index
The concept of index
The index is a sorted list, in which the value of the index and the physical address of the row where the data containing this value is stored (similar to the linked list in C language through the pointer to the memory address of the data record).
After using the index, you do not need to scan the entire table to locate the data of a row, but first find the physical address corresponding to the row of data through the index table and then access the corresponding data, thus speeding up the query speed of the database.
The index is like the table of contents of a book, you can quickly find what you need according to the page number in the table of contents.
An index is a method of sorting the values of a column or several columns in a table.
The purpose of indexing is to speed up the lookup or sorting of records in a table.
The role of the index
After setting up a suitable index, the database can greatly speed up the query speed by using various fast positioning technologies, which is the main reason for creating an index.
When the table is large or the query involves multiple tables, using an index can speed up the query by thousands of times.
The IO cost of the database can be reduced, and the index can also reduce the sorting cost of the database.
By creating a unique index, the uniqueness of each row of data in the data table can be guaranteed.
Can speed up joins between tables.
When using grouping and sorting, the time for grouping and sorting can be greatly reduced.
Indexing can significantly improve performance when searching and restoring data in the database
Side effects of indexing:
Indexes require additional disk space.
For the MyISAM engine, the index file and the data file are separated, and the index file is used to save the address of the data record.
The table data files of the InnoDB engine are themselves index files.
Updating a table with an index takes more time than updating a table without an index because the index itself also needs to be updated. Therefore, the ideal approach is to create indexes only on frequently searched columns (and tables).
Rules for creating indexes
Although indexes can improve the speed of database queries, they are not suitable for creating indexes in any situation. Because the index itself consumes system resources, if there is an index, the database will perform index query first, and then locate specific data rows. If the index is not used properly, it will increase the burden on the database.
The primary key and foreign key of the table must have indexes. Because the primary key is unique, the foreign key is associated with the primary key of the main table, which can be quickly located when querying.
Tables with more than 300 rows should have indexes. If there is no index, each query needs to traverse the table, which will seriously affect the performance of the database.
Tables that are frequently joined with other tables should have indexes on the join fields.
Fields that are too unique are not suitable for indexing.
Fields that are updated too frequently are not suitable for indexing.
Fields that often appear in where clauses, especially those in large tables, should be indexed.
Build indexes on fields that are frequently grouped by and ordered by;
Indexes should be built on highly selective fields.
Indexes should be built on small fields, and do not build indexes on large text fields or even super-long fields.
Classification of Index
normal index
Ordinary index: the most basic index type, without restrictions such as uniqueness.
create index directly
直接创建索引
CREATE INDEX 索引名 ON 表名 (列名[(length)]);
#(列名(length)):length是可选项,下同。如果忽略 length 的值,则使用整个列的值作为索引。如果指定,使用列的前 length 个字符来创建索引,这样有利于减小索引文件的大小。在不损失精确性的情况下,长度越短越好。
#索引名建议以“_index”结尾。
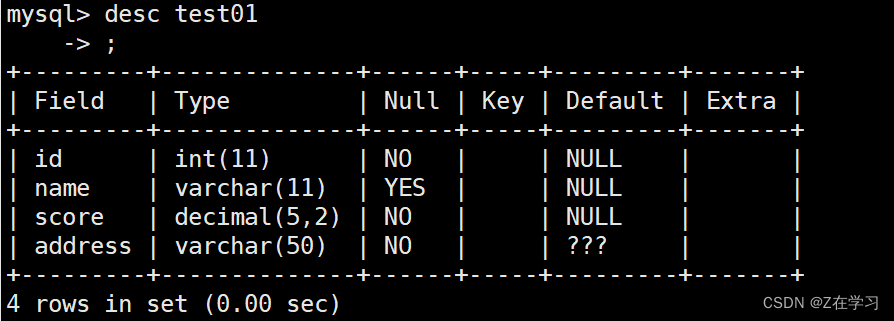
Create an ordinary index on the name of the above table
create index name_index on member (name);
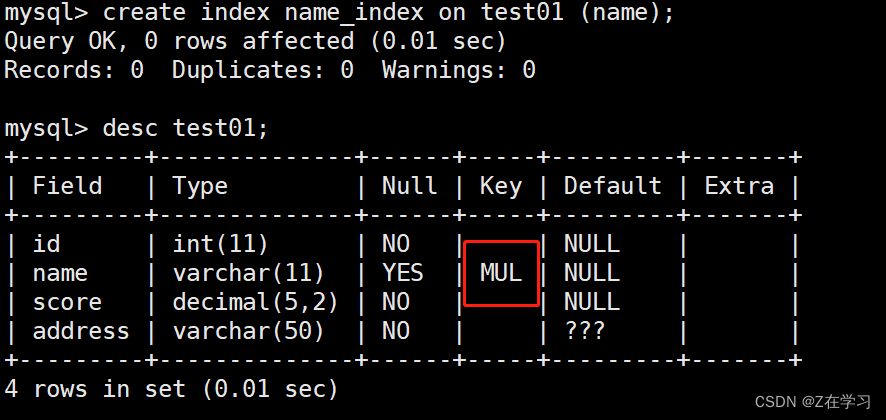
Create indexes by modifying the table
ALTER TABLE 表名 ADD INDEX 索引名 (列名);
alter table test01 add index scoree_index(score);

Specify the index when creating the table
CREATE TABLE 表名 (字段1 数据类型,字段2 数据类型[,...],INDEX 索引名(列名));
create table test04 (id int(10),name varchar(10),cardid int(18),phonenum int(11),address varchar(50),index name_index(name));

unique index
A unique index is similar to a normal index, but the difference is that each value of a unique index column is unique . Unique indexes allow null values ( note that unique indexes are different from primary keys ).
