Related Blog
[Megatron-DeepSpeed] Tensor Parallel Tool Code mpu Detailed Explanation (4): Implementation and Testing of Tensor Parallel Version Embedding Layer and Cross Entropy [Megatron-DeepSpeed] Tensor
Parallel Tool Code Mpu Detailed Explanation (3): Tensor Parallel Layer implementation and testing
[Megatron-DeepSpeed] Tensor parallel tool code mpu detailed explanation (1): Parallel environment initialization
[Megatron-DeepSpeed] Tensor parallel tool code mpu detailed explanation (2): Collective communication operation encapsulation mappings
[Deep learning] [Distributed training] DeepSpeed: AllReduce and ZeRO-DP
[Deep learning] Mixed precision training and memory analysis
[Deep learning] [Distributed training] Collective communication operation and Pytorch example
[Natural language processing] [Large model] BLOOM, a large language model Reasoning tool test
[Natural Language Processing] [Large Model] GLM-130B: an open source bilingual pre-trained language model
[Natural Language Processing] [Large Model] Introduction to 8-bit matrix multiplication for large Transformers
Megatron-DeepSpeed is the DeepSpeed version of NVIDIA Megatron-LM. Mainstream large models such as BLOOM and GLM-130B are developed based on Megatron-DeepSpeed. Here we take the BLOOM version of Megetron-DeepSpeed as an example to introduce the details of its tensor parallel code mpu (located under megatron/mpu).
Relevant principle knowledge suggested reading:
- [Deep Learning] [Distributed Training] Collective Communication Operation and Pytorch Example
- [Deep Learning] [Distributed Training] One article outlines 100 billion model training techniques: pipeline parallelism, tensor parallelism and 3D parallelism
- [Deep Learning] [Distributed Training] DeepSpeed: AllReduce and ZeRO-DP
Strongly recommend reading , otherwise it will affect the understanding of this article:
Reading suggestions:
- This article will only analyze the core code, and will not introduce all the code;
- This article will provide some test scripts to demonstrate the functionality of each part of the code;
- Practical hands-on exercises are recommended to deepen understanding;
- It is recommended to have a certain understanding of Collective communication and distributed model training before reading this article;
1. Overview
The core files in the mpu directory are:
- initialize.py: Responsible for the initialization of data parallel groups, tensor parallel groups and pipeline parallel groups, and obtaining information related to various parallel groups;
- data.py: Realize the data broadcast function in tensor parallelism;
- cross_entropy.py: Tensor parallel version of cross entropy;
- layers.py: Parallel version of Embedding layer, as well as column parallel linear layer and row parallel linear layer;
- mappings.py : used for tensor parallel communication operations;
2. Code implementation and testing
1. _reduce
source code
_reduce provides the function of performing All-Reduce on the entire tensor parallel group. The function is defined as follows:
def _reduce(input_):
"""
在模型并行组上对输入张量执行All-reduce.
"""
if get_tensor_model_parallel_world_size()==1:
return input_
# All-reduce.
torch.distributed.all_reduce(input_, group=get_tensor_model_parallel_group())
return input_
test code
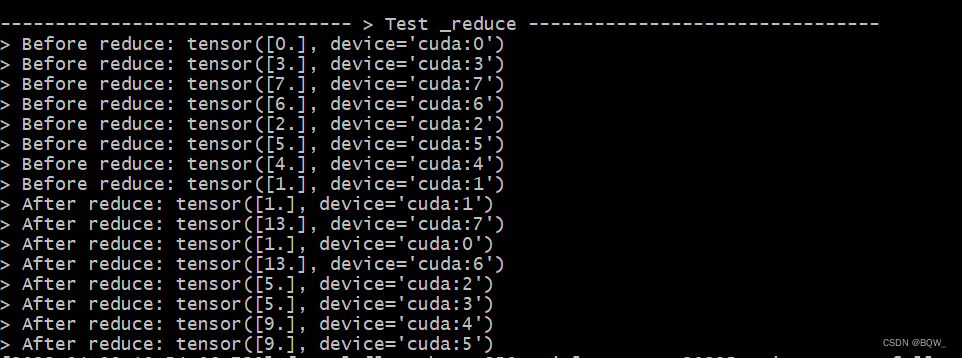
The test follows the article [Megatron-DeepSpeed] Tensor Parallel Tool Code mpu Detailed Explanation (1): The settings in the parallel environment initialization, the tensor parallelism is 2, and the pipeline parallelism is 2. Then the tensor parallel groups are: [Rank0, Rank1], [Rank2, Rank3], [Rank4, Rank5], [Rank6, Rank7].
