This article undertakes the transformation of the above code, the above link: HTTP
Article directory
1. Implement website jump
Enter w3school on your browser to search

url represents a link,
Link text represents text/button
, and you can jump to the specified website.

In index.html, add a line to represent the Baidu link, enter by clicking the Visit W3School text

After running the executable program, you can click the Visit W3School text
Paste the link to Baidu in index.html, so click to jump directly to the Baidu website
Implement your own website jump

At this time, change Baidu's URL to the file1 and file2 files implemented by yourself.

At this time, enter the host IP + port number. You can see two links, file1 and file2, below the picture.

At this time, enter the host IP + port number. You can see that there are two links, file1 and file2, below the picture.
Click file1 and file2 respectively to enter different websites.
2. Request method (get) && response method (post)
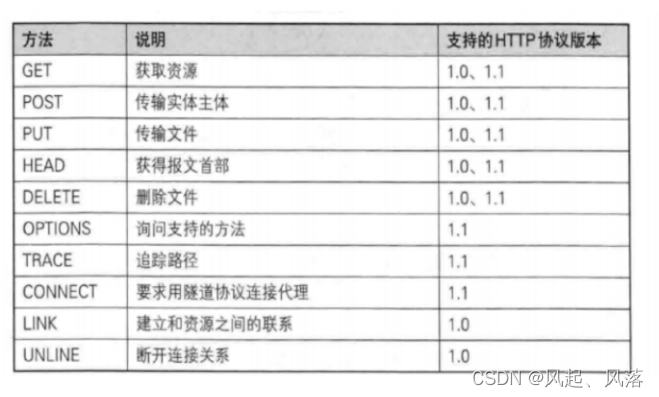
The most commonly used methods are GET and POST, which
are generally initiated by the browser client and will construct an http request. The carried method may be GET/POST,
prompting the browser to use different methods for resource submission and requesting,
thus proposing an HTML form. the concept of
GET method
Click to view: HTML form

The syntax is the form tag and ends with /form
to form an input box, allowing users to directly extract their personal information and submit it to the server
action means submitting the form to /a/b/c.exe and the corresponding method is GET
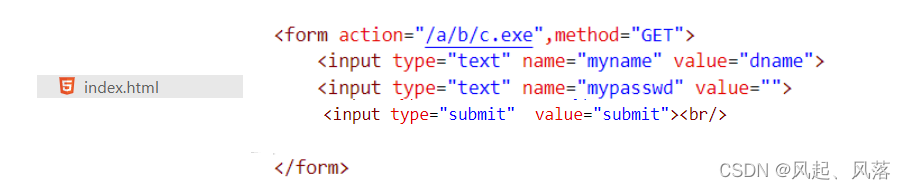
Through the GET method, enter your name and password, and finally click submit to submit.

After entering your name and password, click Submit. The URL of the jump page is http://101.43.252.143:8989/a/b/c.exe?myname=dname&mypasswd=123456
Also displayed on Linux


After clicking submit, the browser will automatically construct an HTTP request
to? As a separator, the left side is the resource to be accessed, and the right side is the parameter you want to give to the resource. The parameter is of KV type.
GET can also submit parameters through URL.
POST method

Change the method to POST, leaving everything else unchanged
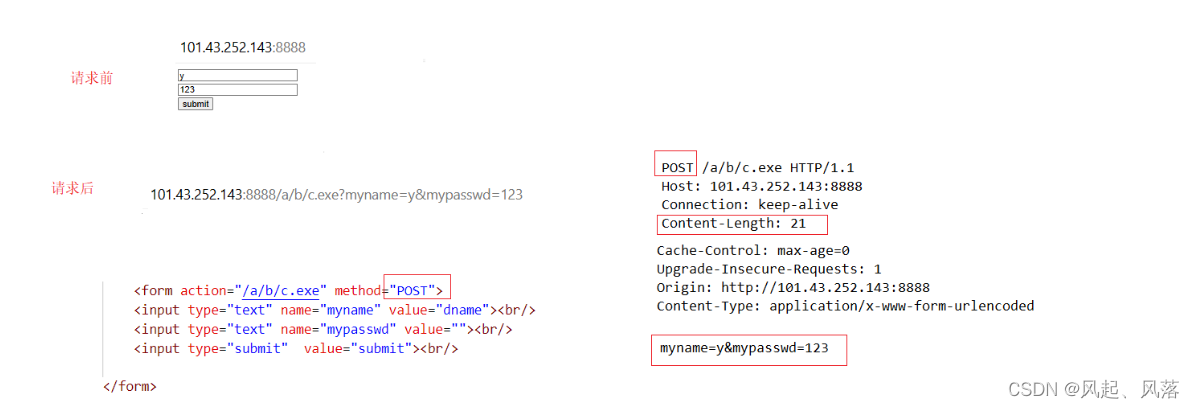
POST request, when submitting data, submit parameters through the body part
Application scenarios of GET and POST
The parameters submitted by the GET method are not private (not safe)
and will echo the parameters to the browser's URL.
The POST method is more private when submitting parameters.
The parameters will not be echoed to the URL.
Therefore, all login and registration activities must use the POST method to submit parameters (not safe).
url: The string of the http request line generally has size constraints. The text
can be very large in theory. It is
recommended to use POST for big data and GET for small data.
3. HTTP status code
In order to tell the browser whether the returned result is correct or wrong

In the previous code, directly tell the browser that its status code is 200, which is correct

In the HTTP server, status codes are divided into five categories, starting with 1, starting with 2, and starting with 3. Starting with 4, starting with 5
An informational status code starting with 1 is called an informational status code.
For example: a submission action is currently being made, but this action is time-consuming. In order to give the client a response as soon as possible, a status code starting with 1 is returned to
indicate that the current request has been accepted and is being processed as soon as possible.
The status code starting with 2 is called a success status code
. Commonly used ones are 200, which means that the request was successful, which means that the response given to you can be interpreted normally.
Codes starting with 3 are called redirection status codes
, such as: 301, 302, 307.
Redirection is divided into permanent redirection and temporary redirection.
4 is called the client error status code
such as: 404 403
For example: Click on JD.com to view: JD.com official website
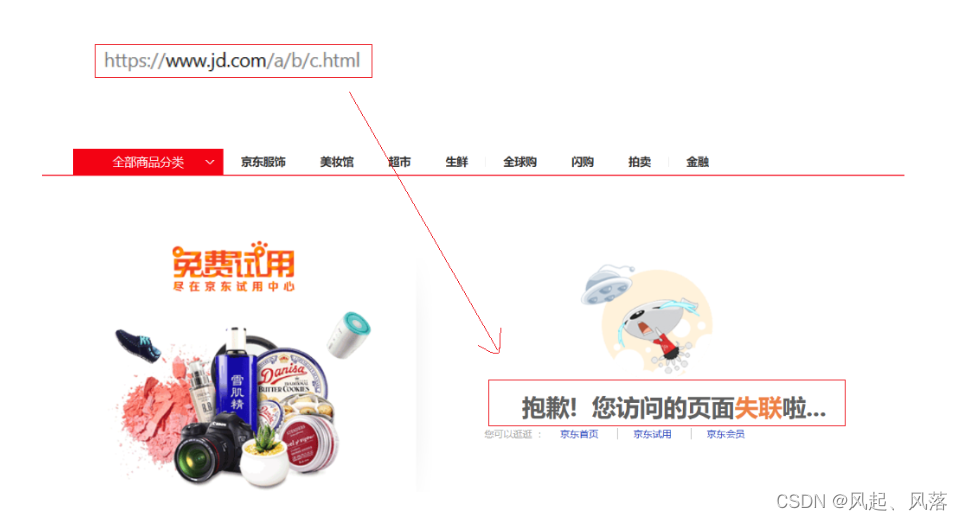
Look for www.jd/a/b/c.html. Since this page does not exist in Jingdong, an error will be reported. Therefore,
the 404 error is a client error, indicating that the client is making an illegal request.
If the client is making an illegal request, the server must tell Client, the request is unreasonable
Found 404 in the code I designed
In the code I designed, if the accessed resource is not found in the website, how to proceed with 404?
So in the wwwroot directory, create a file err_404.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>404 Not Found</title>
</head>
<body>
<h1>404 Not Found</h1>
<p>Sorry, the page you are looking for could not be found.</p>
</body>
</html>
Found a 404 html web page source code on the Internet
In the HandlerHttp callback function of Main.cc

If the ReadFile function (function is to read the contents of the entire file) returns true, it means that the file was read successfully.

