With the increasing volume of data, people have put forward more requirements on the query performance of Hudi. In addition to the original performance advantages of the Parquet storage format, it is also hoped that Hudi can provide more technical approaches for performance optimization, especially for Hudi. After the table is written in high concurrency and a large number of small files are generated, it is necessary to use Presto/Trino to perform high-throughput ad-hoc query on the Hudi table. How to deal with these small files, that is, make the originally write-optimized Hudi table support read optimization, has become a problem that users who use Hudi need to solve.
| The Amazon cloud technology developer community provides developers with global development technology resources. There are technical documents, development cases, technical columns, training videos, activities and competitions, etc. Help Chinese developers connect with the world's most cutting-edge technologies, ideas, and projects, and recommend outstanding Chinese developers or technologies to the global cloud community. If you haven't paid attention/favorite yet, please don't rush over when you see this, click here to make it your technical treasure house! |
This article will use a practical example to reorganize and rewrite the data files of the Hudi table by using Clustering technology, so as to improve the SQL query performance of the Hudi table.
1. Severe
Hudi brings the core functionality of data warehouses and databases directly into data lakes. Hudi provides tables, transactions, efficient upgrade/delete, advanced indexing, streaming ingestion services, data clustering (Clustering), compression optimization and concurrency, while maintaining data in an open source file format, that is, the data of Hudi tables can be saved In HDFS, Amazon S3 and other file systems.
The reason why Hudi has quickly become popular and accepted by most development users is that it can be easily used on any cloud platform and can be accessed through any popular query engine (including Apache Spark, Flink, Presto, Trino, Hive, etc.) Hudi's data is even more commendable because Hudi's designers have considered as many business scenarios and actual needs as possible.
Starting from the actual business scenario, the requirements for the data lake platform can be divided into two categories: read preference and write preference, so Apache Hudi provides two types of tables:
- Copy On Write table: COW for short, this type of Hudi table uses a column file format (such as Parquet) to store data, if there is data written, it will copy the entire Parquet file, suitable for read-preferred operations
- Merge On Read table: MOR for short, this type of Hudi table uses column file format (such as Parquet) and row file format (such as Avro) to store data together. When data is updated, it is written to row files, and then compressed to generate column files synchronously or asynchronously, which is suitable for write-preferred operations
Subdivided further, Hudi provides different query types for two types of tables:
- Snapshot Queries: Snapshot query, query the latest snapshot of data, that is, all data
- Incremental Queries: Incremental queries, which can query new or modified data within a specified time range
- Read Optimized Queries: read optimized queries, for the MOR table, only query the data in the Parquet file
For the above three query types, read-optimized queries can only be used for MOR tables (actually, it doesn’t make sense to use them for COW, COW only has Parquet files to store data), and the other two query modes can be used for COW tables and MOR tables.
Not only that, Hudi also uses many advanced concepts and technologies in indexing, transaction management, concurrency, compression, etc., which also provides a wide space and more for users who want to tune the performance of Hudi tables The means, such as Index, Metadata Table, Clustering, etc., this article will introduce the technology of Clustering.
2. Hudi Clustering
In a data lake/data warehouse, one of the key tradeoffs is between write speed and query performance. Data writes generally favor small files to increase parallelism and make data available to queries as quickly as possible. However, if there are many small files, the query performance will be poor. Also, during writing, data is usually written to the file at the same location based on arrival time. However, the query engine performs better when frequently queried data is co-located.
This puts forward requirements for Hudi's data reorganization, that is, use small files when writing data, and use large files when querying data.
2.1 Set the Clustering parameters of the Hudi table
In the document [RFC-19], the author created a Hudi table and set the parameters of Clustering, then started the asynchronous Clustering Job, and compared the results. Please note that when creating the Hudi table in this document, call the getQuickstartWriteConfigs method to set the parameter hoodie.upsert.shuffle.parallelism to 2, which is obviously not enough for a test with a large amount of data.
Let's look at a different example. First, generate a set of TPC-DS test data, which specifically includes 24 tables and 99 SQL query statements for performance testing. For the specific steps of generating data, please refer to:
Improving EMR Price/Performance with Amazon Graviton2 | AWS Official Blog
Create an Amazon EMR cluster, version 6.5.0, with the following hardware configuration:

It takes about 30 minutes to use this cluster to generate a set of 100G TPC-DS data.
Amazon EMR provides the Hudi component, and then use the generated TPC-DS data to generate a Hudi table, we select the table store_sales, the script is as follows:
spark-shell --master yarn \
--deploy-mode client \
--conf "spark.serializer=org.apache.spark.serializer.KryoSerializer" \
--conf "spark.sql.hive.convertMetastoreParquet=false" \
--packages org.apache.hudi:hudi-spark3-bundle_2.12:0.10.0
import org.apache.hudi.QuickstartUtils._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import java.util.Date
val tableName = "store_sales"
val basePath = "s3://dalei-demo/hudi/tpcds_hudi_cluster/store_sales"
val partitionKey = "ss_sold_date_sk"
val df = spark.read.format("parquet").
load(s"s3://dalei-demo/tpcds/data10g/store_sales").
filter("ss_sold_time_sk is not null and ss_item_sk is not null and ss_sold_date_sk is not null and ss_customer_sk is not null").
withColumn("ts", lit((new Date()).getTime)).
repartition(1000)
df.write.format("org.apache.hudi").
option(TABLE_NAME, tableName).
option("hoodie.datasource.write.precombine.field", "ts").
option("hoodie.datasource.write.recordkey.field", "ss_sold_time_sk, ss_item_sk").