def test_reduce():
print_separator(f'> Test _reduce')
global_rank = torch.distributed.get_rank()
# global_rank为1时,则会生成张量tensor([1])
tensor = torch.Tensor([global_rank]).to(torch.device("cuda", global_rank))
print(f"> Before reduce: {
tensor}")
# 保证reduce前后的输出不混乱
torch.distributed.barrier()
# reduce操作
# 期望结果:[Rank0, Rank1]为一组,经过reduce后均为tensor([1])
# 期望结果:[Rank6, Rank7]为一组,经过reduce后均为tensor([13])
mappings._reduce(tensor)
print(f"> After reduce: {
tensor}")
Test Results
2. _gather
source code
Collect the tensors in the tensor parallel group and concatenate them according to the last dimension.
def _gather(input_):
"""
gather张量并按照最后一维度拼接.
"""
world_size = get_tensor_model_parallel_world_size()
if world_size==1:
return input_
# 最后一维的索引
last_dim = input_.dim() - 1
# 张量并行组中的rank
rank = get_tensor_model_parallel_rank()
# 初始化空张量列表,用于存储收集来的张量
tensor_list = [torch.empty_like(input_) for _ in range(world_size)]
tensor_list[rank] = input_
torch.distributed.all_gather(tensor_list, input_, group=get_tensor_model_parallel_group())
# 拼接
output = torch.cat(tensor_list, dim=last_dim).contiguous()
return output
test code
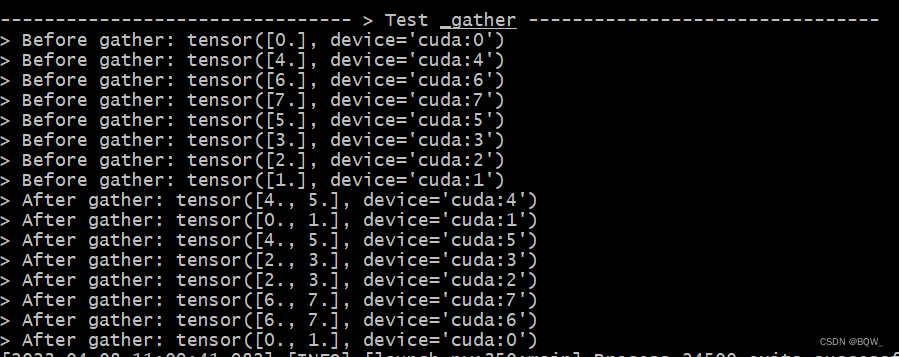
The experimental setup is the same as above.
def test_gather():
print_separator(f'> Test _gather')
global_rank = torch.distributed.get_rank()
# global_rank为1时,则会生成张量tensor([1])
tensor = torch.Tensor([global_rank]).to(torch.device("cuda", global_rank))
print(f"> Before gather: {
tensor}\n", end="")
torch.distributed.barrier()
# 期望结果:[Rank0, Rank1]为一组,经过gather后均为tensor([0., 1.])
gather_tensor = mappings._gather(tensor)
print(f"> After gather: {
gather_tensor}\n", end="")
Test Results
3. _split
source code
Splits a tensor along the last dimension and keeps the shards corresponding to rank.
def _split(input_):
"""
沿最后一维分割张量,并保留对应rank的分片.
