period of time, and accessed frequently, yes 面向应用的数据.
Data import layer table design
In this tutorial, the data mainly included in the ODS layer are: transaction system order details, user information details, product details, etc. These data are unprocessed and are the most raw data. Logically, these data are 二维表stored in the form of . Although strictly speaking the ODS layer does not belong to the category of data warehouse modeling, it is also very important to plan the ODS layer reasonably and do a good job in data synchronization .
In this tutorial, 6 ODS tables are used:
record commodity information for auction: s_auction.
Record commodity information for normal sale: s_sale.
Log user details: s_users_extra.
Record the newly added commodity transaction order information: s_biz_order_delta.
Record the newly added logistics order information: s_logistics_order_delta.
Record the newly added payment order information: s_pay_order_delta.
Description:
Pass to _deltaidentify the table as an incremental table.
The names of some fields in the table happen to be the same as the keywords, which can be _col1resolved by adding a suffix.
Example of table creation (s_auction)
CREATE TABLE IF NOT EXISTS s_auction
(
id STRING COMMENT '商品ID',
title STRING COMMENT '商品名',
gmt_modified STRING COMMENT '商品最后修改日期',
price DOUBLE COMMENT '商品成交价格,单位元',
starts STRING COMMENT '商品上架时间',
minimum_bid DOUBLE COMMENT '拍卖商品起拍价,单位元',
duration STRING COMMENT '有效期,销售周期,单位天',
incrementnum DOUBLE COMMENT '拍卖价格的增价幅度',
city STRING COMMENT '商品所在城市',
prov STRING COMMENT '商品所在省份',
ends STRING COMMENT '销售结束时间',
quantity BIGINT COMMENT '数量',
stuff_status BIGINT COMMENT '商品新旧程度 0 全新 1 闲置 2 二手',
auction_status BIGINT COMMENT '商品状态 0 正常 1 用户删除 2 下架 3 从未上架',
cate_id BIGINT COMMENT '商品类目ID',
cate_name STRING COMMENT '商品类目名称',
commodity_id BIGINT COMMENT '品类ID',
commodity_name STRING COMMENT '品类名称',
umid STRING COMMENT '买家umid'
)
COMMENT '商品拍卖ODS'
PARTITIONED BY (ds STRING COMMENT '格式:YYYYMMDD')
LIFECYCLE 400;data import layer storage
In order to meet the requirements 历史数据分析需求, the time dimension can be added to the ODS layer table as a partition field. In practical applications, you can choose to adopt 增量,全量 store or 拉链store.
-
Incremental storage
Incremental storage in units of days, with business dates as partitions, and each partition stores daily incremental business data. An example is as follows:
On January 1, user A visited company A’s e-commerce store B, and company A’s e-commerce log generated a record t1. On January 2, user A visited company A’s e-commerce store C, and company A’s e-commerce store The log produces a record t2. Using the incremental storage method, t1 will be stored in the partition on January 1, and t2 will be stored in the partition on January 2.
On January 1, user A purchased product B on the e-commerce website of company A, and a record t1 will be generated in the transaction log. On January 2, user A purchased product B again, and the transaction log will update the record t1退货. Using the incremental storage method, the initial purchased t1 record will be stored in the partition on January 1 , and the updated t1 will be stored in the partition on January 2 .
transactions, logs, 事务性较强的ODS表适合增量存储etc. This type of table has a large amount of data, and the storage cost of using the full storage method is high . In addition, the downstream applications of this type of table have less demand for historical full data access (such demand can be obtained through the subsequent summary of the data warehouse). For example, log-type ODS tables do not have a data update business process, so all incremental partitions are UNIONed together to form a full amount of data.
-
Full storage
Full storage in days, with business dates as partitions, and each partition stores data up to the business date全量业务数据.
For example, on January 1, seller A released two products B and C on the e-commerce website of company A, and the front-end product table will generate two records t1 and t2. On January 2, seller A released product B, and at the same下架time After product D is released, the front-end product table will update record t1 and generate new record t3. Using the full storage method, two records t1 and t2 are stored in the January 1 partition, and updated t1, t2, and t3 records are stored in the January 2 partition .
For slowly changing dimensional data with a small amount of data, such as commodity categories, full storage can be used directly.
-
Zipper storage uses zipper storage
新增两个时间戳字段(start_dt和end_dt)to record all the change data at the granularity of days, and usually the partition fields are also these two timestamp fields.
