Imagine that, as a developer, your current company has an online Hadoop cluster. Department A often makes some regular BI reports, and Department B often uses software to make some temporary needs. Then they will definitely encounter the scenario of submitting tasks at the same time. At this time, how should resources be allocated to meet these two tasks? Do you execute the task of A first, and then execute the task of B, or run both at the same time?
If you have the above confusion, you can learn more about Yarn's resource scheduler .
Yarn's three schedulers
Starting from Hadoop2, the official separation of resource management is mainly to consider it as a public resource management platform in the later stage, and any computing engine that meets the rules can be executed on it. As a resource sharing resource of Hadoop cluster , Yarn can not only run MapReduce, but also run Spark and Flink.
In the Yarn framework, the scheduler is a very important part. With appropriate scheduling rules , multiple applications can be guaranteed to work in an orderly manner at the same time.
The most primitive scheduling rule is FIFO , which determines which task to execute first according to the time when the user submits the task, but this is likely to monopolize resources for one large task, and other resources need to wait continuously, or a bunch of small tasks may occupy resources. Quests have been unable to get proper resources, causing starvation. So although FIFO is very simple, it cannot meet our needs.
As shown in the figure below, there are three schedulers to choose from in Yarn: FIFO Scheduler, Capacity Scheduler, and Fair Scheduler.
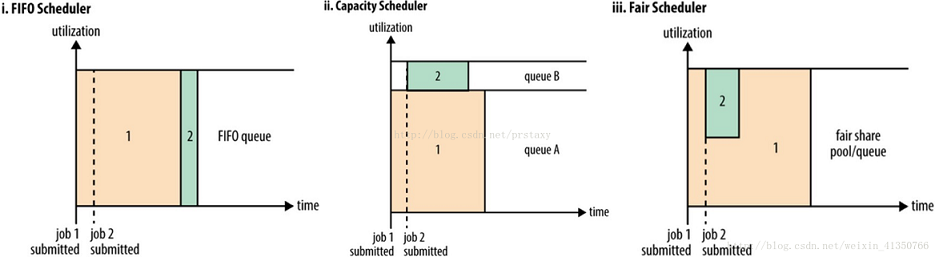
FIFO Scheduler
Arrange the applications in a first-in-first-out queue in the order of submission. When allocating resources, first allocate resources to the application at the head of the queue, and then allocate resources to the next application after the requirements of the application at the top are met. And so on.
FIFO Scheduler is the simplest and easiest to understand scheduler. It does not require any configuration, but it is not suitable for shared clusters. Large applications may consume all cluster resources, causing other applications to be blocked.
Capacity Scheduler
Allows multi-tenants to safely share cluster resources . The core concept provided is Queues (queue), which supports multiple queues. Each queue can be configured with a certain amount of resources to ensure that resources can be used in one queue before other queues are allowed to use idle resources. The sub-queues of the organization are shared, and each queue adopts the FIFO scheduling strategy . In order to provide more control and predictability on shared resources, applications can allocate resources in a timely manner under capacity constraints.
Fair Scheduler
In the Fair scheduler, we don't need to occupy certain system resources in advance, and the Fair scheduler will dynamically adjust the system resources for all running jobs. When the first big job is submitted, only this one job is running, and it gets all cluster resources at this time; when the second small job is submitted, the Fair scheduler will allocate half of the resources to this small task, so that the two Tasks share cluster resources fairly.
It should be noted that there will be a certain delay from the submission of the second task to the acquisition of resources, because it needs to wait for the first task to release the occupied Container. After the execution of the small task is completed, the resources it occupies will be released, and the large task will obtain all the system resources. The final effect is that the Fair scheduler not only achieves high resource utilization, but also ensures that small tasks are completed in time.
How EasyMR manages the Yarn resource queue
The most primitive scheduling rule is FIFO, which determines which task is executed first according to the time when the user submits the task, but this may cause a large task to monopolize resources, and other resources need to wait continuously, and may also cause a bunch of small tasks to occupy resources , large tasks have been unable to get the proper resources, causing starvation.
So although FIFO is very simple, it cannot meet our needs. The most commonly used is the capacity scheduling strategy, but when configuring the capacity queue, the operation and maintenance personnel need to consider the resource utilization rate of the queue and the status of the queue. After the modification is completed, it is impossible to verify whether the configuration is correct.