"""
world_size = get_tensor_model_parallel_world_size()
if world_size==1:
return input_
# 按world_size分割输入张量input_
input_list = split_tensor_along_last_dim(input_, world_size)
# Note: torch.split does not create contiguous tensors by default.
rank = get_tensor_model_parallel_rank()
output = input_list[rank].contiguous()
return output
test code
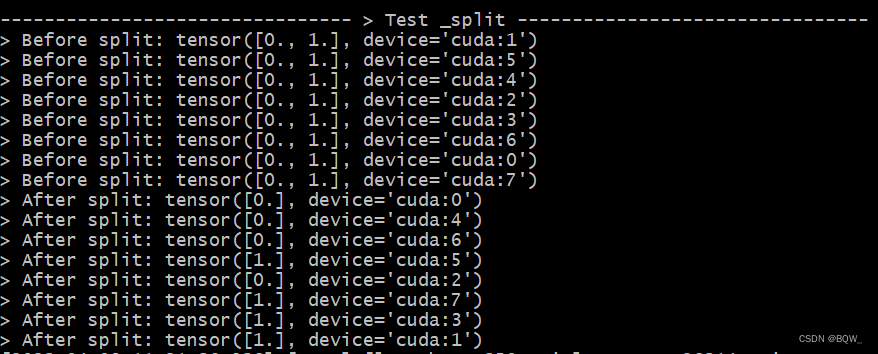
The test setup is the same as above.
def test_split():
print_separator(f'> Test _split')
global_rank = torch.distributed.get_rank()
# 在实验设置下为tp_world_size=2
tp_world_size = mpu.get_tensor_model_parallel_world_size()
# 在实验设置下tensor=[0,1]
tensor = torch.Tensor(list(range(tp_world_size))).to(torch.device("cuda", global_rank))
print(f"> Before split: {
tensor}\n", end="")
torch.distributed.barrier()
# 期望结果:Rank0,Rank2,Rank4,Rank6持有张量tensor([0])
# 期望结果:Rank1,Rank3,Rank5,Rank7持有张量tensor([1])
split_tensor = mappings._split(tensor)
print(f"> After split: {
split_tensor}\n", end="")
Test Results
4. copy_to_tensor_model_parallel_region
source code
- During forward propagation, do nothing
- When backpropagating, sum the gradients of all pairs of input_ in the same tensor group
class _CopyToModelParallelRegion(torch.autograd.Function):
@staticmethod
def symbolic(graph, input_):
return input_
@staticmethod
def forward(ctx, input_): # 前向传播时,不进行任何操作
return input_
@staticmethod
def backward(ctx, grad_output): # 反向传播时,对同张量并行组的梯度进行求和
return _reduce(grad_output)
def copy_to_tensor_model_parallel_region(input_):
return _CopyToModelParallelRegion.apply(input_)
test code
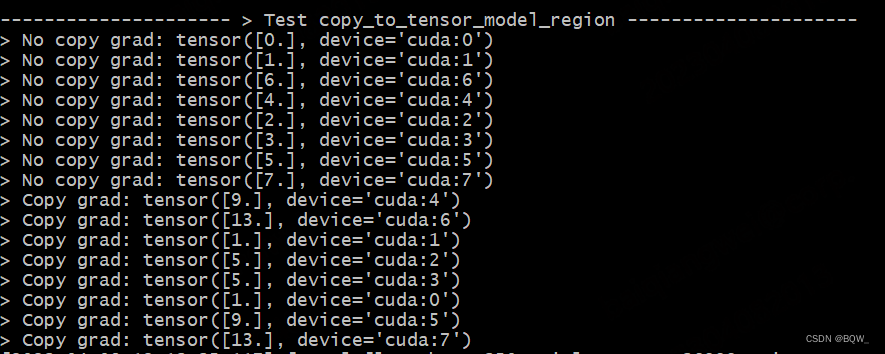
The test setup is the same as above. In this experiment, copy and non-copy tensors will be used to find the gradient and show the difference.
def test_copy_to_tensor_model_parallel_region():
print_separator(f'> Test copy_to_tensor_model_region^S')
global_rank = torch.distributed.get_rank()
# global_rank为1时,则会生成张量tensor([1])
tensor = Parameter(torch.Tensor([global_rank]).to(torch.device("cuda", global_rank)))
loss = global_rank * tensor
loss.backward()
# 非copy的tensor梯度期望结果为,Ranki的梯度为i
print(f"> No copy grad: {
tensor.grad}\n", end="")
torch.distributed.barrier()
tensor.grad = None
# 使用copy_to_tensor_model_parallel_region对tensor进行操作
# 该操作不会影响前向传播,仅影响反向传播
tensor_parallel = mappings.copy_to_tensor_model_parallel_region(tensor)
# 例:对于rank=5,则loss=5*x,其反向传播的梯度为5;依次类推
loss_parallel = global_rank * tensor_parallel
loss_parallel.backward()
torch.distributed.barrier()
# 例:张量组[Rank6, Rank7]的期望梯度均为13
print(f"> Copy grad: {
tensor.grad}\n", end="")
Test Results
5. reduce_from_tensor_model_parallel_region
source code
- During forward propagation, allreduce the input input_ of the same tensor parallel group;
- When backpropagating, directly return the gradient of input_;
class _ReduceFromModelParallelRegion(torch.autograd.Function):
@staticmethod
def symbolic(graph, input_):
return _reduce(input_)
@staticmethod
def forward(ctx, input_): # 前向传播时,对张量并行组中的输入进行allreduce
return _reduce(input_)
@staticmethod
def backward(ctx, grad_output):
return grad_output
def reduce_from_tensor_model_parallel_region(input_):
return _ReduceFromModelParallelRegion.apply(input_)
test code
The test setup is the same as above.
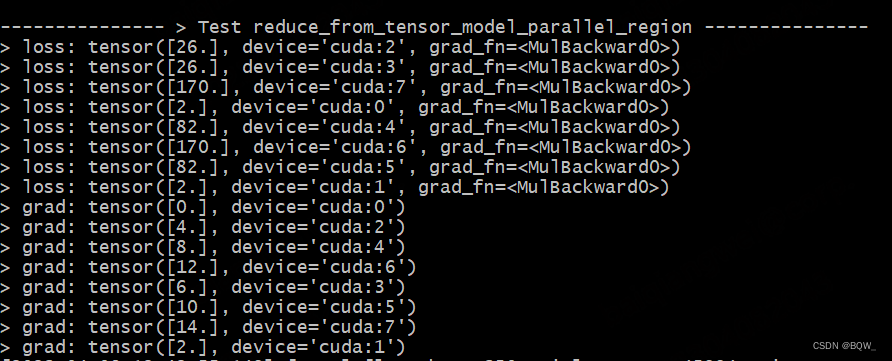
Take the tensor parallel group [Rank6, Rank7] as an example, loss = 2 ∗ ( 6 ∗ x 6 + 7 ∗ x 7 ) loss=2*(6*x_6+7*x_7)loss=2∗(6∗x6+7∗x7) . Therefore, the result of forward propagation is2 ∗ ( 6 ∗ 6 + 7 ∗ 7 ) = 170 2*(6*6+7*7)=1702∗(6∗6+7∗7)=170 . The backpropagation gradient of Rank6 is 12, and the backpropagation gradient of Rank7 is 14.
def test_reduce_from_tensor_model_parallel_region():
print_separator(f"> Test reduce_from_tensor_model_parallel_region")
global_rank = torch.distributed.get_rank()
# global_rank为1时,则会生成张量tensor([1])
tensor1 = Parameter(torch.Tensor([global_rank]).to(torch.device("cuda", global_rank)))
tensor2 = global_rank * tensor1
tensor_parallel = mappings.reduce_from_tensor_model_parallel_region(tensor2)
loss = 2 * tensor_parallel
loss.backward()
print(f"> value: {
tensor1.data}\n", end="")
print(f"> grad: {
tensor1.grad}\n", end="")
Test Results
6. scatter_to_tensor_model_parallel_region
source code
- During forward propagation, split the input input_ into different processes of the same tensor parallel group;
- When backpropagating, the gradients of the same tensor parallel group are collected and spliced;
class _ScatterToModelParallelRegion(torch.autograd.Function):
"""
分割输入,仅保留对应rank的块。
"""
@staticmethod
def symbolic(graph, input_):
return _split(input_)
@staticmethod
def forward(ctx, input_): # 切分输入
return _split(input_)
@staticmethod
def backward(ctx, grad_output): # 收集梯度
return _gather(grad_output)
def scatter_to_tensor_model_parallel_region(input_):
return _ScatterToModelParallelRegion.apply(input_)
test code
The test setup is the same as above.