option("hoodie.datasource.write.partitionpath.field", partitionKey).
option("hoodie.upsert.shuffle.parallelism", "1000").
option("hoodie.datasource.write.table.type", "MERGE_ON_READ").
option("hoodie.datasource.write.operation", "upsert").
option("hoodie.parquet.max.file.size", "10485760").
option("hoodie.datasource.write.hive_style_partitioning", "true").
option("hoodie.datasource.write.keygenerator.class", "org.apache.hudi.keygen.ComplexKeyGenerator").
option("hoodie.datasource.hive_sync.enable", "true").
option("hoodie.datasource.hive_sync.mode", "hms").
option("hoodie.datasource.hive_sync.database", "tpcds_hudi_cluster").
option("hoodie.datasource.hive_sync.table", tableName).
option("hoodie.datasource.hive_sync.partition_fields", partitionKey).
option("hoodie.parquet.small.file.limit", "0").
option("hoodie.clustering.inline", "true").
option("hoodie.clustering.inline.max.commits", "2").
option("hoodie.clustering.plan.strategy.max.num.groups", "10000").
option("hoodie.clustering.plan.strategy.target.file.max.bytes", "1073741824").
option("hoodie.clustering.plan.strategy.small.file.limit", "629145600").
option("hoodie.clustering.plan.strategy.sort.columns", "ss_customer_sk").
mode(Append).
save(basePath);Explain the main parameters used in the above code:
- hoodie.upsert.shuffle.parallelism: the number of parallelism of shuffle during upsert
- hoodie.parquet.max.file.size: Specifies the size of the Parquet file. In order to compare the effect before and after Clustering, we hope to generate a large number of small files, so the file size is limited here.
- hoodie.datasource.write.keygenerator.class: If it is a composite primary key, you need to specify the value of this parameter as org.apache.hudi.keygen.ComplexKeyGenerator
- hoodie.datasource.hive_sync.*: These parameters are to synchronize the Schema information of the Hudi table to the Hive MetaStore
- hoodie.parquet.small.file.limit: If it is smaller than the specified value, it will be regarded as a small file. When Upsert, the small file will be replaced with a large file (the so-called "extension") instead of generating a new file. The value is set to 0, that is, the small file limit is turned off, so that a new file will be generated every time data is written
- hoodie.clustering.inline: Enable synchronous Clustering, that is, once the number of Commits is reached, Clustering will be executed immediately
- hoodie.clustering.inline.max.commits: After how many Commits, start to execute Clustering
- hoodie.clustering.plan.strategy.max.num.groups: How many File Groups will be generated by Clustering, default 30
- hoodie.clustering.plan.strategy.target.file.max.bytes: file size limit after Clustering
- hoodie.clustering.plan.strategy.small.file.limit: Files smaller than this value will be Clustered
- hoodie.clustering.plan.strategy.sort.columns: When Clustering, use this field to sort
Parameters can use constants defined in org.apache.hudi.DataSourceWriteOptions (such as TABLE_NAME), or directly use strings (such as "hoodie.datasource.write.table.name"), the effect is the same.
2.2 Trigger Clustering
The previous operation just created the Hudi table and configured Clustering. Since the number of Commits was less than 2 (please pay attention to the configuration parameters, the previous Upsert was 1 Commit), so Clustering has not been triggered. You can first understand Commit as one Upsert operation.
Let's simulate the Commit operation again, modify a certain field of a partition of the store_sales table, and then upload it to the table, the code is as follows:
val df1 = spark.read.format("hudi").option("hoodie.datasource.query.type", "read_optimized").
load("s3://dalei-demo/hudi/tpcds_hudi_cluster/store_sales").
filter("ss_sold_date_sk=2450816").
drop(col("_hoodie_commit_seqno")).drop(col("_hoodie_commit_time")).
drop(col("_hoodie_record_key")).drop(col("_hoodie_partition_path")).
drop(col("_hoodie_file_name"))
val df2 = df1.withColumn("ss_ext_tax", col("ss_ext_tax") + lit(1.0))
df2.write.format("org.apache.hudi").
option(TABLE_NAME, tableName).
option("hoodie.datasource.write.precombine.field", "ts").
option("hoodie.datasource.write.recordkey.field", "ss_sold_time_sk, ss_item_sk").
option("hoodie.datasource.write.partitionpath.field", partitionKey).
option("hoodie.upsert.shuffle.parallelism", "1000").
option("hoodie.datasource.write.table.type", "MERGE_ON_READ").
option("hoodie.datasource.write.operation", "upsert").
option("hoodie.parquet.max.file.size", "10485760").
option("hoodie.datasource.write.hive_style_partitioning", "true").
option("hoodie.datasource.write.keygenerator.class", "org.apache.hudi.keygen.ComplexKeyGenerator").
option("hoodie.datasource.hive_sync.enable", "true").
option("hoodie.datasource.hive_sync.mode", "hms").
option("hoodie.datasource.hive_sync.database", "tpcds_hudi_cluster").
option("hoodie.datasource.hive_sync.table", tableName).
option("hoodie.datasource.hive_sync.partition_fields", partitionKey).
option("hoodie.parquet.small.file.limit", "0").
option("hoodie.clustering.inline", "true").
option("hoodie.clustering.inline.max.commits", "2").
option("hoodie.clustering.plan.strategy.max.num.groups", "10000").
option("hoodie.clustering.plan.strategy.target.file.max.bytes", "1073741824").
option("hoodie.clustering.plan.strategy.small.file.limit", "629145600").
option("hoodie.clustering.plan.strategy.sort.columns", "ss_customer_sk").
mode(Append).
save(basePath);After the code is executed, the number of Commits reaches 2 times, and Clustering has been executed in the background.
2.3 Explain the Clustering operation process
Before explaining Clustering, first introduce the composition of the operation file of the Hudi table.
2.3.1 Operation file of Hudi table
Taking the store_sales table generated earlier as an example, the operation records of this table are contained in the .hoodie directory, as shown in the following figure:
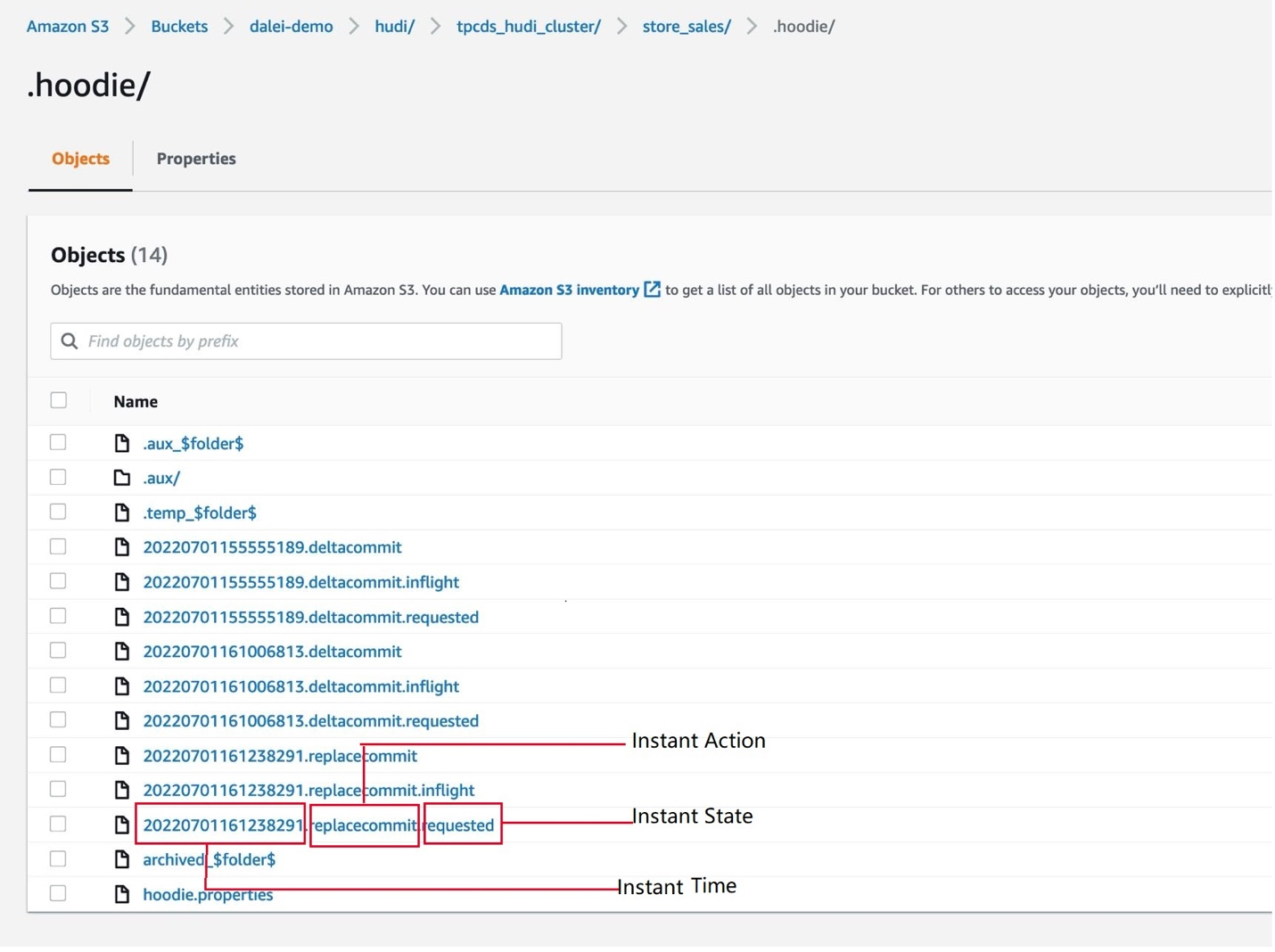
Figure 1: Operation file for Hudi table
The file name of the Hudi operation usually consists of three parts:
- Instant Time: The time of operation, a 17-digit timestamp (8-digit date + 9-digit time, accurate to milliseconds)
- Instant Action: The type of operation. When the front end executes Upsert, the type of operation that will be generated is deltacommit; the type of operation that will be generated by Clustering is replacecommit
- Instant State: The status of the operation, requested means the request, inflight means it is in progress, and the status is empty means the execution has been completed
You can download the Clustering request file 20220701161238291.replacecommit.requested because it is in Avro format. Use avro-tools to view its content:
[ec2-user@cm ~]$ aws s3 cp s3://dalei-demo/hudi/tpcds_hudi_cluster/store_sales/.hoodie/20220701161238291.replacecommit.requested ./
[ec2-user@cm ~]$ wget http://archive.apache.org/dist/avro/avro-1.9.2/java/avro-tools-1.9.2.jar
[ec2-user@cm ~]$ java -jar avro-tools-1.9.2.jar tojson 20220701161238291.replacecommit.requested >> 20220701161238291.replacecommit.requested.jsonYou can use a browser to open the file, as shown below:
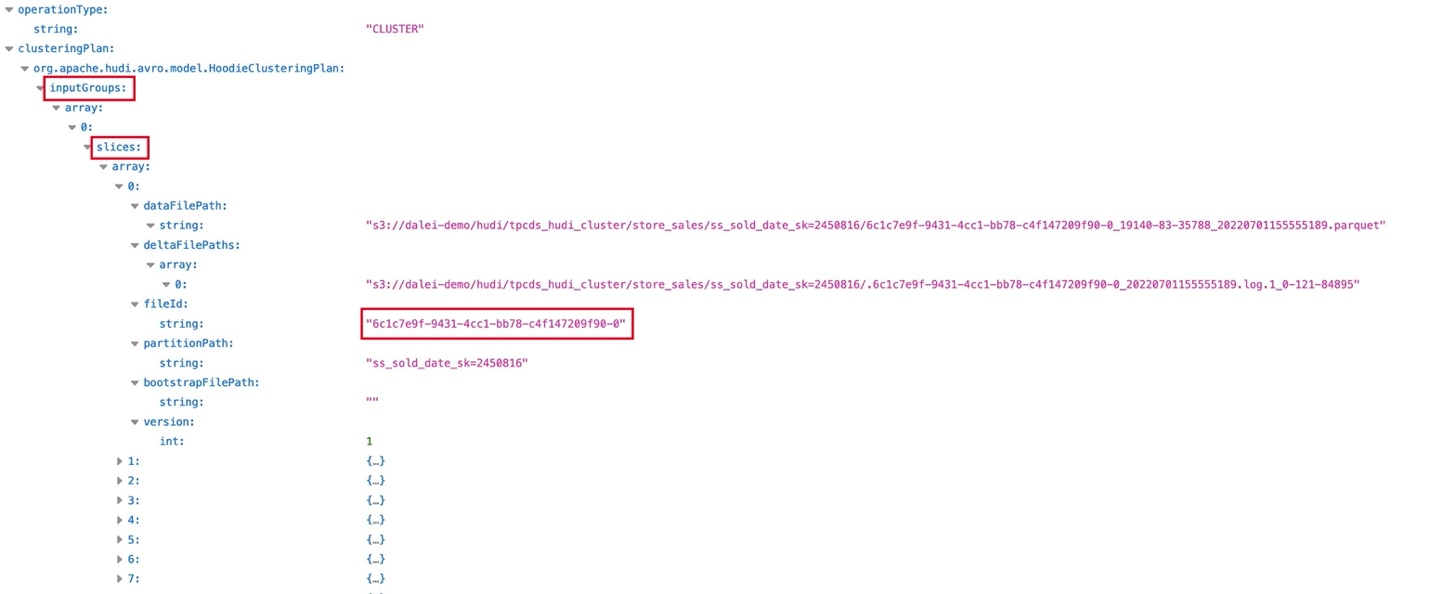
Figure 2: Clustering request file
The inputGroups in the figure above are File Groups, slices are File Slices, and File IDs. These three concepts will be introduced in 2.3.2. This file is a request to initiate a Clustering operation. These files are used as input to generate Larger files to replace them, the generated files will also be introduced in 2.3.2.
The size of the 20220701161238291.replacecommit.inflight file is 0, indicating that the Clustering has been completed immediately. Let’s look at the 20220701161238291.replacecommit file. It is a file in json format and can be opened directly. The content is as follows:
{
"partitionToWriteStats" : {
"ss_sold_date_sk=2451080" : [ {
"fileId" : "91377ca5-48a9-491a-9c82-56a1ba4ba2e3-0",
"path" : "ss_sold_date_sk=2451080/91377ca5-48a9-491a-9c82-56a1ba4ba2e3-0_263-1967-116065_20220701161238291.parquet",
"prevCommit" : "null",
"numWrites" : 191119,
"numDeletes" : 0,
"numUpdateWrites" : 0,
"numInserts" : 191119,
"totalWriteBytes" : 11033199,
"totalWriteErrors" : 0,
"tempPath" : null,
"partitionPath" : "ss_sold_date_sk=2451080",
"totalLogRecords" : 0,
"totalLogFilesCompacted" : 0,
"totalLogSizeCompacted" : 0,
"totalUpdatedRecordsCompacted" : 0,
"totalLogBlocks" : 0,
"totalCorruptLogBlock" : 0,
"totalRollbackBlocks" : 0,
"fileSizeInBytes" : 11033199,
"minEventTime" : null,
"maxEventTime" : null
} ],
......
},
"compacted" : false,
"extraMetadata" : {
"schema" : "{\"type\":\"record\",\"name\":\"store_sales_record\",\"namespace\":\"hoodie.store_sales\",\"fields\":[{\"name\":\"ss_sold_time_sk\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"ss_item_sk\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"ss_customer_sk\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"ss_cdemo_sk\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"ss_hdemo_sk\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"ss_addr_sk\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"ss_store_sk\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"ss_promo_sk\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"ss_ticket_number\",\"type\":[\"null\",\"long\"],\"default\":null},{\"name\":\"ss_quantity\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"ss_wholesale_cost\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ss_list_price\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ss_sales_price\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ss_ext_discount_amt\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ss_ext_sales_price\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ss_ext_wholesale_cost\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ss_ext_list_price\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ss_ext_tax\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ss_coupon_amt\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ss_net_paid\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ss_net_paid_inc_tax\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ss_net_profit\",\"type\":[\"null\",\"double\"],\"default\":null},{\"name\":\"ts\",\"type\":\"long\"},{\"name\":\"ss_sold_date_sk\",\"type\":[\"null\",\"int\"],\"default\":null}]}"
},
"operationType" : "CLUSTER",
"partitionToReplaceFileIds" : {
"ss_sold_date_sk=2451080" : [ "2e2bec06-78fb-4059-ad89-2914f63dd1c0-0", "63fc2a2d-73e6-4261-ab30-ff44912e1696-0", "fc5fd42e-0f3f-434c-aa56-ca43c36c659d-0", "41299b3d-0be9-4338-bbad-6feeb41d4975-0", "c23873a1-03a3-424a-aa9c-044b40f1659f-0", "8af23590-4b8c-4b44-946e-0fdd73747e19-0", "7d740b43-83ca-48ca-a9dc-6b8e19fce6f0-0", "bc90dfd5-7323-4786-832c-4a6516332adf-0", "67abd081-dfcc-45d9-8f29-50a4fb71108c-0", "80bffa2b-df05-4c9f-9766-84a700403a89-0", "cbba9f2a-32cd-4c73-a38b-570cbb5501e4-0", "ea59e1a4-1f97-40e8-baae-3bedc5752095-0", "55cffcb6-5410-4c2a-a61d-01300be50171-0", "601b74b3-663d-4ef8-bf5e-158f135f81ea-0", "c46e8539-418e-482d-936e-a79464d869ac-0", "3dbe1997-bfc2-41a7-ac12-f302d3013c87-0", "acf9be44-71a3-436f-b595-c0f322f34172-0", "d7bbe517-87c7-482c-b885-a16164062b81-0", "f1060ef7-ba7c-4b8e-abc3-c409cd6af7d4-0" ],
......
},
"writePartitionPaths" : [ "ss_sold_date_sk=2451080", ......],
"fileIdAndRelativePaths" : {
"742c6044-4f76-4d04-993c-d4255235d484-0" : "ss_sold_date_sk=2451329/742c6044-4f76-4d04-993c-d4255235d484-0_511-1967-116236_20220701161238291.parquet",
"20dafb58-8ae7-41d6-a02d-2b529bcdcc83-0" : "ss_sold_date_sk=2452226/20dafb58-8ae7-41d6-a02d-2b529bcdcc83-0_1407-1967-116870_20220701161238291.parquet",
......
},
"totalRecordsDeleted" : 0,
"totalLogRecordsCompacted" : 0,
"totalLogFilesCompacted" : 0,
"totalCompactedRecordsUpdated" : 0,
"totalLogFilesSize" : 0,
"totalScanTime" : 0,
"totalCreateTime" : 151847,
"totalUpsertTime" : 0,
"minAndMaxEventTime" : {
"Optional.empty" : {
"val" : null,
"present" : false
}
}
}A lot of repetitive content is omitted above, the main information is as follows:
- partitionToWriteStats: List the partitions to be Clustered and the information of the files to be Clustered
- extraMetadata: Hudi 表的 Schema
- operationType: Indicates that the operation type is Clustering
- partitionToReplaceFileIds: List the partitions and file IDs to be clustered
- fileIdAndRelativePaths: New files generated by Clustering, please note that the timestamp of the file name
2.3.2 Data file of Hudi table
Next, introduce the composition of the data file of the Hudi table, taking the MOR type table as an example, as shown in the following figure:
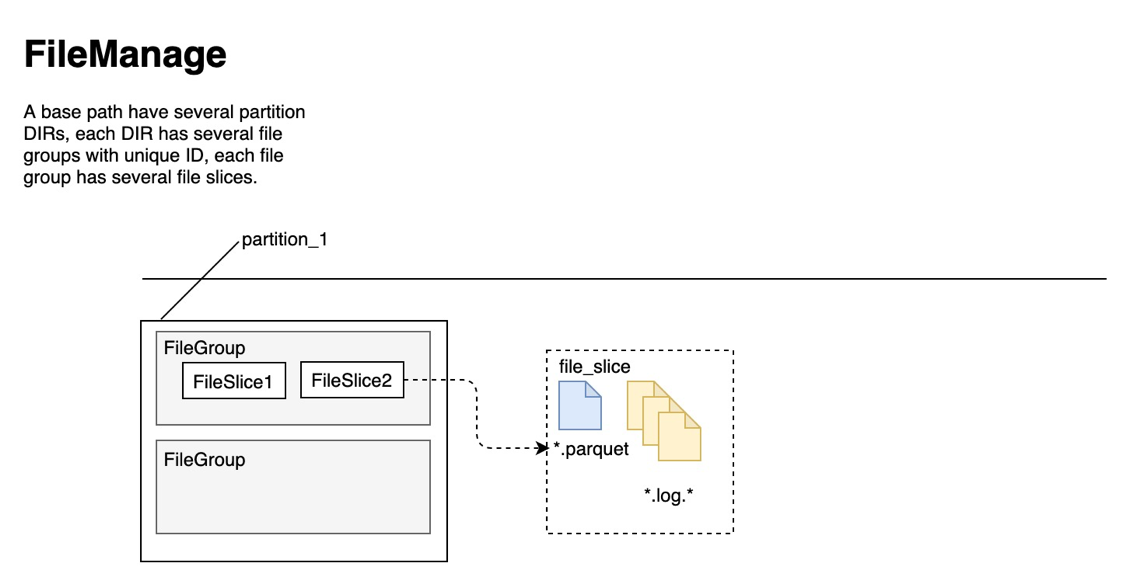
Figure 3: File structure of the MOR table
It can be seen that the hierarchy and inclusion relationship of files is: Partition -> File Group -> File Slice -> Parquet + Log, where:
- Partition: partition, everyone is familiar with it, some tables may not have Partition
- File Group: Used to control the file version, there is a unique File ID in the same File Group
- File Slice: Used to organize file data. In the same File Slice, not only the File ID but also the Instant Time must be the same
- The Parquet file is a column storage format file, and the Log file is a row storage file format. The default value is Apache Avro, which records the modification of the Parquet file in the same File Slice.
Let's look at an example of a File Group:

Figure 4: Example of FileGroup
In Figure 4, the File ID of the first file and the second file are the same, indicating that they are the same File Group, but the Instant Time is different, indicating that they are not the same File Slice. When querying data using the read-optimized method, it will read Take Instant Time's larger Parquet file.
Look at the data file of the store_sales table, as shown below:
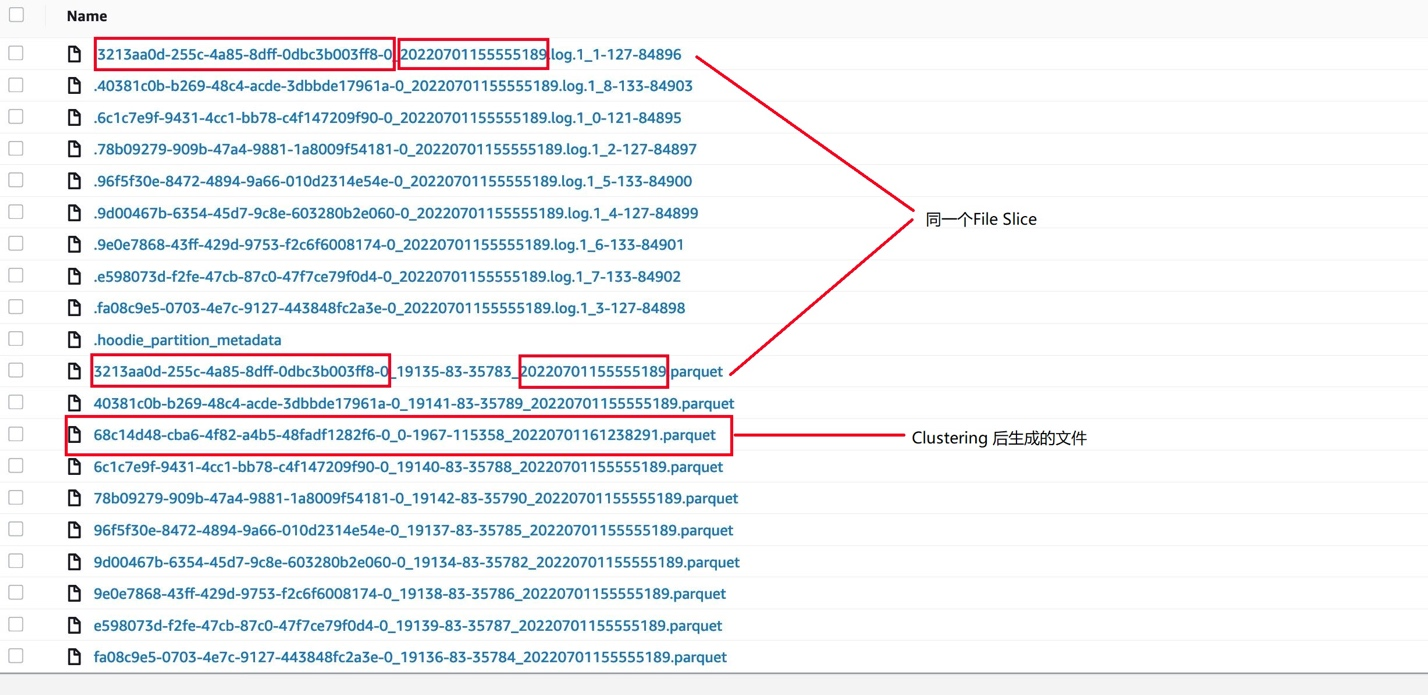
Figure 5: Data file for the store_sales table
In Figure 5, the marked Log file and Parquet file have the same File ID and Instant Time, indicating that the Log file is generated after an Upsert based on the Parquet file, and they belong to the same File Slice. If it is a Snapshot query , it is necessary to read the Log file of the same File Slice and the Parquet data together.
In Figure 5, the "68c14d48-cba6-4f82-a4b5-48fadf1282f6-0_0-1967-115358_20220701161238291.parquet" file is the file generated by clustering. You can download it and use parquet-tool to view its data, as follows:
[ec2-user@cm ~]$ wget http://logservice-resource.oss-cn-shanghai.aliyuncs.com/tools/parquet-tools-1.6.0rc3-SNAPSHOT.jar
[ec2-user@cm ~]$ aws s3 cp s3://dalei-demo/hudi/tpcds_hudi_cluster/store_sales/ss_sold_date_sk=2450816/68c14d48-cba6-4f82-a4b5-48fadf1282f6-0_0-1967-115358_20220701161238291.parquet ./
[ec2-user@cm ~]$ java -jar ./parquet-tools-1.6.0rc3-SNAPSHOT.jar head -n 10 68c14d48-cba6-4f82-a4b5-48fadf1282f6-0_0-1967-115358_20220701161238291.parquetThe above command shows the data of 10 Parquet files after Clustering. Pay attention to the value of Sort Column (ss_customer_sk), which is already sorted.