If it is created with a composite index, the combination of column values must be unique. Adding a unique key will automatically create a unique index .
Create a unique index directly
CREATE UNIQUE INDEX 索引名 ON 表名(列名);
create unique index cardid_index on test04(cardid);
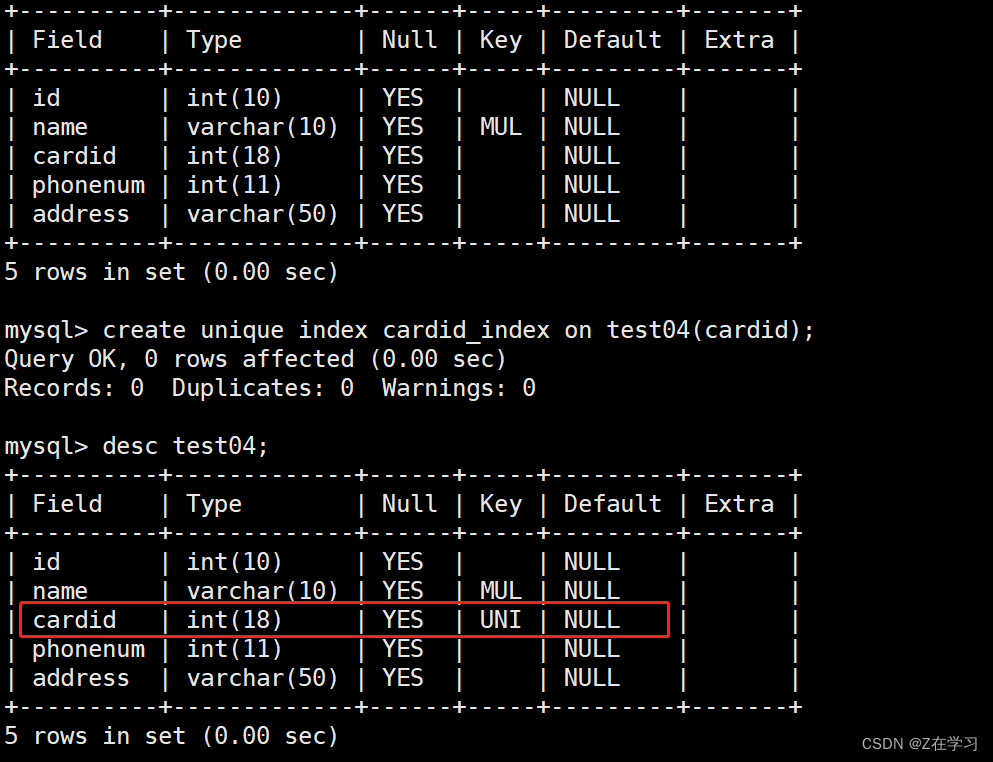
Create a unique index by modifying the table
ALTER TABLE 表名 ADD UNIQUE 索引名 (列名);
alter table test04 add unique phonenum_index(phonenum);

Specify a unique index when creating a table
CREATE TABLE 表名 (字段1 数据类型,字段2 数据类型[,...],UNIQUE 索引名 (列名));
create table test05 (id int(10),name varchar(20),cardid int(18),phonenum int(11),address varchar(48),unique id_index(id));

primary key index
The primary key index is a special unique index that must be specified as " PRIMARY KEY ". A table can only have one primary key, and null values are not allowed . Adding a primary key will automatically create a primary key index.
Specify the index when creating the table
创建表的时候指定
CREATE TABLE 表名 ([...],PRIMARY KEY (列名));create table test06 (id int(10),name varchar(20),cardid int(18),phonenum int(11),address varchar(48),primary key(id));

Modify the table to create a primary key index
ALTER TABLE 表名 ADD PRIMARY KEY (列名);
Create a table without any primary key specified
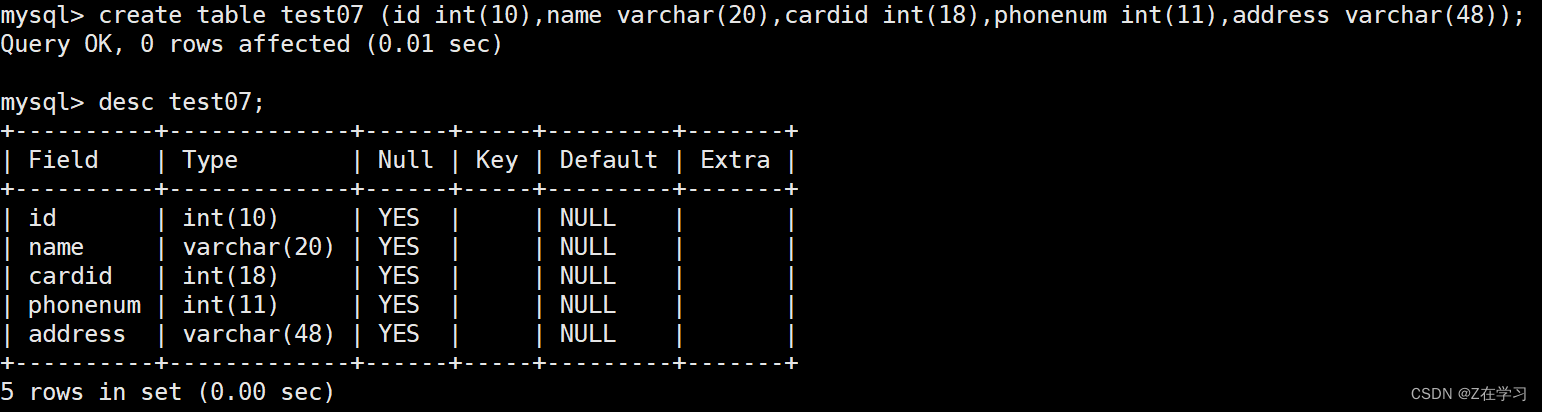 alter table test07 add primary key(id);
alter table test07 add primary key(id);
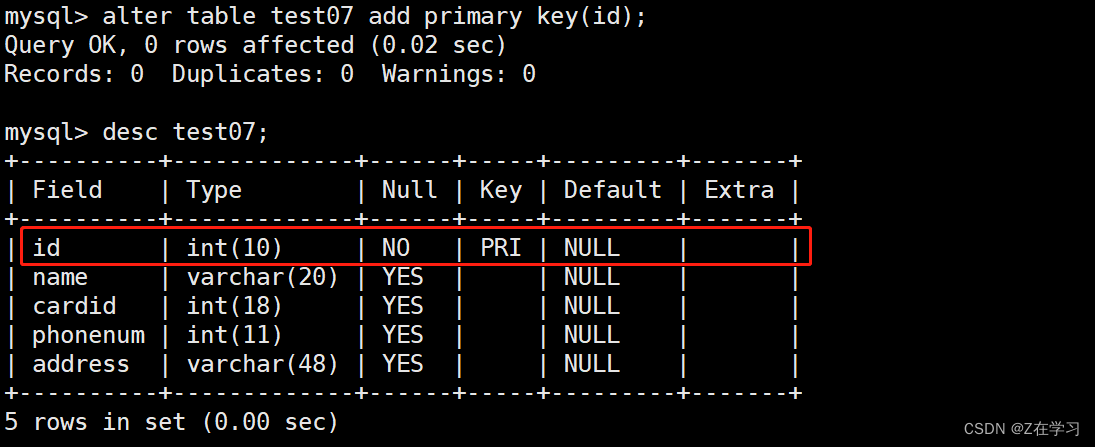
composite index
A composite index can be an index created on a single column or an index created on multiple columns.
The composite index needs to satisfy the leftmost principle , because the where condition of the select statement is executed from left to right in sequence ,
Therefore, when using the select statement to query, the order of the fields used in the where condition must be consistent with the order in the composite index, otherwise the index will not take effect.
Create composite index directly
CREATE INDEX 组合索引名 表名(列名1,列名2,列名3);
select 查询时 where 语句中的条件字段 要与组合索引的字段排列顺序一致(最左原则)
