1. Start
1. Import dependencies
<!--redis引用-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<!--排除spring-boot-starter-data-redis使用的默认客户端
BUG:永远会造成堆外内存溢出异常-->
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--使用jedis客户端-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>2. Configure Redis connection information
spring:
redis:
host: xxx.xx.xxx.xxx
password: 密码
database: 7 //使用的数据库3. Simple test
@Autowired
StringRedisTemplate stringRedisTemplate;
@Test
void testStringRedisTemplate(){
ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();
// 保存
ops.set("msg","hello,world"+ UUID.randomUUID().toString());
// 查询
String msg = ops.get("msg");
System.out.println(msg);
}Result: print hello,world67245659-1f7f-42cb-98d2-bed399d100ba
4. Practical business application
@Override
public Map<String, List<Catelog2Vo>> getCatalogJson() {
// 1、加入缓存逻辑,缓存中存的数据的json字符串
String catelogData = redisTemplate.opsForValue().get("catelogData");
if(StringUtils.isEmpty(catelogData)){
// 缓存中没有,则查询数据库
Map<String, List<Catelog2Vo>> catalogJsonFromDB = getCatalogJsonFromDB();
// 将查到的数据以json存入redis
String catalogJsonString = JSON.toJSONString(catalogJsonFromDB);
redisTemplate.opsForValue().set("catelogData",catalogJsonString);
// 将查询到的数据直接放回
return catalogJsonFromDB;
}
// 返回指定对象
Map<String, List<Catelog2Vo>> res = JSON.parseObject(catelogData, new TypeReference<Map<String, List<Catelog2Vo>>>() {
});
return res;
}2. Cache invalidation problem
1. Cache penetration
-
Cache penetration refers to querying a data that must not exist . Since the cache is not hit, the database will be queried, but the database does not have such a record. We did not write the null of this query into the cache, which will result in this non-existent Every time the data is requested, it must be queried at the storage layer, which loses the meaning of caching.
-
When the traffic is heavy , the DB may be down. If someone uses a non-existent key to frequently attack our application, this is a vulnerability.
-
solve:
Cache empty results and set a short expiration time.
2. Cache avalanche
-
Cache avalanche means that we use the same expiration time when setting up the cache, causing the cache to expire at the same time at a certain moment, all requests are forwarded to the DB, and the DB instantaneously suffers from an avalanche of excessive pressure.
-
solve:
Add a random value to the original expiration time , such as 1-5 minutes randomly, so that the repetition rate of each cache's expiration time will be reduced, making it difficult to cause collective failure events.
3. Cache breakdown
- For some keys with an expiration time set, if these keys may be accessed very concurrently at certain points in time, it is a very "hot" data.
- At this time, there is a problem that needs to be considered: if the key expires before a large number of requests come in at the same time, then all data queries for this key will fall to the db, which is called cache breakdown.
- solve:
Lock
3. Distributed locks and local locks
Scenes:
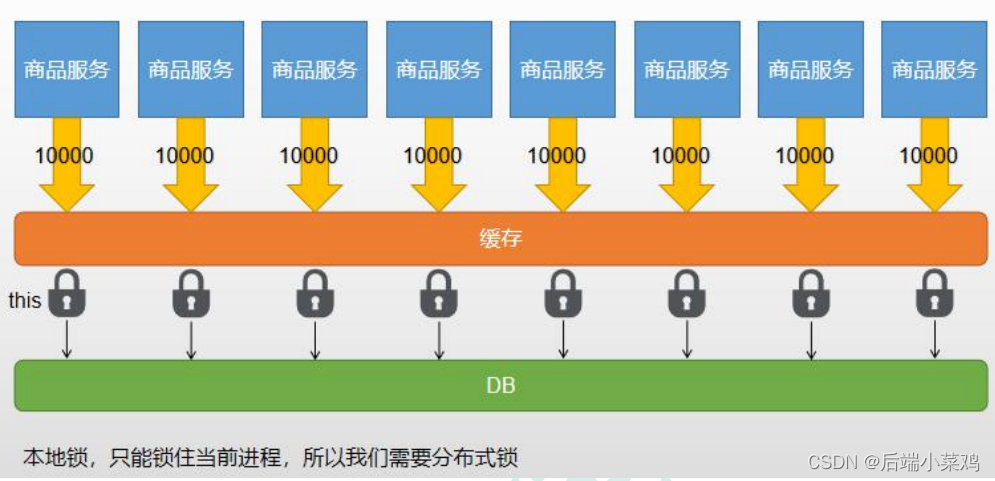
1. Implement local locks (suitable for single architecture projects)
When a request comes in, the cache is first queried. If the cache misses, the data is queried. Therefore, we need to add a lock to the code for querying the database. Here we use synchronized(this){database query....}. Note that after querying the database, the query will The received data is put into the cache. This step must also be in the synchronized code block. Otherwise, the lock may be released after the first request completes querying the database without putting the data into the cache, and the second request may miss the cache. , resulting in repeated queries to the database.
