Selenium usage
Selenium
Overview
Selenium is an open source framework for automating browser operations. It provides a set of tools and libraries for testing the functionality and user interface of web applications.
Using Selenium, you can write scripts to simulate user interaction in the browser, such as clicking, filling out forms, selecting drop-down boxes, etc. These scripts can be run automatically and verify that the application behaves as expected.
Selenium supports a variety of different programming languages, including Java, Python, C#, etc., allowing developers to write and execute test scripts in a language they are familiar with.
Selenium also has different tools and components, including Selenium WebDriver for interacting directly with browsers, Selenium Grid for executing tests in parallel across multiple browsers and platforms, and provides a rich API and functionality for handling browsing search, interaction, and assertions on page elements.
Official website:https://www.selenium.dev/
Official website document:https://www.selenium.dev/documentation/
Chinese documentation:https://python-selenium-zh.readthedocs.io/zh_CN/latest/

working principle
Utilize the browser's native API and encapsulate it into the object-oriented Selenium WebDriver API (which encapsulates various functions of the browser). The program script controls the browser (Google and Microsoft) through the Selenium API, operates the browser page elements, or operates the browser itself. (Screenshot, window size, startup, shutdown)
Application scenarios
automated test:
Selenium is one of the most commonly used automated testing tools. It can simulate real user interaction behaviors and automatically execute various test cases, including functional testing, regression testing, and performance testing. With Selenium, you can automatically test various functions of your web application, verify the correctness of the user interface, and capture and report problems.
Compatibility testing:
Using Selenium, automated test scripts can be run on different browsers and operating systems to verify the compatibility of web applications in various environments. This ensures that the application runs consistently across browsers and platforms.
Data scraping and web summarization:
Selenium can be used to crawl web content to obtain the required data. By writing scripts, you can simulate users operating the browser, accessing web pages and extracting data, such as price comparisons, news summaries, etc.
Automated form filling:
When a large amount of form data needs to be filled in, doing it manually can consume a lot of time and effort. Using Selenium, you can write scripts to automatically fill in forms and improve efficiency.
UI automation testing:
Selenium can verify the correctness and consistency of the user interface. By simulating user interactions and operations, various scenarios of user interfaces can be automatically tested to ensure their correctness and functionality.
Front-end development and debugging:
Developers can use Selenium to debug and verify front-end code. With automated test scripts, you can simulate user actions and see if the rendering and functionality of the page work properly.
Install browser driver
Take the Chrome browser as an example to install the browser driver.
Notice:必须下载对应的 chrome 版本对应的驱动
chrome driver:https://sites.google.com/chromium.org/driver/
chrome driver (old):https://sites.google.com/a/chromium.org/chromedriver/
Domestic Taobao mirror:http://npm.taobao.org/mirrors/chromedriver/
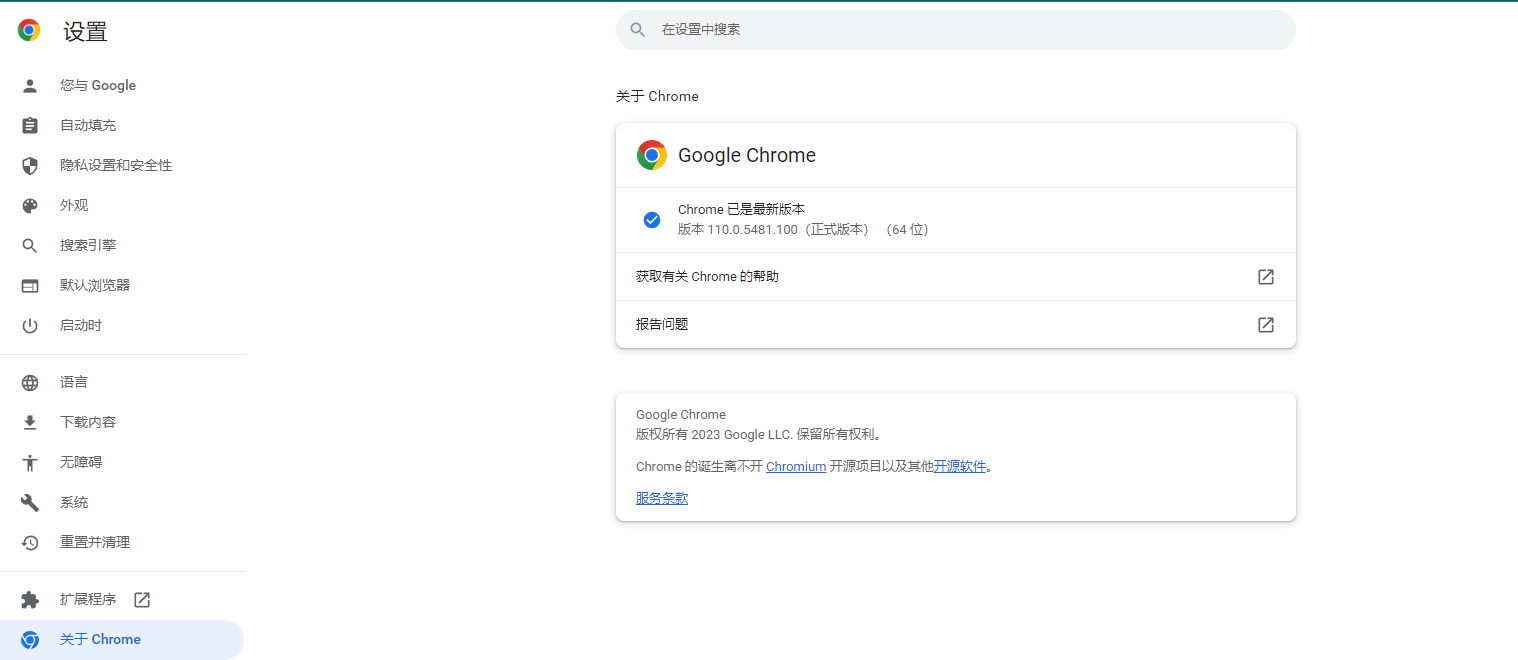
1. Determine Chrome version
Determine the Chrome version as: 110.0.5481.100
2. Determine the ChromeDriver version
1. Get the Chrome version number, delete the last part, and get 110.0.5481.
2. Splice the results to https://chromedriver.storage.googleapis.com/LATEST_RELEASE_the back.
3. Get the URL: https://chromedriver.storage.googleapis.com/LATEST_RELEASE_110.0.5481, and access the link to get the ChromeDriver version number

3. Download ChromeDriver
Just find the corresponding version of ChromeDriver and download it. Since it is the latest Chrome browser, you can find it on the homepage at once.
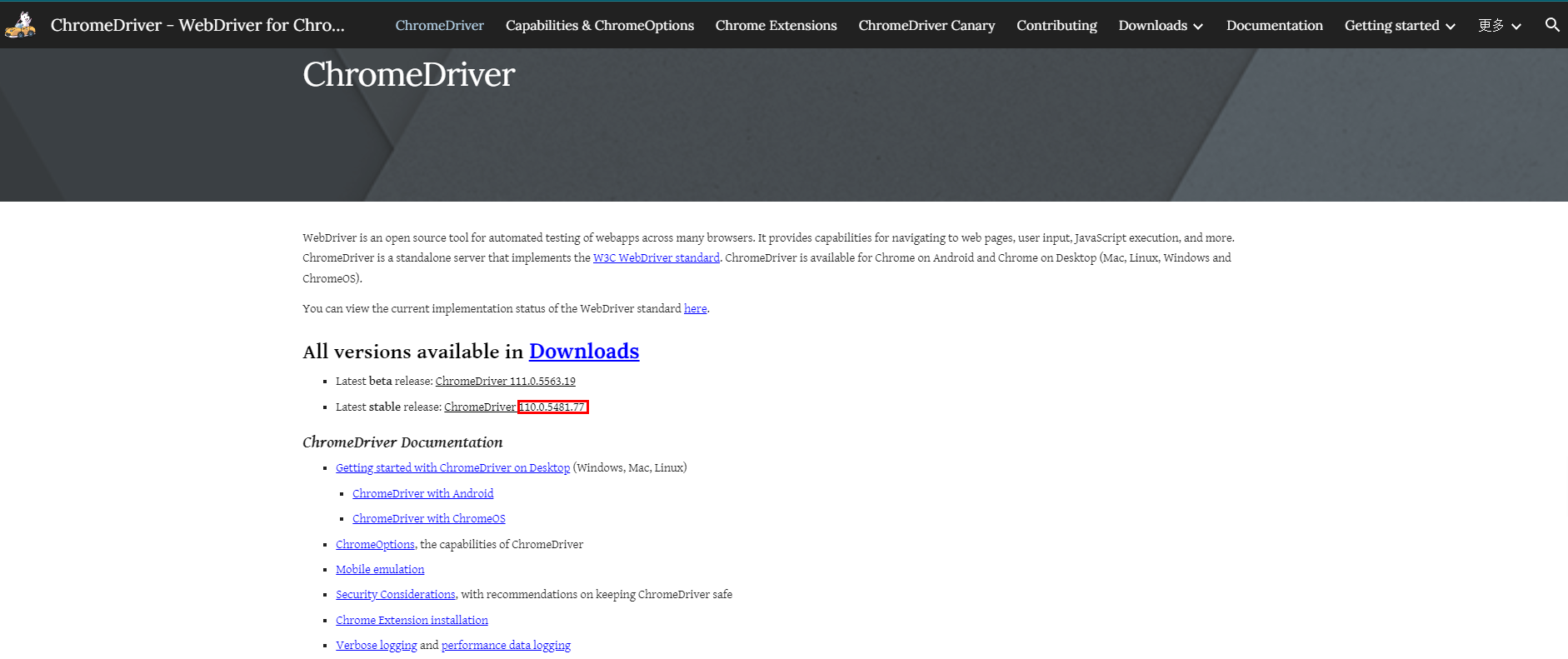
Download different ChromeDrivers according to the operating system
3. Configure environment variables (optional)
After decompressing the compressed package, you will get chromedriver.exethe executable file, and the python code can be called directly.
In the path environment variable, add chromedriver.exe the directory where it is located
basic use
Install Selenium module
pip install selenium
important point
Due to version iteration, the new version of selenium no longer uses
find_element_by_idmethods, but usesfind_element(By.ID, ''). For details, refer to the selenium version.
Due to version iteration, exceptions may occur:AttributeError: 'WebDriver' object has no attribute 'find_element_by_id'
from selenium import webdriver
from selenium.webdriver.common.by import By
# 老版本
input_element = browser.find_element_by_id("kw")
# 新版本
input_element = browser.find_element(By.ID, 'kw')
Use analytics
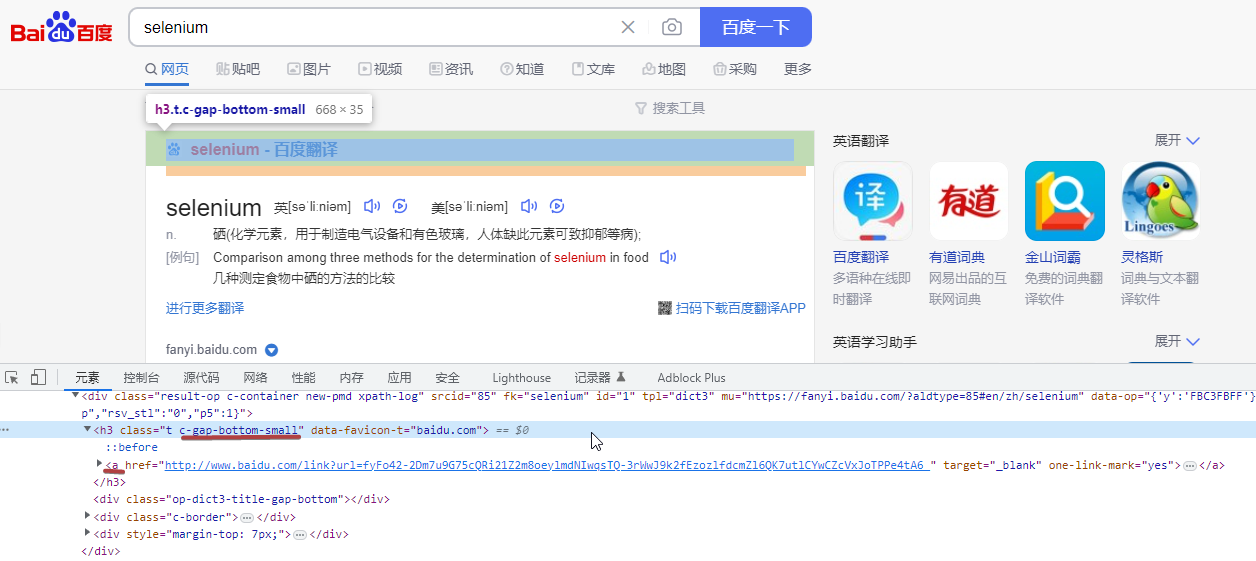
Use Baidu to automatically search for
seleniumkeywords and automatically click to jump to a search result.
Get the input box element and get the search button element information
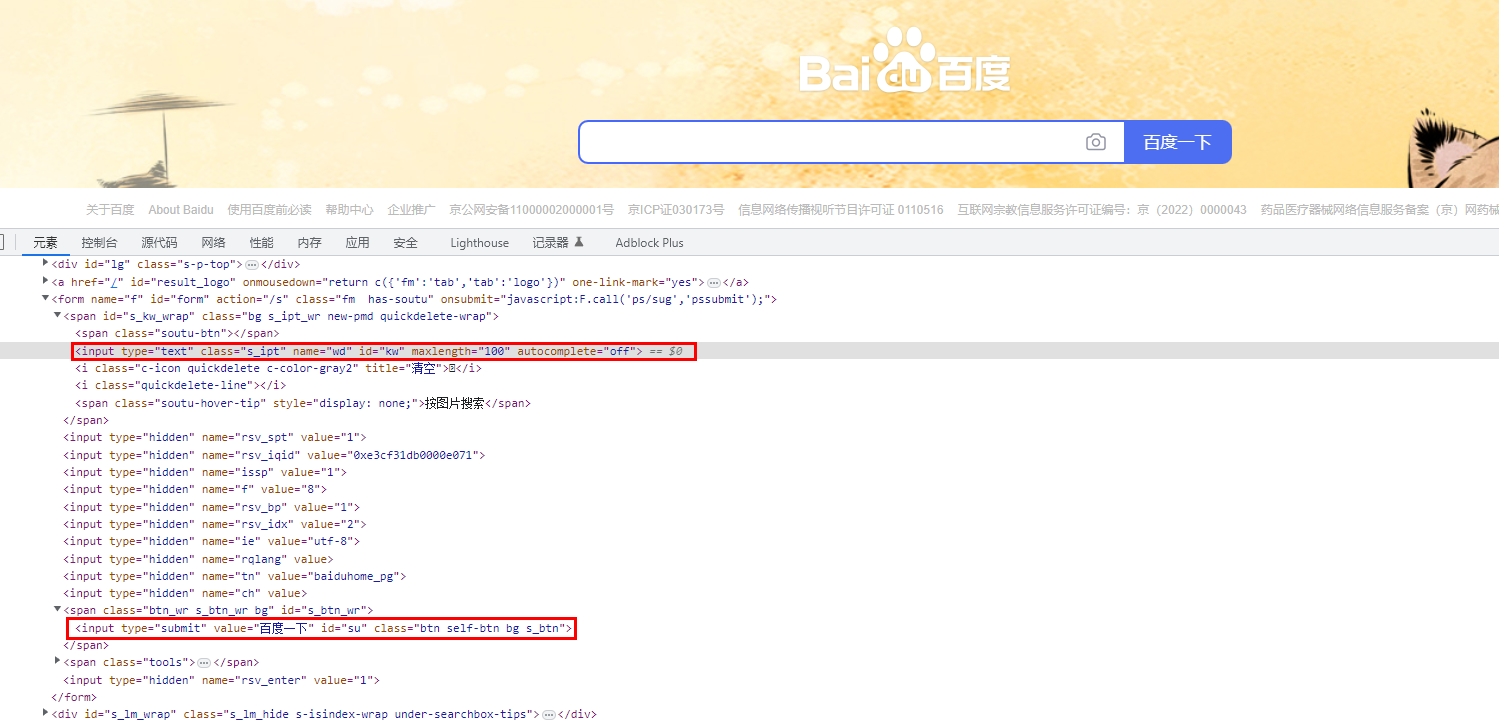
Get the address information of the first search result
Code
# 导入模块
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 创建浏览器对象,需指定驱动。驱动有2种方式获取
# 1.通过手动指定浏览器驱动路径
browser = webdriver.Chrome('D:\Development\chromedriver_win32\chromedriver.exe')
# 2.通过$PATH环境变量寻找驱动,如果寻找不到就报错
# browser = webdriver.Chrome()
# 指定操作浏览器对象的行为
# 让浏览器访问网页
browser.get("https://www.baidu.com/")
# 获取输入框元素
# input_element = browser.find_element_by_id("kw")
input_element = browser.find_element(By.ID, 'kw')
# 输入内容
input_element.send_keys('selenium')
# 获取搜索按钮
button_element = browser.find_element(By.ID, 'su')
# 点击搜索
button_element.click()
time.sleep(3)
# 获取地址
url_element = browser.find_element(By.CLASS_NAME, "c-gap-bottom-small").find_element(By.TAG_NAME, 'a')
url_element.click()
time.sleep(5)
# 退出浏览器
browser.quit()
Common methods
driver object
In the process of using selenium, after instantiating the driver object, the driver object has some commonly used properties and methods.
driver.page_source 当前标签页浏览器渲染之后的网页源代码
driver.current_url 当前标签页的url
driver.close() 关闭当前标签页,如果只有一个标签页则关闭整个浏览器
driver.quit() 关闭浏览器
driver.forward() 页面前进
driver.back() 页面后退
driver.screen_shot(img_name) 页面截图
Locating label elements and obtaining label objects
There are many ways to locate tags in selenium and return tag element objects.
old version
find_element_by_xxx 返回第一个符合条件
find_elements_by_xxx 返回符合条件所有元素的WebEelemnt列表
find_element匹配不到就抛出异常,find_elements匹配不到就返回空列表
find_element_by_id 通过ID
find_element_by_class_name 通过class查询元素
find_element_by_name 通过name
find_element_by_tag_name 通过标签名称
find_element_by_css_selector css样式选择
find_element_by_link_text 通过链接内容查找
find_element_by_partial_link_text 通过链接内容包含的内容查找,模糊查询
find_element_by_xpath 通过xpath查找数据
new version
find_element(BY, 'str')
find_elements(BY, 'str')
find_element(By.ID, 'id')
find_element(By.CLASS_NAME, 'calss_name')
find_element(By.NAME, 'name')
find_element(By.TAG_NAME, 'tag_name')
find_element(By.CSS_SELECTOR, 'css_selector')
find_element(By.LINK_TEXT, 'link_text')
find_element(By.PARTIAL_LINK_TEXT, 'partial_link_text')
find_element(By.XPATH, 'xpath')
Get text content and attribute values
Get element attribute value
element.get_attribute('属性名')
Get element text content
element.text
Enter data into the input box
input_element.send_keys('selenium')
Perform a click on an element
button_element.click()
Use a headless browser
The vast majority of servers have no interface. Selenium controls Google Chrome in a headless mode. The interfaceless mode is also called the headless mode.
Using pyantomjs driver
It is not recommended to use the pyantomjs driver. The pyantomjs method has been eliminated by Selenium.
download link:http://phantomjs.org/download.html
Usage
# 导入模块
import time
from selenium import webdriver
# 创建浏览器对象
browser = webdriver.PhantomJS(executable_path=r"D:\Development\phantomjs-2.1.1-windows\bin\phantomjs.exe")
# 指定操作浏览器对象的行为
# 让浏览器访问网页
browser.get("https://www.baidu.com/")
# 保存截图调试
browser.save_screenshot('screenshot.png')
Exception 1:
The new version of selenium has abandoned PhantomJS, so
AttributeError: module 'selenium.webdriver' has no attribute 'PhantomJS'exceptions will occur.
uninstall selenium
pip uninstall selenium
Install the specified version of selenium
pip install selenium==3.14.0
Exception 2:
selenium.common.exceptions.WebDriverException: Message: 'phantomjs.exe' executable needs to be in PATH.
Solution 1: Add an r in front of the full path
browser = webdriver.PhantomJS(executable_path=r"D:\Development\phantomjs-2.1.1-windows\bin\phantomjs.exe")
Solution 2: Add the path to the bin file to the system variable
C:\Users\Admin>phantomjs -v
2.1.1
Set chrome startup parameters
# 导入模块
from selenium import webdriver
# 创建浏览器对象,指定配置参数
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 开启无界面模式
options.add_argument('--disable-gpu') # 禁用gpu
# 实例化带有配置对象的driver对象
browser = webdriver.Chrome('D:\Development\chromedriver_win32\chromedriver.exe', chrome_options=options)
# 指定操作浏览器对象的行为
# 让浏览器访问网页
browser.get("https://www.baidu.com/")
# 保存截图调试
browser.save_screenshot('screenshot.png')
other operations
Window switching
The browser may open multiple web pages and needs to locate which form the currently obtained web page element is. Switch windows through browser.switch_to.window
# 获取当前所有的窗口
print(browser.window_handles)
# 获取当前选中窗体的名称
print(browser.current_window_handle)
print("切换前:", browser.title)
# 执行js新开一个标签页
js = 'window.open("https://www.baidu.com");'
browser.execute_script(js)
time.sleep(3)
# 获取当前所有的窗口
print(browser.window_handles)
# 切换窗体
browser.switch_to.window(browser.window_handles[1])
print("切换后:", browser.title)
ifrme switch
iframe is a technology commonly used in HTML, that is, one page is nested within another web page
The browser webpage may contain an iframe webpage. Selenium cannot access the content in the frame by default, so it is necessary to obtain the iframe webpage element. Switch iframe via browser.switch_to.frame
import time
# 导入模块
from selenium import webdriver
# 创建浏览器对象
# 参数驱动路径
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get("https://mail.qq.com/cgi-bin/loginpage")
print("切换前:", browser.page_source)
# 获取iframe元素对象
iframe_element = browser.find_element(By.ID, 'login_frame')
# 切换 iframe
browser.switch_to.frame(iframe_element)
print("切换后:", browser.page_source)
# 切换回 主窗口
browser.switch_to.default_content()
print("切回后:", browser.page_source)
# 利用切换标签页的方式切出frame标签
# windows = driver.window_handles
# driver.switch_to.window(windows[0])
time.sleep(5)
# 退出浏览器
browser.quit()
Set up User-Agent and proxy
When selenium controls Google Chrome, the User-Agent defaults to Google Chrome and can be replaced.
Selenium can also use proxy IP to control the browser.
options = webdriver.ChromeOptions()
# 切换User-Agent
options.add_argument('--user-agent=Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1')
# 设置代理
options.add_argument('--proxy-server=代理服务器地址') # 设置代理
browser = webdriver.Chrome('./chromedriver',chrome_options=options)
Get web page source code
The obtained web page source code is the result source code after JS page execution.
browser.page_source
Cookie operations
selenium can help handle cookies in pages
获取所有Cookies
browser.get_cookies()
把cookie转化为字典
cookies_dict = {
cookie['name']: cookie['value'] for cookie in browser.get_cookies()}
通过名字获取Cookie
browser.get_cookie()
添加Cookie
browser.add_cookie()
通过名字删除Cookie
browser.delete_cookie()
删除所有Cookie
browser.delete_all_cookies()
execute javascript
selenium allows the browser to execute specified js code
# js语句:滚动
js = 'window.scrollTo(0,document.body.scrollHeight)'
# 执行js的方法
browser.execute_script(js)
js ="alert("hello world")"
browser.execute_script(js)
Page waiting
During the loading process, the page needs to spend time waiting for the response of the website server. During this process, the tag element may not be loaded yet, and at the same time, data is obtained, causing the browser to fail to find the element that needs to be operated, thus causing an exception. At this time, the program needs to wait. There are three ways:
selenium page waiting for classification
强制等待
隐式等待
显式等待
1. Forced waiting
The setting time is too short and the elements are not loaded. Setting up takes too long and is a waste of time
time.sleep(秒数)
2. Hidden waiting
Implicit waiting is aimed at element positioning. Implicit waiting sets a time to determine whether the element is successfully positioned within a period of time. If it is completed, proceed to the next step. If the positioning is not successful within the set time, a timeout loading will be reported.
browser.implicitly_wait(等待时间)
3. Explicit waiting, each element can define its own check conditions
Every few seconds, check whether the waiting condition is met. If it is met, stop waiting and continue executing subsequent code. If it is not reached, it will continue to wait until the specified time is exceeded, and a timeout exception will be reported.
1. Manually implement page waiting
t = time.time()
# 定义超时时间
timeout = 60
while True:
try:
# 超时时间间隔
time.sleep(1)
url_element = browser.find_element(BY.ID, "OK")
break
except:
# 超时处理
if time.time() - t > timeout:
break
pass
2. Provide explicit waiting API
# 等待对象模块
from selenium.webdriver.support.wait import WebDriverWait
# 导入等待条件模块
from selenium.webdriver.support import expected_conditions as EC
# 导入查询元素模块
from selenium.webdriver.common.by import By
# 使用selenium api 实现显性等待
# 创建等待对象,传入:浏览器对象、超时时间、检查元素时间间隔
wait = WebDriverWait(browser, 60, 0.1)
# 检查元素是否存在,参数是一个元祖,元祖内部描述等待元素查询方案
# EC.presence_of_element_located()
# 检查元素是否可见
# EC.visibility_of_element_located()
url_element = wait.until(EC.presence_of_element_located((By.CLASS_NAME, "OK")))