foreword
Text generation aims to use NLP technology to generate a specific target text sequence based on given information. There are many application scenarios, and similar model frameworks can be adapted to different application scenarios by adjusting the corpus. This article focuses on the Encoder-Decoder structure, and lists some technical developments that use text summarization or QA system text generation as experimental scenarios.
Seq2Seq framework and its latest research progress
The Seq2Seq framework was originally an algorithm architecture designed to solve machine translation tasks, and it is mainly divided into two parts: an encoder and a decoder. The encoder is responsible for compressing the source language sentence into a vector in the semantic space, which is expected to contain the main information of the source language sentence; the other part of the decoder, based on the semantic vector provided by the encoder, produces semantically equivalent target language sentences . Its essence is to solve the many-to-many mapping task. The following is mainly from the motivation of model construction, pre-training tasks, fine-tuning and experiments in a comparative manner.
Introduce two comparative models BART and T5 with leading edge.
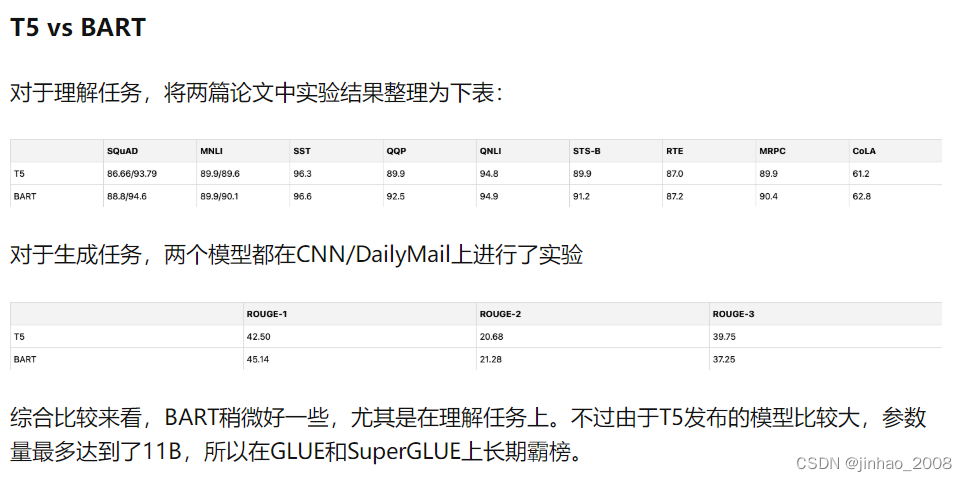
| T5 | BART | |
|---|---|---|
| motivation | It is an overview of language models, looking for the optimal structure of language models, determining the Seq2Seq structure after trying various structures, conducting a large number of experiments through multi-task learning and other perspectives, and then reaching the SOTA level on NLU and NLG tasks. Output C4 English corpus. | Want to unify BERT and GPT, determine the original structure of Transformers. BART explores the effectiveness of various objective functions, that is, adding various types of noise to the input and restoring it at the output. On the premise that NLU remains similar to RoBerta, BART has achieved SOTA results on multiple NLG tasks. |
| Model Features | 1. T5 changes Position Encoding to relative position embedding 2. T5 still adopts ReLU |
1. BART is replaced with the same learnable absolute position code as BERT 2. GELU is used when the activation function BART is the same as BERT and GPT |
| pre-training task | T5 uses two tasks, classified as supervised and unsupervised. Among them, the unsupervised task is also a span-level mask, but the output does not need to restore the entire sentence. You only need to output the masked tokens. There is little improvement in supervised tasks. T5 also experimented with other mission types. Prefix language model task, Bert style task (decode output original sentence is similar to BART) and scramble restoration task (DEshuffling) | 1. Restore the input with noise 2. Use Text Infilling + Sentence permutation, where Text Infilling plays the most important role, which is the Span-level mask. The length of the span can be 0, and it obeys the Poisson distribution |
| fine-tuning | 1) Fine-tuning on multi-task learning 2) Regardless of classification tasks or generation tasks, they are all regarded as generative tasks |
1) The input of the classification task is sent to the Encoder and decoder at the same time, and the final output text representation 2) When translating tasks, since the vocabulary (the vocabulary of the translation task and the vocabulary of the model) is different, a small Encoder is used to replace the Embedding in BART |
| experiment | The T5 experiment was not directly compared with BERT, which only has an Encoder model, because the experiment needs to complete the generation task, which BERT cannot complete. T5: 2048 ( batch_size)* 512(seq_length) * 1000000(steps) T5-base: 12-12-768(220M) T5-large: 24-24-1024(770M) |
BART: 8000(batch_size) * 512(seq_length) * 500000(steps) BART-large: 12-12-1024 |
Analysis of key technical points
The difference between Relu and GELU activation functions
| resume | GELU (Gaussian Error Linear Unit) | |
|---|---|---|
| Functional properties | Piecewise linear functions are not smooth, and are not smooth at some point (point 0 is not differentiable) | Basically linear output, non-linear output when x is close to 0. have a certain continuity, |
| advantage | Simplify the calculation process, reduce the calculation cost, and avoid gradient explosion and gradient disappearance | Provides random regularity while maintaining input information, improving the generalization ability of the model |
| shortcoming | The zero point is not differentiable, which will affect the network performance to some extent, and it is necessary to add random regularization to improve the generalization ability of the model | High computational complexity and increased computational cost |
| graphics |  |
 |