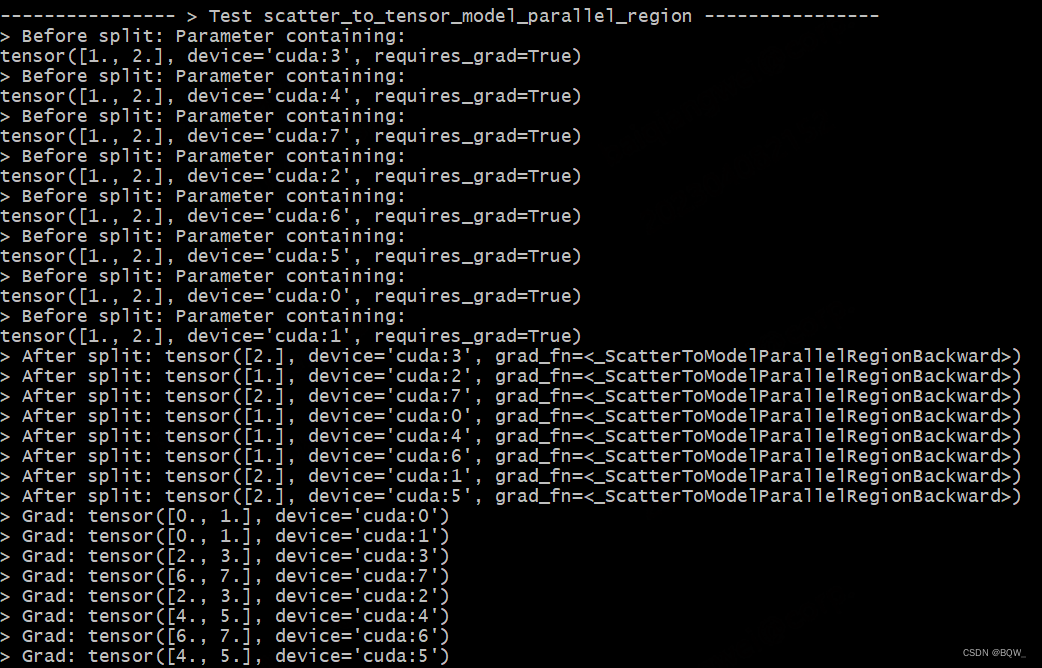
Taking the tensor parallel group [Rank6, Rank7] as an example, the gradient of Rank6 is 6, and the gradient of Rank7 is 7. scatter_to_tensor_model_parallel_regionThe backward process will collect the gradients of both, so the gradients of Rank6 and Rank7 are both tensor([6.,7.]).
def test_scatter_to_tensor_model_parallel_region():
print_separator(f'> Test scatter_to_tensor_model_parallel_region')
global_rank = torch.distributed.get_rank()
tp_world_size = mpu.get_tensor_model_parallel_world_size()
# tensor = [1,2]
tensor = Parameter(torch.Tensor(list(range(1, tp_world_size+1))).to(torch.device("cuda", global_rank)))
# split之后, Rank0、Rank2、Rank4、Rank6为tensor([1]), 其余Rank为tensor([2])
tensor_split = mappings.scatter_to_tensor_model_parallel_region(tensor)
loss = global_rank * tensor_split
loss.backward()
print(f"> Before split: {
tensor}\n", end="")
torch.distributed.barrier()
print(f"> After split: {
tensor_split}\n", end="")
torch.distributed.barrier()
print(f"> Grad: {
tensor.grad}\n", end="")
Test Results
7. gather_from_tensor_model_parallel_region
source code
- During forward propagation, the input_ of the same tensor parallel group is collected and spliced together;