Based on the principle of simplicity and efficiency, EasyMR has opened up the resource queue management function .
Taking capacity scheduling as an example, we will briefly demonstrate the use of queues in EasyMR . Assume that the company has a big data department, and there is a data synchronization group under this department. The queue tree diagram is as follows:
root
├── bigdata
|---dataSync
To create such a hierarchical queue, you first need to create a bigdata queue under the parent level, and then divide a subqueue dataSync under bigdata, which will be described in detail below.
create queue
First create the parent queue bigdata , set the minimum capacity to 20%, and the maximum capacity to 50%.
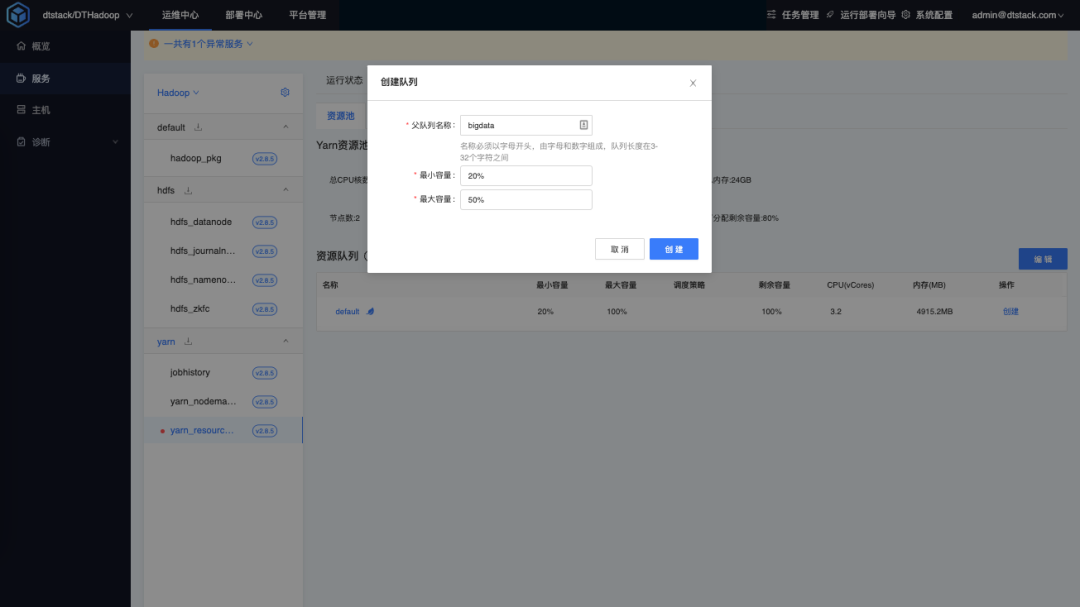
Add the bigdata queue name in the parent queue.
<property>
<!-- root队列中有哪些子队列-->
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,bigdata</value>
<description></description>
</property>
Sets the capacity scheduling configuration for bigdata.
<property>
<!-- bigdata队列占用的容量百分比-->
<name>yarn.scheduler.capacity.root.bigdata.capacity</name>
<value>20</value>
<description></description>
</property>
<property>
<!-- root队列中bigdata队列占用的容量百分比的最大值-->
<name>yarn.scheduler.capacity.root.bigdata.maximum-capacity</name>
<value>50</value>
<description></description>
</property>
<property>
<!-- queue容量的倍数,用来设置一个user可以获取更多的资源。默认值为1-->
<name>yarn.scheduler.capacity.root.bigdata.user-limit-factor</name>
<value>1</value>
<description></description>
</property>
<property>
<!--设置bigdata队列的状态-->
<name>yarn.scheduler.capacity.root.bigdata.state</name>
<value>RUNNING</value>
<description></description>
</property>
create subqueue
Under the bigdata parent queue, choose to create a child queue, set the minimum capacity to 10%, and the maximum capacity to 30%.
