Table of contents
3.3 Adjustment of generation instructions for node classification
3.4 Auxiliary self-supervised link prediction
4.4 Instruction Tuning at Low Label Ratio
Paper link: https://arxiv.org/pdf/2308.07134.pdf
Summary
The emergence of large-scale pre-trained language models such as ChatGPT has completely changed various research fields of artificial intelligence. Transformer-based large language models (LLM) have gradually replaced CNN and RNN to unify the fields of computer vision and natural language processing. Compared with relatively independent data such as images, videos, or texts, graphs are data that contain rich structural and relationship information. At the same time, natural language, as one of the most expressive media, is good at describing complex structures.
However, existing work on incorporating graph learning problems into generative language modeling frameworks is still very limited. As the importance of large language models continues to grow, it becomes crucial to explore whether LLM can also replace GNN as the underlying model for graphs.
In this paper, we propose InstructGLM (Instruction-finetuned Graph Language Model) to systematically design highly scalable hints based on natural language instructions, and use natural language to describe the geometric structure and node characteristics of the graph for instruction-tuned LLM to execute Learn and reason about graphs generatively. Our method outperforms all competing GNN baselines on ogbn-arxiv, Cora, and PubMed datasets, which demonstrates the effectiveness of our method and reveals generative large language models as fundamental models for graph machine learning.
Introduction
Before the emergence of Transformers [1], various artificial intelligence fields with different inductive biases had different underlying model architectures. For example, CNN [2, 3] is designed taking into account the spatial invariance of images, resulting in superior performance in computer vision tasks [4, 5]. Memory enhancement models such as RNN [6] and LSTM [7, 8] are widely used to process sequence data such as natural language [9] and audio [10]. Graph neural network (GNN) is good at capturing topological information through message passing and aggregation mechanisms, making it the first choice in the field of graph learning for a long time [11-13]. In recent years, the artificial intelligence community has witnessed the emergence of numerous powerful pre-trained large language models (LLMs) [14-18], which are driving huge advances and leading to the pursuit of possible general artificial intelligence (AGI) [19]. In this context, there is a unified trend in model architectures in different fields. Specifically, pre-trained Transformers have shown excellent performance in various modes, such as images [20] and videos [21] in computer vision, text in natural language processing [22], and graph machine learning. of structured data [23], decision sequences in reinforcement learning [24], and visual text pairs in multimodal tasks [25]. There are even Transformers [26] that can handle 12 modes.
In addition to model architecture, the unification of processing methods for handling multi-modal data is also an important trend worthy of attention. T5 [15] established a text-to-text framework that unifies all NLP tasks as a sequence generation problem. Furthermore, models like CLIP [25] utilize image-text pairs to accomplish multi-modal tasks and use natural language descriptions of images. As for reinforcement learning, Di Palo et al. [24] adopted natural language to describe the environmental state of the agent and successfully solved many reinforcement learning (RL) problems. P5 [27] further promotes this trend by reformulating all personalized recommendation tasks as language modeling tasks through prompts. The above works collectively show that utilizing natural language for multimodal information representation has become a prominent and promising trend.
However, in the field of graph machine learning, the exploration of leveraging natural language processing for graph-related tasks is still limited. Existing methods that utilize large language models to handle graph tasks can be roughly divided into two categories: 1) Combining LLM and GNN, where LLM acts as a feature extractor or data augmentation module to improve the performance of downstream GNN [28 -30]. Such methods usually require training multiple models, thus incurring huge computational overhead. In addition, since GNNs are still responsible for learning the structural information of the graph, they tend to inherit the shortcomings of GNNs, such as being prone to over-smoothing [31]. 2) Relying only on transformers, but requiring novel label embedding designs for nodes and edges [32] or creating complex graph attention modules to learn structural information [33, 34]. This type of approach requires local attention computation for each node at each optimization step, resulting in considerable computational cost, and thus limits the scope of each node to only 1-hop neighbors. At the same time, complex pipelines transfer structural information through special attention mechanisms or token representations, which prevents the model from directly observing and learning structural information like GNN, thus limiting further improvement in performance.
In order to solve the existing problems in LLM-based graph learners and bridge the gap in natural language-based graph learning, we propose InstructGLM (Instruction Fine-tuned Graph Language Model). Given that LLM dominates many AI fields, we aim to answer the question: Can LLM also replace GNN as the basic model for graph machine learning? Intuitively, as one of the most expressive media, natural language is good at describing complex structures, so InstructGLM has the following advantages over GNN:
1) Flexibility. Natural language sentences are able to effectively describe connectivity at any desired hop level and intermediate paths without the need for information passing and aggregation. Even multi-modal features of nodes and edges can be directly integrated into natural language prompts, which makes natural language a very flexible medium that can convey both structural information and content information of the graph.
2) Scalability. Injecting graph structure into multiple natural language sentences enables small-batch training and independent gradient propagation, further easily extending to distributed training and inference on massive graphs while reducing machine communication overhead.
3) Compatibility. With the assistance of structural description, InstructGLM can consistently reformulate various graph learning pipelines into language modeling tasks, thereby integrating well into the multi-modal processing framework based on LLM, providing a basis for integrating graph learning with vision, language, recommendation, etc. The integration of other AI tasks paves the way to build a unified AI system.
In this paper, we focus on solving the graph node classification task while enhancing it with self-supervised link prediction to improve performance. Inspired by various message passing pipelines in GNN [35, 36], we design a series of scalable graph prompts for instruction tuning on generative LLM [37, 38]. Specifically, after determining the central node and performing neighbor sampling, we systematically use natural language to describe the topology of the graph according to prompts. By doing so, graph structures can be provided to LLM clearly and intuitively without the need for complex processes tailored to the graph. Therefore, we can handle graphics tasks efficiently and concisely in a generative manner through the common Transformer architecture [1] and language modeling goals [39]. Furthermore, our approach ensures high compatibility between graph learning, NLP, and multi-modal processing, thereby exhibiting high scalability in multi-task learning in various domains. Overall, our contributions can be summarized as the following four points
To the best of our knowledge, we are the first to propose purely using natural language for graph structure representation and making instruction adjustments to generative LLM to solve graph-related problems. We eliminate the requirement to design a specific complex attention mechanism or a tokenizer tailored for the graph. Instead, we provide a concise and efficient natural language processing interface for graph machine learning, which exhibits high scalability in a unified multi-modal and multi-task framework, in line with current trends in other artificial intelligence fields.
• Inspired by various message passing mechanisms in GNN, we design a series of rule-based, highly scalable instruction prompts for general graph structure representation and graph machine learning. Although in this paper our focus is on exploring instruction tuning for large language models, these tips can also be used for zero-shot experiments with LLM.
• In addition to node classification, we also perform self-supervised link prediction as an auxiliary task and further study its impact on the main task under a multi-task instruction tuning framework. This exploration provides valuable insights into future LLM-based multi-task graph learning, demonstrating the importance of self-supervised link prediction for large language models to better understand graph structure.
• We conduct extensive experiments on three widely used datasets: ogbn-arxiv, Cora and PubMed. Results show that our InstructGLM outperforms previous competitive GNN baselines and Transformer-based methods on all three datasets, achieving top performance. These findings validate the effectiveness of our proposed approach and highlight the trend of leveraging generative large language models as fundamental models for graph machine learning.
Related Work
GNN-based method
Graph neural networks (GNN) [40, 41] have long dominated the field of graph machine learning. Utilizing message passing and aggregation mechanisms, GNN is good at learning node features, edge features, and topological structure information simultaneously. In general, GNNs can be divided into space-based GNNs [12, 13, 42, 43] and spectrum-based GNNs [11, 44, 45], with various message passing mechanisms. To solve some inherent problems such as over-smoothing [31], researchers have proposed methods such as incorporating intermediate layer features into the final representation [36], convolving multiple subgraphs extracted from different skip levels [35] , as well as discarding edges to prevent overfitting [46]. A major drawback of GNNs is that they cannot directly process raw data from various modalities, requiring extensive feature engineering as a preprocessing step. GNN cannot directly process non-numeric information such as text or images. To solve this problem, existing work uses techniques such as BoW, TF-IDF or Skip-gram to construct shallow embeddings as input to GNN [47]. Its lack of compatibility with existing large-scale generative models poses significant challenges for integration with other artificial intelligence fields such as vision and language into unified intelligent systems.
Transformer-based approach
The attention-based Transformer model can also be used for graph processing by representing each node and edge in the graph as a different token [48]. However, this simple approach poses two challenges: first, it is computationally expensive when processing large-scale graphs. Secondly, the global weighted average calculation with basic attention mechanism cannot effectively capture and learn the topology of the graph [32]. In order to overcome these problems, various methods have been proposed to improve the Transformer structure or graphic representation method. Some methods incorporate graph structure information into attention matrices [23] or coefficients [49], while other methods restrict attention to local subgraphs [34] or cleverly design orthogonal vectors for node and edge labels to encode structure. Details[32]. These enhancements often involve complex attention mechanisms or data transformations, making direct representation of graph structures challenging and significantly increasing the difficulty of model training. The only work similar to ours is Zhang et al. [50], which utilizes specially formulated encoder-only models and natural language templates to solve the biological concept linking problem [51, 52]. However, unlike our method, it is not designed for general graph learning and is difficult to extend beyond classification tasks due to the use of encoder-only models [53]. Furthermore, its natural language templates are tailored for the biological concept linking domain and are therefore not as expressive and flexible as our approach
Fuse GNN 和 Transformers
GNNs are good at learning structural information, while Transformers are good at capturing multi-modal features. Many works combine GNN and Transformer to effectively solve graph-related tasks. For example, Chien et al. [54] utilized the multi-label neighbor prediction task to incorporate structural information into the language model to generate enhanced features named GIANT to improve the performance of downstream GNNs. Mavrommatis et al. [29] use GNN to perform knowledge distillation on language models. Zhao et al. [30] iteratively train GNN and language models in a variational inference framework. Rong et al. [55] try to use GNN to replace Transformers. attention head to better capture global information. The main disadvantage of the above method is the lack of decoupling between the Transformer model and GNN, which requires training multiple models and easily generates a large amount of computational overhead [34]. Furthermore, model performance is still susceptible to inherent problems of GNNs, such as over-smoothing [56]. Furthermore, the process of training multiple models is often very complex compared to the simplicity of a single generative LLM framework.
Methods based on large language models (LLM)
Inspired by LLM's excellent zero-sample capabilities in various AI fields, using LLM to solve graph problems has attracted widespread attention from researchers. Existing work has included leveraging LLM to automatically select the most appropriate graph processor based on the query [57], leveraging LLM's zero-shot prediction and corresponding interpretation of data augmentation to obtain state-of-the-art TAPE graph feature embeddings [28], and generating hints. to solve graph construction problems [58], structural reasoning tasks [59] and molecular property prediction tasks [60]. In addition, new LLM-based graph problem datasets and benchmarks have been collected and released [61]. There are three works that share similarities with our approach. Guo et al. [61] attempted to accomplish graph tasks by describing graphs. However, it does not use natural language like our prompt. Instead, it uses complex formal languages such as Brandes et al. [62] and Himsoldt [63] Wang et al. [64] and Chen et al. [65] both explore the use of natural language and LLM to solve graph problems, [64] focuses more on mathematical problems on small graphs, while [65] focuses on node classification in text attribute graphs (TAG) [66]. Compared with Wang et al. [64] and Chen et al. [65], the natural language instruction prompt we designed shows better regularity and scalability, is suitable for both small and large graphs, and is not limited to specific types of graphs. data. In contrast, some of the natural language templates in the above-mentioned works are generated by LLM for specific task instructions and are also enhanced by advanced prompting techniques such as Chain of Thoughts (CoT) [67]. Overall, these three related works only explore the basic capabilities of leveraging LLM for graph tasks in a zero-shot setting. Since they do not employ instruction tuning [37], their performance does not exceed the GNN baseline in most cases, only demonstrating the potential of LLM as an option for graphics tasks. In contrast, our work successfully bridges this gap by adapting instructions to generative LLM with simple hints, achieving experimental results that surpass competitive GNN baselines.
3 InstructGLM
In this section, we will introduce in detail our proposed instruction fine-tuning graph language model, namely InstructGLM, a framework that utilizes natural language to describe graph structure and node features to generate large language models , and further solve graph-related problems through instructions Adjustment. We start with the symbolic setup, then introduce instruction hints and their design rationale, and then explain the proposed pipeline in more detail.