- When backpropagating, divide the gradient into different processes of the same tensor parallel group;
class _GatherFromModelParallelRegion(torch.autograd.Function):
"""
收集张量并行组的张量并拼接
"""
@staticmethod
def symbolic(graph, input_):
return _gather(input_)
@staticmethod
def forward(ctx, input_): # 前向传播时,相同张量并行组gather在一起
return _gather(input_)
@staticmethod
def backward(ctx, grad_output): # 反向传播时,将张量split至张量组中的机器
return _split(grad_output)
test code
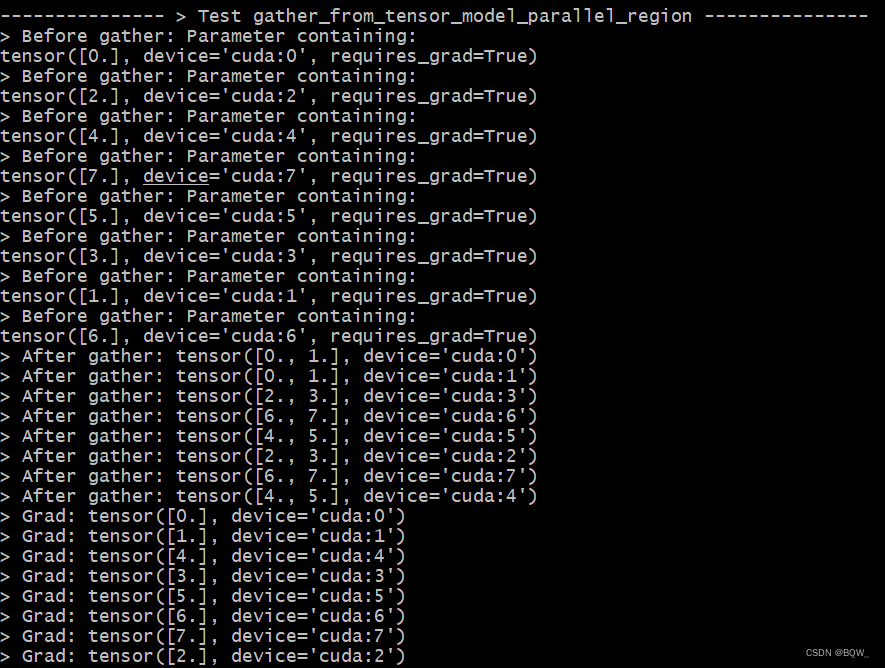
The test setup is the same as above.
def test_gather_from_tensor_model_parallel_region():
print_separator(f'> Test gather_from_tensor_model_parallel_region')
global_rank = torch.distributed.get_rank()
# tp_world_size = mpu.get_tensor_model_parallel_world_size()
tensor = Parameter(torch.Tensor([global_rank]).to(torch.device("cuda", global_rank)))
print(f"> Before gather: {
tensor}\n", end="")
torch.distributed.barrier()
gather_tensor = mappings.gather_from_tensor_model_parallel_region(tensor)
print(f"> After gather: {
gather_tensor.data}\n", end="")
loss = (global_rank * gather_tensor).sum()
loss.backward()
print(f"> Grad: {
tensor.grad}\n", end="")
Test Results
3. Complete test script
The test uses 8 graphics cards. Here is the full test script:
# test_mappings.py
import sys
sys.path.append("..")