Comparing the files before and after Clustering, it can be seen that the original data saved with 10 Parquet files of about 1M is only one Parquet file of 5.1M after Clustering. As for saving the same number of data, why the total capacity of the file drops so much, please refer to the relevant knowledge of Parquet: Apache Parquet .
2.3.3 Clustering of multi-partition tables
By default, Hudi uses the parameter hoodie.clustering.plan.strategy.max.num.groups (the default value is 30) for workload considerations, and specifies that Clustering will only create 30 File Groups. (According to the document Size setting, currently each partition only needs to create 1 File Group)
If there are many partitions, you can use the hoodie.clustering.plan.partition.filter.mode parameter to plan the partition range of Clustering. For details, please refer to: [ All Configurations | Apache Hudi .]( All Configurations | Apache Hudi .)
3. Use Trino to query data
3.1 Prepare other tables
The data of the store_sales table is ready. Similarly, we can also generate four tables customer_address, customer, date_dim, and item, which are all tables used for test queries. These four tables are all dimension tables, and the changes will not be very frequent, so they all generate COW tables, and the code for generating customer_address tables is as follows:
val tableName = "customer_address"
val basePath = "s3://dalei-demo/hudi/tpcds_hudi_cluster/customer_address"
val df = spark.read.format("parquet").
load(s"s3://dalei-demo/tpcds/data10g/customer_address").
filter("ca_address_sk is not null")
df.write.format("org.apache.hudi").
option(TABLE_NAME, tableName).
option("hoodie.datasource.write.precombine.field", "ca_address_id").
option("hoodie.datasource.write.recordkey.field", "ca_address_sk").
option("hoodie.upsert.shuffle.parallelism", "100").
option("hoodie.datasource.write.table.type", "COPY_ON_WRITE").
option("hoodie.datasource.write.operation", "upsert").
option("hoodie.parquet.max.file.size", "10485760").
option("hoodie.datasource.hive_sync.enable", "true").
option("hoodie.datasource.hive_sync.mode", "hms").
option("hoodie.datasource.hive_sync.database", "tpcds_hudi_cluster").
option("hoodie.datasource.hive_sync.table", tableName).
option("hoodie.parquet.small.file.limit", "0").
option("hoodie.clustering.inline", "true").
option("hoodie.clustering.inline.max.commits", "2").
option("hoodie.clustering.plan.strategy.target.file.max.bytes", "1073741824").
option("hoodie.clustering.plan.strategy.small.file.limit", "629145600").
option("hoodie.clustering.plan.strategy.sort.columns", "").
mode(Append).
save(basePath);The code that triggers Clustering is as follows:
val df1 = spark.read.format("hudi").option("hoodie.datasource.query.type", "read_optimized").
load("s3://dalei-demo/hudi/tpcds_hudi_cluster/customer_address")
val df2 = df1.withColumn("ca_gmt_offset", col("ca_gmt_offset") + lit(1.1))
df2.write.format("org.apache.hudi").
option(TABLE_NAME, tableName).
option("hoodie.datasource.write.precombine.field", "ca_address_id").
option("hoodie.datasource.write.recordkey.field", "ca_address_sk").
option("hoodie.upsert.shuffle.parallelism", "100").
option("hoodie.datasource.write.table.type", "COPY_ON_WRITE").
option("hoodie.datasource.write.operation", "upsert").
option("hoodie.parquet.max.file.size", "10485760").
option("hoodie.datasource.hive_sync.enable", "true").
option("hoodie.datasource.hive_sync.mode", "hms").
option("hoodie.datasource.hive_sync.database", "tpcds_hudi_cluster").
option("hoodie.datasource.hive_sync.table", tableName).
option("hoodie.parquet.small.file.limit", "0").
option("hoodie.clustering.inline", "true").
option("hoodie.clustering.inline.max.commits", "2").
option("hoodie.clustering.plan.strategy.target.file.max.bytes", "1073741824").
option("hoodie.clustering.plan.strategy.small.file.limit", "629145600").
option("hoodie.clustering.plan.strategy.sort.columns", "").
mode(Append).
save(basePath);The generation statements of the other three tables are similar to the customer_address table, you can try to generate them.
For comparison, we also need to generate a set of tables with the same name that do not use Clustering. These two sets of tables can be placed in different Hive Databases, such as tpcds_hudi_cluster and pcds_hudi_nocluster. Generating scripts without Clustering tables is similar to generating Clustering tables The script of is similar, just remove the parameters related to Clustering.
