1. Introduction to CAP theory
CAP is the basic theory of distributed applications. It discusses how distribution meets the issues of consistency, availability, and network partitioning.
C (Consistency): Consistency requires all nodes to maintain consistent data at the same time.
A (Availability): Availability requires that the application itself is available when an exception occurs on some nodes.
P (Partition Tolerance): Network partition fault tolerance, distributed applications will have multiple nodes, and network communication is required between nodes, and network interruption or timeout may occur.
2. CAP can choose two out of three?
The biggest misunderstanding of the CAP theory is that the three factors are of equal status. In fact, it is not the case. In a distributed system, P (network partition) is inevitable, so it can only be weighed between APs. Therefore, in practical applications, most of them support CP. or AP. CP pursues consistency at the expense of availability, such as zk. AP pursues availability at the expense of consistency, such as master-slave replication.
Why is P mandatory? Redundancy is necessary to ensure high availability, and A and P cannot be discussed in stand-alone applications. Redundancy will cause partition problems, so P must exist, and P cannot be exchanged for A or C at the expense of A or C.
3. Does strong consistency exist?
3.1 Node communication takes time
We often say that CP is the pursuit of strong consistency, but does strong consistency really exist? As long as there is P (network partition), there will be communication between nodes. Assuming that the communication between nodes is normal, then communication will take time. Although the processing speed of the computer world is on the millisecond, microsecond, or nanosecond level, no matter how fast the processing is, this time is still a non-zero number.
3.2 The only constant is change
The information world is always changing, and even if communication is normal one moment, it may change the next moment. For example, the consumer obtains the available list of service providers from the CP registration center, and selects an address through the load to initiate the call. At this time, there is still the possibility that the node corresponding to this address has died. Therefore, the information you see now may be outdated the next moment.
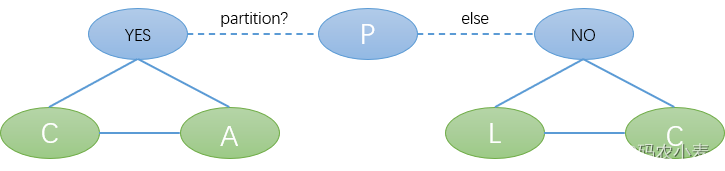
4. PACELC theory
According to the above discussion, in fact, complete strong consistency does not exist, that is, there will be a delay in synchronization between nodes, so there is the PACELC theory. PAC is still the above-mentioned CAP, E is else, L is latency delay, and C is still Consistency. A simple understanding is that when a network partition anomaly occurs, a trade-off needs to be made between A and C, and when there is no network partition anomaly, a trade-off needs to be made between L and C.
5. Typical cases
5.1 mysql master-slave replication
MySQL master-slave replication brings high availability, but even when the network communication is normal, there is still a delay in master-slave synchronization, so at this time, it is necessary to weigh whether the delay is acceptable. If not, you can directly read the master library. Of course, when an exception occurs in master-slave synchronization, it does not affect the reading of data from the slave library, that is, the slave library is available.
5.2 zk distributed lock
Using zk's temporary nodes can implement distributed locks. Zk and the client maintain a live connection through heartbeat. If the connection fails, the temporary nodes will be automatically deleted to release the lock. However, there are many situations in which this connection is maintained. If the network times out or the application freezes, then there will be two processes that acquire the lock, resulting in the failure of the distributed lock. Redis distributed locks also have similar problems, so the use of distributed locks must be be careful.
note:
When building distributed applications, you should look at the big picture and start with the details. Usually, only by meeting the conditions of AP and controlling C according to the actual situation can a robust application be built.