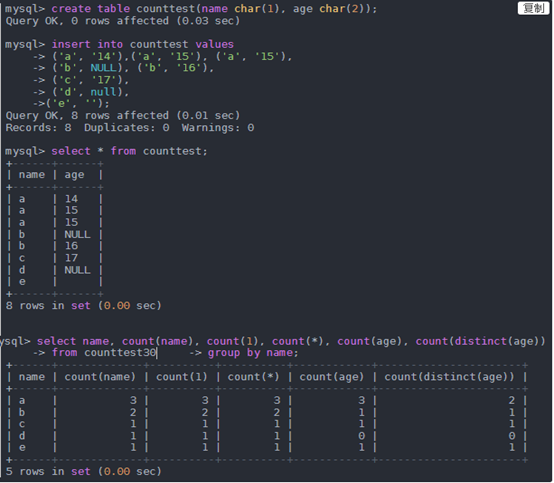
count difference (*), count (1) and count (column name) of
1 , the implementation of the results:
l count (*) includes all of the columns, equivalent to the number of rows in the statistics, it does not ignore the column value is NULL
l count (1) includes ignores all, with one line of code on behalf of, the statistical results, it does not ignore the column value is NULL
l count (column names) comprises only the row column names in the statistics when the column is empty ignored (empty here is not only an empty string or 0, but rather null) count, i.e., a field value of is NULL, not statistics.
2 , implementation of efficiency:
l primary key column names, count (column name) will be (1) faster than count
l is not the primary key column name, count (1) faster than count (column name)
If a plurality of columns of Table l and no primary key, then the count (1) is superior to the efficiency count (*)
l If a primary key, then select count (primary key) is optimal execution efficiency
l If the table has only one field, then select count (*) is optimal.
3 , Case Study: