Article directory
Disclaimer :
(1) This article was originally organized by blogger Minnie_Vautrin , and uploaded after I overhauled it.
(2) There are many references and resources in this article, some of which cannot be traced to the source, if there is any infringement, please contact for deletion.
First, the purpose
- Increase the resolution of the image;
- Rich image detail texture.

2. Research Background
- Intelligent display field : The resolution of images captured by ordinary cameras is generally low, which cannot meet the visual requirements of high resolution. At present, 4K high-definition display is gradually becoming popular, but the pixel resolution of pictures taken by many imaging devices and old movies is far lower than 4K.
- In the field of medical imaging : the resolution of images collected by medical instruments is usually low, and high-resolution medical images are conducive to the discovery of tiny lesions.
- In the field of remote sensing imaging : the distance between the satellite or aircraft and the imaging object is relatively long during remote sensing imaging, and is limited by the sensor technology and the cost of imaging equipment. for analysis.
- In the field of urban video surveillance : limited by cost and other factors, the cameras of public surveillance systems are often low-resolution, and low-resolution pictures or videos are not conducive to subsequent tasks such as face recognition, license plate recognition, and target structural feature recognition.
- Image compression transmission field : In order to reduce the pressure of massive data on the transmission bandwidth, image or video data will be compressed during transmission, such as reducing the resolution of the image. However, people have high requirements for the clarity of these images or videos, so image super-resolution technology needs to be used at the receiving end to increase the resolution and reconstruct the original high-definition images or videos as much as possible.
3. Existing problems
- Estimation of the degradation model : The biggest challenge in practically solving the image super-resolution reconstruction problem is the accurate estimation of the degradation model. Estimating the degradation model is to estimate the motion information, blur information and noise information of the image from the low-resolution image while performing super-resolution reconstruction on the image. In reality, estimating degradation models only from low-resolution images is difficult due to lack of data. Previously, most scholars focused their research on how to design an accurate image prior, while ignoring the impact of the degradation model on the results. Although many methods have achieved good reconstruction results, the performance on natural images is not satisfactory. This is because the degradation model of natural images does not match the model assumed in the algorithm. This is why the existing mature The main reason why the algorithm cannot be generalized.
- Computational complexity and stability : The factors that restrict the wide application of image super-resolution reconstruction algorithms are the computational complexity and stability of the algorithm. Existing algorithms basically improve the quality of reconstruction results by sacrificing computational costs, especially when the magnification is large, the calculation amount increases by a square factor, which leads to very time-consuming image super-resolution processing, thus lacking the value of practical applications. Recently, some scholars have focused on how to achieve image super-resolution reconstruction quickly and well. Although, existing practices are able to reconstruct high-quality images, when the input image does not meet the model assumed by the algorithm, it will produce wrong details. Especially when the learning dataset is incomplete, the learning-based methods only rely on the generalization ability of the learning model to predict the missing high-frequency details due to lack of knowledge, and the introduction of wrong details is inevitable. Therefore, the existing image super-resolution reconstruction algorithms so far do not have strong stability.
- Compression degradation and quantization error : In existing image super-resolution reconstruction algorithms, image compression degradation is often ignored. In fact, consumer-grade cameras require image compression in the final output step. In addition, due to the limitations of transmission conditions and storage space, images appearing on the Internet are also compressed. The impact of image compression on the super-resolution reconstruction problem is to change the image degradation model, and the image degradation model plays a very important role in super-resolution reconstruction. For example, noise, when the image is compressed, the noise in the degraded image not only has additive noise, but also multiplicative noise related to the image content. In addition, most of the super-resolution reconstruction work is based on continuous imaging models, and does not consider the factors of digital quantization. However, the actual processed images are all digital, and quantization errors are inevitably introduced in the quantization process. This error will in turn affect the degradation model of the image.
- Objective evaluation indicators : At present, the most commonly used objective evaluation indicators for evaluating super-resolution reconstruction are peak signal-to-noise ratio (Peak Signal Noise Ratio, PSNR), mean square error (Mean Square Error, MSE) and structural similarity (Structural SIMilarity, SSIM ). These indicators need to use real high-resolution images as a reference to evaluate the similarity between the reconstructed image and the real image. The higher the similarity, the better the reconstruction result, and vice versa. However, these evaluation indicators cannot fully reflect the quality of the reconstruction effect. When doing experimental comparisons, it is often encountered that the subjective evaluation of the reconstructed image is high and the objective evaluation is low. In addition, when performing super-resolution reconstruction of natural images, it is difficult to obtain real reference images, and these evaluation indicators lose their role in such situations. Therefore, it is meaningful to study an objective image evaluation index that does not require reference images and is consistent with subjective evaluation.
4. Research status
- Based on interpolation: Common interpolation methods include nearest neighbor interpolation, bilinear interpolation, and bicubic interpolation. Although these methods are simple and effective, they all assume that the image is continuous and do not introduce more effective information. Often the edges and outlines of the reconstruction results are blurred, the texture restoration effect is not good, and the performance is very limited.
- Based on reconstruction: This type of method regards image super-resolution reconstruction as a problem of optimizing reconstruction error, and obtains a local optimal solution by introducing prior knowledge. Common reconstruction-based algorithms include Projection onto Convex Set (POCS), Maximum A Posterior probability (Maximum A Posterior estimation, MAP), Bayesian Analysis (BA), iterative back-projection (Iterative Back Projection, IBP) and so on. Although such methods add constraints to the image super-resolution reconstruction process by introducing prior information, and then obtain good reconstruction results. However, there are obvious problems such as unsatisfactory convergence in these algorithms.
- Based on learning: Convolutional Neural Network (CNN) has been widely used in image super-resolution reconstruction research due to its excellent detail representation ability, and Transformer has also achieved success in the field of image super-resolution. It can implicitly learn the prior knowledge of the image, and use the learned prior knowledge to generate better super-resolution images. Classic methods of this type include SRCNN, ESPCN, VDSR, DRCN, DRRN, EDSR, SRGAN, ESRGAN, RDN, WDSR, LapSRN, RCAN, SAN, IGNN, SwinIR, etc. Learning-based image super-resolution reconstruction algorithms have achieved far superior advantages over traditional algorithms in reconstruction results, but due to the high requirements for hardware equipment and processing time, few of these algorithms have been practically applied.
5. Summary of innovation points and core codes of each algorithm
SRCNN
Paper : https://arxiv.org/abs/1501.00092
Code :
MatLab http://mmlab.ie.cuhk.edu.hk/projects/SRCNN.html
TensorFlow https://github.com/tegg89/SRCNN-Tensorflow
Pytorch https://github.com/fuyongXu/SRCNN_Pytorch_1.0
Keras https://github.com/jiantenggei/SRCNN-Keras

- Innovation point : The pioneering work of image super-resolution reconstruction based on deep learning. For a low-resolution image, first use bicubic interpolation (bicubic) method to transform it to the size of the real high-resolution image. The interpolated image is used as the input of the convolutional neural network, and finally a reconstructed high-resolution image is obtained.
- Subjective effect : Compared with traditional methods, the reconstructed image quality of SRCNN is higher.
- Disadvantages : (1) rely on image region information; (2) the training convergence speed is too slow; (3) the network is only suitable for single-scale input.
- Core code :
import torch.nn as nn
class SRCNN(nn.Module):
def __init__(self, inputChannel, outputChannel):
super(SRCNN, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(inputChannel, 64, kernel_size=9, padding=9 // 2),
nn.ReLU(inplace=True),
nn.Conv2d(64, 32, kernel_size=1),
nn.ReLU(inplace=True),
nn.Conv2d(32, outputChannel, kernel_size=5, padding=5 // 2),
)
def forward(self, x):
out = self.conv(x)
return out
ESPCN
Paper : https://arxiv.org/abs/1609.05158
Code :
MatLab https://github.com/wangxuewen99/Super-Resolution/tree/master/ESPCN
TensorFlow https://github.com/drakelevy/ESPCN-TensorFlow
Pytorch https://github.com/leftthomas/ESPCN

- Innovation point : Sub-pixel convolution is used directly at the end for upsampling.
- Benefits : (1) Upsampling is only performed at the end of the model, allowing more texture areas to be preserved in low-resolution space, and it can also be achieved in real-time in video super-resolution. (2) At the end of the module, sub-pixel convolution is directly used for upsampling. Compared with interpolating low scores to high scores as shown, this upsampling method can obtain better reconstruction results.
- Insufficient : only considering the problem of upsampling, there is not much research on how to learn and utilize richer feature information.
- Others : Sub-pixel convolution does not actually involve convolution operations. It is an efficient, fast, and parameter-free upsampling method for pixel rearrangement. Due to the high processing speed, it can be directly used in video super-resolution in real time. Therefore, this upsampling method has often become the first choice for upsampling, and is often used in the field of low-level computer vision.
- Core code :
import math
import torch
from torch import nn
class ESPCN(nn.Module):
def __init__(self, scale_factor, num_channels=1):
super(ESPCN, self).__init__()
self.first_part = nn.Sequential(
nn.Conv2d(num_channels, 64, kernel_size=5, padding=5//2),
nn.Tanh(),
nn.Conv2d(64, 32, kernel_size=3, padding=3//2),
nn.Tanh(),
)
self.last_part = nn.Sequential(
nn.Conv2d(32, num_channels * (scale_factor ** 2), kernel_size=3, padding=3 // 2),
nn.PixelShuffle(scale_factor)
)
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
if m.in_channels == 32:
nn.init.normal_(m.weight.data, mean=0.0, std=0.001)
nn.init.zeros_(m.bias.data)
else:
nn.init.normal_(m.weight.data, mean=0.0, std=math.sqrt(2/(m.out_channels*m.weight.data[0][0].numel())))
nn.init.zeros_(m.bias.data)
def forward(self, x):
x = self.first_part(x)
x = self.last_part(x)
return x
VDSR
Paper : https://arxiv.org/abs/1511.04587
Code :
MatLab (1) https://cv.snu.ac.kr/research/VDSR/ (2) https://github.com/huangzehao/caffe- vdsr
TensorFlow https://github.com/Jongchan/tensorflow-vdsr
Pytorch https://github.com/twtygqyy/pytorch-vdsr

- Innovation points : (1) Use a sufficiently deep neural network; (2) Introduce residual learning; (3) Higher learning rate; (4) Propose a multi-scale super-resolution model.
- Benefits : (1) VDSR deepens the network depth and makes the network receptive field larger, which makes better use of the context information of a larger area. (2) Residual learning accelerates network convergence, and at the same time fuses high-level and low-level feature information; (3) Higher learning rates can accelerate network convergence; (4) VDSR allows parameters to be shared among all predefined scale factors, The problem of different magnification scales is solved economically.
- Insufficient : Excessive learning rate may cause gradient explosion, so a gradient reduction method is proposed to avoid it.
- Core code :
import torch
import torch.nn as nn
from math import sqrt
class Conv_ReLU_Block(nn.Module):
def __init__(self):
super(Conv_ReLU_Block, self).__init__()
self.conv = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
return self.relu(self.conv(x))
class VDSR(nn.Module):
def __init__(self):
super(VDSR, self).__init__()
self.residual_layer = self.make_layer(Conv_ReLU_Block, 18)
self.input = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False)
self.output = nn.Conv2d(in_channels=64, out_channels=1, kernel_size=3, stride=1, padding=1, bias=False)
self.relu = nn.ReLU(inplace=True)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, sqrt(2. / n))
def make_layer(self, block, num_of_layer):
layers = []
for _ in range(num_of_layer):
layers.append(block())
return nn.Sequential(*layers)
def forward(self, x):
residual = x
out = self.relu(self.input(x))
out = self.residual_layer(out)
out = self.output(out)
out = torch.add(out, residual)
return out
DRCN
Paper : https://arxiv.org/pdf/1511.04491.pdf
Code :
MatLab https://cv.snu.ac.kr/research/DRCN/
TensorFlow (1) https://github.com/nullhty/DRCN_Tensorflow ( 2) https://github.com/jiny2001/deeply-recursive-cnn-tf
Pytorch https://github.com/fungtion/DRCN
Keras https://github.com/ghif/drcn


- Innovations : (1) Propose a deep recurrent convolutional network, replacing different convolutional layers with the same recurrent layer; (2) Propose recurrent supervision and use skip connections.
- Benefits : (1) Increase the receptive field of the network; (2) Avoid the gradient disappearance/explosion problem of the deep network.
- Core code :
import torch.nn as nn
class DRCN(nn.Module):
def __init__(self, n_class):
super(DRCN, self).__init__()
# convolutional encoder
self.enc_feat = nn.Sequential()
self.enc_feat.add_module('conv1', nn.Conv2d(in_channels=1, out_channels=100, kernel_size=5,
padding=2))
self.enc_feat.add_module('relu1', nn.ReLU(True))
self.enc_feat.add_module('pool1', nn.MaxPool2d(kernel_size=2, stride=2))
self.enc_feat.add_module('conv2', nn.Conv2d(in_channels=100, out_channels=150, kernel_size=5,
padding=2))
self.enc_feat.add_module('relu2', nn.ReLU(True))
self.enc_feat.add_module('pool2', nn.MaxPool2d(kernel_size=2, stride=2))
self.enc_feat.add_module('conv3', nn.Conv2d(in_channels=150, out_channels=200, kernel_size=3,
padding=1))
self.enc_feat.add_module('relu3', nn.ReLU(True))
self.enc_dense = nn.Sequential()
self.enc_dense.add_module('fc4', nn.Linear(in_features=200 * 8 * 8, out_features=1024))
self.enc_dense.add_module('relu4', nn.ReLU(True))
self.enc_dense.add_module('drop4', nn.Dropout2d())
self.enc_dense.add_module('fc5', nn.Linear(in_features=1024, out_features=1024))
self.enc_dense.add_module('relu5', nn.ReLU(True))
# label predict layer
self.pred = nn.Sequential()
self.pred.add_module('dropout6', nn.Dropout2d())
self.pred.add_module('predict6', nn.Linear(in_features=1024, out_features=n_class))
# convolutional decoder
self.rec_dense = nn.Sequential()
self.rec_dense.add_module('fc5_', nn.Linear(in_features=1024, out_features=1024))
self.rec_dense.add_module('relu5_', nn.ReLU(True))
self.rec_dense.add_module('fc4_', nn.Linear(in_features=1024, out_features=200 * 8 * 8))
self.rec_dense.add_module('relu4_', nn.ReLU(True))
self.rec_feat = nn.Sequential()
self.rec_feat.add_module('conv3_', nn.Conv2d(in_channels=200, out_channels=150,
kernel_size=3, padding=1))
self.rec_feat.add_module('relu3_', nn.ReLU(True))
self.rec_feat.add_module('pool3_', nn.Upsample(scale_factor=2))
self.rec_feat.add_module('conv2_', nn.Conv2d(in_channels=150, out_channels=100,
kernel_size=5, padding=2))
self.rec_feat.add_module('relu2_', nn.ReLU(True))
self.rec_feat.add_module('pool2_', nn.Upsample(scale_factor=2))
self.rec_feat.add_module('conv1_', nn.Conv2d(in_channels=100, out_channels=1,
kernel_size=5, padding=2))
def forward(self, input_data):
feat = self.enc_feat(input_data)
feat = feat.view(-1, 200 * 8 * 8)
feat_code = self.enc_dense(feat)
pred_label = self.pred(feat_code)
feat_encode = self.rec_dense(feat_code)
feat_encode = feat_encode.view(-1, 200, 8, 8)
img_rec = self.rec_feat(feat_encode)
return pred_label, img_rec
DRRN
Paper : https://openaccess.thecvf.com/content_cvpr_2017/html/Tai_Image_Super-Resolution_via_CVPR_2017_paper.html
Code :
MatLab https://github.com/tyshiwo/DRRN_CVPR17
TensorFlow https://github.com/LoSealL/VideoSuperResolution
Pytorch https: https://github.com/Major357/DRRN-pytorch

- Innovations : (1) Deeper network than VDSR; (2) Recursive learning; (3) Residual learning.
