Parallelism setting & priority
Parallelism
Parallelism setting
In Flink, parallelism can be set in different ways, with different effective ranges and priorities.
set in code
In the code, we can simply call the setParallelism() method after the operator to set the parallelism of the current operator:
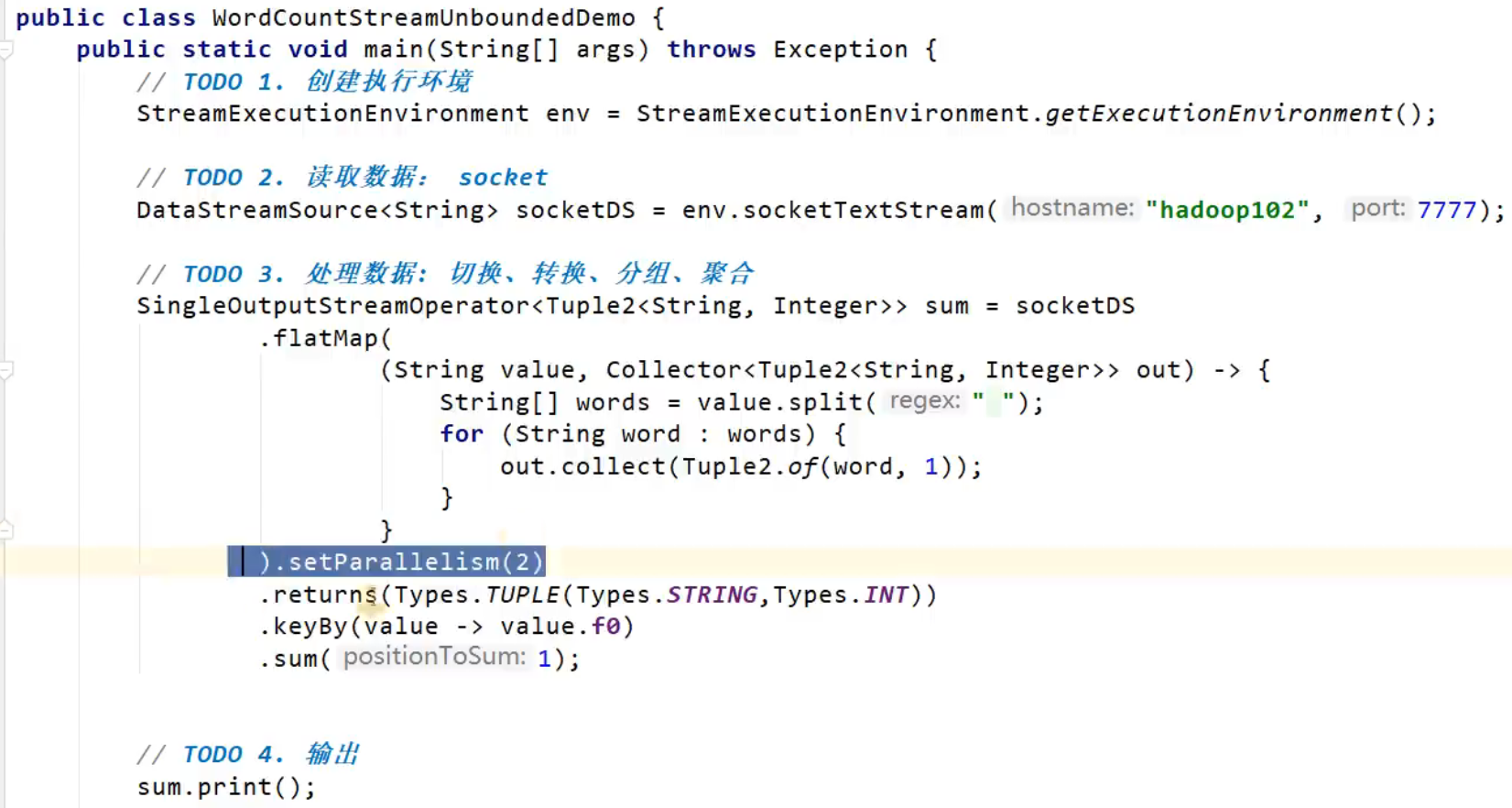
stream.map(word -> Tuple2.of(word, 1L)).setParallelism(2);
The parallelism set in this way is only valid for the current operator.