Examples of zipper storage are as follows.
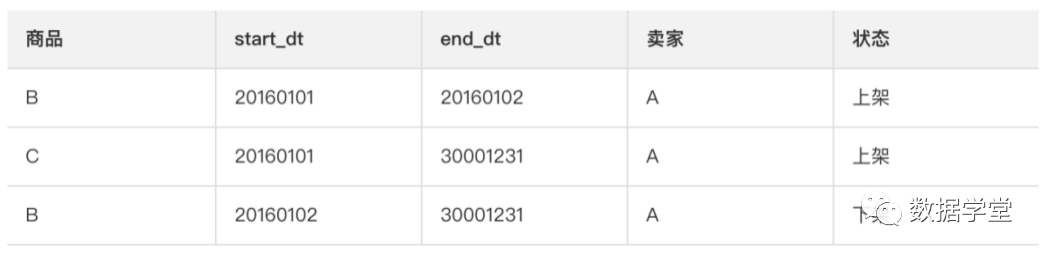
In this way, downstream applications can obtain historical data by restricting the timestamp field. For example, if a user accesses the data on January 1, only need to limit start_dt<=20160101 and end_dt>20160101.
slowly changing dimensions
MaxCompute does not recommend using surrogate keys, and recommends using natural keys as dimension primary keys. There are two main reasons:
-
MaxCompute is a distributed computing engine, and the workload of generating a globally unique surrogate key is very heavy. When encountering a large amount of data, this work will be more complicated and unnecessary.
-
The use of surrogate keys increases the complexity of ETL, thereby increasing the development and maintenance costs of ETL tasks.
In the case where surrogate keys are not used, 缓慢变化维度it can 快照be handled by way.
The calculation cycle of data in snapshot mode is usually once a day . Based on this period, the way to handle dimension changes is a full snapshot per day.
For example, in the product dimension, a full product snapshot data is kept every day. The fact table of any day can get the product information of that day, or the latest product information, by limiting the date and using natural keys to associate . The advantages of this method mainly include the following two points:
-
The way to deal with slowly changing dimensions is simple and effective, and the development and maintenance costs are low.
-
Easy to use and easy to understand. The data user only needs to limit the date to get the snapshot data of that day. The fact snapshot of any day can be associated with the dimension snapshot of any day through the natural key of the dimension.
该方法的弊端主要是存储空间的极大浪费. For example, the daily change of a certain dimension accounts for a very low proportion of the total data volume. In extreme cases, there is no change every day. In this case, the storage waste is serious. This method mainly realizes the optimization and logical simplification of obtaining ETL efficiency by sacrificing storage. Please avoid overuse of this method and must have a counterpart .数据生命周期制度,清除无用的历史数据
Data synchronous loading and processing
ODS data needs to be synchronized to MaxCompute by each data source system before it can be used for further data development. This tutorial recommends using DataWorksthe data integration feature to complete data synchronization. In the process of using data integration, it is recommended to follow the following guidelines:
-
The source table of a system can only be synchronized to MaxCompute once to maintain the consistency of the table structure.
-
Data integration is only used for offline full data synchronization. Real-time incremental data synchronization needs to be implemented using the data transmission service DTS. For details, see Data transmission service DTS.
-
Data integration The data that is fully synchronized directly enters the current day partition of the full scale table.
-
Tables in the ODS layer are recommended to be stored in the form of statistical date and time partition tables , which is convenient for managing data storage costs and policy control.
-
Data integration can adaptively handle changes in source system fields:
-
If the target table of the source system field does not exist on MaxCompute, Data Integration can automatically add the non-existing table field.
-
If the field in the target table does not exist in the source system, Data Integration fills it with NULL.
2. Common dimension summary layer (DIM)
The public dimension summary layer (DIM) is based on the concept of dimensional modeling to establish consistent dimensions for the entire enterprise.
The public dimension summary layer (DIM) is mainly composed of dimension tables (dimension tables). Dimension is a logical concept, and it is a perspective to measure and observe business. Dimension table is a table that physicalizes the tables built on the data platform according to dimensions and their attributes, and adopts the principle of wide table design. Therefore, 构建公共维度汇总层(DIM)首先需要定义维度.
define dimensions
When dividing 数据域and building 总线矩阵, you need to combine 对业务过程的分析定义维度. Taking this tutorial A电商公司的营销业务板块as an example, in the transaction data domain , we focus on the business process of confirming receipt (successful transaction).
