| This article briefly introduces the development process of the cyclic neural network RNN, and analyzes the gradient descent algorithm, backpropagation and LSTM process. |
With the development of science and technology and the substantial improvement of hardware computing power, artificial intelligence has suddenly jumped into people's eyes from decades of behind-the-scenes work. Behind artificial intelligence comes from the support of big data, high-performance hardware and excellent algorithms. In 2016, deep learning has become a hot word in Google search. After AlphaGo won the world champion in the Go man-machine battle in the last one or two years, people feel that they can no longer resist the fast approaching of the wheels of AI. In 2017, AI has broken through the sky, and related products have also appeared in people's lives, such as intelligent robots, unmanned driving and voice search. Recently, the World Intelligence Conference was successfully held in Tianjin. At the conference, many industry experts and entrepreneurs expressed their views on the future. It can be learned that most technology companies and research institutions are very optimistic about the prospects of artificial intelligence. All of his wealth is on artificial intelligence, no matter whether he becomes famous or fails after all, as long as he doesn't get nothing. Why does deep learning suddenly have such a big effect and upsurge? This is because technology changes life, and many occupations may be slowly replaced by artificial intelligence in the future. All the people are talking about artificial intelligence and deep learning. Even Yann LeCun feels the popularity of artificial intelligence in China!
Closer to home, behind artificial intelligence is big data, excellent algorithms, and hardware support with powerful computing capabilities. For example, Nvidia has won the top 50 smartest companies in the world by virtue of its strong hardware research and development capabilities and support for deep learning frameworks. In addition, there are many excellent deep learning algorithms, and a new algorithm will appear from time to time, which is really dazzling. But most of them are based on the improvement of classic algorithms, such as convolutional neural network (CNN), deep belief network (DBN), recurrent neural network (RNN) and so on.
This article will introduce the classic network recurrent neural network (RNN), which is also the network of choice for time series data. When it comes to certain sequential machine learning tasks, RNNs can achieve high levels of accuracy that no other algorithm can match. This is due to the fact that traditional neural networks only have a kind of short-term memory, while RNN has the advantage of limited short-term memory. However, the first generation of RNNs has not attracted significant attention, because researchers have suffered from the severe gradient vanishing problem in the process of utilizing backpropagation and gradient descent algorithms, which has hindered the development of RNNs for decades. Finally, a major breakthrough occurred in the late 90s, leading to a new generation of more accurate RNNs. Building on this breakthrough for nearly two decades, until apps like Google Voice Search and Apple Siri started snatching up its key processes, developers perfected and optimized a new generation of RNNs. RNN networks are now found in every field of research and are helping to ignite a renaissance in artificial intelligence.
Past-Related Neural Networks (RNN)
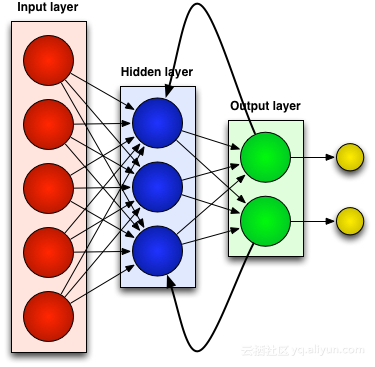
Most artificial neural networks, such as feedforward neural networks, have no memory of the input they have just received. For example, if you feed a feed-forward neural network the character "WISDOM", by the time it reaches the character "D", it has forgotten that it just read the character "S", which is a big problem. No matter how hard it is to train the network, it is always difficult to guess the next most likely character "O". This makes it a rather useless candidate for certain tasks, such as in speech recognition, where recognition benefits largely from the ability to predict the next character. RNN networks, on the other hand, do remember previous inputs, but at a very complex level.
We enter "WISDOM" again and apply it to a recurrent network. A unit, or artificial neuron, in the RNN network, when it receives a "D," also takes as its input the character "S" it received earlier. In other words, it takes the past event combined with the present event as input to predict what will happen next, which gives it the advantage of limited short-term memory. When training, given enough context, it can guess that the next character is most likely to be "O".