from torch.nn.parameter import Parameter
from commons import print_separator
from commons import initialize_distributed
import megatron.mpu.mappings as mappings
import megatron.mpu as mpu
import torch
def test_reduce():
print_separator(f'> Test _reduce')
global_rank = torch.distributed.get_rank()
tensor = torch.Tensor([global_rank]).to(torch.device("cuda", global_rank))
print(f"> Before reduce: {
tensor}\n", end="")
torch.distributed.barrier()
mappings._reduce(tensor)
print(f"> After reduce: {
tensor}\n", end="")
def test_gather():
print_separator(f'> Test _gather')
global_rank = torch.distributed.get_rank()
tensor = torch.Tensor([global_rank]).to(torch.device("cuda", global_rank))
print(f"> Before gather: {
tensor}\n", end="")
torch.distributed.barrier()
gather_tensor = mappings._gather(tensor)
print(f"> After gather: {
gather_tensor}\n", end="")
def test_split():
print_separator(f'> Test _split')
global_rank = torch.distributed.get_rank()
tp_world_size = mpu.get_tensor_model_parallel_world_size()
tensor = torch.Tensor(list(range(tp_world_size))).to(torch.device("cuda", global_rank))
print(f"> Before split: {
tensor}\n", end="")
torch.distributed.barrier()
split_tensor = mappings._split(tensor)
print(f"> After split: {
split_tensor}\n", end="")
def test_copy_to_tensor_model_parallel_region():
print_separator(f'> Test copy_to_tensor_model_region')
global_rank = torch.distributed.get_rank()
# global_rank为1时,则会生成张量tensor([1])
tensor = Parameter(torch.Tensor([global_rank]).to(torch.device("cuda", global_rank)))
loss = global_rank * tensor
loss.backward()
print(f"> No copy grad: {
tensor.grad}\n", end="")
torch.distributed.barrier()
tensor.grad = None
# 使用copy_to_tensor_model_parallel_region对tensor进行操作
# 该操作不会影响前向传播,仅影响反向传播
tensor_parallel = mappings.copy_to_tensor_model_parallel_region(tensor)
# 例:对于rank=5,则loss=5*x,其反向传播的梯度为5;依次类推
loss_parallel = global_rank * tensor_parallel
loss_parallel.backward()
torch.distributed.barrier()
print(f"> Copy grad: {
tensor.grad}\n", end="")
def test_reduce_from_tensor_model_parallel_region():
print_separator(f"> Test reduce_from_tensor_model_parallel_region")
global_rank = torch.distributed.get_rank()
# global_rank为1时,则会生成张量tensor([1])
tensor1 = Parameter(torch.Tensor([global_rank]).to(torch.device("cuda", global_rank)))
tensor2 = global_rank * tensor1
tensor_parallel = mappings.reduce_from_tensor_model_parallel_region(tensor2)
loss = 2 * tensor_parallel
loss.backward()
print(f"> loss: {
loss}\n", end="")
print(f"> grad: {
tensor1.grad}\n", end="")
def test_scatter_to_tensor_model_parallel_region():
print_separator(f'> Test scatter_to_tensor_model_parallel_region')
global_rank = torch.distributed.get_rank()
tp_world_size = mpu.get_tensor_model_parallel_world_size()
# tensor = [1,2]
tensor = Parameter(torch.Tensor(list(range(1, tp_world_size+1))).to(torch.device("cuda", global_rank)))
# split之后, Rank0、Rank2、Rank4、Rank6为tensor([1]), 其余Rank为tensor([2])
tensor_split = mappings.scatter_to_tensor_model_parallel_region(tensor)
loss = global_rank * tensor_split
loss.backward()
print(f"> Before split: {
tensor}\n", end="")
torch.distributed.barrier()
print(f"> After split: {
tensor_split}\n", end="")
torch.distributed.barrier()
print(f"> Grad: {
tensor.grad}\n", end="")
def test_gather_from_tensor_model_parallel_region():
print_separator(f'> Test gather_from_tensor_model_parallel_region')
global_rank = torch.distributed.get_rank()
tensor = Parameter(torch.Tensor([global_rank]).to(torch.device("cuda", global_rank)))
print(f"> Before gather: {
tensor}\n", end="")
torch.distributed.barrier()
# 例: [Rank6, Rank7]的gather_tensor均为tensor([6.,7.])
gather_tensor = mappings.gather_from_tensor_model_parallel_region(tensor)
print(f"> After gather: {
gather_tensor.data}\n", end="")
loss = (global_rank * gather_tensor).sum()
loss.backward()
print(f"> Grad: {
tensor.grad}\n", end="")
if __name__ == '__main__':
initialize_distributed()
world_size = torch.distributed.get_world_size()
tensor_model_parallel_size = 2
pipeline_model_parallel_size = 2
# 并行环境初始化
mpu.initialize_model_parallel(
tensor_model_parallel_size,
pipeline_model_parallel_size)
test_reduce()
test_gather()
test_split()
test_copy_to_tensor_model_parallel_region()
test_reduce_from_tensor_model_parallel_region()
test_scatter_to_tensor_model_parallel_region()
test_gather_from_tensor_model_parallel_region()
The startup script is
deepspeed test_mappings.py