When you're choosing a database or search engine for your project, it's critical to understand the nuances of each option. Today, we'll dive into the strengths of Elasticsearch and explore how it compares to traditional SQL and NoSQL databases.
1. Introduction to Elasticsearch
Elasticsearch is a distributed search and analysis engine based on the powerful Apache Lucene library. It is known for its speed, scalability, and ability to quickly index large amounts of data. Unlike many traditional databases, Elasticsearch is tailor-made for search-centric applications, providing many features that databases do not natively support. For more introduction to Elasticsearch, please refer to the article " Introduction to Elasticsearch ".
For Elasticsearch copyright issues, please refer to the " Introduction to Copyright" chapter in the article " Elastic: A Developer's Guide " .
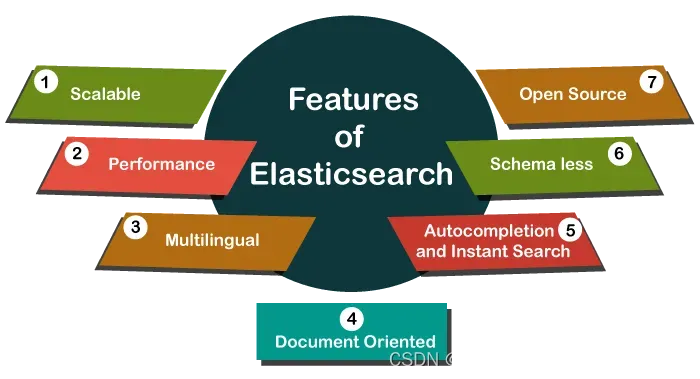
2. Advantages of Elasticsearch
a. Full text search function
- Inverted Index : At its core, Elasticsearch uses an inverted index, a data structure that lists each unique word and its corresponding position in the data. This structure is optimized for speed, enabling fast text searches across massive datasets. Read the article " Elasticsearch: inverted index, doc_values and source " in detail.
- Advanced text processing : Elasticsearch provides out-of-the-box features such as tokenization (breaking text into individual words or terms), stemming (returning words to their root forms), and handling synonyms, among others. These processes enhance search relevance and precision. Read the article " Elasticsearch: analyzer " for details.
- Relevance Scoring and Ranking : When you search in Elasticsearch, it not only finds matches, but uses various algorithms to rank them based on relevance, ensuring that the most relevant results are returned first. Related reading " Elasticsearch: Distributed Scoring ".
b. Data flexibility
- JSON native structure : Elasticsearch treats data as JSON documents. Not only is this format ubiquitous in modern web applications, but it also allows data to be structured hierarchically, allowing for more complex queries.
- Dynamic mapping : Unlike some databases that require a fixed schema, Elasticsearch can automatically detect and index the data types of fields in documents. This flexibility is beneficial for evolving datasets. Read " Elasticsearch: Dynamic mapping " for details.
c. Batch indexing
- Efficient data ingestion : Elasticsearch's bulk API allows multiple index, update, or delete operations to be performed in a single request. This simplified approach ensures high-speed data ingestion, especially when dealing with large amounts of information.
- Parallel processing : Elasticsearch is designed to handle synchronous indexing operations across distributed nodes. This concurrent processing ensures fast indexing of large amounts of data.
d. Distributed design
- Sharding and Replication : Data in Elasticsearch is essentially divided into "shards". These shards can be replicated across nodes, providing scalability (by adding more shards) and resiliency (via replicas). As your data grows, Elasticsearch grows with you. For more descriptions about sharding, please read the article " Some important concepts in Elasticsearch: cluster, node, index, document, shards and replica ".
- Horizontal Scalability : Need to handle more data? Just add more nodes to your Elasticsearch cluster. The system automatically distributes your data and query load, ensuring optimal performance.
- Fault Tolerance : In the event of a node failure, replica shards exist to ensure your data remains available and your search operations can continue without interruption.
e. Real-time indexing
- Near-instant data availability : Once data in Elasticsearch is ingested, it is almost immediately available for search operations. This real-time indexing feature ensures your applications always have access to the latest data thanks to its optimized refresh interval. Read " Elasticsearch: A guide to refresh and flush in Elasticsearch " for details.
- Optimized for high throughput : In addition to real-time indexing, Elasticsearch is designed to handle a continuous stream of data updates, making it particularly effective for time-sensitive applications such as log monitoring or real-time data analysis.
3. Where traditional databases may have an advantage
a. ACID transactions
SQL databases generally prioritize strong ACID guarantees, making them more suitable for applications that require strict data integrity and consistency.
b. Complicated relationships
SQL databases are designed around data normalization and relations. They excel at handling complex joins and modeling relational data.
c. Generic use cases
While Elasticsearch excels at search and analytics, SQL databases are more general and suitable for a wide variety of applications.