The query database code is as follows:
/**
* 从数据库查询数据并封装数据
* @return
*/
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDB() {
synchronized(this){
// 只要是同一把锁,就能锁住需要这个锁的所有线程
String catelogData = redisTemplate.opsForValue().get("catelogData");
if(!StringUtils.isEmpty(catelogData)){
// 返回指定对象
Map<String, List<Catelog2Vo>> res = JSON.parseObject(catelogData, new TypeReference<Map<String, List<Catelog2Vo>>>() {
});
return res;
}
/**
* 1、将数据库多次查询改为一次
*/
List<CategoryEntity> selectList = baseMapper.selectList(null);
// 1 查出所有分类
List<CategoryEntity> level1Categorys = getParent_cid(selectList,0l);
Map<String, List<Catelog2Vo>> parent_cid = level1Categorys.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
List<CategoryEntity> categoryEntities = getParent_cid(selectList,v.getCatId());
List<Catelog2Vo> catelog2Vos = null;
if (categoryEntities != null) {
catelog2Vos = categoryEntities.stream().map(l2 -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName());
List<CategoryEntity> level3category = getParent_cid(selectList,l2.getCatId());
if(level3category!=null){
List<Catelog2Vo.Catelog3Vo> collect = level3category.stream().map(l3 -> {
Catelog2Vo.Catelog3Vo catelog3Vo = new Catelog2Vo.Catelog3Vo(l2.getCatId().toString(),l3.getCatId().toString(),l3.getName());
return catelog3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatalog3List(collect);
}
return catelog2Vo;
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
// 将查到的数据以json存入redis
String catalogJsonString = JSON.toJSONString(parent_cid);
redisTemplate.opsForValue().set("catelogData",catalogJsonString,12,TimeUnit.HOURS);
return parent_cid;
}
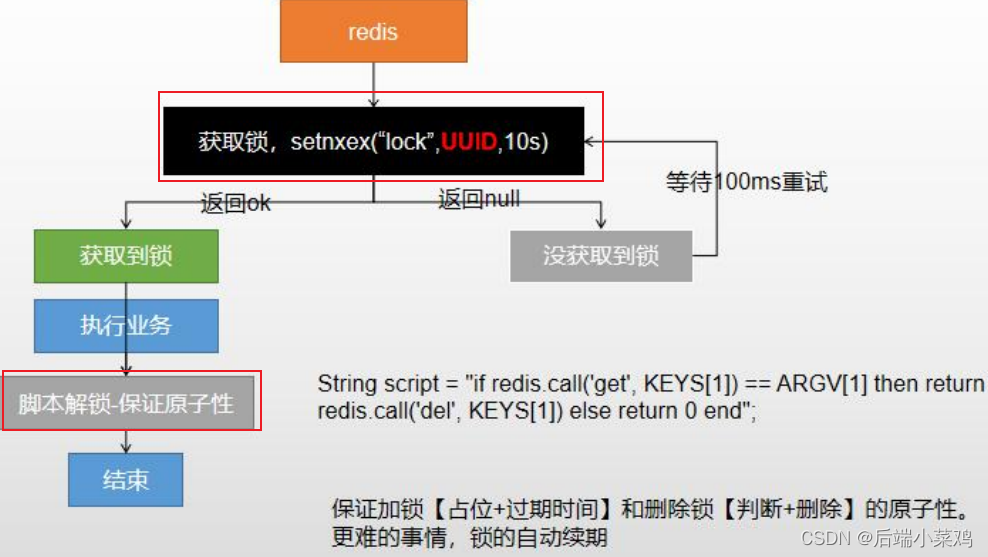
}2. Simple implementation of distributed locks
Basic logic:
Code:
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDBWithReidsLock() {
// 1、占分布式锁,去redis占锁
// setIfAbsent 相当于 setnx 有值 则 不设置
// 设置过期时间,以防程序发生错误或机器断电造成死锁
String uuid = UUID.randomUUID().toString();
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid,300,TimeUnit.SECONDS);
if(lock){
Map<String, List<Catelog2Vo>> dataFromDB = null;
try {
// 拿到锁,执行业务
dataFromDB = getDataFromDB();
}finally { // 无论怎样都释放锁
// 查询锁 与 删除锁 必须是原子操作
// 只删除自己的锁
String script= "if redis call('get',KEYS[1]) == ARGV[1] then return redis call('del',KEYS[1]) else return 0 end";
Long delLock = redisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class), Arrays.asList("lock"), uuid);
}
return dataFromDB;
}else{
// 加锁失败...重试
return getCatalogJsonFromDBWithReidsLock(); // 自旋的方式
}
}
Among them: it must be ensured that locking and setting expiration time, querying locks and deleting locks must be atomic operations, and no matter how the business code is executed, the lock must be released eventually to avoid deadlock.
Unlocking requires the use of a Lua script. When the query is found, redis will help us delete the Key.
Lua script:
if redis call('get',KEYS[1]) == ARGV[1] then return redis call('del',KEYS[1]) else return 0 end