Original link:
www.zhihu.com/question/607397171/answer/3148846973
Recently, I have been doing some fine-tuning work on large models. At the beginning, I had a headache how to adjust the hyperparameters. After all, I can’t run experiments like a small model. I have accumulated experience after seeing the results. First, the amount of calculation is too large. It is difficult to obtain relevant test sets in some vertical fields, and most engineers who are fine-tuning are tuning vertical models :). Secondly, if GPT4 evaluation involves data privacy issues, and an article listed below shows that GPT4 is more inclined to give higher scores to answers with longer sentences and more diverse answers, sometimes it is not accurate. In the end, I can only read more papers related to fine-tuning/training for reference. The following will list some recently read articles, give important conclusions and some of my personal opinions, if you are interested, please read them intensively, hoping to help some fine-tuners, this article is updated irregularly. . .
1.Towards Better Instruction Following Language Models for Chinese.
The research report corresponding to the BELLE project is fine-tuned based on LLAMA. A tokenizer was retrained with the BPE algorithm on 12 million rows of Chinese data. Expand the vocabulary to 79458, and then perform a second pre-training on 3.4B Chinese words. It is found that the expanded vocabulary, higher quality of fine-tuning data (GPT4 is better than the quality of instruction data generated by GPT3.5), and more fine-tuning data is conducive to fine-tuning a better model. LLAMA itself has multilingual capabilities, and it can fine-tune good results by adding a small amount of new language data.
2. Exploring the Impact of Instruction Data Scaling on Large Language Models An Empirical Study on Real-World Use Cases
The article of the BELLE project team mainly studies the impact of different amounts of instruction data on model performance. It is found that increasing the amount of instruction data can continuously improve the model performance. At the same time, it is also found that as the amount of fine-tuning data increases (does this conflict with "LIMA: Less Is More for Alignment", LIMA's point of view is that fine-tuning with very little high-quality data can get better results, increasing fine-tuning The amount of data will not increase the effect of the model. Maybe it is because of the evaluation method? BELLE is a multiple-choice question, LIMA is evaluated by humans and GPT4, welcome to discuss in the comment area), different task types show different characteristics: a) for translation , rewriting, generation and brainstorming tasks, 2 million or less data volume can make the model perform well; b) for extraction, classification, closed QA and summary tasks, the performance of the model can continue as the data volume increases improved, which shows that we can still improve the performance of the model by simply increasing the amount of training data. But the potential for improvement may be limited. c) The performance in mathematics, code and internal structure of COT is still poor, and further exploration is needed in data quality, model size and training strategy. The basic summary is: it is difficult to improve the effect through fine-tuning for tasks that the basic model does poorly.
3. A Comparative Study between Full-Parameter and LoRA-based Fine-Tuning on Chinese Instruction Data for Instruction Following Large Language Model
The article of the BELLE project team compared the gap between LoRA and full parameter fine-tuning. Fine-tuning the basic model (such as a model without dialogue ability like llama) LoRA is still worse than full fine-tuning, and the fine-tuning dialogue model is not far behind. Sometimes full fine-tuning of personal tasks is not as good as LoRA, and the phenomenon of disaster forgetting will be more serious when full fine-tuning is fine-tuned. The fine-tuning effect depends on the amount of data and hyperparameters. And lora rank=8 will not be a bit small.
4. Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca
Technical report of the Chinese-LLaMA-Alpaca project. Based on the original lamma, this project has expanded the vocabulary by 2w Chinese characters/words. There are hundreds of Chinese characters in the original lamma vocabulary. If you encounter a Chinese character that you have never encountered before, it will degenerate to 3-4 bytes, and then perform id encoding, so that when you input a Chinese sentence, the generated token id list will be compared. It is not conducive to training and reasoning performance, and it will also affect the learning of Chinese semantic information by the model. Use the LoRA efficient fine-tuning method for secondary pre-training (chinese llama, first version 20G corpus, plus version 120G corpus) and supervised fine-tuning (chinese alpaca, based on Chinese llama, the amount of fine-tuning data is 200w-300w, plus Version 400w, maximum length 512), LoRA acts on all fully connected networks (including the QKVO network and the two neural networks of the FFN layer). When fine-tuning the instructions, a template that is not used in the alpaca project is used. Regardless of whether there is input or not, only one template is used, and insruct and input are merged (the change of the template should have no effect on the performance of the trained model:).