4. Scenarios where Elasticsearch is most suitable
- Logging and Monitoring : Due to its ability to process large volumes of data and make it searchable in near real time.
- Full-text search applications : such as e-commerce platforms, where a combination of searching, filtering, and ranking is essential.
- Analytics and visualization : Tools like Kibana can turn Elasticsearch into a powerful data visualization platform.
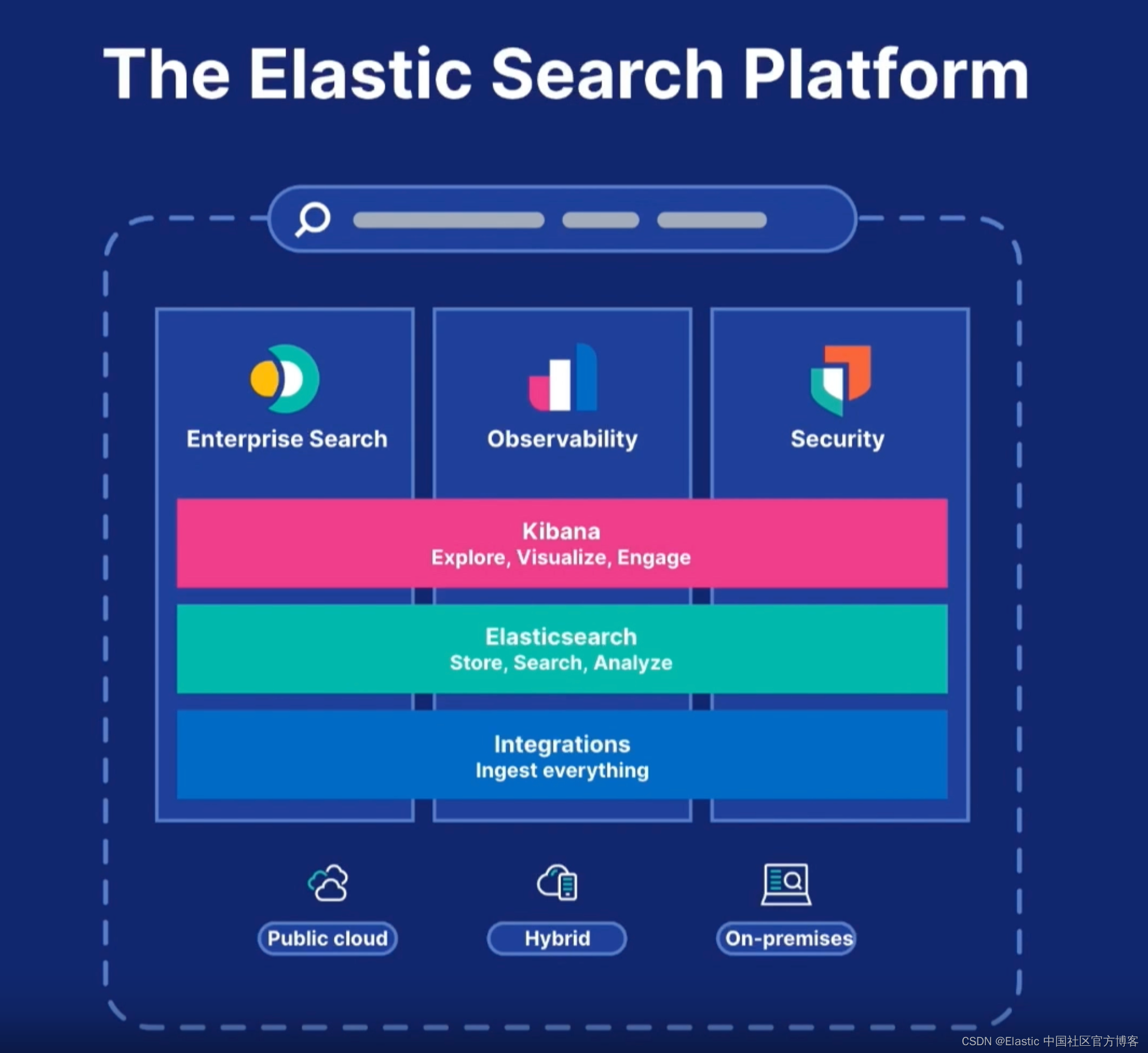
In the release of the Elastic Stack, around Elasticsearch, it provides three out-of-the-box solutions: Enterprise Search , Observability and Security .
5 Conclusion
In the vast world of databases and search engines, each tool has its own unique strengths. While Elasticsearch is undoubtedly powerful for search-centric and data-heavy applications, it is critical to assess the needs of your specific project. By understanding the capabilities and tradeoffs of each option, you can ensure you're leveraging the right tools for your unique challenges.