Table of contents
3 Automatic marker-free LiDAR-camera calibration
3.1 Based on information theory
3.1.1 Point cloud and camera attribute pairs
3.1.2 Statistical similarity estimation
3.2.2 Feature matching strategy
3.4 Methods based on deep learning
Summary
LiDAR and camera calibration are very important. Traditional methods rely on specific markers or require manual intervention, which is very inconvenient. This article provides an in-depth report on the automatic marker-free LiDAR-camera calibration method. The methods are mainly divided into four categories: based on information theory, features, self-motion and deep learning.
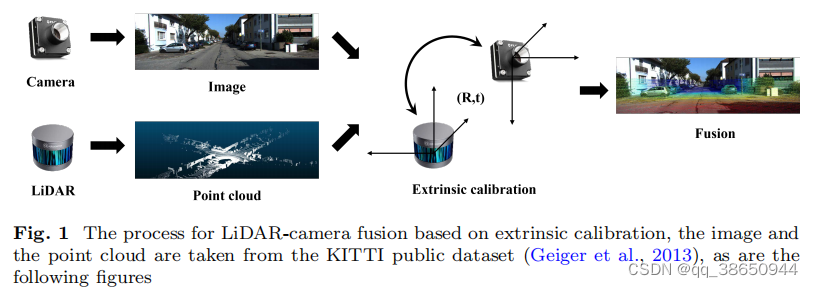
3 Automatic marker-free LiDAR-camera calibration
3.1 Based on information theory
measure the statistical similarity between joint histogram values of several common properties between the two modalities
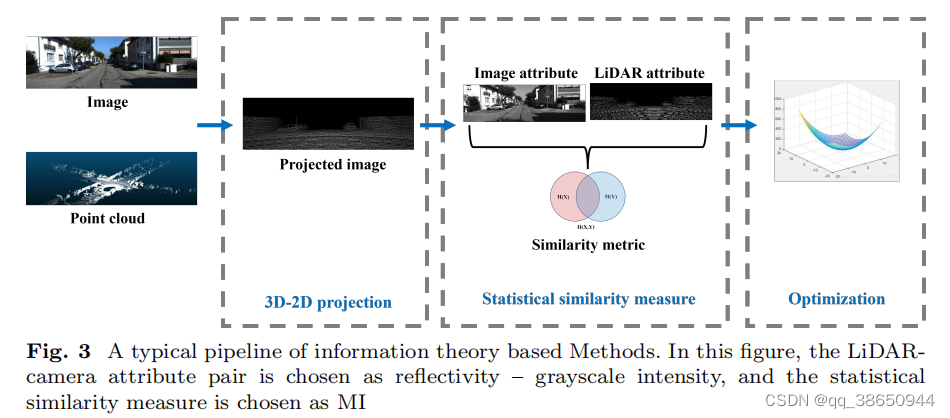
The external parameters are mainly estimated by maximizing the information similarity transformation between radar cameras. The similarity can have a variety of information measures. The basic rules are as follows. The main purpose is to project the point cloud into the image coordinate system according to T and solve the information IM of the two images.
 The above method is mainly divided into three steps:
The above method is mainly divided into three steps:
1) 3D->2D projection of LiDAR points: using external parameter T
2) Statistical similarity estimation: IM mainly estimates the statistical similarity between the image obtained by LiDAR point projection and the target image. Some feature distributions of the two are similar, so the selection of different features and the selection of statistical features will lead to different calibration methods.
3) Optimization: The statistical estimation of IM is generally a non-convex problem, so an optimization algorithm is required to obtain the global optimal solution. A typical process is shown in Fig3
It can be noted that radar cameras have multiple similarly distributed properties. For example, radar points with high reflectivity often correspond to bright surfaces in the image, and points with low reflectivity correspond to dark areas in the image. The correlation between radar reflectivity and camera intensity is also often used to estimate the similarity between the two. Gradient magnitude and orientation extracted from radar point clouds and camera images can also be used.
3.1.1 Point cloud and camera attribute pairs
1) Reflection intensity-grayscale value
2) Plane normal vector - gray value: Because of the light source in the environment, the surface normal vector will affect the gray value of the corresponding pixel in the image.
3) Gradient size and direction - Gradient size and direction: When comparing two multi-modal images, if the pixel value of one image is significantly different from the surroundings, the corresponding area of the corresponding image of the other modality will also change drastically. The gradient size and direction of the 2D image can be calculated using the Sobel operator, while each pixel of the radar point cloud can be projected onto a sphere first, and its gradient can be calculated using the 8 nearest neighbor points [Multi-modal sensor calibration using a gradient orientation measure ]
4) 3D semantic labels - 2D semantic labels: because the semantic labels of the corresponding areas are consistent. Semantic tags can be obtained using deep learning
5) Association of 3D-2D attribute pairs: Some papers have found that the fusion effect of using multiple features is better, and different attributes are fused using the correct weights. These attribute sets often use the aforementioned multiple attribute pairs.
3.1.2 Statistical similarity estimation
1) Mutual Information (MI): MI estimates the statistical correlation between two random variables or amounts of information. According to Shannon's entropy theorem, MI is defined as
That is, the sum of individual entropies minus the joint entropy
where p represents the marginal probability and joint probability respectively. In practice, we can use the reflection value of the radar and the intensity value of the pixel as two random variables X and Y. Then the probability distribution of the two can be calculated using some methods, such as kernel density estimation (KDE) [ Multivariate density estimation: Theory, practice and visualization ]
2) Normalized Mutual Information (NMI): MI will be affected by the total amount of information between the two. The similarity transformation corresponding to the aforementioned radar camera may result in a large MI estimate value. NMI solves this problem by normalizing the MI value.

3) Gradient Orientation Measure (GOM): It calculates the gradient direction of two pictures, and the gradient value can also be used as a weight. The main difference between GOM and NMI is that GOM uses the gradient of points instead of intensity, so it takes into account the geometric features of adjacent points and images.
4) Normalized Information Distance (NID): It is a similarity measurement method that can be used to match sensors of different modalities. Its normalization property is also better than MI because it does not depend on the total information amount of the two images. So it does no harm to global image alignment of two high-texture image areas.
5) Bagged Least-squares Mutual Information (BLSMI): Contains kernel-based dependency estimator and bootstrap aggregating noise suppression method. Compared with MI, its advantage is that it is more robust to external points because it does not include logarithms.
6) Mutua Information and Distance between Histogram of Oriented Gradients: It is a measurement method that combines the distance between NMI and directional gradients to estimate the consistency between images.

When the image is not artistic enough, DHOG is better than NMI. When the image is artistic, NMI is more accurate, so MIDHOG can inherit the properties of both in different scenes.
7) Mutual Information Neural Estimation (MINE): Use neural networks to estimate the mutual information of high-dimensional continuous random variables. It is scalable, flexible, and trainable via back-propm. It can be used for mutual information estimation, maximization, and minimization.
MINE uses Donsker-Varadhan duality to represent MI:

are the neural network and
are the parameters of the neural network.
3.1.3 Optimization method
3.2 Feature-based
Extract geometric , semantic or motion features from the environment
Geometric features are mainly constructed from geometric features such as points or edges in the environment. Semantic features are mainly high-level data information, such as skylines, vehicles, and poles. Motion features use motion characteristics, such as posture, speed, acceleration, etc.
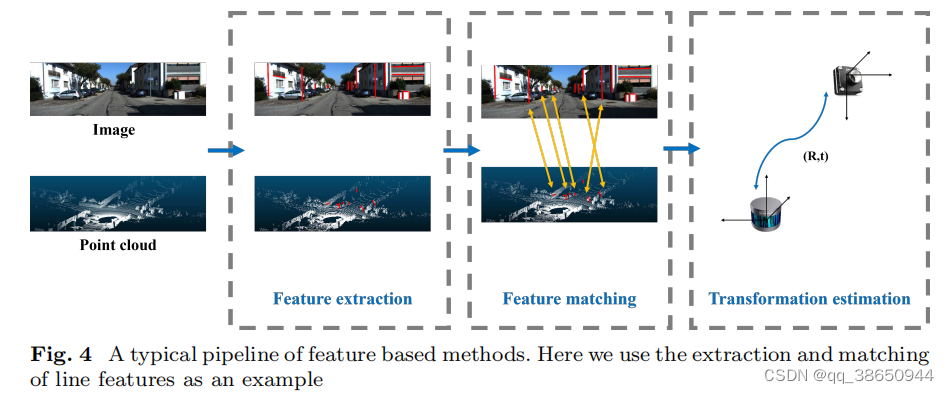
Feature-based methods are mainly divided into feature extraction, feature matching and external parameter estimation.
3.2.1 Feature extraction
1) Point feature extraction
Forstner operator:
Corner: You can use edge detectors, such as the Sobel operator. This can be used in intensity maps of images as well as point cloud projections.
SIFT: variant SURF is also available.
2) Edge feature extraction
Depth continuity-intensity value difference: Calculate the depth difference with adjacent points, and eliminate points whose depth difference is less than the threshold. You can also upsample the point cloud first, and then calculate the depth gradient change. Edges in images can also be extracted by detecting shape changes. The general assumption is that there is a one-to-one correspondence between the radar and the edges in the point cloud.