Compared with the original alpaca project, insruct and input are merged
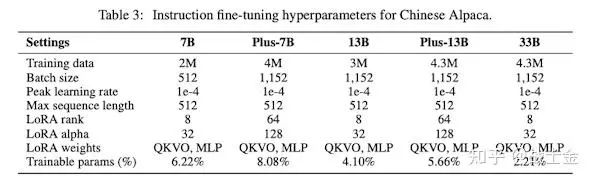
The plus version has a larger lora rank
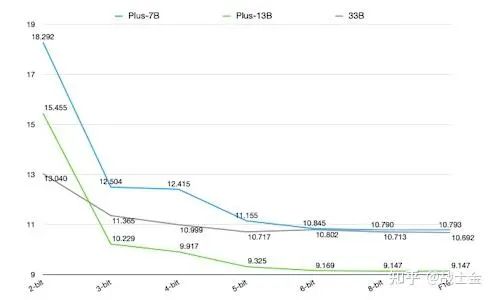
8bit quantization doesn't affect much precision
5. BloombergGPT: A Large Language Model for Finance
The financial vertical model trained by Bloomberg , 50B, the kind trained from scratch. The article is written in great detail, such as various bugs encountered during the training process, how many versions have been trained, what problems have been encountered in each version, how to improve, and the drop curve of the loss function of each version. . . The full text is 76 pages, a very pragmatic article. In order to ensure that the model takes into account both financial professional ability and general ability, 51% financial data and 49% general data are used for training. Using Unigram to train the tokenizer, the vocabulary size is determined to be 125,000 through calculation. Use ALiBi position encoding, formulate the model size and training data volume according to the chinchilla expansion law (given a fixed computing power, calculate the most suitable model size and training data size), and calculate the best hidden unit dimensions for different layers according to the formula .
6. How Far Can Camels Go? Exploring the State ofInstruction Tuning on Open Resources
It is found that there is no supervised fine-tuning data set that can keep the fine-tuned model in good condition in all aspects of performance. If you want to improve any task, you need to add relevant fine-tuning data to the fine-tuning data set. Experiments have found that putting some fine-tuning data sets that can be collected on the market together to train the model can achieve the best results (to put it bluntly, the fine-tuning data needs to be diverse, and it can also be understood as the task type trying to cover all downstream tasks). It was found that evaluating the effect of the model with GPT4 is also inaccurate, and GPT4 is more inclined to give high scores to answers with longer sentences and more diversity.
7. XuanYuan 2.0: A Large Chinese Financial Chat Model with Hundreds of Billions Parameters
Technical report of Du Xiaoman Xuanyuan Financial Large Model . It is generally believed that in the pre-training stage of injecting knowledge, supervised fine-tuning is only used to standardize the "speaking style" (supervised fine-tuning data can also inject knowledge, but the data is not easy to get). For building a vertical model in a certain field based on a general model, you can inject knowledge into pre-training twice, and then do supervised fine-tuning. But this will bring about two "catastrophic forgetting". This article attempts to combine raw text data and supervised fine-tuning data (both including general and financial domains) to continue training BLOOM-176B. The author has tried the method of mixing fine-tuning data and original text data for training, and the effect of injecting knowledge and following instructions is not bad. The phenomenon of disaster forgetting in the LoRA method is not serious.