In the business process of confirming receipt, there are mainly business perspectives that depend on the two dimensions of commodity and receiving location (in this tutorial, it is assumed that receiving and purchasing are the same location).
From the product point of view, the following dimensions can be defined:
product ID
product name
product price
product newness: 0-new, 1-idle, 2-used
product category ID
product category name category
ID
category name
buyer ID
product status: 0- Normal, 1-deleted by the user, 2-off the shelf, 3-never put on the shelf
The city where the product is located
The province where the product is located
From a geographical perspective, the following dimensions can be defined:
buyer ID
city code
city name
province code
province name
As the core of dimensional modeling, the uniqueness of dimensions must be guaranteed in enterprise data warehouses. Take the commodity dimension of Company A as an example, 有且只允许有一种维度定义. For example, the dimension of province code is consistent with the information conveyed by any business process.
Design Dimension Table
After the dimension definition is completed, the dimension can be supplemented to generate a dimension table.
The design of the dimension table needs to pay attention to:
-
It is recommended that dimension tables
单表信息have no more than 10 million entries. -
It is recommended when dimension tables are joined with other tables
使用Map Join. -
避免过于频繁的更新The data of the dimension table.
When designing dimension tables, the following aspects need to be considered:
-
Stability of data in dimension tables. For example, company A's e-commerce members usually do not die, but the member data may be updated at any time. At this time, it is necessary to consider creating a single partition to store the full amount of data. May be required if there are records that will not be updated
分别创建历史表与日常表. The daily table is used to store the currently valid records, so that the data volume of the table will not expand; the historical table is inserted into the corresponding partition according to the death time, and a single partition is used to store the death records of the corresponding time of the partition. -
Whether to split vertically. If a large number of attributes are not used in a dimension table, or the query is slowed down due to carrying too many attribute fields, you need to consider splitting the fields and creating multiple dimension tables.
-
Whether to split horizontally. If there are clear boundaries between records, consider splitting into multiple tables or designing multi-level partitions.
-
The output time of the core dimension table usually has strict requirements.
The main steps to design a dimension table are as follows:
-
Complete the preliminary definition of dimensions and ensure the consistency of dimensions.
-
Identify the main dimension table (the central fact table, used in this tutorial
星型模型). The main dimension table here is usually a data introduction layer (ODS) table, which is directly synchronized with the business system. For example, s_auction is a product table synchronized with the front-end product center system, and this table is the main dimension table. -
Determine the relevant dimension tables. Data warehouse is the data integration of business source systems, and there are correlations between tables in different business systems or in the same business system. Based on the sorting out of the business, determine which tables are associated with the main dimension table, and select some of them to generate dimension attributes. Taking the commodity dimension as an example, according to the combing of the business logic, it can be found that there are correlations between commodities and categories, sellers, stores and other dimensions.
-
Determining dimension attributes mainly includes two stages. The first stage is to select dimension attributes from the master dimension table or generate new dimension attributes; the second stage is to select dimension attributes from related dimension tables or generate new dimension attributes. Taking commodity dimension as an example, select dimension attributes or generate new dimension attributes from the main dimension table (s_auction) and related dimension tables such as categories, sellers, and stores.
Generate as many dimension attributes as possible.
Give as many meaningful textual descriptions as possible.
Distinguish between numeric attributes and facts.
Precipitate general dimension attributes as much as possible.
Common Dimension Summary Layer (DIM) Dimension Table Specification
Public Dimension Summary Layer (DIM) Dimension Table Naming Specification:dim_{业务板块名称/pub}_{维度定义}[_{自定义命名标签}], the so-called pub is a dimension that has nothing to do with a specific business segment or is common to all business segments, such as the time dimension.
An example is as follows:
Dimension table in the public areadim_pub_area The full list of products in the e-commerce sector of company Adim_asale_itm
Example of building a table
CREATE TABLE IF NOT EXISTS dim_asale_itm
(
item_id BIGINT COMMENT '商品ID',
item_title STRING COMMENT '商品名称',
item_price DOUBLE COMMENT '商品成交价格_元',
item_stuff_status BIGINT COMMENT '商品新旧程度_0全新1闲置2二手',
cate_id BIGINT COMMENT '商品类目ID',
cate_name STRING COMMENT '商品类目名称',
commodity_id BIGINT COMMENT '品类ID',
commodity_name STRING COMMENT '品类名称',
umid STRING COMMENT '买家ID',
item_status BIGINT COMMENT '商品状态_0正常1用户删除2下架3未上架',
city STRING COMMENT '商品所在城市',
prov STRING COMMENT '商品所在省份'
)
COMMENT '商品全量表'
PARTITIONED BY (ds STRING COMMENT '日期,yyyymmdd');
CREATE TABLE IF NOT EXISTS dim_pub_area
(
buyer_id STRING COMMENT '买家ID',
city_code STRING COMMENT '城市code',
city_name STRING COMMENT '城市名称',
prov_code STRING COMMENT '省份code',
prov_name STRING COMMENT '省份名称'
)
COMMENT '公共区域维表'
PARTITIONED BY (ds STRING COMMENT '日期分区,格式yyyymmdd')
LIFECYCLE 3600;3. Detail-grained fact layer (DWD)
The fine-grained fact layer is modeled by business process drive , and based on the characteristics of each specific business process, the most fine-grained fact table of the detail layer is constructed. Some important dimension attribute fields of the detailed fact table can be appropriately redundant in combination with the data usage characteristics of the enterprise, ie 宽表化处理.
As the core of data warehouse dimensional modeling, the fact tables of the public summary granularity fact layer (DWS) and detailed granularity fact layer (DWD) need to be designed around business processes . Describe the business process by obtaining the measures that describe the business process, including referenced dimensions and measures related to the business process. 度量通常为数值型数据, as the basis of the fact logic table. The description information of the fact logic table is the fact attribute, and the foreign key field in the fact attribute is associated through the corresponding dimension.
The degree of business detail expressed by a record in the fact table is called granularity . Generally, granularity can be expressed in two ways: one is the level of detail represented by the combination of dimension attributes, and the other is the specific business meaning represented.
As a fact to measure the business process, it is usually an integer or floating-point decimal value, and there are three types: additivity, semi-additivity and non-additivity:
-
Additive facts are those that can be aggregated along any dimension associated with the fact table.
-
Semi-additive facts can only be aggregated along specific dimensions, not across all dimensions. For example, inventory can be summarized by location and product, but it is meaningless to accumulate inventory for each month of the year by time dimension.
-
Complete non-additivity, such as ratio facts. For non-additive facts, aggregation can be achieved by decomposing them into additive components.
Compared with dimension tables, fact tables are usually more slender, and the row growth rate is faster . Dimension attributes can be stored in the fact table, such 存储到事实表中的维度列称为维度退化,可加快查询速度. Like other dimensions stored in dimension tables, dimension degeneration can be used to filter and query fact tables, implement aggregation operations, and so on .
The detailed fact layer (DWD) is usually divided into three types: 事务事实表,周期快照事实表 and 累积快照事实表, for details, please refer to the data warehouse construction guide.

-
Transactional fact tables are used to describe business processes, track measurement events at a certain point in space or time, and store the most atomic data, also known as atomic fact tables .
-
Periodic snapshot fact tables record facts at regular, predictable intervals.
-
The cumulative snapshot fact table is used to express key step events between the start and end of the process, covering the entire life cycle of the process, usually with multiple date fields to record key time points. While the cumulative snapshot fact table is constantly changing over the lifetime, records are also modified as the process changes.
Design Principles for Detail-Grained Fact Tables
The design principles of the fine-grained fact table are as follows:
-
Typically, a detail-grained fact table is associated with only one dimension.
-
Include all relevant facts about the business process as much as possible.
-
Only select facts that are relevant to the business process.
-
Decomposes non-additive facts into additive components.
-
Granularity must be declared before selecting dimensions and facts.
-
There cannot be multiple facts of different granularities in the same fact table.
-
Units of fact should be consistent.
-
Handle Null values with care.
-
Use degenerate dimensions to improve the usability of fact tables.
-
The overall design process of the fine-grained fact table is shown in the figure below.

The transaction business process and its measurement have been defined in the consistency measurement. The detailed fact table pays attention to the model design for the business process . The design of the detailed fact table can be divided into four steps:
选择业务过程, 确定粒度, 选择维度,确定事实(度量) . Granularity is mainly to record the semantic description of business activities without dimension expansion. When building a detailed fact table, it is necessary to choose to develop the detailed layer data based on the existing table, and to know what granularity data is stored in the record of the built table.
