I often see some sql optimization suggestions on the Internet not to use Count(*) but to use Count(1), which can improve performance. The reason given is that Count( ) will bring a full table scan. However, a comparative experiment found that the efficiency is basically the same .
First of all, let’s understand: count() is an aggregation function. The parameters of the function can be not only field names, but also any other expressions. The function of this function is to count the records that meet the query conditions, and the parameters specified by the function are not NULL. how many. Assume that the parameter of the count() function is the field name, as follows:
select count(1) from icaAccountingBill
select COUNT( ) from icaAccountingBill
select count(BillNo) from icaAccountingBill ---- the slowest efficiency
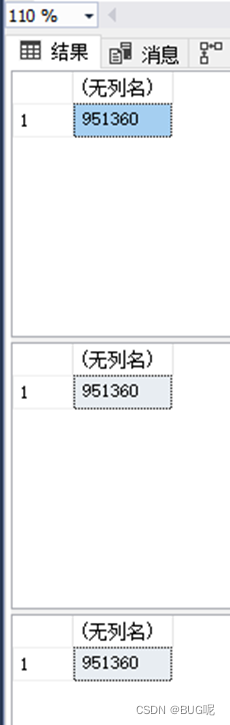
First read the difference:
count(name)
is to count the number of records whose name field is not NULL in the icaAccountingBill table. So SQL Server must read the value of each row of the col, and then confirm whether it is NULL, and then count.
count(1)