- Benefits : (1) Deeper networks can generally get better reconstruction results; (2) It is equivalent to increasing the depth of the network, and weight sharing reduces the number of parameters; (3) Avoiding the problem of gradient disappearance/explosion.
- Core code :
import torch
import torch.nn as nn
from math import sqrt
class DRRN(nn.Module):
def __init__(self):
super(DRRN, self).__init__()
self.input = nn.Conv2d(in_channels=1, out_channels=128, kernel_size=3, stride=1, padding=1, bias=False)
self.conv1 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1, bias=False)
self.conv2 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1, bias=False)
self.output = nn.Conv2d(in_channels=128, out_channels=1, kernel_size=3, stride=1, padding=1, bias=False)
self.relu = nn.ReLU(inplace=True)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, sqrt(2. / n))
def forward(self, x):
residual = x
inputs = self.input(self.relu(x))
out = inputs
for _ in range(25):
out = self.conv2(self.relu(self.conv1(self.relu(out))))
out = torch.add(out, inputs)
out = self.output(self.relu(out))
out = torch.add(out, residual)
return out
EDSR
Paper : https://arxiv.org/abs/1707.02921
Code :
TensorFlow https://github.com/jmiller656/EDSR-Tensorflow
Pytorch (1) https://github.com/sanghyun-son/EDSR-PyTorch (2 ) https://github.com/thstkdgus35/EDSR-PyTorch

- Innovation points : (1) Remove the BatchNorm layer; (2) Propose a multi-scale block with a single main branch, first train the low-resolution super-resolution model, and then train the high-resolution super-resolution model based on it.
- Benefits : (1) The model is lighter and can better express image features; (2) Weight sharing reduces the training time of high-resolution super-resolution models, and the reconstruction effect is better.
- The reason for removing the BN layer :
BatchNorm is a very important technology in deep learning. It not only makes it easier to train deeper networks, accelerates convergence, but also has a certain regularization effect to prevent network overfitting. Therefore, BatchNorm is used in CNN. Used a lot. However, in terms of image super-resolution and image generation and restoration, BatchNorm does not perform well. Instead, it makes network training slow, unstable, and even divergent.
BatchNorm ignores the absolute difference between image pixels (or features) (because the mean is zeroed and the variance is normalized), and only considers the relative difference, so it is icing on the cake in tasks that do not require absolute differences (such as classification). For image super-resolution tasks that require absolute differences, BatchNorm is not suitable. In addition, since BatchNorm consumes the same size of memory as the convolutional layer in front of it, EDSR can stack more network layers or extract more features from each layer under the same computing resources after removal, so as to achieve better performance. .
Reference: https://blog.csdn.net/sinat_36197913/article/details/104845599 - Core code :
class EDSR(nn.Module):
def __init__(self, args, conv=common.default_conv):
super(EDSR, self).__init__()
n_resblocks = args.n_resblocks
n_feats = args.n_feats
kernel_size = 3
scale = args.scale[0]
act = nn.ReLU(True)
self.sub_mean = common.MeanShift(args.rgb_range)
self.add_mean = common.MeanShift(args.rgb_range, sign=1)
# define head module
m_head = [conv(args.n_colors, n_feats, kernel_size)]
# define body module
m_body = [
common.ResBlock(
conv, n_feats, kernel_size, act=act, res_scale=args.res_scale
) for _ in range(n_resblocks)
]
m_body.append(conv(n_feats, n_feats, kernel_size))
# define tail module
m_tail = [
common.Upsampler(conv, scale, n_feats, act=False),
conv(n_feats, args.n_colors, kernel_size)
]
self.head = nn.Sequential(*m_head)
self.body = nn.Sequential(*m_body)
self.tail = nn.Sequential(*m_tail)
def forward(self, x):
x = self.sub_mean(x)
x = self.head(x)
res = self.body(x)
res += x
x = self.tail(res)
x = self.add_mean(x)
return x
SRGAN
Paper : http://arxiv.org/abs/1609.04802
Code :
MatLab https://github.com/ShenghaiRong/caffe_srgan
TensorFlow (1) https://github.com/brade31919/SRGAN-tensorflow (2) https:/ /github.com/zsdonghao/SRGAN (3) https://github.com/buriburisuri/SRGAN
Pytorch (1) https://github.com/zzbdr/DL/tree/main/Super-resolution/SRGAN (2) https://github.com/aitorzip/PyTorch-SRGAN
Keras (1) https://github.com/jiantenggei/srgan (2) https://github.com/jiantenggei/Srgan_ (3) https://github .com/titu1994/Super-Resolution-using-Generative-Adversarial-Networks

- Innovation points : (1) Use GAN for super-resolution reconstruction; (2) Propose a new perceptual loss based on the Euclidean distance between feature maps extracted by the VGG network to replace content loss based on MSE; (3) Propose a new image Quality evaluation index Mean Opinion Score (MOS).
- Benefits : (1) GAN network can produce images with high perceptual quality, so as to obtain high-score images that are more comfortable for the naked eye; (2) higher-level image features will produce more image details, and the loss is calculated in the feature map It makes it possible to reconstruct a visually better high-scoring image; (3) The evaluation of the reconstructed image is more in line with the visual effect of the human eye.
- Limitations of the MSE loss function : While directly optimizing MSE can yield high PSNR/SSIM, at large magnifications, MSE loss-guided learning fails to make the reconstructed images capture detailed information.
- Why not use PSNR/SSIM to evaluate image quality : As we all know, the size of PSNR value does not reflect the quality of the image absolutely, and SSIM is closer to the visual effect of human eyes than PSNR in evaluating image quality. But in this paper, the author believes that these two indicators are not accurate enough, so the mean opinion score MOS is proposed.