3.2 Query
Trino360 is provided in Amazon EMR 6.5.0, and we use it to test the SQL query performance of the Hudi table. The startup command is as follows: /usr/lib/trino/bin/trino-cli-360-executable –server localhost:8889 –catalog hive –schema tpcds_hudi_cluster
If the TPC-DS test data is generated according to 2.1, you will see the query statement generated together for testing. We use q6.sql to test. The script is as follows:
--q6.sql--
SELECT state, cnt FROM (
SELECT a.ca_state state, count(*) cnt
FROM
customer_address a, customer c, store_sales_ro s, date_dim d, item i
WHERE a.ca_address_sk = c.c_current_addr_sk
AND c.c_customer_sk = s.ss_customer_sk
AND s.ss_sold_date_sk = d.d_date_sk
AND s.ss_item_sk = i.i_item_sk
AND d.d_month_seq =
(SELECT distinct (d_month_seq) FROM date_dim
WHERE d_year = 2001 AND d_moy = 1)
AND i.i_current_price > 1.2 *
(SELECT avg(j.i_current_price) FROM item j
WHERE j.i_category = i.i_category)
GROUP BY a.ca_state
) x
WHERE cnt >= 10
ORDER BY cnt LIMIT 100The query for the Hudi table without Clustering is as follows:
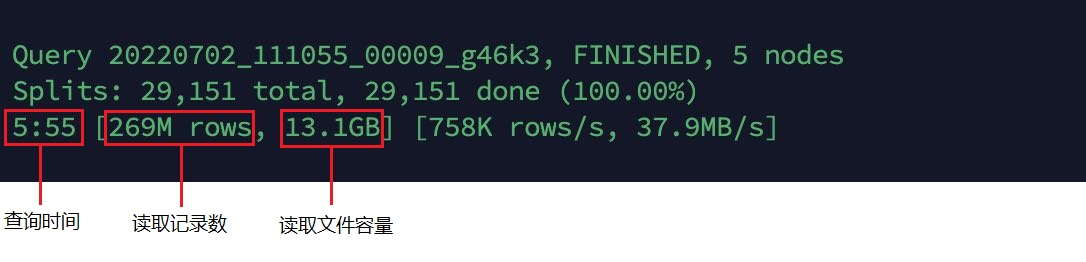
Figure 6: Queries for Hudi tables without Clustering
The query for the Hudi table using Clustering is as follows:
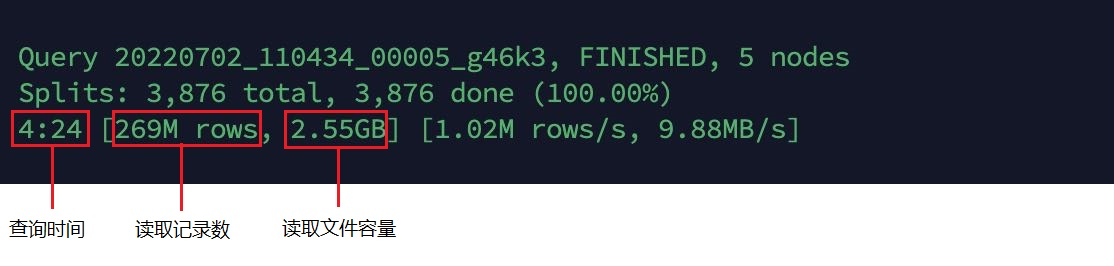
Figure 7: Hudi table query using Clustering
It can be seen that the query performance of the Hudi table using Clustering is improved by 35.4% compared with the Hudi table without Clustering, the number of read records is the same, and the capacity of the read file is greatly reduced.
4. Some suggestions for using Clustering
4.1 Impact on Upsert
When executing Clustering, the Snapshot Isolation level isolation is implemented for the File Group, so their modification is not allowed. That is to say, if there are Upsert and Compaction operations (MOR table), they must wait until the end of Clustering
4.2 Load considerations
If the amount of table data required for Clustering is relatively large, and if there are many partitions, performing Clustering once will also generate a large amount of load. Therefore, Hudi provides a variety of options for the scope of Clustering. For tables that require both high-concurrency writing and high-throughput reading, Clustering can be performed during the trough period of high-concurrency writing, such as at night
4.3 Synchronous or asynchronous
udi provides two Clustering methods, synchronous and asynchronous. It is not recommended to use synchronous clustering when writing to Hudi tables with high concurrency. You can refer to the method in [RFC-19] and use commands to perform asynchronous clustering.
4.4 Whether to choose Sort Column
If some fields are often used for Join, and the value of this field can be guaranteed to be non-empty, it can be placed in Sort Column. If there are multiple files after Clustering, Sort Column helps to confirm each The range of this field in the file can avoid excessive file reading and improve the performance of the Join operation. The principle is somewhat similar to Hive Clustering, please refer to: Bucketing in Hive: Create Bucketed Table in Hive | upGrad blog .
Friends who are interested can compare the difference in Join query performance between choosing Sort Column or not.
4.5 Is Clustering the same as large files?
Some people will say that Clustering is to merge small files into large files. When creating a Hudi table, can I just select the large file? If you only consider read performance, it is indeed possible to do so. However, Clustering provides more options. Clustering is very suitable for tables that sometimes have high-concurrency writing (suitable for small files) and sometimes high-throughput reading (suitable for large files).
4.6 Incremental query
Under the current Hudi version 0.10, Clustering does not support incremental queries very well. The data after Clustering will be considered as "new" data and will also appear in the results of incremental queries, which is not what we expected. Because no changes have been made to the data, it is considered as incremental data if it is just rewritten from a small file to a large file. Therefore, it is not recommended to use Clustering for tables that rely on incremental queries.
4.7 When to specify Clustering?
You can specify the relevant configuration of Clustering whenever Clustering is required, not only when creating a Hudi table. That is to say, for any Hudi table, if a large number of small files are found, if other conditions are met ( No high concurrent writing, no dependence on incremental query, etc.), you can specify Clustering at any time.
reference documents
Improving EMR Price/Performance with Amazon Graviton2 | AWS Official Blog
RFC - 19 Clustering data for freshness and query performance - HUDI - Apache Software Foundation
Badass - Amazon EMR
Bucketing in Hive: Create Bucketed Table in Hive | upGrad blog
The author of this article

Dalei Xu
Amazon data analysis product technical expert, responsible for consulting and architectural design of Amazon data analysis solutions. He has been engaged in front-line development for many years and has accumulated rich experience in data development, architecture design, performance optimization and component management. He hopes to promote Amazon's excellent service components to more enterprise users and achieve win-win and common growth with customers.
Article source: https://dev.amazoncloud.cn/column/article/6309c8e20c9a20404da79150?sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN