How to ensure the consistency of data without affecting the performance of the system is a key consideration and trade-off for every distributed system. Thus, the consistency level was born:
1. Strong consistency
This consistency level is most in line with user intuition. It requires the system to write what will be read out. The user experience is good, but its implementation often has a great impact on the performance of the system.
2. Weak consistency
This consistency level constrains the system to not promise to read the written value immediately after the write is successful, and to promise how long it will take for the data to be consistent, but it will try to guarantee it to a certain time level (such as the second level). ), the data can reach a consistent state
3. Eventual consistency
Eventual consistency is a special case of weak consistency, and the system will ensure that a data-consistent state can be reached within a certain period of time. The reason why eventual consistency is proposed separately here is because it is a highly respected consistency model in weak consistency, and it is also a model that is highly respected by the industry in the data consistency of large-scale distributed systems
In 2000, Professor Eric Brewer proposed the CAP conjecture. Two years later, the possibility of the conjecture was theoretically proved by Seth Gilbert and Nancy Lynch. Since then, the CAP theory has officially become a recognized theorem in the field of distributed computing. . And deeply affected the development of distributed computing.
The CAP theory tells us that it is impossible for a distributed system to satisfy the three basic requirements of consistency (C: Consistency), availability (A: Availability) and partition tolerance (P: Partition tolerance) at the same time. 2.
C (Consistence) Consistency refers to the characteristic that data can remain consistent between multiple copies (strict consistency)
A (Availability) Availability means that the services provided by the system must always be available, and a non-error response can be obtained for each request - but the data obtained is not guaranteed to be the latest data
P(Network partitioning)分区容错性分布式系统在遇到任何网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务,除非整个网络环境都发生了故障
什么是分区?
在分布式系统中,不同的节点分布在不同的子网络中,由于一些特殊的原因,这些子节点之间出现了网络不通的状态,但他们的内部子网络是正常的。从而导致了整个系统的环境被切分成了若干个孤立的区域。这就是分区。
1、为什么只能 3 选 2
为什么只能 3 选 2?

首先问,能不能同时满足这三个条件?
假设有一个系统如下:
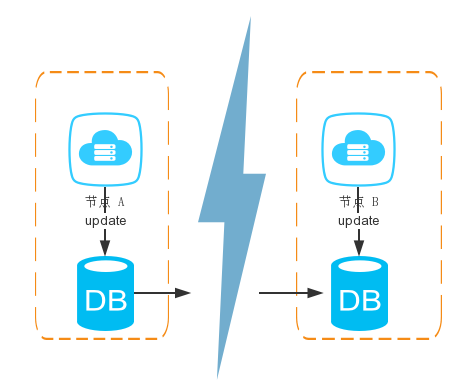
整个系统由两个节点配合组成,之间通过网络通信,当节点 A 进行更新数据库操作的时候,需要同时更新节点 B 的数据库(这是一个原子的操作)。
上面这个系统怎么满足 CAP 呢?
C:当节点A更新的时候,节点B也要更新
A:必须保证两个节点都是可用的
P:当节点 A,B 出现了网络分区,必须保证对外可用。
可见,根本完成不了,只要出现了网络分区,A 就无法满足,因为节点 A 根本连接不上节点 B。如果强行满足 C 原子性,就必须停止服务运行,从而放弃可用性 C。
所以,最多满足两个条件:
CA,一致性,可用性 满足原子和可用,放弃分区容错。说白了,就是一个整体的应用
CP,一致性,分区容错性 满足原子和分区容错,也就是说,要放弃可用。当系统被分区,为了保证原子性,必须放弃可用性,让服务停用
AP,可用性,分区容错性 满足可用性和分区容错,当出现分区,同时为了保证可用性,必须让节点继续对外服务,这样必然导致失去原子性
2、能不能解决 3 选 2 的问题
难道真的没有办法解决这个问题吗?