select * from 表名 where 列名1='...' AND 列名2='...' AND 列名3='...';
create index name_cardid_phonenum_index on test07(name,cardid,phonenum);
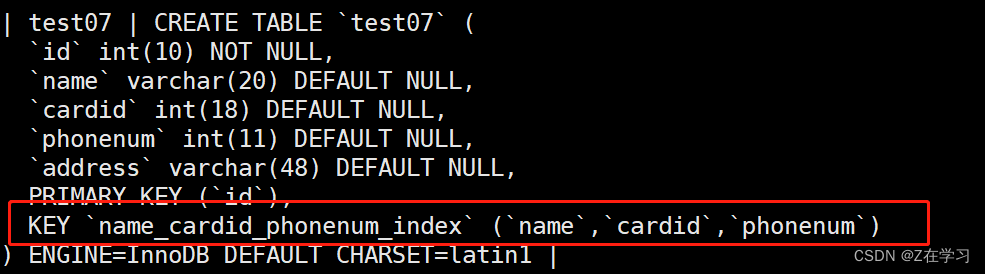
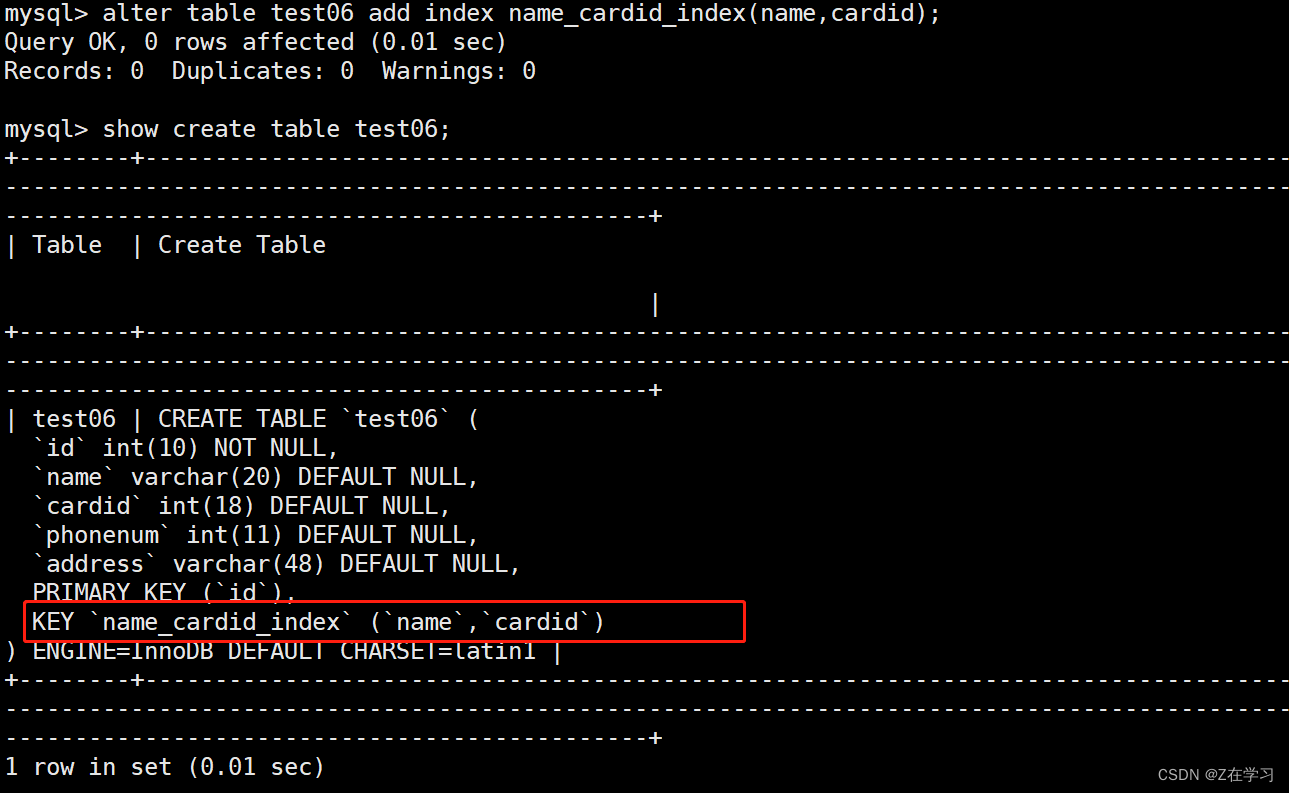
Create a composite index by modifying the table
alter table 表名 add index 索引名 (字段1,字段2,字段3,...);
alter table test06 add index name_cardid_index(name,cardid);
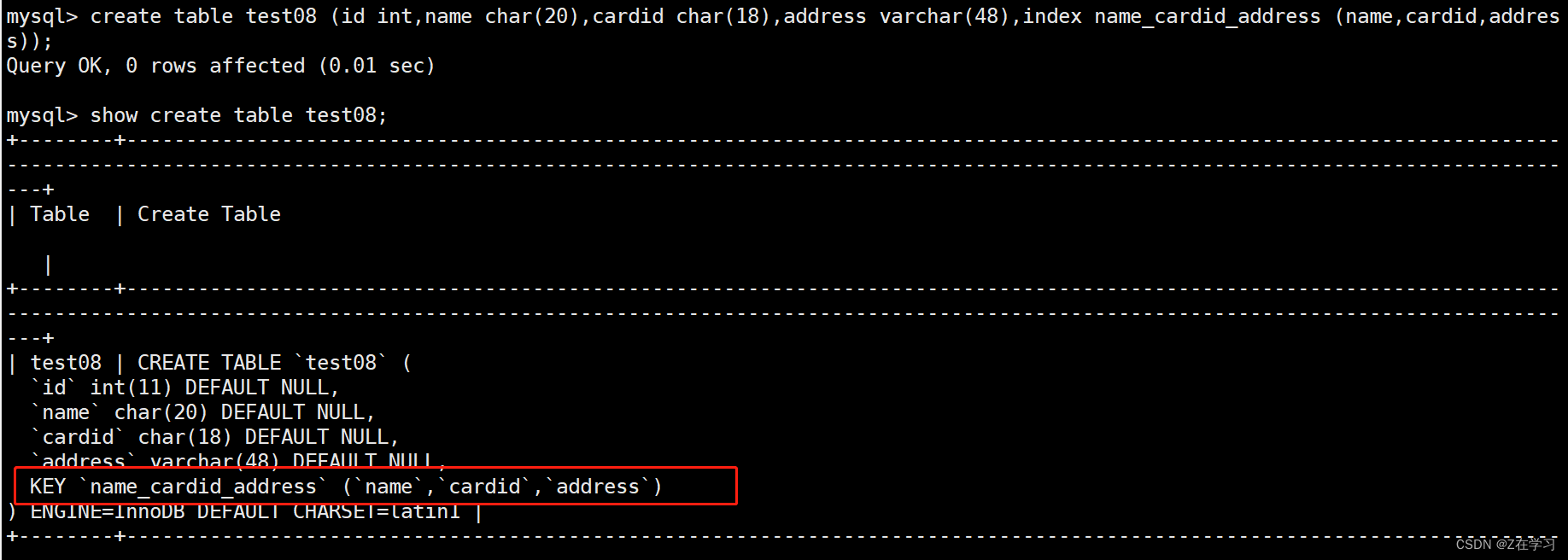
Specify the composite index when creating the table
CREATE TABLE 表名 (列名1 数据类型,列名2 数据类型,列名3 数据类型,INDEX 索引名 (列名1,列名2,列名3));
create table test08 (id int,name char(20),cardid char(18),address varchar(48),index name_cardid_address (name,cardid,address));
Full-text indexing (FULLTEXT)
It is suitable for fuzzy query and can be used to retrieve text information in an article. Before MySQL5.6, the FULLTEXT index can only be used for the MyISAM engine, and after the 5.6 version, the innodb engine also supports the FULLTEXT index. Full-text indexes can be created on columns of type CHAR, VARCHAR, or TEXT.
Create a full-text index directly
CREATE FULLTEXT INDEX 索引名 ON 表名 (列名);
create fulltext index address_index on test06(address);

Create a full-text index by modifying the table
ALTER TABLE 表名 ADD FULLTEXT 索引名(列名);
alter table test0 add fulltext remark_index(address);
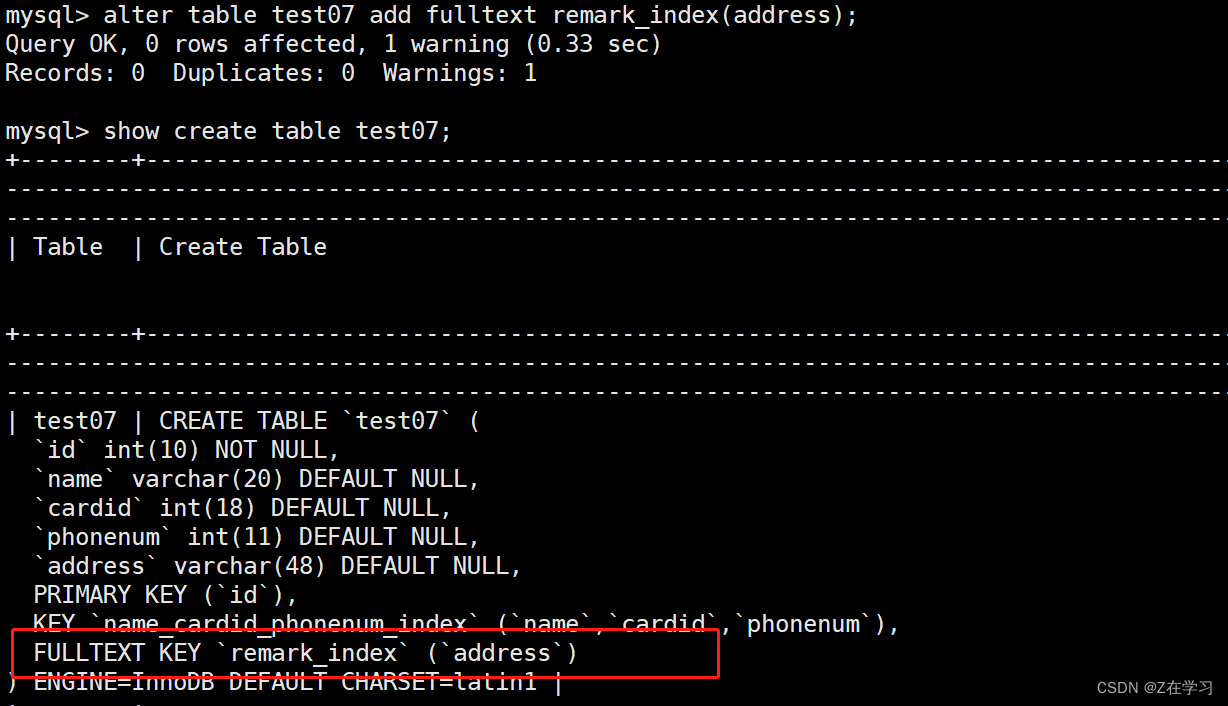
Specify the index when creating the table
CREATE TABLE 表名 (字段1 数据类型[,...],FULLTEXT 索引名 (列名));
#数据类型可以为 CHAR、VARCHAR 或者 TEXT
create table test09 (id int,name char(10),cardid char(20),address varchar(48),fulltext address_index(address));
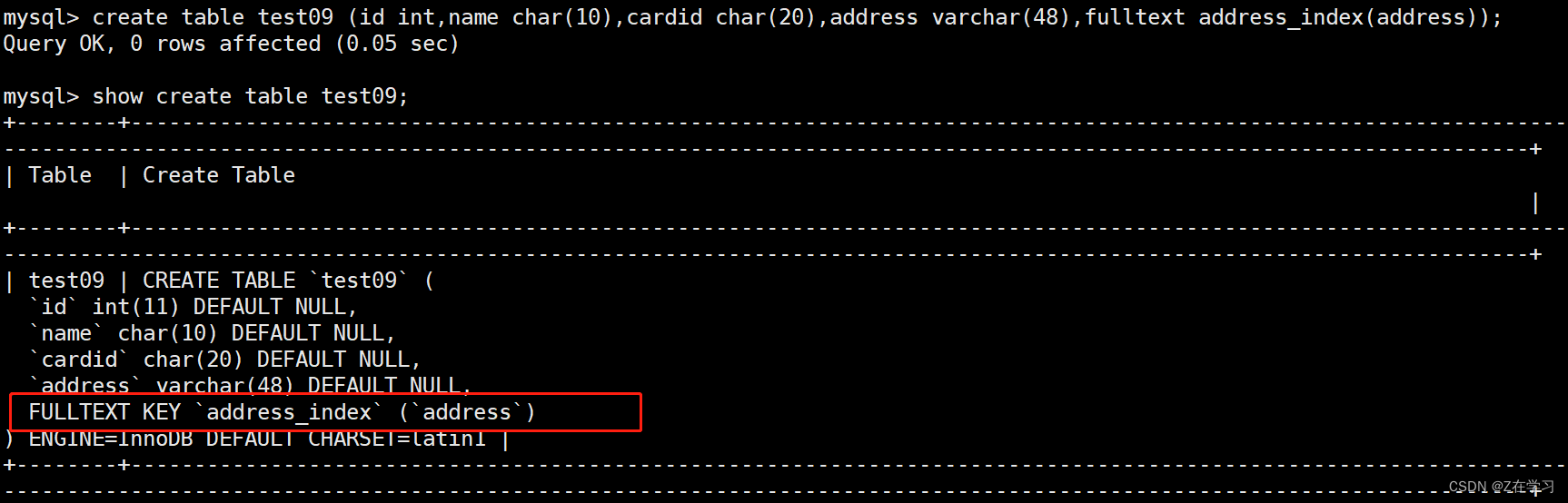
Queries using full-text indexes
#插入表数据
insert into test09 values(1,'aaa','123456','nanjing');
insert into test09 values(2,'bbb','456123','beijing');
insert into test09 values(3,'ccc','7777777','beijing');
insert into test09 values(4,'ddd','090909','shanghai');
insert into test09 values(5,'eee','67890123','nanjing');
#使用全文查询
SELECT * FROM 表名 WHERE MATCH(列名) AGAINST('查询内容');select * from test09 where match(address) against('beijing');

view index
show index from 表名;
show keys from 表名;
各字段的含义如下:
Table:表的名称。
Non_unique:如果索引不能包括重复词,则为 0;如果可以,则为 1。
Key_name:索引的名称。
Seq_in_index:索引中的列序号,从 1 开始。
Column_name:列名称。
Collation:列以什么方式存储在索引中。在 MySQL 中,有值‘A’(升序)或 NULL(无分类)。
Cardinality:索引中唯一值数目的估计值。
Sub_part:如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为 NULL。
Packed:指示关键字如何被压缩。如果没有被压缩,则为 NULL。
Null:如果列含有 NULL,则含有 YES。如果没有,则该列含有 NO。
Index_type:用过的索引方法(BTREE, FULLTEXT, HASH, RTREE)。
Comment:备注
delete index
Delete the index directly
DROP INDEX 索引名 ON 表名;
drop index address_index on test09;
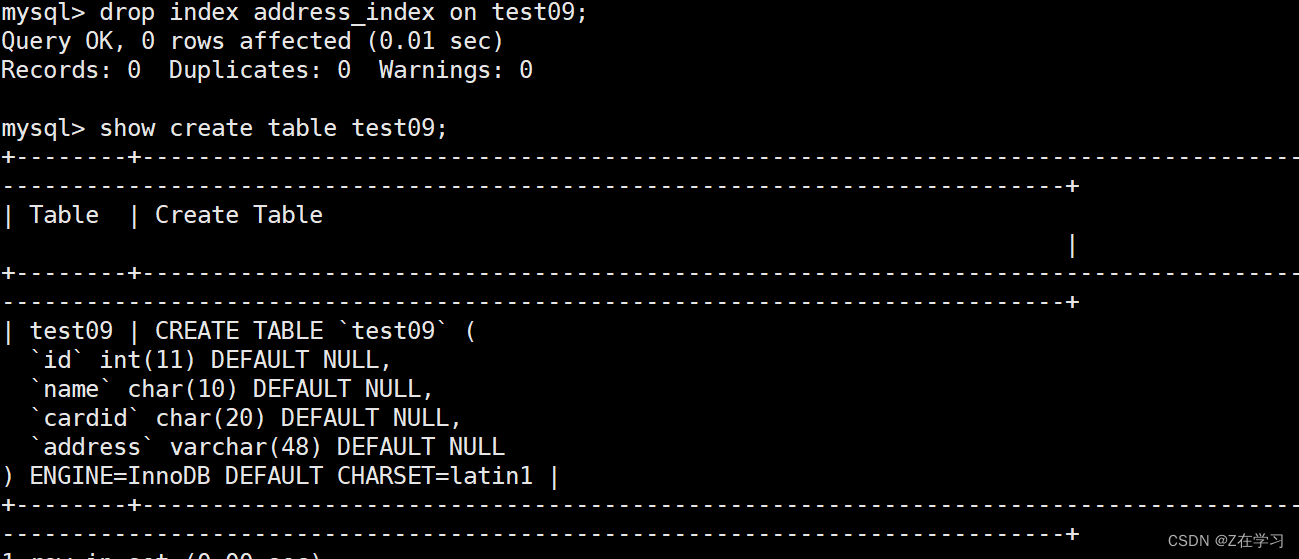
Modify the table to delete the index
ALTER TABLE 表名 DROP INDEX 索引名;
alter table test08 drop index name_cardid_address;

delete primary key index
ALTER TABLE 表名 DROP PRIMARY KEY;
alter table test08 drop primary key;

affairs
business concept
A transaction is a mechanism , an operation sequence, which includes a set of database operation commands, and submits or revokes operation requests to the system together with all the commands as a whole , that is, this set of database commands is either executed or not executed .
A transaction is an indivisible logical unit of work. When performing concurrent operations on a database system, a transaction is the smallest control unit.
Transactions are suitable for scenarios where multiple users operate database systems at the same time, such as banks, insurance companies, and securities trading systems.
Transactions ensure data consistency through the integrity of transactions.
Transactions improve reliability during updates and inserts into tables.
ACID characteristics of transactions
ACID refers to the four characteristics that transactions should have in a reliable database management system (DBMS): Atomicity, Consistency, Isolation, and Durability. These are a few properties that a reliable database should have.
Atomicity
It means that a transaction is an indivisible unit of work, and the operations in the transaction either all occur or none occur.
A transaction is a complete operation, and the elements of a transaction are inseparable.
All elements in a transaction must be committed or rolled back as a whole .
If any element in the transaction fails, the entire transaction fails.
Example:
When A transfers money to B, it executes the deduction statement and submits it. If a system failure occurs at this time, the A account has already been debited, but the B account has not received the additional payment, which will cause a dispute. In this case, the atomicity of the transaction is required to ensure that the transaction is either executed or not executed.
Consistency
It means that the integrity constraints of the database are not violated before the transaction starts and after the transaction ends.
When the transaction completes, the data must be in a consistent state.
Before a transaction starts, the data stored in the database is in a consistent state.
During an ongoing transaction, data may be in an inconsistent state .
When the transaction completes successfully, the data must come back to a known consistent state again.
Example:
When the transfer transaction is completed, regardless of whether the transaction succeeds or fails, it should be ensured that the total deposits of A and B in the table after the transaction is completed are consistent with those before the transaction is executed.
Isolation _
It means that in a concurrent environment, when different transactions manipulate the same data at the same time, each transaction has its own complete data space .
All concurrent transactions that modify data are isolated from each other , indicating that a transaction must be independent, it should not depend on or affect other transactions in any way.
A transaction that modifies data can access the data before another transaction using the same data begins, or after another transaction using the same data ends.