counts how many records in the icaAccountingBill table, the expression 1 is not NULL. 1 This expression is a simple number, it will never be NULL, so the above statement is actually counting how many records there are in the icaAccountingBill table.
count(*)
can actually understand that count( ) just returns the number of rows in the table, so SQL Server only needs to find the header of the data block belonging to the table when processing count( ), and then calculate the number of rows instead of reading The data in the data column inside.
COUNT() in SQL Server only needs to find the number of rows that are not NULL in the specific table, that is, all rows (if a row is all NULL, the row does not exist). Then the easiest way to implement it is to find a NOT NULL column. If the column has an index, use the index. Of course, for performance, SQL Server will choose the narrowest index to reduce IO.
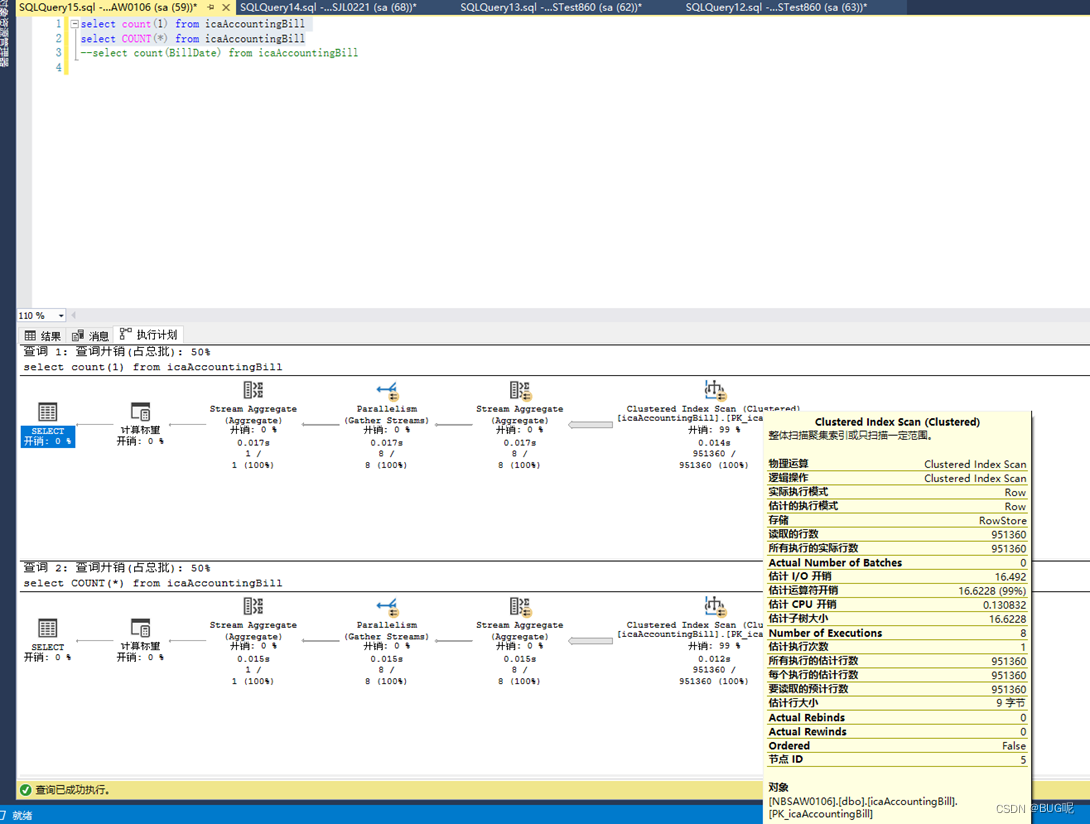
Without primary key and index:
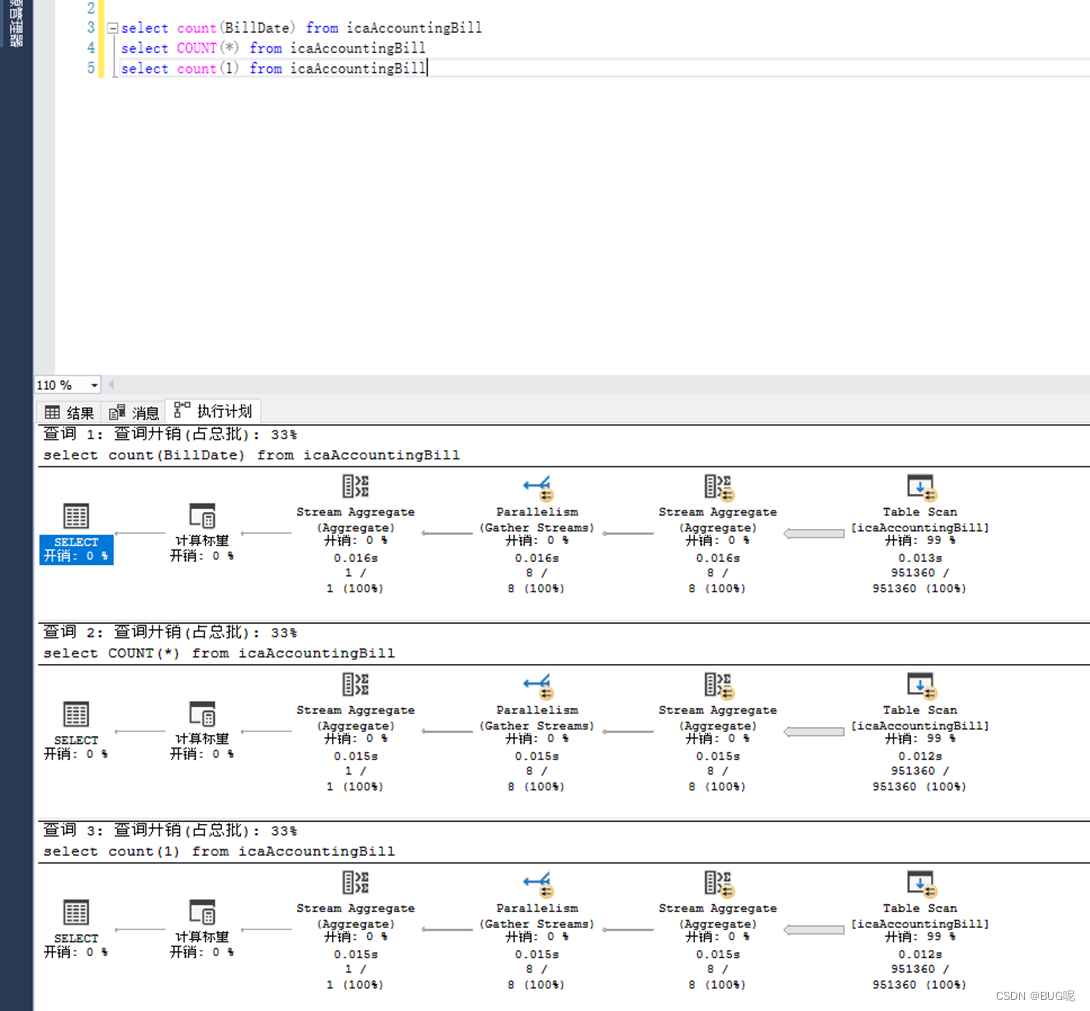
In case of no index: automatically find the primary key index
With indexes:
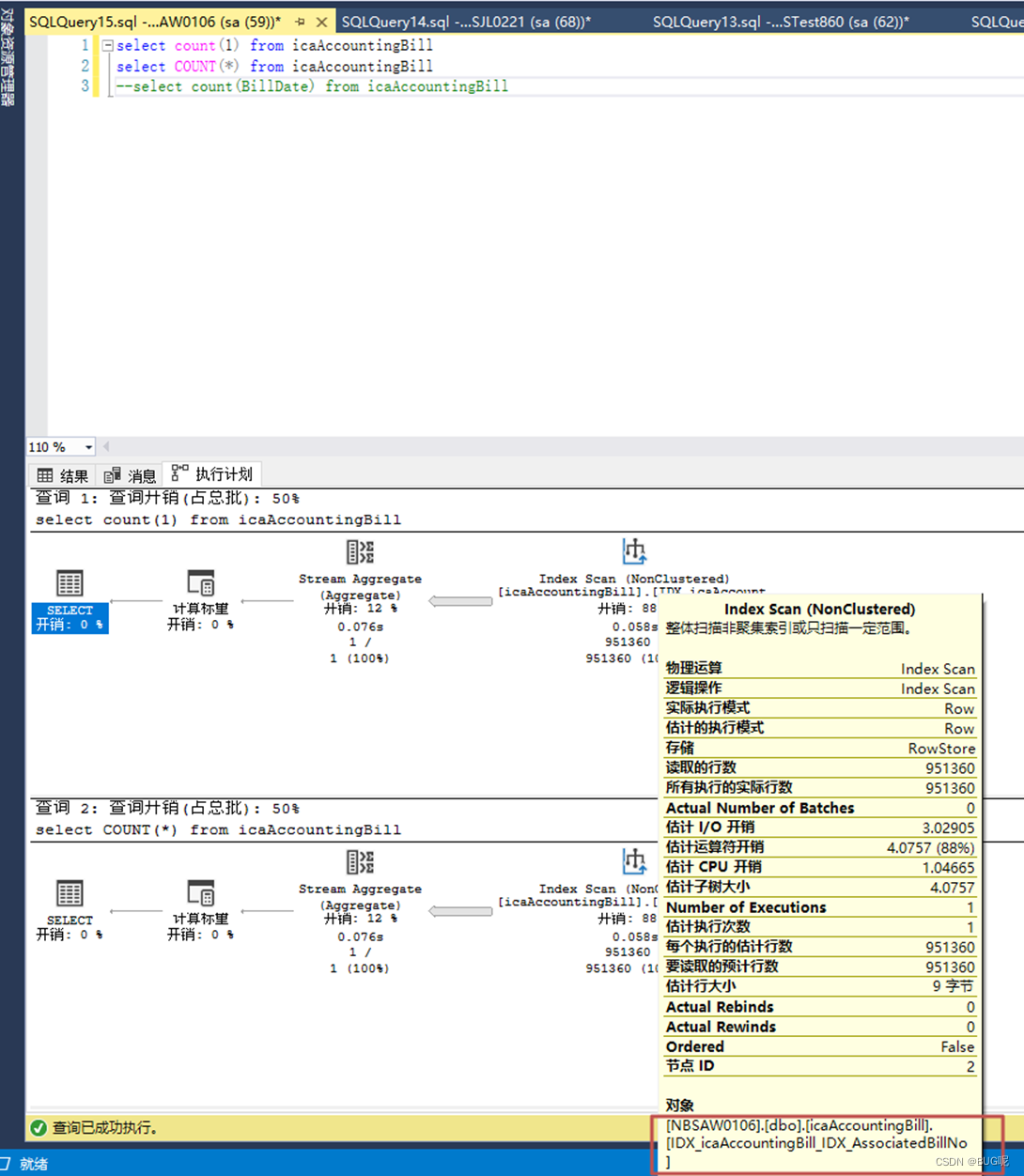

#dbcc show_statistics('NBSAW0106.dbo.icaAccountingBill',IDX_icaAccountingBill_IDX_FOrgId)----显示索引的语法
The conclusion is : if the table has only one primary key index without any secondary index, then both COUNT( ) and COUNT(1) count the number of rows through the primary key index. If the table has a secondary index, both COUNT(1) and COUNT( ) will count through the secondary index of the field that occupies the smallest space. Here, the operation of counting the number of rows, the optimization direction of the query optimizer is to select the IO times The least index, that is, the index built based on the field with the smallest space (the amount of data read by each IO is fixed, and the smaller the space occupied by the index, the fewer the number of IOs required). The primary key index is a clustered index (including KEY, other field values except KEY, transaction ID and rollback pointer), so the primary key index must be larger than the secondary index (including KEY and corresponding primary key ID), that is to say In the case of secondary indexes, generally COUNT() will not count the number of rows through the primary key index, and select the one that occupies the smallest space when there are multiple secondary indexes.
Therefore, if Count (*) is used a lot on a table, consider building a single-column index on the shortest column, which will greatly improve performance.