Detail-grained fact layer (DWD) specification
The naming convention that usually needs to be followed is: dwd_{业务板块/pub}_{数据域缩写}_{业务过程缩写}[_{自定义表命名标签缩写}] _{单分区增量全量标识}, pub indicates that the data includes data of multiple business sectors. The incremental full amount of a single partition is usually identified as: i means incremental, and f means full amount. For example: dwd_asale_trd_ordcrt_trip_di (A e-commerce company’s airline ticket order order fact table, daily refresh increment) and dwd_asale_itm_item_df (A e-commerce product snapshot fact table, daily refresh full amount).
In this tutorial, the DWD layer mainly consists of three tables:
transaction commodity information fact table: dwd_asale_trd_itm_di.
Transaction member information fact table: ods_asale_trd_mbr_di.
Transaction order information fact table: dwd_asale_trd_ord_di.
Table creation example (dwd_asale_trd_itm_di)
CREATE TABLE IF NOT EXISTS dwd_asale_trd_itm_di
(
item_id BIGINT COMMENT '商品ID',
item_title STRING COMMENT '商品名称',
item_price DOUBLE COMMENT '商品价格',
item_stuff_status BIGINT COMMENT '商品新旧程度_0全新1闲置2二手',
item_prov STRING COMMENT '商品省份',
item_city STRING COMMENT '商品城市',
cate_id BIGINT COMMENT '商品类目ID',
cate_name STRING COMMENT '商品类目名称',
commodity_id BIGINT COMMENT '品类ID',
commodity_name STRING COMMENT '品类名称',
buyer_id BIGINT COMMENT '买家ID',
)
COMMENT '交易商品信息事实表'
PARTITIONED BY (ds STRING COMMENT '日期')
LIFECYCLE 400;4. Public Summary Granularity Fact Layer (DWS)
明细粒度 ==> 汇总粒度
The public summary granularity fact layer 以分析的主题对象作为建模驱动builds a public granularity summary indicator fact table based on the upper-layer application and product indicator requirements. A table in a common aggregation layer usually corresponds to a derived metric .
Common Summary Fact Table Design Principles
Aggregation refers to 原始明细粒度的数据summarizing. The DWS public summary layer is a topic aggregation modeling for analysis objects. In this tutorial, the final analysis goal is: the total sales of a certain category (for example: kitchen utensils) in each province in the last day , the top 10 sales commodity names of this category , and the distribution of user purchasing power in each province . Therefore, we can 最终交易成功summarize the data of the latest day from the perspectives of commodities, categories, buyers, etc.
-
Aggregation does not span facts. Aggregations are summaries made against the original star schema. To obtain and query results that are consistent with the original model, aggregated dimensions and measures must be consistent with the original model, so aggregates do not span facts.
-
Aggregation will improve query performance, but aggregation will also increase the difficulty of ETL maintenance. When the first-level category corresponding to the subcategory changes, the previously existing data that has been summarized into the aggregation table needs to be readjusted.
In addition, the following principles should be followed when designing the DWS layer:
-
Data Commons: Consider whether aggregated aggregates can be made available to third parties. It can be judged whether aggregation based on a certain dimension is often used in data analysis. If the answer is yes, it is necessary to aggregate the detailed data into the aggregated table.
-
Does not cross the data domain: The data domain is an abstraction that classifies and aggregates data at a higher level. Data domains are usually classified by business process. For example, transactions are unified under the transaction domain, and new additions and modifications of commodities are placed under the commodity domain.
-
Distinguish between statistical periods: The statistical period of the data must be explained in the name of the table, for example ,
_1d, , .最近1天td表示截至当天nd表示最近N天
Public Summary Fact Table Specification
Public summary fact table naming convention: dws_{业务板块缩写/pub}_{数据域缩写}_{数据粒度缩写}[_{自定义表命名标签缩写}]_{统计时间周期范围缩写}. Regarding the statistical actual period range abbreviation, by default, the offline calculation should include 最近一天(_1d),最近N天(_nd) and 历史截至当天(_td)three tables. If there are too many table fields of _nd that need to be split, only one statistical period unit is allowed as an atomic split. That is, a table is split in a statistical cycle, for example, a table is split in the last 7 days (_1w). A split table is not allowed to store multiple statistical periods.
For 小时表(whether it is day refresh or hour refresh), it is _hhused to indicate. For 分钟表(whether it is day refresh or hour refresh), it is _mmused to indicate.
An example is as follows: dws_asale_trd_byr_subpay_1d(One-day summary fact table of buyer’s granular transaction payment by stages of A e-commerce company)
dws_asale_trd_byr_subpay_td (Summary table of A’s buyer’s granularity of staged payment up to the day)
dws_asale_trd_byr_cod_nd (Buyer’s granular cash on delivery of A e-commerce company Transaction Summary Fact Table)
dws_asale_itm_slr_td (the stock summary table of sellers of A e-commerce company as of the current day)
dws_asale_itm_slr_hh (the hourly summary table of sellers of A e-commerce company’s granular goods) --- dimension is hour
dws_asale_itm_slr_mm (minute summary of sellers of A e-commerce company granular goods Table)---
Example of building a table whose dimension is minutes
The DWS layer table creation statement that meets the business requirements is as follows
CREATE TABLE IF NOT EXISTS dws_asale_trd_byr_ord_1d
(
buyer_id BIGINT COMMENT '买家ID',
buyer_nick STRING COMMENT '买家昵称',
mord_prov STRING COMMENT '收货人省份',
cate_id BIGINT COMMENT '商品类目ID',
cate_name STRING COMMENT '商品类目名称',
confirm_paid_amt_sum_1d DOUBLE COMMENT '最近一天订单已经确认收货的金额总和'
)
COMMENT '买家粒度所有交易最近一天汇总事实表'
PARTITIONED BY (ds STRING COMMENT '分区字段YYYYMMDD')
LIFECYCLE 36000;
CREATE TABLE IF NOT EXISTS dws_asale_trd_itm_ord_1d
(
item_id BIGINT COMMENT '商品ID',
item_title STRING COMMENT '商品名称',
cate_id BIGINT COMMENT '商品类目ID',
cate_name STRING COMMENT '商品类目名称',
mord_prov STRING COMMENT '收货人省份',
confirm_paid_amt_sum_1d DOUBLE COMMENT '最近一天订单已经确认收货的金额总和'
)
COMMENT '商品粒度交易最近一天汇总事实表'
PARTITIONED BY (ds STRING COMMENT '分区字段YYYYMMDD')
LIFECYCLE 36000;04 Hierarchical calling specification
After completing the layering of the data warehouse, it is necessary to make an agreement on the calling relationship between the data of each layer.
The ADS application layer prioritizes calling the public layer data of the data warehouse . 如果已经存在CDM层数据,不允许ADS应用层跨过CDM中间层从ODS层重复加工数据. The CDM middle layer should actively understand the data construction requirements of the application layer, deposit public data to the public layer, and provide data services for other data layers. At the same time, the ADS application layer also needs to actively cooperate with the CDM middle layer to carry out continuous transformation of data public construction. Avoid excessive ODS layer references, unreasonable data duplication, and sub-collection redundancy. The general principle of hierarchical calling is as follows:
-
ODS layer data cannot be directly referenced by application layer tasks. If there is no precipitated ODS layer data in the middle layer, it can be accessed through the view of the CDM layer. The CDM layer view must be encapsulated with a scheduler to maintain the maintainability and manageability of the view .
-
The depth of CDM layer tasks should not be too large (it is recommended not to exceed 10 layers).
-
Only one output table is allowed for a calculation refresh task, except in special cases.
-
If multiple tasks refresh and output a table (different tasks are inserted into different partitions), a virtual task needs to be created on DataWorks to rely on the refresh and output of multiple tasks. Typically, downstream should rely on this dummy task.
-
The CDM summary layer preferentially calls the CDM detailed layer, which can accumulate indicator calculations. The CDM summary layer tries to give priority to calling the coarse-grained summary layer that has been produced, so as to avoid a large amount of summary layer data being directly calculated from the massive detailed data layer.
-
The cumulative snapshot fact table of the CDM detail layer prioritizes calling the CDM transactional fact table to maintain data consistency and output.
-
Build a CDM public summary layer in a targeted manner to avoid excessive reference and reliance on detailed data at the CDM layer at the application layer.