If the return value of the ReadFile function is false, it means that reading the file failed and a 404 page needs to be added.

Create a string page_404 to represent the path of the 404 page. If
the file fails to open, import the path corresponding to 404 into the body (payload).
In the GetContentType function (the function is to determine the suffix of a certain resource), it is directly determined to be .html

When the port number 8888 is entered in the executable program, it means that the browser can only enter the host IP + port number.
After the browser enters the host IP + port number, and then enters other things, it will result in a 404 error.
Server error status codes starting with 5 are called
When creating a process or thread in the server, if the creation process or thread processing fails, it is a server error.
Or when the operation is performed, the file exists, but opening/reading the file fails, it is also a server error.
Generally speaking, even if there is a server error, the status code starting with 5 will not be displayed, but the status code starting with 1 to 4 will be displayed.
Status code starting with 3 (redirect status code)

Mainly look at three status codes: 301, 302, 307.
301 means permanent redirection,
302 and 307 means temporary redirection.
The difference between permanent redirection and temporary redirection
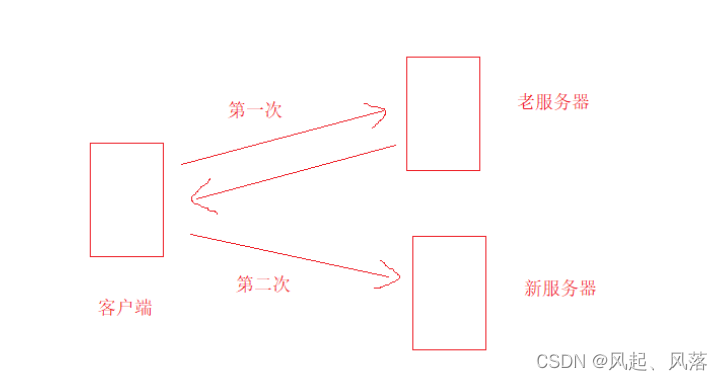
The server has some reasons, such as changing the manufacturer from Alibaba Cloud to Tencent Cloud.
However, the user does not know that the user may still make a request to the old server.
At this time, the current host will not provide services to the client, but will tell the client A new address needs to be accessed
, so the client will initiate a second request to access the new server.
This behavior is called redirection.