CAP 理论已经提出了 13 年,也许可以做些改变。
仔细想想,分区是百分之百出现的吗?如果不出现分区,那么就能够同时满足 CAP。如果出现了分区,可以根据策略进行调整。比如 C 不必使用那么强的一致性,可以先将数据存起来,稍后再更新,实现所谓的 “最终一致性”。
这个思路又是一个庞大的问题,同时也引出了第二个理论 Base 理论
我们说,CAP 不可能同时满足,而分区容错是对于分布式系统而言,是必须的。最后,我们说,如果系统能够同时实现 CAP 是再好不过的了,所以出现了 BASE 理论。
BASE:全称:Basically Available(基本可用),Soft state(软状态),和 Eventually consistent(最终一致性)三个短语的缩写,来自 ebay 的架构师提出。
Base 理论是对 CAP 中一致性和可用性权衡的结果,其来源于对大型互联网分布式实践的总结,是基于 CAP 定理逐步演化而来的。其核心思想是:
既是无法做到强一致性(Strong consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。
1、Basically Available(基本可用)
什么是基本可用呢?假设系统,出现了不可预知的故障,但还是能用,相比较正常的系统而言:
1、响应时间上的损失:正常情况下的搜索引擎 0.5 秒即返回给用户结果,而基本可用的搜索引擎可以在 1 秒作用返回结果。
2、功能上的损失:在一个电商网站上,正常情况下,用户可以顺利完成每一笔订单,但是到了大促期间,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面。
2、Soft state(软状态)
什么是软状态呢?相对于原子性而言,要求多个节点的数据副本都是一致的,这是一种 “硬状态”。
软状态指的是:允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本存在数据延时。
3、Eventually consistent(最终一致性)
这个比较好理解了哈。
上面说软状态,然后不可能一直是软状态,必须有个时间期限。在期限过后,应当保证所有副本保持数据一致性。从而达到数据的最终一致性。这个时间期限取决于网络延时,系统负载,数据复制方案设计等等因素。
稍微官方一点的说法就是:
系统能够保证在没有其他新的更新操作的情况下,数据最终一定能够达到一致的状态,因此所有客户端对系统的数据访问最终都能够获取到最新的值。
而在实际工程实践中,最终一致性分为 5 种:
1、因果一致性(Causal consistency)
指的是:如果节点 A 在更新完某个数据后通知了节点 B,那么节点 B 之后对该数据的访问和修改都是基于 A 更新后的值。于此同时,和节点 A 无因果关系的节点 C 的数据访问则没有这样的限制。
2、读己之所写(Read your writes)
这种就很简单了,节点 A 更新一个数据后,它自身总是能访问到自身更新过的最新值,而不会看到旧值。其实也算一种因果一致性。
3、会话一致性(Session consistency)
会话一致性将对系统数据的访问过程框定在了一个会话当中:系统能保证在同一个有效的会话中实现 “读己之所写” 的一致性,也就是说,执行更新操作之后,客户端能够在同一个会话中始终读取到该数据项的最新值。
4、单调读一致性(Monotonic read consistency)
单调读一致性是指如果一个节点从系统中读取出一个数据项的某个值后,那么系统对于该节点后续的任何数据访问都不应该返回更旧的值。
5、单调写一致性(Monotonic write consistency)
指一个系统要能够保证来自同一个节点的写操作被顺序的执行。
然而,在实际的实践中,这 5 种系统往往会结合使用,以构建一个具有最终一致性的分布式系统。实际上,不只是分布式系统使用最终一致性,关系型数据库在某个功能上,也是使用最终一致性的,比如备份,数据库的复制过程是需要时间的,这个复制过程中,业务读取到的值就是旧的。当然,最终还是达成了数据一致性。这也算是一个最终一致性的经典案例。
我们说,CAP 不可能同时满足,而分区容错是对于分布式系统而言,是必须的。最后,我们说,如果系统能够同时实现 CAP 是再好不过的了,所以出现了 BASE 理论,总的来说,BASE 理论面向的是大型高可用可扩展的分布式系统,和传统事务的 ACID 是相反的,它完全不同于 ACID 的强一致性模型,而是通过牺牲强一致性来获得可用性,并允许数据在一段时间是不一致的。
原文出处:
[1]:http://t.cn/ECwS0zz
[2]:http://t.cn/ECwSntj
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知我们,我们会立即删除并表示歉意。谢谢!
本文分享自微信公众号 - JAVA高级架构(gaojijiagou)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。