Depth continuity-Sobel operator: Point clouds use depth continuity to extract edges, while pictures can use the Sobel operator, Canny detector or LSD algorithm. In particular, the Canny edge detector uses a multi-stage algorithm to detect a larger range of edges, which includes steps such as noise suppression, intensity gradient estimation, non-maximum suppression, and hysteresis threshold methods. LSD is a gradient-based edge extraction method in grayscale images.
3D Line Detector-LSD
Deep Continuity-Canny Detector
The above-mentioned depth continuous edges can be extracted through dense point clouds, such as solid-state radar. In particular, for example, changes in plane intersections can be obtained through voxel segmentation and plane fitting.
Deep Continuity-L-CNN
3) Semantic feature extraction
It is worth noting that there are many similar lines in the real environment, which increases the difficulty of calibration. So semantic features such as skyline, vehicles and lane lines.
Skyline-Skyline
Lane and Pole-Lane and Pole
3D Semantic Center-2D Semantic Center: Mainly using deep learning
4) Motion feature extraction
Motion trajectory - motion trajectory: The trajectory of the radar camera can be obtained separately, and the two can be registered to complete the radar camera calibration.
3.2.2 Feature matching strategy
Descriptors similarity: brute force matching, nearest neighbor search, where Euclidean distance can be used as a metric. RANSAC needs to be used to eliminate incorrectly matched point pairs.
Spatial geometrical relation: Directly use spatial set association and optimization methods to construct the relationship between two features.
Semantic relation: Match through the semantic level. For example, points on the same vehicle can be matched.
Trajectory relation: Trajectories can be matched at the same time, and the speed and curvature can also be matched.
3.3 Based on own movement
3.3.1 Hand-eye calibration
AX=XB
refine : (focus on)
1) Edge alignment: line feature constraints
2) Intensity matching: Some articles align radar reflectivity and camera image intensity through mutual information measurement methods.
3) Depth matching: The radar depth map uses initial external parameters to project into the image, and the camera depth map uses monocular depth estimation.
4) Color matching: This assumes that the points in the point cloud have the same color in two consecutive frames. First, the point cloud is projected to the current picture to obtain the corresponding color, and then the point cloud is projected to the next frame of picture based on the motion information. By minimizing the average difference between two frames, more accurate external parameters can be obtained
5) 3D-2D point matching: The 3D coordinates of the 2D features are obtained through triangulation, and the results use nonlinear optimization. (SFM)
3.3.2 3D structure estimation
Recover the 3D structure of the environment from moving images, namely SFM. Then use registration methods such as ICP, which is bundle block adjustment refinement. Mutual information can also be used for global refinement.
After SFM, ICP coarse matching, and then the 3D radar points are projected into the image for optimization using edge feature points.
Because SFM does not have enough points and ICP is not accurate enough, the article also designs a method of self-calibration from semantic features, and then maximizes the overlap area of the same target pair.
The target-level registration method is used, that is, SFM first obtains the points, and then introduces target-level alignment based on the target detection results.
Some articles use point ICP to eliminate registration errors after target-level registration, and then introduce a curve-based non-rigid point cloud registration refinement step based on non-uniform rational basis spline approximation (they introduce a curve-based non-rigid point cloud registration refinement step ) -rigid point cloud registration refifinement step build on the non-uniform rational basis spline approximation. )
3.3.3 Other methods
Try to correlate video and radar data obtained from a moving vehicle. The initial external parameters are obtained from the IMU motion signal, and then refined by registering the contour of the camera radar.
A radar-fused visual odometry framework is developed to integrate self-motion assessment into the calibration of radar cameras. The main idea is that the quality of external parameters will affect the performance of ego-motion.
Under the assumption of Gaussian noise, the Gauss-Helmert model is used to calibrate the external parameters of the radar camera. Given the constraints of a single sensor motion, the Guass-Helmert paradigm is used to jointly optimize external parameters and reduce pose observation errors.
A motion-oriented method is proposed. Given a series of synchronized radar camera data, the motion vector of each sensor is calculated individually, and then the external parameters are estimated.
When using motion information for external parameter calibration, sufficient motion in all directions and all axes is required. If the sensor moves in a plane, some parameters are not appreciable. [ Automatic multi-sensor extrinsic calibration for mobile robots ] Computes 2D parameters (x, y, yaw) from the sensor's incremental motion and then uses ground estimates (z, pitch, roll)
Use dual quaternions (DQs) to represent rotations and translations with fewer parameters. It restricts the optimization to plane calibration and then combines local and global optimization methods to estimate the final result.
3.4 Methods based on deep learning
Use neural network models to evaluate external parameters