For example: There is a XXX Malatang restaurant at the east gate of your school. You and your friends are in the dormitory.
At the east gate of your school, there is a road at the door. This road is under construction, but you can still walk there, so You and your friends went to a Malatang restaurant for a meal
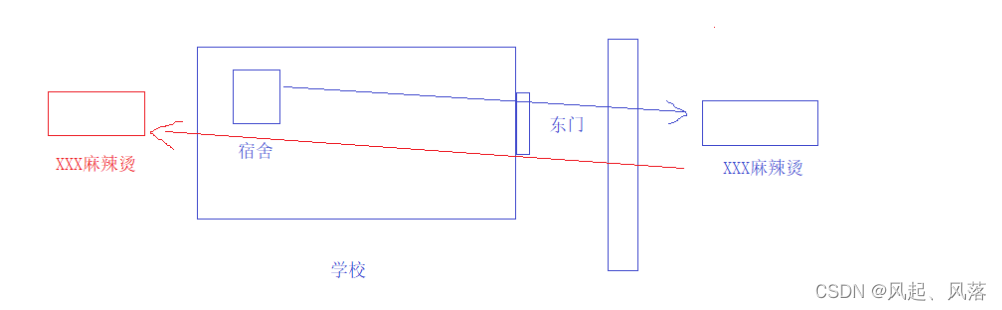
A few months later, you two wanted to eat Malatang again.
But at this time, a piece of paper was posted at the door of Malatang. Because of the road construction at the door, the dining environment of our restaurant was not very good, so the restaurant was moved to Ximen
because you two wanted Malatang very much. It was hot, so I went to Ximen
This behavior is called a redirect
Because XXX Malatang is a temporary move, they don’t know when they will move back to the east gate, so every time they eat Malatang, they have to go to the East Gate to check it out. If they are not there, they go to Ximen to eat Malatang. This behavior is
called temporary Redirect
(it will go to the old address every time, and then jump from the old address to the new address).
Temporary redirection does not change any address information of the browser.
Later, the owner of the Malatang shop found that the business in Ximen was better than that in Eastmen, because Ximen was closest to the school dormitory, so the boss wanted to attract all the old customers to the new Ximen store, so he posted a notice again in the Eastmen Malatang
shop
because The restaurant's dining environment is not good due to road construction at the entrance. If you want to eat Malatang in the future, you can go directly to Ximen. This store will no longer be operating.
At this time, you and your friends still come to the East Gate to eat Mala Tang as usual, but after finding the notice, you have to go to the West Gate. After
a while, you and your friends go directly to the West Gate to eat Mala Tang
(after redirecting once) , I will go to a new place next time)
This behavior is called a permanent redirect.
A permanent redirect changes the browser's local bookmarks.
It can be found that whether it is a temporary redirect (302) or a permanent redirect (301), a new address will be left at the Dongmen Malatang store, and the
client will return a status code of 301 302 307 plus Location, followed by Location. Can follow a new store address
Location: Used with 3xx status code to tell the client where to visit next.
Temporary redirection in action
In the HandlerHttp callback function of Main.cc,
as long as the user sends a request, redirect directly
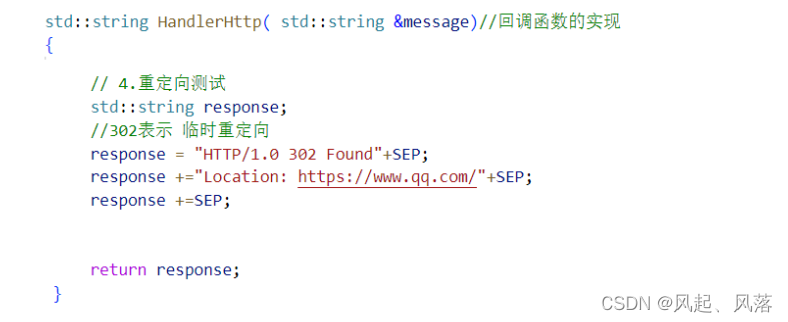
Define a string response, add 302 (temporary redirection) to it
and redirect to https://www.qq.com/

Enter the host IP + port number and you will jump directly to the qq official website.
Practical practice of permanent redirection

Define a string response, add 301 (permanent redirect) to it
and redirect to https://www.baidu.com/
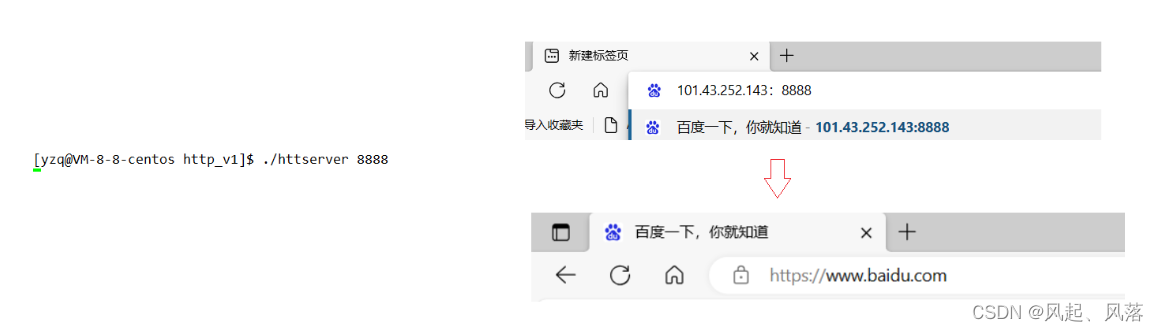
Enter the host IP + port number and you will jump directly to the Baidu official website.
Even if you comment out the code, run the executable program, and enter the host IP+8888, it will still be the official Baidu website.
4. About Http session persistence function
HTTP itself is stateless.
For example: after accessing file1, after a while, you still want to access file1. HTTP does not know that file1 was accessed some time ago and will still make requests.
After opening site B and logging in the user, I found that when I opened site B again, the user was already logged in, so cookies and session
cookies are needed : used to store a small amount of information on the client, usually used to implement the session function.
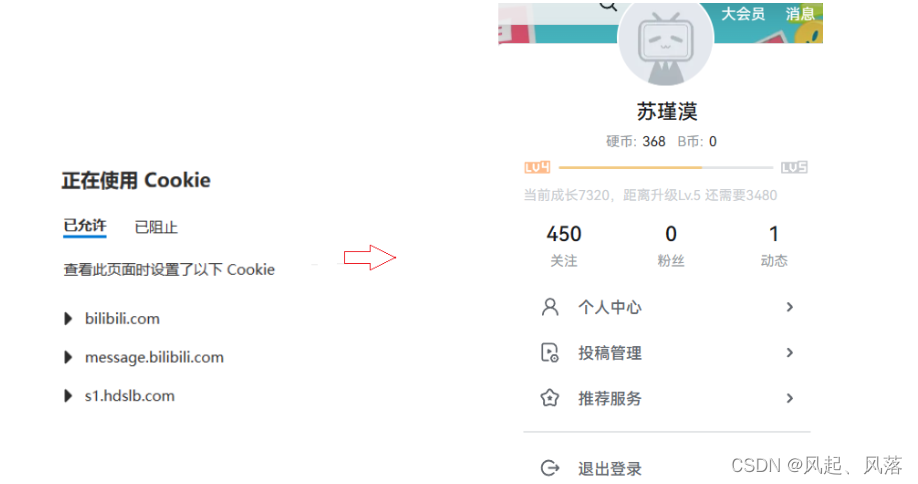
When logging in, the server will pass some Http options to the local browser and write some cookie information locally.
So when re-entering site B, the user has already logged in.
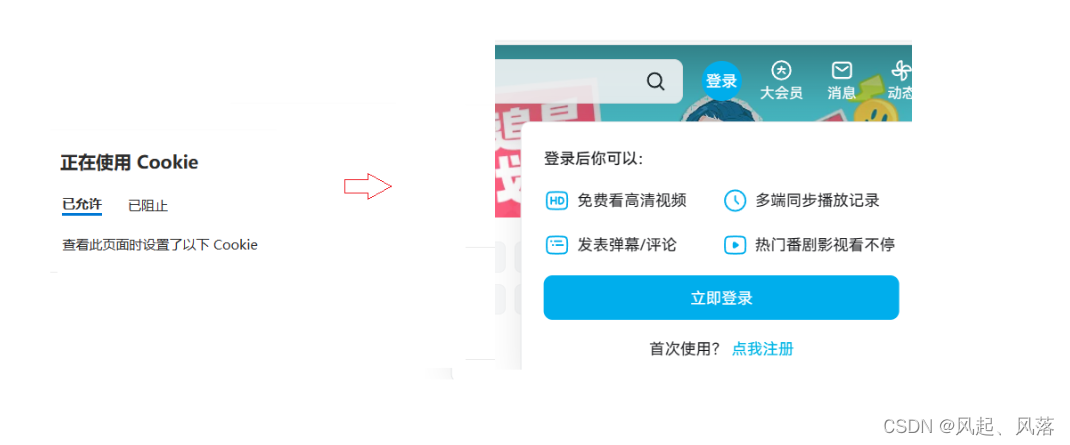
If you delete the cookies corresponding to site B and enter site B again, you will need to log in again.
Use of cookies
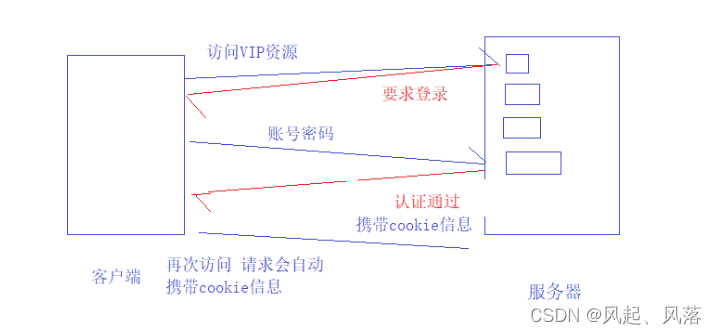
There are many resources in the server.
When requesting a certain resource, if the server finds that there is no login, it will ask the client to log in.
After entering the account and password, the server will authenticate the account and password
. If the authentication is passed, it will return that the authentication is successful. news
The server carries private information (user name, password, etc.) into the Http response through Set-Cookie.
When the browser receives the information carrying the cookie, it saves the cookie information in the response locally.
The browser has two local storage solutions. : Memory level, file level
Whenever you visit the same website in the future, the request will carry cookie information (automatically done by the browser)
for automatic identity authentication, so the user does not need to enter their account and password.
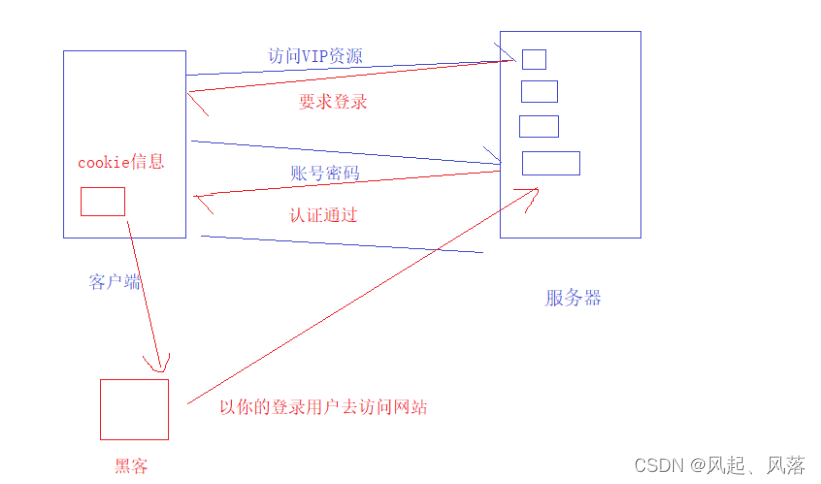
When you click on some inappropriate links sent by hackers, the hackers will steal all the cookie information.
If the hacker also visits the website you have visited, the logged-in user on the website will still be you.
Proposal of session id
The previous solution has obvious shortcomings. Hackers can obtain the corresponding account password and other information,
so use the current solution.
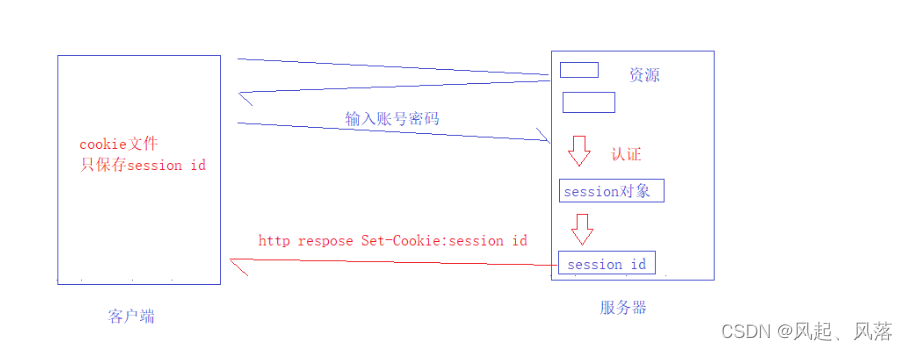
There are many resources in the current server.
When requesting a certain resource, if the server finds that there is no login, it will ask the client to log in.
When logging in, you need to use the POST method and enter the account and password.
After entering the account and password, the server will authenticate the account and password.
If the authentication is passed, the new solution will form a session object on the server (filled with the current user's basic information).
And the seesion id (the sequence formed in 10/16 hexadecimal is guaranteed to be unique)
passes the session id to the client through the http response.
When accessing later, the Http request will carry the session id, and you can use the session id to confirm whether it exists. If it exists, you can access the resource.
Even if a hacker steals your information again, they will only steal the session ID. Although your identity will still be used to access resources
, there is no need to worry about the user's account and password being leaked.