That is to say, when accessing the database concurrently, a user's transaction will not be interfered by other transactions, and the database between concurrent transactions is independent.
When multiple clients access the same table concurrently, the following consistency issues may arise:
Dirty read:
When a transaction is accessing data and modifying the data, but this modification has not been submitted to the database, at this time, another transaction also accesses the data and then uses the data.
non-repeatable read:
Refers to reading the same data multiple times within a transaction. While this transaction is not over, another transaction also accesses the same data. Then, between the two reads in the first transaction, due to the modification of the second transaction, the data read twice by the first transaction may be different. In this way, the data read twice in a transaction is different, so it is called non-repeatable read. (that is, the same data content cannot be read)
phantom read:
A transaction modifies the data in a table, and this modification involves all the data rows in the table. At the same time, another transaction also modifies the data in this table. This modification is to insert a new row of data into the table. Then, the user who operated the previous transaction will find that there is still an unmodified data row in the table, as if an illusion has occurred.
Missing updates:
Two transactions read the same record at the same time. A modifies the record first, and B also modifies the record (B does not know that A has modified it). After B submits the data, the modification result of B overwrites the modification result of A.
The isolation level of a transaction determines the level of visibility between transactions.
MySQL transaction supports the following four isolations to control the modification made by the transaction and notify the modification to other concurrent transactions
1. Uncommitted read (Read Uncommitted (RU)):
Dirty reads are allowed, that is, allowing a transaction to see uncommitted modifications of other transactions. 2. Read Committed (RC):
A transaction is allowed to only see the modifications that have been committed by other transactions, and the uncommitted modifications are not visible. Prevent dirty reads.
3. Repeatable Read (RR): --mysql default isolation level
Make sure that if you execute the same SELECT statement twice in a transaction, you will get the same result, regardless of whether other transactions commit these changes. Dirty reads and non-repeatable reads can be prevented.
4. Serializable (Serializable):——equivalent to lock table
Fully serialized reads, completely isolating one transaction from other transactions. Every time you read, you need to obtain a table-level shared lock, and reading and writing will block each other. Dirty reads, non-repeatable reads and phantom reads can be prevented, (transaction serialization) will reduce the efficiency of the database.
MySQL's default transaction level is repeatable read, while Oracle and SQL Server are read committed.
The scope of action of the transaction isolation level is divided into two types:
事务隔离级别的作用范围分为两种:
● 全局级:对所有的会话有效
● 会话级:只对当前的会话有效
查询全局事务隔离级别:
show global variables like '%isolation%';
SELECT @@global.tx_isolation;
查询会话事务隔离级别:
show session variables like '%isolation%';
SELECT @@session.tx_isolation;
SELECT @@tx_isolation;
设置全局事务隔离级别:
set global transaction isolation level read committed;
set @@global.tx_isolation='read-committed'; #重启服务后失效
设置会话事务隔离级别:
set session transaction isolation level repeatable read;
set @@session.tx_isolation='repeatable-read';Durability _
After the transaction is completed, the changes made by the transaction to the database are persistently saved in the database and will not be rolled back.
It means that regardless of whether the system fails or not, the results of transaction processing are permanent.
Once a transaction is committed, the effects of the transaction are permanently retained in the database.
Summary: In transaction management, atomicity is the foundation, isolation is the means, consistency is the purpose, and persistence is the result.
transaction control statement
BEGIN or START TRANSACTION : Explicitly start a transaction.
COMMIT or COMMIT WORK : Commits the transaction and makes all changes made to the database permanent.
ROLLBACK or ROLLBACK WORK : Rollback ends the user's transaction and undoes all uncommitted modifications in progress.
SAVEPOINT S1 : Use SAVEPOINT to allow creating a rollback point in a transaction, and there can be multiple SAVEPOINTs in a transaction; "S1" represents the name of the rollback point.
ROLLBACK TO [SAVEPOINT] S1 : Roll back the transaction to the mark point.
Check the current isolation level
show session variables like '%isolation%';Modify the isolation level
set session transaction isolation level read committed;Use set settings to control transactions
SET AUTOCOMMIT=0; #禁止自动提交
SET AUTOCOMMIT=1; #开启自动提交,Mysql默认为1
SHOW VARIABLES LIKE 'AUTOCOMMIT'; #查看Mysql中的AUTOCOMMIT值
如果没有开启自动提交,当前会话连接的mysql的所有操作都会当成一个事务直到你输入rollback|commit;当前事务才算结束。当前事务结束前新的mysql连接时无法读取到任何当前会话的操作结果。
如果开起了自动提交,mysql会把每个sql语句当成一个事务,然后自动的commit。
当然无论开启与否,begin; commit|rollback; 都是独立的事务。Check whether the auto-commit function of the transaction is turned on
show variables like 'autocommit';storage engine
MyISAM tables support 3 different storage formats
1. Static (fixed length) table
Static tables are the default storage format. The fields in the static table are all non-variable fields, so that each record is of fixed length. The advantage of this storage method is that it is stored very quickly, easy to cache, and easy to recover when a failure occurs; the disadvantage is that it usually takes up more space than a dynamic table .
2. Dynamic table
The dynamic table contains variable fields, and the records are not of fixed length. The advantage of such storage is that it occupies less space, but frequent updates and deletions of records will cause fragmentation. It is necessary to regularly execute the OPTIMIZE TABLE statement or the myisamchk -r command to improve performance, and Recovery is relatively difficult in the event of a failure.
3. Compression table
Compressed tables are created by the myisamchk tool and take up very little space because each record is compressed individually, so there is very little access overhead.
common storage engine
InnoDB:
Supports transactions, foreign key constraints, and row-level locking (table-level locking during full table scans),
Read and write concurrency is better. Only version 5.5 supports full-text indexing. Better caching can reduce disk IO pressure. Data and indexes are stored in one file.
Usage scenario: It is suitable for business scenarios with high consistency requirements, frequent data updates, and high concurrent read and write.
MyISAM:
Transactions and foreign key constraints are not supported, only table-level locking is supported.
It is suitable for single query or writing. It has poor read and write concurrency, supports full-text indexing, and occupies less resources. It is suitable for servers with relatively poor hardware resources. Data and indexes are stored separately.
Usage scenarios: Suitable for business scenarios that do not require transaction processing, separate queries, or data insertion.
View the storage engines supported by the system
show engines;

View the storage engine used by the table
方法一
show table status from 库名 where name='表名'\G

方法二
use 库名;
show create table 表名;
Modify the storage engine
method one
方法一
通过 alter table 修改
use 库名;
alter table 表名 engine=MyISAM;
alter table test09 engine=myisam;
show create table test09;

Method Two
方法二:
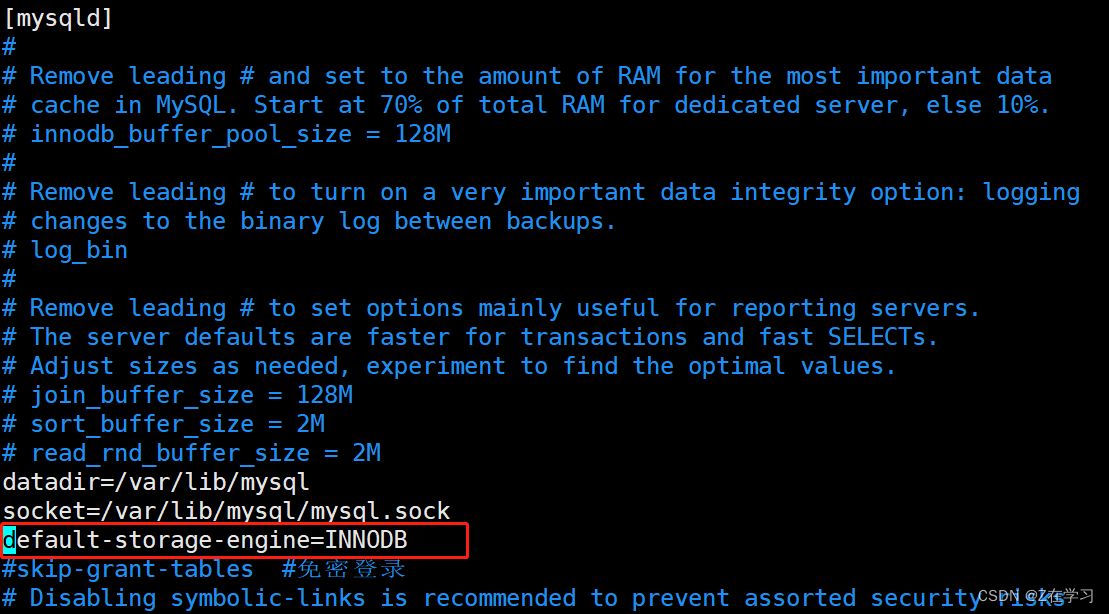
通过修改 /etc/my.cnf 配置文件,指定默认存储引擎并重启服务
vim /etc/my.cnf
......
[mysqld]
......
default-storage-engine=INNODB
systemctl restart mysql.service
Note: This method is only valid for newly created tables after modifying the configuration file and restarting the mysql service, and the existing tables will not be changed.
method three
方法三:
通过 create table 创建表时指定存储引擎
use 库名;
create table 表名(字段1 数据类型,...) engine=MyISAM;
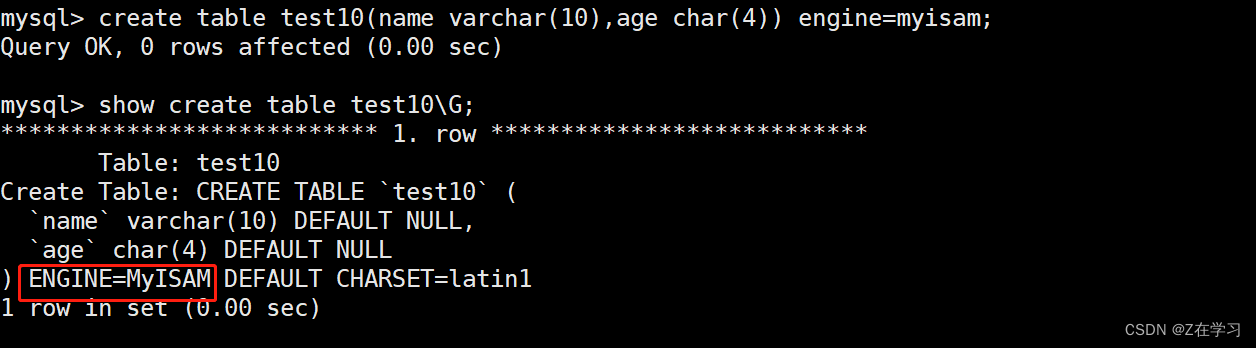
create table test10(name varchar(10),age char(4)) engine=myisam;
show create table test10\G;
The relationship between InnoDB row locks and indexes
one,
delete from test1 where id=1;
If the id field is the primary key, InnoDB uses a clustered index for the primary key, which will directly lock the entire row of records.
two,
delete from test1 where name='aaa';
If the name field is an ordinary index, the two rows of the index will be locked first, and then the record corresponding to the corresponding primary key will be locked.
three,
delete from test1 where age=23;
If the age field is not indexed, full table scan filtering will be used, and each record on the table will be locked.