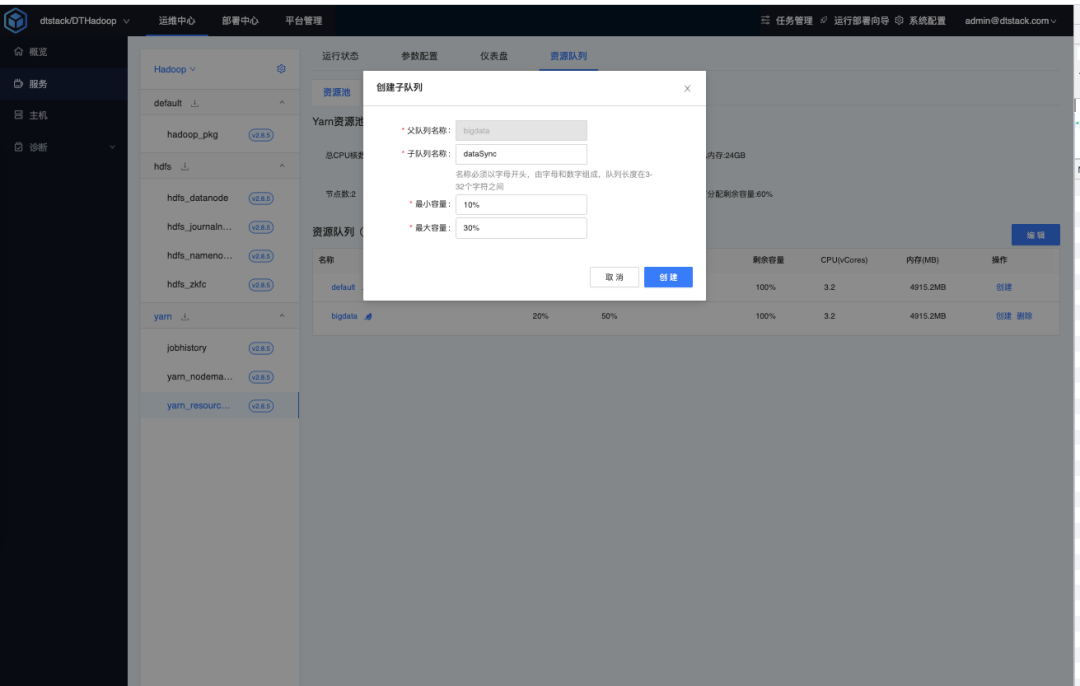
Add dataSync queue name in bigdata queue .
<property>
<!-- bigdata队列中有哪些子队列-->
<name>yarn.scheduler.capacity.root.bigdata.queues</name>
<value>dataSync</value>
<description></description>
</property>
Sets the capacity scheduling configuration for the dataSync queue.
<property>
<!-- bigdata队列dataSync子队列的容量百分比-->
<name>yarn.scheduler.capacity.root.bigdata.dataSync.capacity</name>
<value>10</value>
<description></description>
</property>
<property>
<!-- bigdata队列中bigdata队列占用的容量百分比的最大值-->
<name>yarn.scheduler.capacity.root.bigdata.dataSync.maximum-capacity</name>
<value>30</value>
<description></description>
</property>
<property>
<!-- queue容量的倍数,用来设置一个user可以获取更多的资源。默认值为1-->
<name>yarn.scheduler.capacity.root.bigdata.dataSync.user-limit-factor</name>
<value>1</value>
<description></description>
</property>
<property>
<!--设置子队列dataSync队列的状态-->
<name>yarn.scheduler.capacity.root.bigdata.dataSync.state</name>
<value>RUNNING</value>
<description></description>
</property>
view queue
After the creation is complete, you can view the queue details in the EasyMR resource queue .
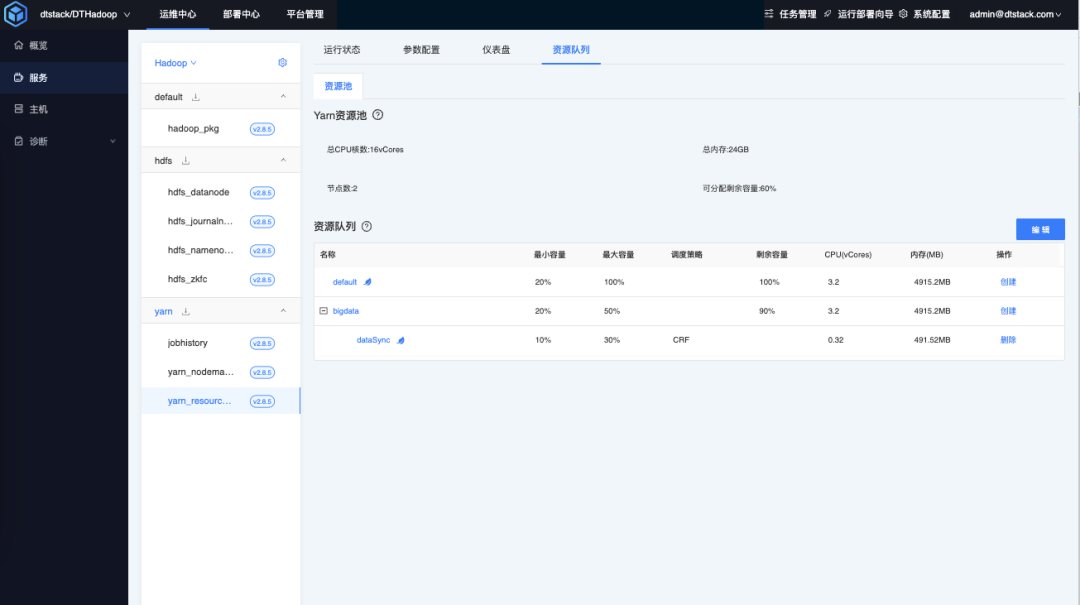
After EasyMR is created, you can also check the queue creation details on the yarn web management page.