In addition, we can also directly call the setParallelism() method of the execution environment to set the parallelism globally:
env.setParallelism(2);
In this way, all operators in the code have a default parallelism of 2. We generally do not set the global parallelism in the program, because if the global parallelism is hard-coded in the program, dynamic expansion will not be possible.
It should be noted here that since keyByit is not an operator, the parallelism cannot be set for keyBy.
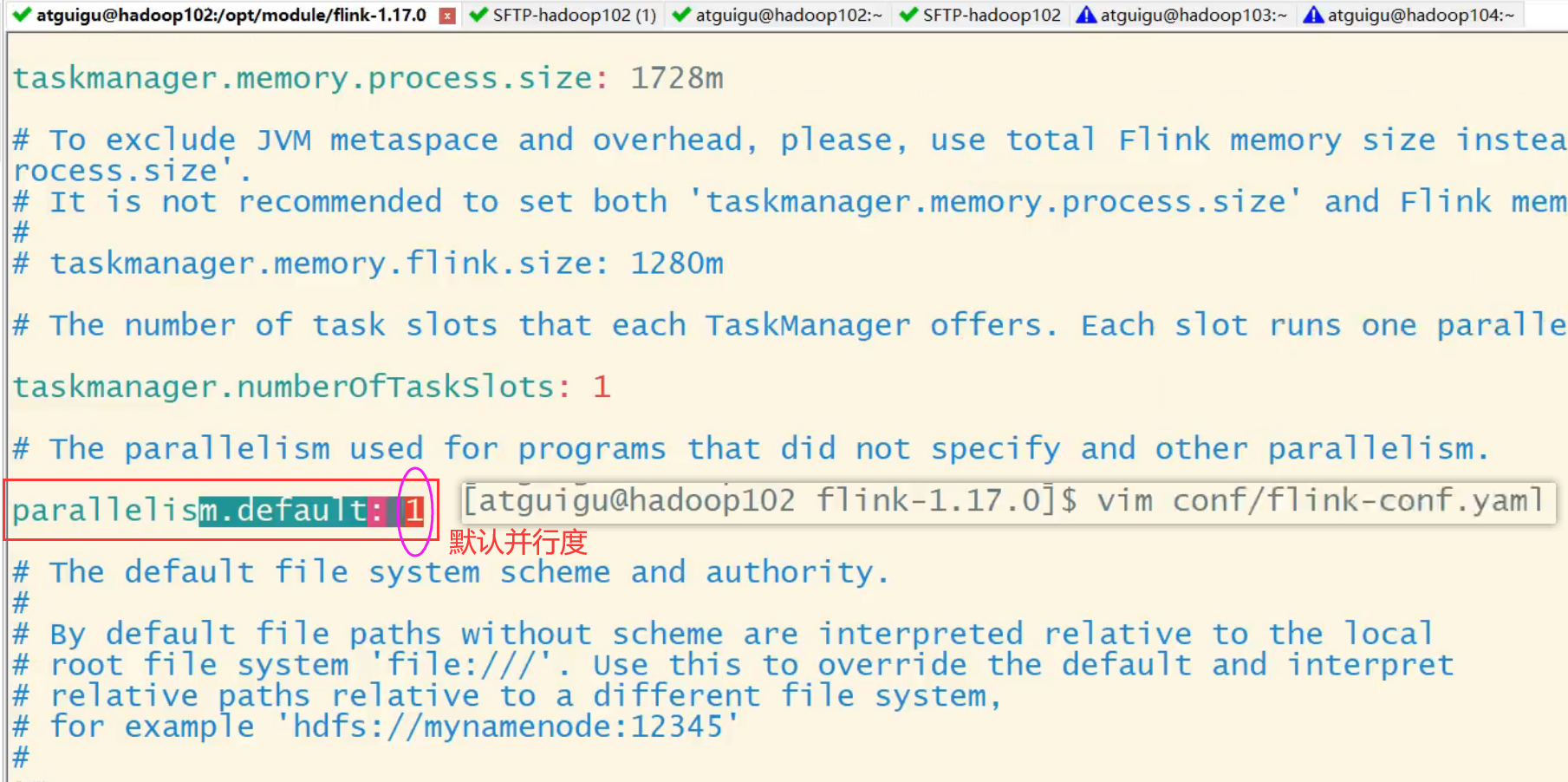