8. Lawyer LLaMA Technical Report
Lawyer-llama's technical report , the Chinese legal large model, based on the original English version of LLaMA, has been pre-trained and fine-tuned. I've tried their models before, and they seem to work just fine. Continued pre-training consists of two stages. In the first stage, multilingual corpus is used to train LLaMA so that it has better Chinese ability (obviously, a better Chinese model made by others can be used, such as the Chinese-LLaMA-Alpaca mentioned in Document 4. , the original LLaMA would be worse without expanding the Chinese vocabulary. But this report also specifically stated on page 4 that they found that the expanded vocabulary was useless. The expanded vocabulary has advantages at least in terms of generation efficiency). In the second stage, a large number of original texts such as legal provisions, judicial interpretations, and judicial documents of the people's courts are used for training to enhance basic legal knowledge. There are 2 parts to fine-tuning the data: 1) Get the law test question data and let ChatGPT explain the answer. 2) Collect legal consultation data and let Chatgpt generate single or multiple rounds of dialogue data. In addition, in order to solve the problem of model illusion, the project also designed a legal article retrieval module, through the vectorized recall technology (you can read my article if you don’t know it), recall relevant legal articles according to user questions, and let the model synthesize Answer user questions and legal provisions. To enhance the model's ability to use legal texts, legal texts are also contextualized when constructing the fine-tuning dataset. The author found that if the legal provisions are directly given to the model, the model will be used directly without distinguishing whether the provided legal provisions are really related to the user's problem. If the recalled legal provisions are inaccurate, it will seriously affect the answering effect of the model. Therefore, in the process of adding legal provisions to the fine-tuning data, some irrelevant provisions are deliberately added, so that the model can learn the ability to ignore irrelevant provisions during the fine-tuning process (as expected, as much artificial intelligence as there is :) )
9.ChatLaw: Open-Source Legal Large Language Model with Integrated External Knowledge Bases
ChatLaw's technical report . A very popular product a while ago, people really use this product as a product, and they have their own website. But I tried the 13B model on his github, and I didn't feel how prominent the legal ability was, and the general ability lost too much. . . But his product idea is still good. As a product, model illusion must be solved. In order to achieve a better vector recall effect in the legal field, a sentence2vec model was specially trained with legal data. In addition, user questions are usually very colloquial, and direct use of user questions for vectorized retrieval may affect the accuracy of recall-related legal provisions (why it affects can be understood by looking at the principle of vectorized recall, you can see my This article), they also specially fine-tuned an LLM, which is specially used to extract legal-related keywords in user questions, and use keywords to perform vectorized retrieval of legal provisions to increase recall accuracy.

10.Scaling Instruction-Finetuned Language Models
The author found that as long as the model is fine-tuned, the effect of the model can be improved (even when the number of fine-tuning tasks is only 9), that is to say, even a small amount of fine-tuning data can bring more benefits than disaster forgetting (the author actually There is a bit of confusion, such as chatglm2, the effect of the model after alignment is worse than that before alignment...but chatglm2 has undergone reinforcement learning, is it that the negative impact of reinforcement learning is too great? Welcome to discuss in the comment area). At the same time, it was found that more types of fine-tuning data tasks (1800 tasks were collected), larger models, and adding COT data in the fine-tuning data can further increase the fine-tuning effect.
11.LIMA: Less Is More for Alignment
A well-known article, the core idea is that the knowledge of the model is obtained during pre-training, and the knowledge is fine-tuned in order to learn the style or format of interacting with users. Fine-tuning the 65BLLaMA model with 1000 pieces of carefully selected data can get better results. 800 pieces of data were manually selected from Stack Exchange, wikiHow, and Reddit, and 200 pieces of data were manually marked. Experiments show that the diversity of fine-tuning data is beneficial to improve the performance of the model, but increasing the number of fine-tuning data has no effect. For most people, I personally think that the ideas in this article are not very meaningful. First of all, the 65B model he used has a good foundation, but most people are still fine-tuning 6/7B. Moreover, quite a few people are fine-tuning the vertical model. In order to inject knowledge, the amount of fine-tuning data must be added.
12.ChatHome: Development and Evaluation of a Domain-Specific Language Model for Home Renovation
It is still an article by the BELLE team . After all, the Shell team has started to make large-scale models related to their own business. ChatHome is a model in the field of furniture and decoration. In the secondary training/fine-tuning of the vertical model, in order to alleviate the negative impact of the disaster forgetting problem, a common method is to add some general data to the training corpus. The author explores the ratio of vertical data and general data. For the secondary training base model (without dialogue ability), vertical data: general data = 1:5 is better. Using some dialogue data to further fine-tune the model, it turned out that even the base model based on vertical data: general data = 1:5 secondary pre-training is not as good as fine-tuning directly on the open source chat model. . . So the second pre-training is a bit useless. The base model is baichuan13B, maybe the training corpus contains some home decoration data. In addition, the author found that the best effect can be achieved by directly mixing the original text and dialogue data of the vertical category, and directly training the base model once (even without general data). This is also consistent with the author's previous experimental experience. The paradigm of secondary pre-training + fine-tuning has caused two disasters to be forgotten, and the negative impact is relatively large.
Recommended reading:
My 2022 Internet School Recruitment Sharing
Talking about the difference between algorithm post and development post
Internet school recruitment research and development salary summary
The 2022 Internet job hunting status, gold 9 silver 10 will soon become copper 9 iron 10! !
Public number: AI snail car
Stay humble, stay disciplined, keep improving

Send [Snail] to get a copy of "Hands-on AI Project" (written by AI Snail Car)
Send [1222] to get a good leetcode brushing notes
Send [AI Four Classics] Get four classic AI e-books