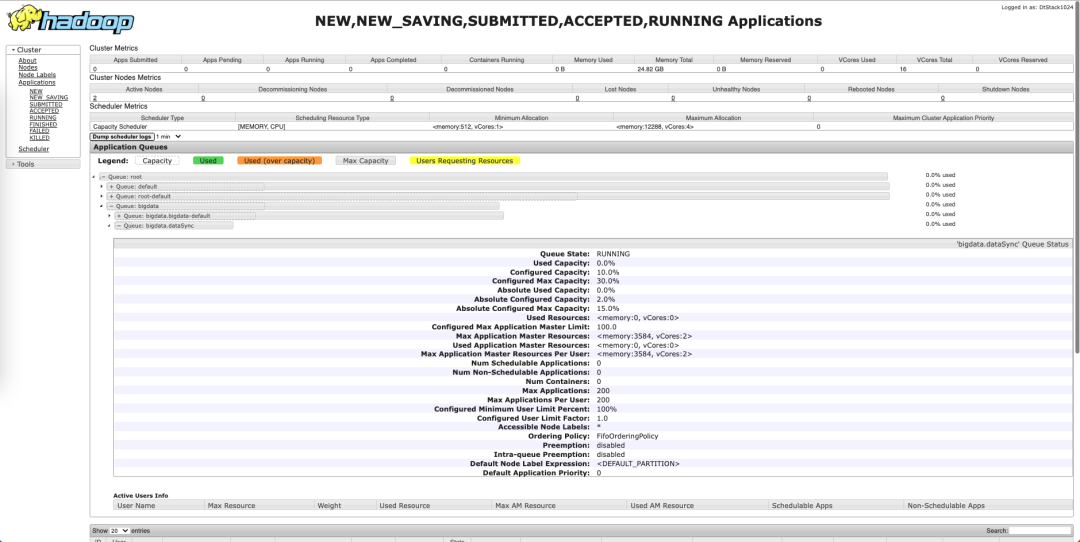
So far, a simple capacity scheduling of Yarn has been created.
"Dutstack Product White Paper": https://www.dtstack.com/resources/1004?src=szsm
"Data Governance Industry Practice White Paper" download address: https://www.dtstack.com/resources/1001?src=szsm If you want to know or consult more about Kangaroo Cloud big data products, industry solutions, and customer cases, visit Kangaroo Cloud official website: https://www.dtstack.com/?src=szkyzg
At the same time, students who are interested in big data open source projects are welcome to join "Kangaroo Cloud Open Source Framework DingTalk Technology qun" to exchange the latest open source technology information, qun number: 30537511, project address: https://github.com/DTStack
Microsoft official announcement: Visual Studio for Mac retired The programming language created by the Chinese developer team: MoonBit (Moon Rabbit) Father of LLVM: Mojo will not threaten Python, the fear should be C++ The father of C++ Bjarne Stroustrup shared life advice Linus also Dislike the acronym, what TM is called "GenPD" Rust 1.72.0 is released, and the minimum supported version in the future is Windows 10 Wenxin said that it will open WordPress to the whole society and launch the "100-year plan" Microsoft does not talk about martial arts and uses "malicious pop-ups "Prompt users to deprecate Google's high-level, functional, interpreted, dynamic programming languages: Crumb