1. Background
1. Description
2. Data set
row_id: encoding of check-in behavior
xy: coordinate system, location of the person
accuracy: positioning accuracy
time: timestamp
place_id: predicting the location where the user will check in
3. The data set download
https://www.kaggle.com/navoshta/grid-knn/data
cannot be downloaded in China, and the verification code cannot be received. It is better to use points on csdn to download the one uploaded by others.
2. Process analysis
1. Get data
2. Data processing
Purpose:
Feature value target
value a
. Narrow the data range. Narrow
the range according to coordinates
2 < Check-in on the road on Saturday, maybe in the mall or sleeping at home c. Filter locations with few check-ins d. Data set division
3. Feature engineering
standardization
4. KNN algorithm predictor process
5. Model selection and tuning
6. Model evaluation
3. Code
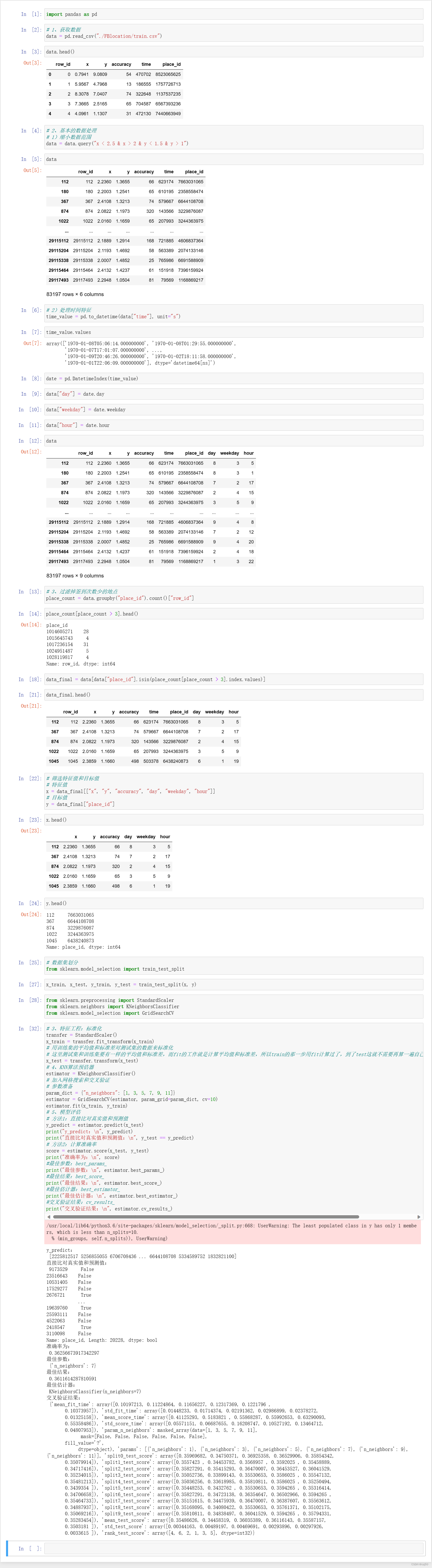
1、day02_facebook_demo
import pandas as pd
# 1、获取数据
data = pd.read_csv("./FBlocation/train.csv")
data.head()
# 2、基本的数据处理
# 1)缩小数据范围
data = data.query("x < 2.5 & x > 2 & y < 1.5 & y > 1")
data
# 2)处理时间特征
time_value = pd.to_datetime(data["time"], unit="s")
time_value.values
date = pd.DatetimeIndex(time_value)
data["day"] = date.day
data["weekday"] = date.weekday
data["hour"] = date.hour
data
# 3、过滤掉签到次数少的地点
place_count = data.groupby("place_id").count()["row_id"]
place_count[place_count > 3].head()
data_final = data[data["place_id"].isin(place_count[place_count > 3].index.values)]
data_final.head()
# 筛选特征值和目标值
# 特征值
x = data_final[["x", "y", "accuracy", "day", "weekday", "hour"]]
# 目标值
y = data_final["place_id"]
x.head()
y.head()
# 数据集划分
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y)
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
# 3、特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
# 用训练集的平均值和标准差对测试集的数据来标准化
# 这里测试集和训练集要有一样的平均值和标准差,而fit的工作就是计算平均值和标准差,所以train的那一步用fit计算过了,到了test这就不需要再算一遍自己的了,直接用train的就可以
x_test = transfer.transform(x_test)
# 4、KNN算法预估器
estimator = KNeighborsClassifier()
# 加入网格搜索和交叉验证
# 参数准备
param_dict = {"n_neighbors": [1, 3, 5, 7, 9, 11]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=10)
estimator.fit(x_train, y_train)
# 5、模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
#最佳参数:best_params_
print("最佳参数:\n", estimator.best_params_)
#最佳结果:best_score_
print("最佳结果:\n", estimator.best_score_)
#最佳估计器:best_estimator_
print("最佳估计器:\n", estimator.best_estimator_)
#交叉验证结果:cv_results_
print("交叉验证结果:\n", estimator.cv_results_)2. Operation results