Set when submitting the app
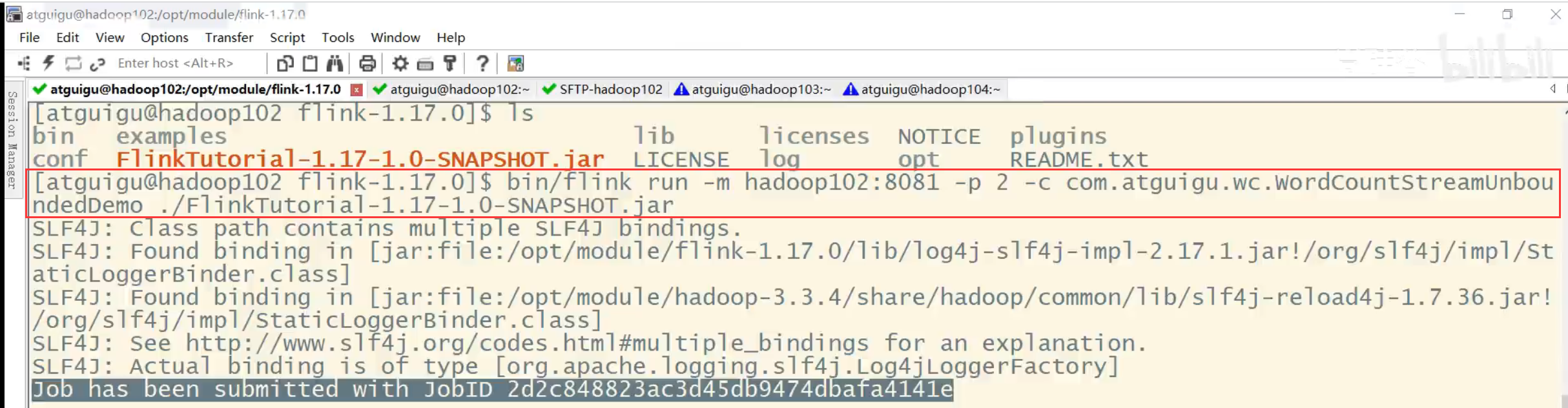
When using the flink run command to submit an application, you can add the -p parameter to specify the parallelism of the current application execution, which is similar to the global setting of the execution environment:
bin/flink run –p 2 –c com.atguigu.wc.SocketStreamWordCount ./FlinkTutorial-1.0-SNAPSHOT.jar
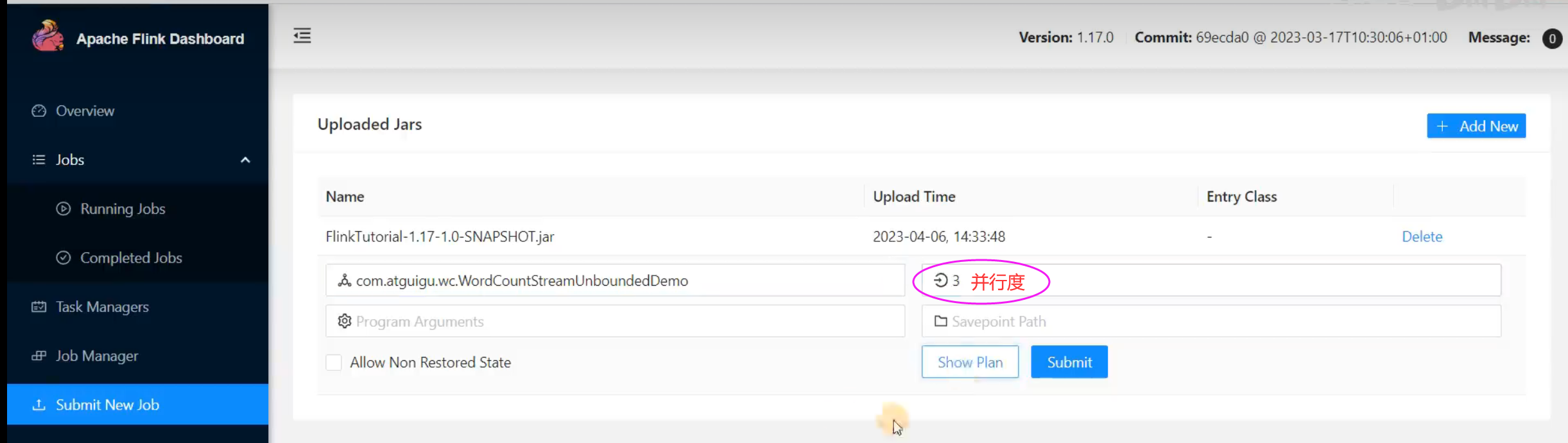
If we submit the job directly on the Web UI, we can also directly add the degree of parallelism in the corresponding input box.
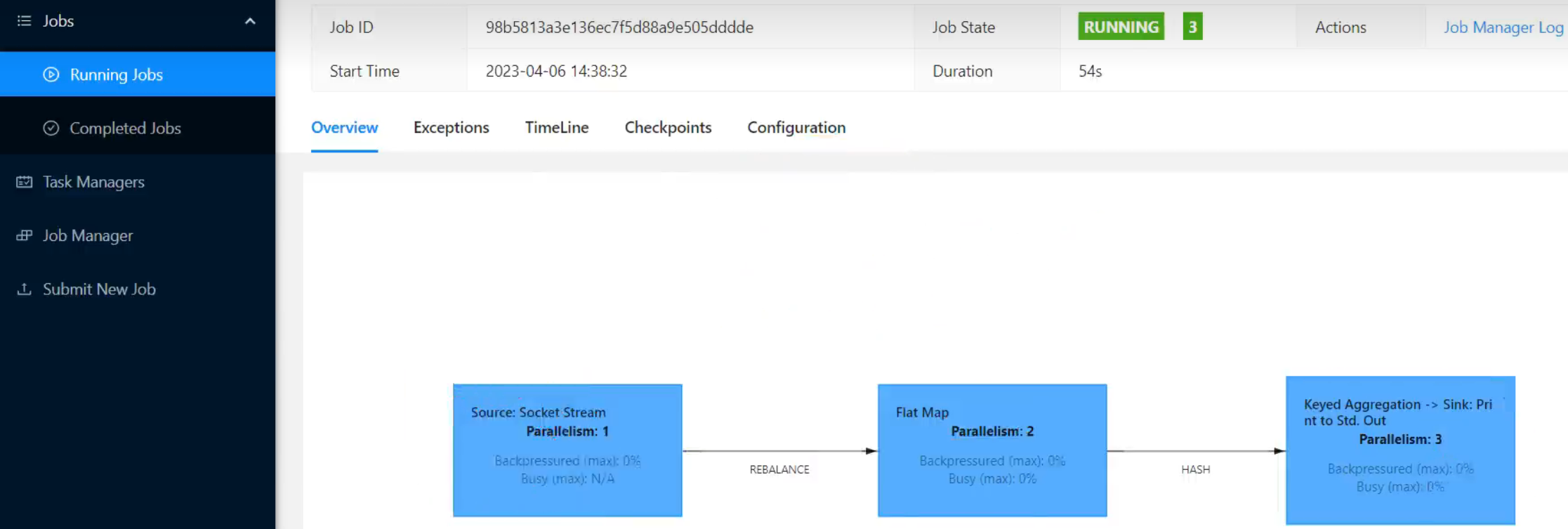
package com.atguigu.wc;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* TODO DataStream实现Wordcount:读socket(无界流)
*
* @author
* @version 1.0
*/
public class WordCountStreamUnboundedDemo {
public static void main(String[] args) throws Exception {
// TODO 1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// IDEA运行时,也可以看到webui,一般用于本地测试
// 需要引入一个依赖 flink-runtime-web
// 在idea运行,不指定并行度,默认就是 电脑的 线程数
// StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setParallelism(3);
// TODO 2.读取数据: socket
DataStreamSource<String> socketDS = env.socketTextStream("hadoop102", 7777);
// TODO 3.处理数据: 切换、转换、分组、聚合
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = socketDS
.flatMap(
(String value, Collector<Tuple2<String, Integer>> out) -> {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
)
.setParallelism(2)
.returns(Types.TUPLE(Types.STRING,Types.INT))
// .returns(new TypeHint<Tuple2<String, Integer>>() {})
.keyBy(value -> value.f0)
.sum(1);
// TODO 4.输出
sum.print();
// TODO 5.执行
env.execute();
}
}
/**
并行度的优先级:
代码:算子 > 代码:env > 提交时指定 > 配置文件
*/
parallelism priority
Code: Operator > Code: env > Specify when submitting > configuration file