- Core code :
import torch.nn as nn
class Block(nn.Module):
def __init__(self, input_channel=64, output_channel=64, kernel_size=3, stride=1, padding=1):
super().__init__()
self.layer = nn.Sequential(
nn.Conv2d(input_channel, output_channel, kernel_size, stride, bias=False, padding=1),
nn.BatchNorm2d(output_channel),
nn.PReLU(),
nn.Conv2d(output_channel, output_channel, kernel_size, stride, bias=False, padding=1),
nn.BatchNorm2d(output_channel)
)
def forward(self, x0):
x1 = self.layer(x0)
return x0 + x1
class Generator(nn.Module):
def __init__(self, scale=2):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, 9, stride=1, padding=4),
nn.PReLU()
)
self.residual_block = nn.Sequential(
Block(),
Block(),
Block(),
Block(),
Block(),
)
self.conv2 = nn.Sequential(
nn.Conv2d(64, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64),
)
self.conv3 = nn.Sequential(
nn.Conv2d(64, 256, 3, stride=1, padding=1),
nn.PixelShuffle(scale),
nn.PReLU(),
nn.Conv2d(64, 256, 3, stride=1, padding=1),
nn.PixelShuffle(scale),
nn.PReLU(),
)
self.conv4 = nn.Conv2d(64, 3, 9, stride=1, padding=4)
def forward(self, x):
x0 = self.conv1(x)
x = self.residual_block(x0)
x = self.conv2(x)
x = self.conv3(x + x0)
x = self.conv4(x)
return x
class DownSalmpe(nn.Module):
def __init__(self, input_channel, output_channel, stride, kernel_size=3, padding=1):
super().__init__()
self.layer = nn.Sequential(
nn.Conv2d(input_channel, output_channel, kernel_size, stride, padding),
nn.BatchNorm2d(output_channel),
nn.LeakyReLU(inplace=True)
)
def forward(self, x):
x = self.layer(x)
return x
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, 3, stride=1, padding=1),
nn.LeakyReLU(inplace=True),
)
self.down = nn.Sequential(
DownSalmpe(64, 64, stride=2, padding=1),
DownSalmpe(64, 128, stride=1, padding=1),
DownSalmpe(128, 128, stride=2, padding=1),
DownSalmpe(128, 256, stride=1, padding=1),
DownSalmpe(256, 256, stride=2, padding=1),
DownSalmpe(256, 512, stride=1, padding=1),
DownSalmpe(512, 512, stride=2, padding=1),
)
self.dense = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(512, 1024, 1),
nn.LeakyReLU(inplace=True),
nn.Conv2d(1024, 1, 1),
nn.Sigmoid()
)
def forward(self, x):
x = self.conv1(x)
x = self.down(x)
x = self.dense(x)
return x
ESRGAN
Paper : https://arxiv.org/abs/1809.00219
Code :
Pytorch https://github.com/xinntao/ESRGAN


- Innovation points : (1) Propose the Residual-in-Residual Dense Block (RRDB) structure, and remove the BatchNorm layer; (2) Learn from the idea of Relativistic GAN, let the discriminator predict the authenticity of the image instead of the image "whether it is a fake image" "; (3) Compute perceptual loss using features before activation.
- Benefits : (1) Dense connection can better integrate features and speed up training, improve the restored texture (because the depth model has a strong representation ability to capture semantic information), and can remove noise, while removing BatchNorm can get better (2) make the reconstructed image closer to the real image; (3) the features before activation will provide sharper edges and more visual results.
- Core code :
import functools
import torch
import torch.nn as nn
import torch.nn.functional as F
def make_layer(block, n_layers):
layers = []
for _ in range(n_layers):
layers.append(block())
return nn.Sequential(*layers)
class ResidualDenseBlock_5C(nn.Module):
def __init__(self, nf=64, gc=32, bias=True):
super(ResidualDenseBlock_5C, self).__init__()
# gc: growth channel, i.e. intermediate channels
self.conv1 = nn.Conv2d(nf, gc, 3, 1, 1, bias=bias)
self.conv2 = nn.Conv2d(nf + gc, gc, 3, 1, 1, bias=bias)
self.conv3 = nn.Conv2d(nf + 2 * gc, gc, 3, 1, 1, bias=bias)
self.conv4 = nn.Conv2d(nf + 3 * gc, gc, 3, 1, 1, bias=bias)
self.conv5 = nn.Conv2d(nf + 4 * gc, nf, 3, 1, 1, bias=bias)
self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
# initialization
# mutil.initialize_weights([self.conv1, self.conv2, self.conv3, self.conv4, self.conv5], 0.1)
def forward(self, x):
x1 = self.lrelu(self.conv1(x))
x2 = self.lrelu(self.conv2(torch.cat((x, x1), 1)))
x3 = self.lrelu(self.conv3(torch.cat((x, x1, x2), 1)))
x4 = self.lrelu(self.conv4(torch.cat((x, x1, x2, x3), 1)))
x5 = self.conv5(torch.cat((x, x1, x2, x3, x4), 1))
return x5 * 0.2 + x
class RRDB(nn.Module):
'''Residual in Residual Dense Block'''
def __init__(self, nf, gc=32):
super(RRDB, self).__init__()
self.RDB1 = ResidualDenseBlock_5C(nf, gc)
self.RDB2 = ResidualDenseBlock_5C(nf, gc)
self.RDB3 = ResidualDenseBlock_5C(nf, gc)
def forward(self, x):
out = self.RDB1(x)
out = self.RDB2(out)
out = self.RDB3(out)
return out * 0.2 + x
class RRDBNet(nn.Module):
def __init__(self, in_nc, out_nc, nf, nb, gc=32):
super(RRDBNet, self).__init__()
RRDB_block_f = functools.partial(RRDB, nf=nf, gc=gc)
self.conv_first = nn.Conv2d(in_nc, nf, 3, 1, 1, bias=True)
self.RRDB_trunk = make_layer(RRDB_block_f, nb)
self.trunk_conv = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
#### upsampling
self.upconv1 = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
self.upconv2 = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
self.HRconv = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
self.conv_last = nn.Conv2d(nf, out_nc, 3, 1, 1, bias=True)
self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
def forward(self, x):
fea = self.conv_first(x)
trunk = self.trunk_conv(self.RRDB_trunk(fea))
fea = fea + trunk
fea = self.lrelu(self.upconv1(F.interpolate(fea, scale_factor=2, mode='nearest')))
fea = self.lrelu(self.upconv2(F.interpolate(fea, scale_factor=2, mode='nearest')))
out = self.conv_last(self.lrelu(self.HRconv(fea)))
return out
RDN
Paper : https://arxiv.org/abs/1802.08797
Code :
TensorFlow https://github.com/hengchuan/RDN-TensorFlow
Pytorch https://github.com/lizhengwei1992/ResidualDenseNetwork-Pytorch
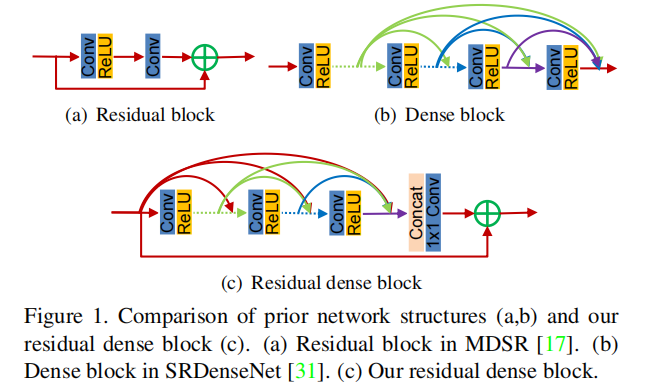
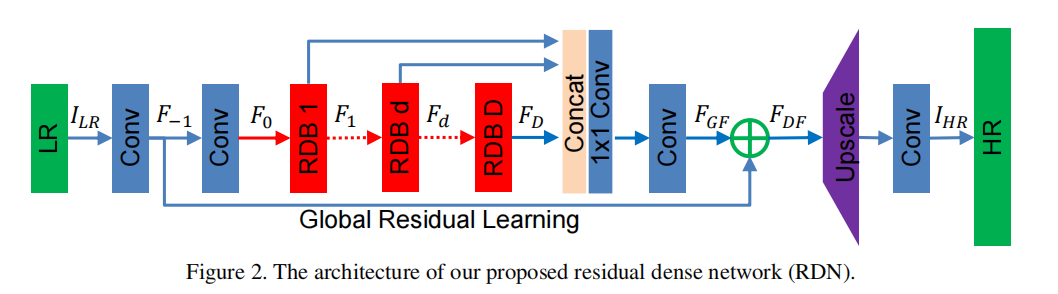
- Innovation point : Propose Residual Dense Block (RDB) structure;
- Benefits : Residual learning and dense connections effectively alleviate the phenomenon of gradient disappearance caused by the increase of network depth, where dense connections strengthen feature propagation and encourage feature reuse.
- Core code :
import torch
import torch.nn as nn
import torch.nn.functional as F
class sub_pixel(nn.Module):
def __init__(self, scale, act=False):
super(sub_pixel, self).__init__()
modules = []
modules.append(nn.PixelShuffle(scale))
self.body = nn.Sequential(*modules)
def forward(self, x):
x = self.body(x)
return x
class make_dense(nn.Module):
def __init__(self, nChannels, growthRate, kernel_size=3):
super(make_dense, self).__init__()
self.conv = nn.Conv2d(nChannels, growthRate, kernel_size=kernel_size, padding=(kernel_size-1)//2, bias=False)
def forward(self, x):
out = F.relu(self.conv(x))
out = torch.cat((x, out), 1)
return out
# Residual dense block (RDB) architecture
class RDB(nn.Module):
def __init__(self, nChannels, nDenselayer, growthRate):
super(RDB, self).__init__()
nChannels_ = nChannels
modules = []
for i in range(nDenselayer):
modules.append(make_dense(nChannels_, growthRate))
nChannels_ += growthRate
self.dense_layers = nn.Sequential(*modules)
self.conv_1x1 = nn.Conv2d(nChannels_, nChannels, kernel_size=1, padding=0, bias=False)
def forward(self, x):
out = self.dense_layers(x)
out = self.conv_1x1(out)
out = out + x
return out
# Residual Dense Network
class RDN(nn.Module):
def __init__(self, args):
super(RDN, self).__init__()
nChannel = args.nChannel
nDenselayer = args.nDenselayer
nFeat = args.nFeat
scale = args.scale
growthRate = args.growthRate
self.args = args
# F-1
self.conv1 = nn.Conv2d(nChannel, nFeat, kernel_size=3, padding=1, bias=True)
# F0
self.conv2 = nn.Conv2d(nFeat, nFeat, kernel_size=3, padding=1, bias=True)
# RDBs 3
self.RDB1 = RDB(nFeat, nDenselayer, growthRate)
self.RDB2 = RDB(nFeat, nDenselayer, growthRate)
self.RDB3 = RDB(nFeat, nDenselayer, growthRate)
# global feature fusion (GFF)
self.GFF_1x1 = nn.Conv2d(nFeat*3, nFeat, kernel_size=1, padding=0, bias=True)
self.GFF_3x3 = nn.Conv2d(nFeat, nFeat, kernel_size=3, padding=1, bias=True)
# Upsampler
self.conv_up = nn.Conv2d(nFeat, nFeat*scale*scale, kernel_size=3, padding=1, bias=True)
self.upsample = sub_pixel(scale)
# conv
self.conv3 = nn.Conv2d(nFeat, nChannel, kernel_size=3, padding=1, bias=True)
def forward(self, x):
F_ = self.conv1(x)
F_0 = self.conv2(F_)
F_1 = self.RDB1(F_0)
F_2 = self.RDB2(F_1)
F_3 = self.RDB3(F_2)
FF = torch.cat((F_1, F_2, F_3), 1)
FdLF = self.GFF_1x1(FF)
FGF = self.GFF_3x3(FdLF)
FDF = FGF + F_
us = self.conv_up(FDF)
us = self.upsample(us)
output = self.conv3(us)
return output
WDSR
Paper : https://arxiv.org/abs/1808.08718
Code :
TensorFlow https://github.com/ychfan/tf_estimator_barebone
Pytorch https://github.com/JiahuiYu/wdsr_ntire2018
Keras https://github.com/krasserm/ super-resolution
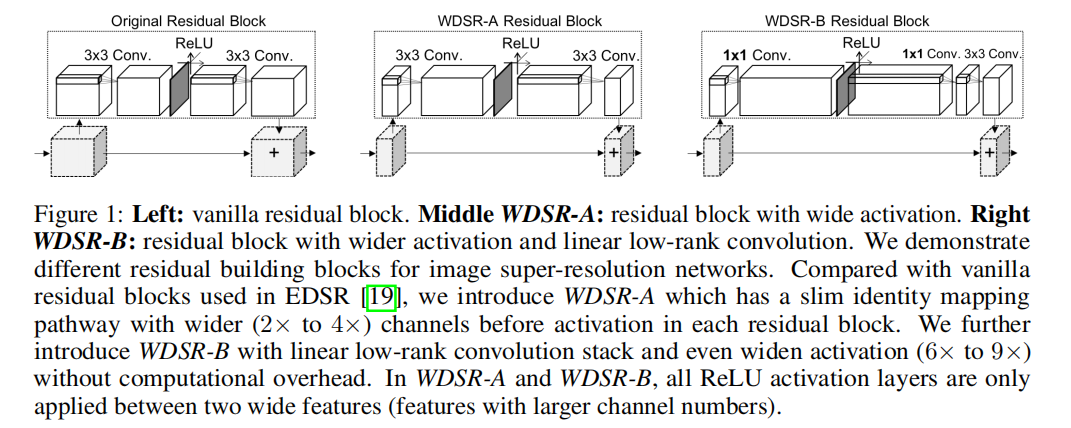

- Innovation points : (1) Increase the number of feature map channels before the activation function, that is, the broad feature map; (2) Weight Normalization; (3) The two branches perform the same upsampling operation, and directly add the high-scoring image.
- Benefits : (1) The activation function will prevent the transmission of information flow, and the influence of the activation function on the information flow can be reduced by increasing the number of feature map channels; (2) The training speed and performance of the network are improved, and it also enables training to use less Large learning rate; (3) The large convolution kernel is split into two small convolution kernels, which can save parameters.
- Core code :
import torch
import torch.nn as nn
class Block(nn.Module):
def __init__(
self, n_feats, kernel_size, wn, act=nn.ReLU(True), res_scale=1):
super(Block, self).__init__()
self.res_scale = res_scale
body = []
expand = 6
linear = 0.8
body.append(
wn(nn.Conv2d(n_feats, n_feats*expand, 1, padding=1//2)))
body.append(act)
body.append(
wn(nn.Conv2d(n_feats*expand, int(n_feats*linear), 1, padding=1//2)))
body.append(
wn(nn.Conv2d(int(n_feats*linear), n_feats, kernel_size, padding=kernel_size//2)))
self.body = nn.Sequential(*body)
def forward(self, x):
res = self.body(x) * self.res_scale
res += x
return res
class MODEL(nn.Module):
def __init__(self, args):
super(MODEL, self).__init__()
# hyper-params
self.args = args
scale = args.scale[0]
n_resblocks = args.n_resblocks
n_feats = args.n_feats
kernel_size = 3
act = nn.ReLU(True)
# wn = lambda x: x
wn = lambda x: torch.nn.utils.weight_norm(x)
self.rgb_mean = torch.autograd.Variable(torch.FloatTensor(
[args.r_mean, args.g_mean, args.b_mean])).view([1, 3, 1, 1])
# define head module
head = []
head.append(
wn(nn.Conv2d(args.n_colors, n_feats, 3, padding=3//2)))
# define body module
body = []
for i in range(n_resblocks):
body.append(
Block(n_feats, kernel_size, act=act, res_scale=args.res_scale, wn=wn))
# define tail module
tail = []
out_feats = scale*scale*args.n_colors
tail.append(
wn(nn.Conv2d(n_feats, out_feats, 3, padding=3//2)))
tail.append(nn.PixelShuffle(scale))
skip = []
skip.append(
wn(nn.Conv2d(args.n_colors, out_feats, 5, padding=5//2))
)
skip.append(nn.PixelShuffle(scale))
# make object members
self.head = nn.Sequential(*head)
self.body = nn.Sequential(*body)
self.tail = nn.Sequential(*tail)
self.skip = nn.Sequential(*skip)
def forward(self, x):
x = (x - self.rgb_mean.cuda()*255)/127.5
s = self.skip(x)
x = self.head(x)
x = self.body(x)
x = self.tail(x)
x += s
x = x*127.5 + self.rgb_mean.cuda()*255
return x
LapSRN
Paper : https://arxiv.org/abs/1704.03915
Code :
MatLab https://github.com/phoenix104104/LapSRN
TensorFlow https://github.com/zjuela/LapSRN-tensorflow
Pytorch https://github.com/ twtygqyy/pytorch-LapSRN

- Innovation points : (1) Propose a cascaded pyramid structure; (2) Propose a new loss function.
- Benefits : (1) Reduce computational complexity, while low-level features and high-level features increase the nonlinearity of the network, so as to better learn and map detailed features. In addition, the pyramid structure also allows the algorithm to complete multiple scales at one time; (2) MSE loss will cause the details of the reconstructed high-score image to be blurred and smooth, and the new loss function can improve this.
- Laplace image pyramid : https://www.jianshu.com/p/e3570a9216a6
- Core code :
import torch
import torch.nn as nn
import numpy as np
import math
def get_upsample_filter(size):
"""Make a 2D bilinear kernel suitable for upsampling"""
factor = (size + 1) // 2
if size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = np.ogrid[:size, :size]
filter = (1 - abs(og[0] - center) / factor) * \
(1 - abs(og[1] - center) / factor)
return torch.from_numpy(filter).float()
class _Conv_Block(nn.Module):
def __init__(self):
super(_Conv_Block, self).__init__()
self.cov_block = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.ConvTranspose2d(in_channels=64, out_channels=64, kernel_size=4, stride=2, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
)
def forward(self, x):
output = self.cov_block(x)
return output
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv_input = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False)
self.relu = nn.LeakyReLU(0.2, inplace=True)
self.convt_I1 = nn.ConvTranspose2d(in_channels=1, out_channels=1, kernel_size=4, stride=2, padding=1, bias=False)
self.convt_R1 = nn.Conv2d(in_channels=64, out_channels=1, kernel_size=3, stride=1, padding=1, bias=False)
self.convt_F1 = self.make_layer(_Conv_Block)
self.convt_I2 = nn.ConvTranspose2d(in_channels=1, out_channels=1, kernel_size=4, stride=2, padding=1, bias=False)
self.convt_R2 = nn.Conv2d(in_channels=64, out_channels=1, kernel_size=3, stride=1, padding=1, bias=False)
self.convt_F2 = self.make_layer(_Conv_Block)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
if isinstance(m, nn.ConvTranspose2d):
c1, c2, h, w = m.weight.data.size()
weight = get_upsample_filter(h)
m.weight.data = weight.view(1, 1, h, w).repeat(c1, c2, 1, 1)
if m.bias is not None:
m.bias.data.zero_()
def make_layer(self, block):
layers = []
layers.append(block())
return nn.Sequential(*layers)
def forward(self, x):
out = self.relu(self.conv_input(x))
convt_F1 = self.convt_F1(out)
convt_I1 = self.convt_I1(x)
convt_R1 = self.convt_R1(convt_F1)
HR_2x = convt_I1 + convt_R1
convt_F2 = self.convt_F2(convt_F1)
convt_I2 = self.convt_I2(HR_2x)
convt_R2 = self.convt_R2(convt_F2)
HR_4x = convt_I2 + convt_R2
return HR_2x, HR_4x
RCAN
Paper: https://arxiv.org/abs/1807.02758
Code:
TensorFlow (1) https://github.com/dongheehand/RCAN-tf (2) https://github.com/keerthan2/Residual-Channel-Attention -Network
Pytorch https://github.com/yulunzhang/RCAN
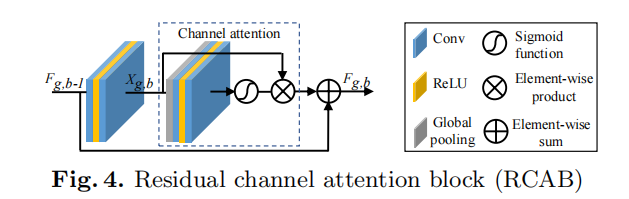
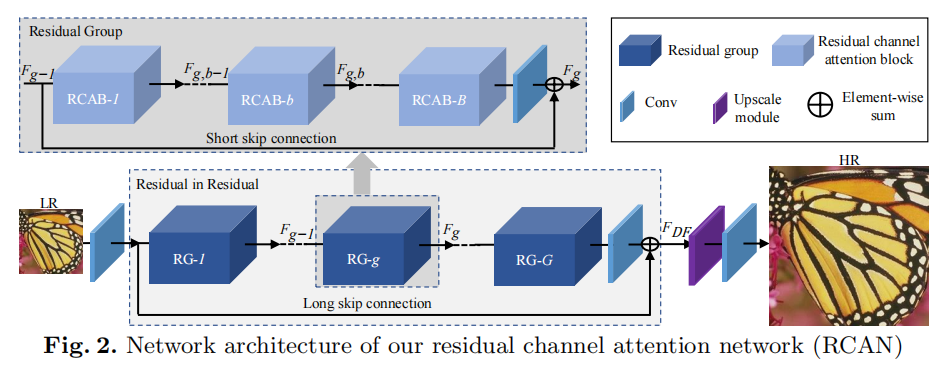
- Innovation points : (1) Use channel attention to enhance feature learning; (2) Propose Residual In Residual (RIR) structure;
- Benefits : (1) Readjust the weight of each channel by using the features of different channels; (2) Multiple residual groups and long skip connections construct coarse-grained residual learning, and stack multiple simplifications inside the residual group The residual block uses short jump connections (large residuals are embedded with small residuals), which fully integrates high and low frequencies, and accelerates network training and stability at the same time.
- Core code :
from model import common
import torch.nn as nn
## Channel Attention (CA) Layer
class CALayer(nn.Module):
def __init__(self, channel, reduction=16):
super(CALayer, self).__init__()
# global average pooling: feature --> point
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# feature channel downscale and upscale --> channel weight
self.conv_du = nn.Sequential(
nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True),
nn.Sigmoid()
)
def forward(self, x):
y = self.avg_pool(x)
y = self.conv_du(y)
return x * y
## Residual Channel Attention Block (RCAB)
class RCAB(nn.Module):
def __init__(
self, conv, n_feat, kernel_size, reduction,
bias=True, bn=False, act=nn.ReLU(True), res_scale=1):
super(RCAB, self).__init__()
modules_body = []
for i in range(2):
modules_body.append(conv(n_feat, n_feat, kernel_size, bias=bias))
if bn: modules_body.append(nn.BatchNorm2d(n_feat))
if i == 0: modules_body.append(act)
modules_body.append(CALayer(n_feat, reduction))
self.body = nn.Sequential(*modules_body)
self.res_scale = res_scale
def forward(self, x):
res = self.body(x)
res += x
return res
## Residual Group (RG)
class ResidualGroup(nn.Module):
def __init__(self, conv, n_feat, kernel_size, reduction, act, res_scale, n_resblocks):
super(ResidualGroup, self).__init__()
modules_body = []
modules_body = [
RCAB(
conv, n_feat, kernel_size, reduction, bias=True, bn=False, act=nn.ReLU(True), res_scale=1) \
for _ in range(n_resblocks)]
modules_body.append(conv(n_feat, n_feat, kernel_size))
self.body = nn.Sequential(*modules_body)
def forward(self, x):
res = self.body(x)
res += x
return res
## Residual Channel Attention Network (RCAN)
class RCAN(nn.Module):
def __init__(self, args, conv=common.default_conv):
super(RCAN, self).__init__()
n_resgroups = args.n_resgroups
n_resblocks = args.n_resblocks
n_feats = args.n_feats
kernel_size = 3
reduction = args.reduction
scale = args.scale[0]
act = nn.ReLU(True)
# RGB mean for DIV2K
rgb_mean = (0.4488, 0.4371, 0.4040)
rgb_std = (1.0, 1.0, 1.0)
self.sub_mean = common.MeanShift(args.rgb_range, rgb_mean, rgb_std)
# define head module
modules_head = [conv(args.n_colors, n_feats, kernel_size)]
# define body module
modules_body = [
ResidualGroup(
conv, n_feats, kernel_size, reduction, act=act, res_scale=args.res_scale, n_resblocks=n_resblocks) \
for _ in range(n_resgroups)]
modules_body.append(conv(n_feats, n_feats, kernel_size))
# define tail module
modules_tail = [
common.Upsampler(conv, scale, n_feats, act=False),
conv(n_feats, args.n_colors, kernel_size)]
self.add_mean = common.MeanShift(args.rgb_range, rgb_mean, rgb_std, 1)
self.head = nn.Sequential(*modules_head)
self.body = nn.Sequential(*modules_body)
self.tail = nn.Sequential(*modules_tail)
def forward(self, x):
x = self.sub_mean(x)
x = self.head(x)
res = self.body(x)
res += x
x = self.tail(res)
x = self.add_mean(x)
return x
SAN
Paper : https://csjcai.github.io/papers/SAN.pdf
Code :
Pytorch https://github.com/daitao/SAN

- Innovation points : (1) Propose a second-order attention mechanism Second-order Channel Attention (SOCA); (2) Propose a Non-Locally Enhanced Residual Group (NLRG) structure.
- Benefits : (1) The internal dependencies of features are adaptively learned through the distribution of second-order features, enabling the network to focus on more beneficial information and improve the ability of discriminative learning; (2) Non-local operations can aggregate contextual information while utilizing The residual structure is used to train the deep network, speeding up and stabilizing the network training process.
- Core code :
from model import common
import torch
import torch.nn as nn
import torch.nn.functional as F
from model.MPNCOV.python import MPNCOV
class NONLocalBlock2D(_NonLocalBlockND):
def __init__(self, in_channels, inter_channels=None, mode='embedded_gaussian', sub_sample=True, bn_layer=True):
super(NONLocalBlock2D, self).__init__(in_channels,
inter_channels=inter_channels,
dimension=2, mode=mode,
sub_sample=sub_sample,
bn_layer=bn_layer)
## Channel Attention (CA) Layer
class CALayer(nn.Module):
def __init__(self, channel, reduction=8):
super(CALayer, self).__init__()
# global average pooling: feature --> point
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
# feature channel downscale and upscale --> channel weight
self.conv_du = nn.Sequential(
nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True),
)
def forward(self, x):
_,_,h,w = x.shape
y_ave = self.avg_pool(x)
y_ave = self.conv_du(y_ave)
return y_ave
## second-order Channel attention (SOCA)
class SOCA(nn.Module):
def __init__(self, channel, reduction=8):
super(SOCA, self).__init__()
self.max_pool = nn.MaxPool2d(kernel_size=2)
# feature channel downscale and upscale --> channel weight
self.conv_du = nn.Sequential(
nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True),
nn.Sigmoid()
)
def forward(self, x):
batch_size, C, h, w = x.shape # x: NxCxHxW
N = int(h * w)
min_h = min(h, w)
h1 = 1000
w1 = 1000
if h < h1 and w < w1:
x_sub = x
elif h < h1 and w > w1:
# H = (h - h1) // 2
W = (w - w1) // 2
x_sub = x[:, :, :, W:(W + w1)]
elif w < w1 and h > h1:
H = (h - h1) // 2
# W = (w - w1) // 2
x_sub = x[:, :, H:H + h1, :]
else:
H = (h - h1) // 2
W = (w - w1) // 2
x_sub = x[:, :, H:(H + h1), W:(W + w1)]
## MPN-COV
cov_mat = MPNCOV.CovpoolLayer(x_sub) # Global Covariance pooling layer
cov_mat_sqrt = MPNCOV.SqrtmLayer(cov_mat,5) # Matrix square root layer( including pre-norm,Newton-Schulz iter. and post-com. with 5 iteration)
cov_mat_sum = torch.mean(cov_mat_sqrt,1)
cov_mat_sum = cov_mat_sum.view(batch_size,C,1,1)
y_cov = self.conv_du(cov_mat_sum)
return y_cov*x
## self-attention+ channel attention module
class Nonlocal_CA(nn.Module):
def __init__(self, in_feat=64, inter_feat=32, reduction=8,sub_sample=False, bn_layer=True):
super(Nonlocal_CA, self).__init__()
# second-order channel attention
self.soca=SOCA(in_feat, reduction=reduction)