Adjust and readjust
Like all artificial neural networks, the cells of an RNN assign a matrix of weights to its multiple inputs, which represent the weight of each input in the network layer; a function is then applied to these weights to determine a single output, typically called Called the loss function (cost function), it limits the error between the actual output and the target output. However, RNNs assign weights not only to the current input, but also to inputs from past moments. Then, by making the loss function down to dynamically adjust the weights assigned to the current input and past inputs, this process involves two key concepts: gradient descent and backpropagation (BPTT).
gradient descent
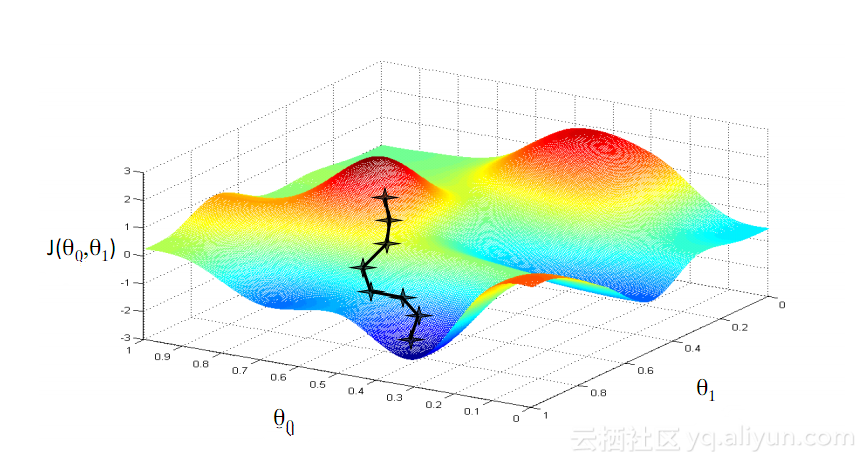
One of the most famous algorithms in machine learning is the gradient descent algorithm. Its main advantage is that it significantly avoids the "curse of dimensionality". What is the "curse of dimensionality", that is to say, in calculation problems involving vectors, as the number of dimensions increases, the amount of calculation will increase exponentially. This problem plagues many neural network systems, because too many variables need to be calculated to achieve the minimum loss function. However, the gradient descent algorithm breaks the curse of dimensionality by amplifying multidimensional errors or local minima of the cost function. This helps the system adjust the weight values assigned to individual units so that the network becomes more precise.
Backpropagation through time
RNNs train their units by fine-tuning their weights through inverse inference. To put it simply, it is based on the error between the total output calculated by the unit and the target output, from the final output of the network to reverse layer-by-layer regression, and use the partial derivative of the loss function to adjust the weight of each unit. This is the famous BP algorithm. About the BP algorithm, you can read the related blogs of this blogger. RNN networks use a similar version called backpropagation through time (BPTT). This version extends the tuning process to include weights responsible for each unit's memory corresponding to the input value at the previous moment (T-1).
Yikes: The vanishing gradient problem
Despite enjoying some initial success with the help of gradient descent algorithms and BPTT, many artificial neural networks (including the first generation of RNNs) eventually suffered a serious setback - the problem of vanishing gradients. What is the problem of gradient disappearance? The basic idea is actually very simple. First, let's look at the concept of a gradient, which is regarded as a slope. In the context of training deep neural networks, larger gradients represent steeper slopes, and the faster the system can slide to the finish line and complete training. But that's where the researchers run into trouble -- when the slope is too flat, fast training doesn't work. This is especially critical for the first layer in the deep network, because if the gradient value of the first layer is zero, it means that there is no adjustment direction, and the relevant weight values cannot be adjusted to minimize the loss function. Gradient loss". As the gradient gets smaller and smaller, the training time will get longer and longer, which is similar to moving along a straight line in physics. On a smooth surface, the ball will keep moving.
Big Breakthrough: Long Short-Term Memory (LSTM)
In the late 1990s, a major breakthrough solved the above-mentioned vanishing gradient problem, which brought a second wave of research to the development of RNN networks. The central idea of this big breakthrough is the introduction of unit Long Short-Term Memory (LSTM).
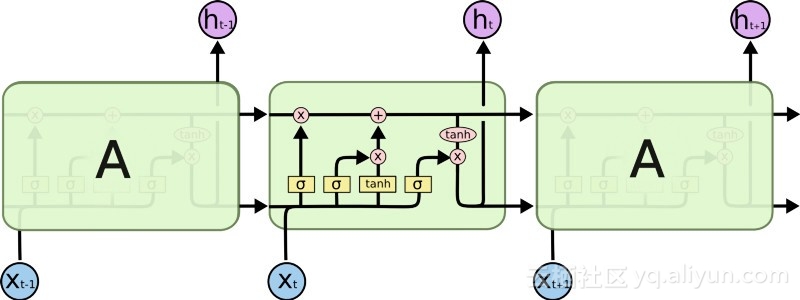
The introduction of LSTM has created a different world in the field of AI. This is due to the fact that these new units, or artificial neurons (like the standard short-term memory units of RNNs), memorize their inputs from the start. However, unlike standard RNN cells, LSTMs can be mounted on their memories, which have read/write properties similar to memory registers in regular computers. Also LSTMs are analog, not digital, making their features distinguishable. In other words, their curves are continuous and the steepness of their slopes can be found. As such, LSTMs are particularly well suited for the partial calculus involved in backpropagation and gradient descent.
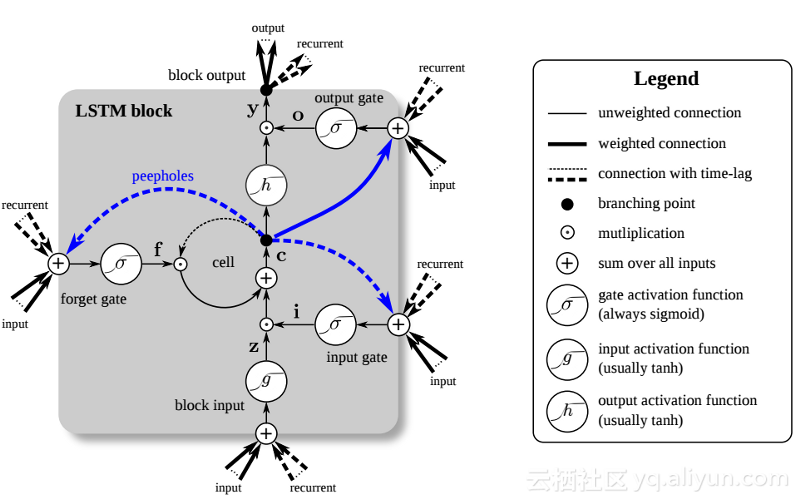
All in all, LSTM can not only adjust its weights, but also retain, delete, transform and control the inflow and outflow of its stored data according to the gradient of training. Most importantly, LSTM can hold important error information for a long time, so that the gradient is relatively steep, so that the training time of the network is relatively short. This solves the problem of vanishing gradients and greatly improves the accuracy of today's LSTM-based RNN networks. Google, Apple, and many other advanced companies are now using RNNs to power applications at the heart of their business, thanks to dramatic improvements in RNN architectures.
Summarize
Recurrent neural networks (RNNs) can remember their previous inputs, giving them a huge advantage over other artificial neural networks when it comes to continuous, context-sensitive tasks like speech recognition.
About the development history of the RNN network: the first generation of RNNs achieved the ability to correct errors through backpropagation and gradient descent algorithms. However, the gradient disappearance problem prevented the development of RNN; until 1997, after the introduction of an LSTM-based architecture, a major breakthrough was made.
The new method effectively turns each unit in the RNN network into an analog computer, greatly improving network accuracy.
Author information
Jason Roell: Software engineer with a passion for deep learning and its transformative applications.
Linkedin: http://www.linkedin.com/in/jason-roell-47830817/
This article was recommended by Beiyou @爱可可-爱生活 teacher, and translated by Alibaba Cloud Yunqi Community.