3.1 Preliminary
Formally, the graph can be expressed as G = (V, A, E, {Nv }v∈V , {Ee}e∈E ), where V is the set of nodes, E is the set of edges, and A ∈ { 0, 1 }|V|×|V| is the adjacency matrix, Nv is the node feature of v ∈ V, and Ee is the edge feature of e ∈ E. It is worth noting that node features and edge features can be in various forms and various modalities. For example, node features can be textual information in citation or social networks, visual images in photography, user profiles in client systems, or even video or audio signals in movie networks, while edge features can be user-item interactions Product review recommendation system diagram in .
3.2 Instruction Prompt Design
In order to fully convey the structural information of the graph and ensure the adaptability of the created instruction prompts to various types of graphs, we systematically designed a set of graph description prompts centered on the central node . These tips can be distinguished based on the following three questions: i) What is the maximum number of hops for the neighbor information of the central node in the tip? ii) Does the prompt contain node features or edge features? iii) For tips with a central node having large (≥ 2) hop neighbors, does the tip contain information about intermediate nodes or paths along the corresponding connection route?
Regarding the first question, prompts can be divided into two types: prompts containing only 1-hop connection information and prompts containing at most 2-hop or 3-hop connection details. Previous studies have shown that utilizing up to 3 hop connections is sufficient to obtain excellent performance [11-13], while information beyond 3 hops usually has less impact on improvement and may even cause negative impacts [31, 68]. Therefore, the maximum level of neighbor information contained in the prompt is level three. However, benefiting from the flexibility of natural language, our designed prompt can accommodate virtually any hop-level structural information. For the latter two questions, there are two possible situations for each question, namely whether node or edge features are included in the prompt, and whether connection route information is included in the prompt.
Then, we represent the instruction prompt as T (·), such that ![]() is the input sentence of LLM and v is the central node of the prompt and its corresponding graph structure described in natural language. For example, the simplest form of a graph description containing up to 2-hop neighbor details is:
is the input sentence of LLM and v is the central node of the prompt and its corresponding graph structure described in natural language. For example, the simplest form of a graph description containing up to 2-hop neighbor details is:

Its most detailed form should include node features, edge features and corresponding different paths:
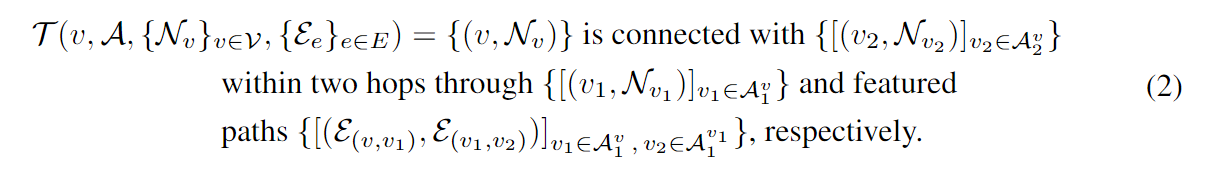
where represents the k-hop neighbor node list of node v. Essentially, the above prompt contains all 2-hop paths with node and edge characteristics, such as
![]() being centered on node v. All instruction prompts we designed are summarized in the appendix.
being centered on node v. All instruction prompts we designed are summarized in the appendix.
3.3 Adjustment of generation instructions for node classification
In prompt engineering [69–71] or contextual learning [72], pre-trained models are often frozen, which prevents them from achieving optimal performance in downstream tasks. However, instruction tuning [37, 38], under the framework of multi-prompt training, directly conveys the requirements of downstream tasks to the pre-trained model by fusing the original input data with task-specific instruction prompts. This allows for very effective fine-tuning, especially when combined with human feedback [18]. Instruction tuning has become an indispensable technique for fine-tuning the most powerful large-scale language models.
In this paper, we introduce InstructGLM as a multi-prompt instruction tuning framework for graph learning. Specifically, we adopt a generative large-scale language model with an encoder-decoder or decoder-only architecture as the backbone, and then fuse all the instruction prompts we design, which span different jump levels and have different structural information, Together, they serve as input to LLM to realize mutual enhancement between instructions. By exclusively using natural language to describe graph structures, we succinctly present graph geometry to LLM and provide a pure NLP interface for all graph-related tasks so that they can be solved generatively through a unified pipeline. It is worth noting that in this study we focus on solving the node classification task. We train InstructGLM to strictly generate category labels for natural language and choose the negative log-likelihood (i.e., NLL) loss popular in language modeling as our objective function.
Formally, given a graph ![]() and a specific instruction prompt T ∈ {T (·)}, we denote x and y as the input to the LLM, and the target sentence. Then our pipeline can be formed as:
and a specific instruction prompt T ∈ {T (·)}, we denote x and y as the input to the LLM, and the target sentence. Then our pipeline can be formed as:

Where L represents the NLL loss, ![]() which is a graph structure description centered on node v ∈ V, and P and Q are task-specific instruction prefixes and queries. Specifically, for node classification, we design P and Q for node classification as follows: P = ' Classify the central node into the following categories: [<all categories>]. Pay attention to the multi-hop link relationships between nodes. ” and Q = “ Which category should {v} belong to? ”. More details of the pipeline are shown in Figure 2.
which is a graph structure description centered on node v ∈ V, and P and Q are task-specific instruction prefixes and queries. Specifically, for node classification, we design P and Q for node classification as follows: P = ' Classify the central node into the following categories: [<all categories>]. Pay attention to the multi-hop link relationships between nodes. ” and Q = “ Which category should {v} belong to? ”. More details of the pipeline are shown in Figure 2.
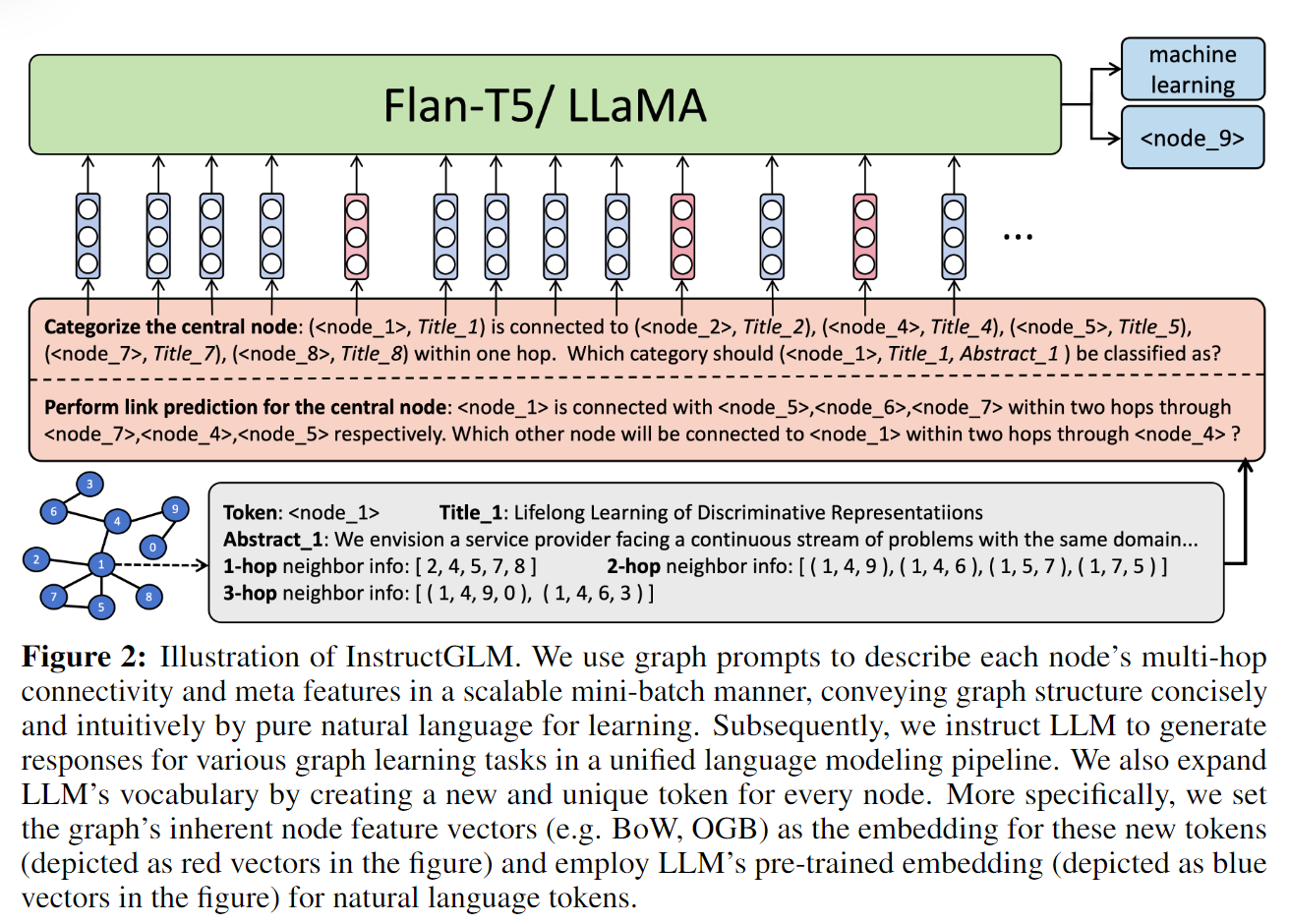
(Figure 2: InstructGLM diagram. We use graph prompts to describe the multi-hop connections and meta-features of each node in a scalable mini-batch manner, concisely and intuitively conveying the graph structure through pure natural language for learning. Subsequently, we instruct LLM Generate responses for various graph learning tasks in a unified language modeling pipeline. We also extend the vocabulary of LLM by creating a new, unique token for each node. More specifically, we incorporate the inherent The node feature vectors (e.g. BoW, OGB) are set to the embeddings of these new tags (shown as red vectors in the figure), and the pre-trained embeddings of LLM (shown as blue vectors in the figure) are adopted for natural language tags.)
Our InstructGLM is essentially similar in mechanism to various GNNs, and thus also covers their advantages. First, we mix prompt information with different skip levels during the training process, which is similar to MixHop [35] that performs graph convolution on subgraphs extracted at different skip levels. Second, Jumping Knowledge [36] combines results from different convolutional layers through skip connections, which is consistent with our prompt featuring intermediate information and high-jump-level neighbors. Furthermore, due to the input length limitation of LLM, we similar to GraphSAGE [13] perform neighbor sampling on the central node when filling in prompts to form mini-batch training. This operation is also similar to graph regularization techniques that prevent over-smoothing, such as DropEdge [46][73].
Furthermore, compared with GNN, our InstructGLM exhibits stronger expressive power. In our approach, even a single graph description containing intermediate paths and k-hop neighbor information is equivalent to a k-layer GNN in terms of expressive power. Therefore, InstructGLM can easily adapt to the inductive bias of graph tasks without any changes to the architecture and process of LLM. For example, since our input is a centralized graph description that directly exhibits the corresponding multi-hop neighbors, self-attention [1] applied to such input can be regarded as an advanced weighted average aggregation mechanism [12, 74] of GAT, thus facilitating InstructGLM effectively grasps the different importance of different neighbors to the central node.
3.4 Auxiliary self-supervised link prediction
Both SuperGAT [75] and DiffPool [76] introduced an auxiliary link prediction task and successfully achieved better node representation and node or graph classification performance, indicating that this auxiliary task can significantly enhance the model's understanding of the graph structure. . Inspired by them, and to eliminate the limitation that our instruction prompt can only treat labeled training nodes as central nodes in single-task semi-supervised learning, we introduce self-supervised link prediction as the basic auxiliary task of InstructGLM . Given an arbitrary hop level, for each node in the graph, we can randomly select neighbors or non-neighbors of that hop level as its candidates. We then prompt our model to either discriminate whether there is a connection at that hop level between the central node and the candidate node (discriminative hint), or to directly generate the correct neighbors in a generative manner (generative hint).
More formally, given a graph ![]() , the pipeline for link prediction is exactly the same as Equations 3 and 4 above. The only differences are newly designed task-specific prefixes and two different query templates. Specifically, we design P and Q for link prediction as follows: P = 'Perform link prediction on the central node. Pay attention to the multi-hop link relationships between nodes. ', Qgenerative = ' Which node within {h} hop will be connected to {v} ? ' and Qdiscriminative = '{~v} will be connected to {v} {h} hop? ', where v is the central node, ~v is the candidate node, and h is the specified hop.
, the pipeline for link prediction is exactly the same as Equations 3 and 4 above. The only differences are newly designed task-specific prefixes and two different query templates. Specifically, we design P and Q for link prediction as follows: P = 'Perform link prediction on the central node. Pay attention to the multi-hop link relationships between nodes. ', Qgenerative = ' Which node within {h} hop will be connected to {v} ? ' and Qdiscriminative = '{~v} will be connected to {v} {h} hop? ', where v is the central node, ~v is the candidate node, and h is the specified hop.
Therefore, we extend InstructGLM into a multi-task, multi-prompt instruction tuning framework. Regardless of the graph type and graph-related task InstructGLM ultimately targets, the inclusion of auxiliary self-supervised link prediction enables each node in the graph to act as a central node in multiple instruction prompts during training. Therefore, it not only serves as a data augmentation, but also encourages LLM to understand the global connection patterns of the graph, providing InstructGLM with promising potential to further improve the performance of the main task.
4 Experiments
4.1 Experimental Setup
In this paper, we mainly utilize InstructGLM for node classification and perform self-supervised link prediction as an auxiliary task. Specifically, we choose the following three popular graphs: ogbn-arxiv [66], Cora, and PubMed [77], where each node represents an academic paper on a specific topic with its title and abstract included in the original text format, and If there are citations between two papers, then there will be an edge between the corresponding two nodes. The graphs of ogbn-arxiv are relatively large, while those of Cora and PubMed are smaller. All our experiments adopt the default numeric node feature embeddings provided by the dataset, extending the vocabulary of LLM by adding newly constructed tags in the form of nodes. It is worth noting that these datasets use different techniques to generate default node feature embeddings, and we use their default embeddings without modification. Table 1 summarizes detailed dataset-specific information.

We adopt a multi-prompt tuning framework for all experiments and report test accuracy as our metric. For the ogbn-arxiv dataset, we adopt the exact same dataset split as the OGB open benchmark [66], i.e. 54%/18%/28%. For the Cora and PubMed datasets, we used the version containing original text information proposed by He et al. [28] and adopt a 60%/20%/20% training/validation/test split in our experiments. Following the research of Yang et al., we study the performance of InstructGLM in a low label ratio training environment. [77], we conducted further experiments on the PubMed dataset, fixing 20 labeled training nodes per class with a label ratio of 0.3%.
4.2 Main Results
Our results achieve state-of-the-art performance, outperforming all single-model graph learners on all three datasets, including representative GNN models and graph transformer models, demonstrating that large-scale language models are a fundamental model for graph learning. A promising trend. More detailed results and analysis are provided below.
4.2.1 ogbn-archive
For the ogbn-arxiv data set, we select a series of top-ranked GNNs from OGB Leaderboard1, including DRGAT, RevGAT, AGDN, etc. as baselines. Several of the most powerful Transformer-based single-model graph learners (such as Graphormer and E2EG on the OGB benchmark) are also considered for comparison with our proposed InstructGLM.
We fine-tuned the instructions of Flan-T5 [38] and Llama-v1-7b [17] (LoRA) [90] as the basis of InstructGLM. The experimental results in Table 2 show that InstructGLM outperforms all GNN and Transformer-based methods. In particular, when using Llama-v1-7b as the backbone of OGB features, our InstructGLM improves by 1.54% over the best GNN method and 2.08% over the best Transformer-based method. At the same time, we also obtain new SoTA performance on the GIANT [54] feature.

4.2.2 Cora & PubMed
In terms of comparison methods between Cora and PubMed datasets, we select top-ranked GNNs from two corresponding benchmark2 3, including Snowball, MixHop, RevGAT, FAGCN, etc. as baselines. In addition, the three most powerful Transformer-based single-model graph learners on these two benchmarks, namely CoarFormer, Graphormer and GT, are also considered for comparison with our proposed InstructGLM.

We use Flan-T5 and Llama-v1 (LoRA) as the backbone of InstructGLM for instruction regulation. The experimental results in Table 3 show that our InstructGLM outperforms all GNN and transformer-based methods. Specifically, on the Cora dataset, InstructGLM improved by 1.02% over the best GNN method and 2.08% over the best transformer-based method; on the PubMed dataset, InstructGLM improved by 3.18% over the best GNN method. , an improvement of 4.87% over the best transformer-based method.
4.3 Ablation Study
In our experiments, two key operations that help Instruct-GLM achieve superior performance in node classification are multi-hint instruction tuning, which provides multi-hop graph structure information to LLM, and utilizing self-supervised link prediction as an auxiliary Task. To verify the impact of the two key components on model performance, we performed ablation experiments on all three datasets, and the results are shown in Table 4.

Regarding the hop count information column, no structural adjustment means that we do not consider the structure of the graph, that is, we directly fine-tune the model based on the title and summary of the node. Single-hop (1-hop) and multi-hop (Multi-hop) respectively mean that the prompt information we use only includes information from single-hop neighbors, and includes information from neighbors with a higher hop count. Experimental results show that both the inclusion of multi-hop information and link prediction tasks can improve the model's performance in node classification tasks.
4.4 Instruction Tuning at Low Label Ratio
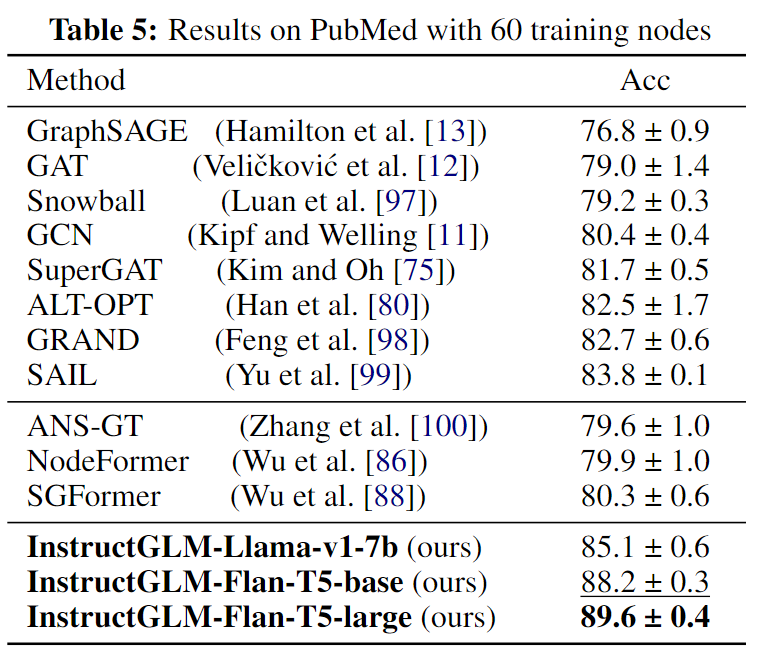
In previous experiments, our data splits ensured a relatively high proportion of labeled training nodes. To further investigate the scalability and robustness of InstructGLM, we conduct experiments on the PubMed dataset using another of its widely used segmentations with extremely low label ratios. Specifically, we only have 60 available training nodes in this setup, so the label ratio is 0.3%.
We consider the top-ranked GNNs in the corresponding rankings, including SAIL, ALT-OPT, GRAND, etc., as the baseline for comparison with our InstructGLM. We also consider the three best Transformer-based graph learners in this dataset setting. Then, we fine-tune the instructions of Flan-T5 and Llama and use them as the backbone of InstructGLM. The experimental results in Table 5 show that Instruct-GLM outperforms all GNN methods, improving by 5.8% relative to the best GNN baseline, while also exceeding the best Transformer-based model by 9.3%, successfully achieving a new state-ranking Most advanced performance on the list
5 Future Work
In this paper, we conduct extensive experiments on text attribute graphs (TAG) to demonstrate the power of our proposed InstructGLM in solving graph machine learning problems. Our command prompt is designed to describe graph structures in natural language, showing a high degree of versatility and scalability, making it applicable to almost all types of graphs. Potentially valuable future work can be explored from three dimensions:
For TAG, our experiments only use the default OGB feature embedding. Future work could consider using more advanced TAG-related embedding features, such as LLM-based features such as TAPE [28]. In addition, utilizing LLM's thought chain, structural information aggregation and other data augmentation techniques to generate more powerful instructions PROMPT will be a promising research direction for graph language models.
• InstructGLM can be integrated into frameworks such as GAN and GLEM for multi-model iterative training, or use ready-made GNN for knowledge extraction. In addition, classic graph machine learning techniques such as label reuse, Self-KD, correctness and smoothing can further improve the performance of the model.
• Benefiting from the powerful expressive power of natural language and the highly scalable design of instruction prompts, InstructGLM can be easily extended to various graphs within a unified generative language modeling framework to solve a wide range of graph learning problems. For example, the instruction prompt we designed can be directly further used for link prediction and inductive node classification tasks. With only slight modifications to our hints, we can effectively deploy tasks such as graph classification, intermediate node/path prediction, and even relationship-based question answering tasks in knowledge graphs with rich edge features.