# nonlocal module
self.non_local = (NONLocalBlock2D(in_channels=in_feat,inter_channels=inter_feat, sub_sample=sub_sample,bn_layer=bn_layer))
self.sigmoid = nn.Sigmoid()
def forward(self,x):
## divide feature map into 4 part
batch_size,C,H,W = x.shape
H1 = int(H / 2)
W1 = int(W / 2)
nonlocal_feat = torch.zeros_like(x)
feat_sub_lu = x[:, :, :H1, :W1]
feat_sub_ld = x[:, :, H1:, :W1]
feat_sub_ru = x[:, :, :H1, W1:]
feat_sub_rd = x[:, :, H1:, W1:]
nonlocal_lu = self.non_local(feat_sub_lu)
nonlocal_ld = self.non_local(feat_sub_ld)
nonlocal_ru = self.non_local(feat_sub_ru)
nonlocal_rd = self.non_local(feat_sub_rd)
nonlocal_feat[:, :, :H1, :W1] = nonlocal_lu
nonlocal_feat[:, :, H1:, :W1] = nonlocal_ld
nonlocal_feat[:, :, :H1, W1:] = nonlocal_ru
nonlocal_feat[:, :, H1:, W1:] = nonlocal_rd
return nonlocal_feat
## Residual Block (RB)
class RB(nn.Module):
def __init__(self, conv, n_feat, kernel_size, reduction, bias=True, bn=False, act=nn.ReLU(inplace=True), res_scale=1, dilation=2):
super(RB, self).__init__()
modules_body = []
self.gamma1 = 1.0
self.conv_first = nn.Sequential(conv(n_feat, n_feat, kernel_size, bias=bias),
act,
conv(n_feat, n_feat, kernel_size, bias=bias))
self.res_scale = res_scale
def forward(self, x):
y = self.conv_first(x)
y = y + x
return y
## Local-source Residual Attention Group (LSRARG)
class LSRAG(nn.Module):
def __init__(self, conv, n_feat, kernel_size, reduction, act, res_scale, n_resblocks):
super(LSRAG, self).__init__()
##
self.rcab= nn.ModuleList([RB(conv, n_feat, kernel_size, reduction, \
bias=True, bn=False, act=nn.ReLU(inplace=True), res_scale=1) for _ in range(n_resblocks)])
self.soca = (SOCA(n_feat,reduction=reduction))
self.conv_last = (conv(n_feat, n_feat, kernel_size))
self.n_resblocks = n_resblocks
self.gamma = nn.Parameter(torch.zeros(1))
def make_layer(self, block, num_of_layer):
layers = []
for _ in range(num_of_layer):
layers.append(block)
return nn.ModuleList(layers)
def forward(self, x):
residual = x
for i,l in enumerate(self.rcab):
x = l(x)
x = self.soca(x)
x = self.conv_last(x)
x = x + residual
return x
# Second-order Channel Attention Network (SAN)
class SAN(nn.Module):
def __init__(self, args, conv=common.default_conv):
super(SAN, self).__init__()
n_resgroups = args.n_resgroups
n_resblocks = args.n_resblocks
n_feats = args.n_feats
kernel_size = 3
reduction = args.reduction
scale = args.scale[0]
act = nn.ReLU(inplace=True)
# RGB mean for DIV2K
rgb_mean = (0.4488, 0.4371, 0.4040)
rgb_std = (1.0, 1.0, 1.0)
self.sub_mean = common.MeanShift(args.rgb_range, rgb_mean, rgb_std)
# define head module
modules_head = [conv(args.n_colors, n_feats, kernel_size)]
# define body module
## share-source skip connection
self.gamma = nn.Parameter(torch.zeros(1))
self.n_resgroups = n_resgroups
self.RG = nn.ModuleList([LSRAG(conv, n_feats, kernel_size, reduction, \
act=act, res_scale=args.res_scale, n_resblocks=n_resblocks) for _ in range(n_resgroups)])
self.conv_last = conv(n_feats, n_feats, kernel_size)
# define tail module
modules_tail = [
common.Upsampler(conv, scale, n_feats, act=False),
conv(n_feats, args.n_colors, kernel_size)]
self.add_mean = common.MeanShift(args.rgb_range, rgb_mean, rgb_std, 1)
self.non_local = Nonlocal_CA(in_feat=n_feats, inter_feat=n_feats//8, reduction=8,sub_sample=False, bn_layer=False)
self.head = nn.Sequential(*modules_head)
self.tail = nn.Sequential(*modules_tail)
def make_layer(self, block, num_of_layer):
layers = []
for _ in range(num_of_layer):
layers.append(block)
return nn.ModuleList(layers)
def forward(self, x):
x = self.sub_mean(x)
x = self.head(x)
## add nonlocal
xx = self.non_local(x)
# share-source skip connection
residual = xx
# share-source residual gruop
for i,l in enumerate(self.RG):
xx = l(xx) + self.gamma*residual
## add nonlocal
res = self.non_local(xx)
res = res + x
x = self.tail(res)
x = self.add_mean(x)
return x
IGNN
Paper : https://proceedings.neurips.cc/paper/2020/file/8b5c8441a8ff8e151b191c53c1842a38-Paper.pdf
Code :
Pytorch https://github.com/sczhou/IGNN
- Innovation points : (1) Propose the non-locally Graph convolution aggregation module non-locally Graph convolution Aggregation (GraphAgg), and then propose the implicit neural network Implicit Graph Neural Network (IGNN).
- Benefits : (1) Cleverly find multiple high-scoring image block neighbors for each low-scoring image, and then construct a connection graph from low-scoring to high-scoring, and then aggregate the texture information of multiple high-scoring images on the low-scoring image , so as to achieve super-resolution reconstruction.
- Core code :
from models.submodules import *
from models.VGG19 import VGG19
from config import cfg
class IGNN(nn.Module):
def __init__(self):
super(IGNN, self).__init__()
kernel_size = 3
n_resblocks = cfg.NETWORK.N_RESBLOCK
n_feats = cfg.NETWORK.N_FEATURE
n_neighbors = cfg.NETWORK.N_REIGHBOR
scale = cfg.CONST.SCALE
if cfg.CONST.SCALE == 4:
scale = 2
window = cfg.NETWORK.WINDOW_SIZE
gcn_stride = 2
patch_size = 3
self.sub_mean = MeanShift(rgb_range=cfg.DATA.RANGE, sign=-1)
self.add_mean = MeanShift(rgb_range=cfg.DATA.RANGE, sign=1)
self.vggnet = VGG19([3])
self.graph = Graph(scale, k=n_neighbors, patchsize=patch_size, stride=gcn_stride,
window_size=window, in_channels=256, embedcnn=self.vggnet)
# define head module
self.head = conv(3, n_feats, kernel_size, act=False)
# middle 16
pre_blocks = int(n_resblocks//2)
# define body module
m_body1 = [
ResBlock(
n_feats, kernel_size, res_scale=cfg.NETWORK.RES_SCALE
) for _ in range(pre_blocks)
]
m_body2 = [
ResBlock(
n_feats, kernel_size, res_scale=cfg.NETWORK.RES_SCALE
) for _ in range(n_resblocks-pre_blocks)
]
m_body2.append(conv(n_feats, n_feats, kernel_size, act=False))
fuse_b = [
conv(n_feats*2, n_feats, kernel_size),
conv(n_feats, n_feats, kernel_size, act=False) # act=False important for relu!!!
]
fuse_up = [
conv(n_feats*2, n_feats, kernel_size),
conv(n_feats, n_feats, kernel_size)
]
if cfg.CONST.SCALE == 4:
m_tail = [
upsampler(n_feats, kernel_size, scale, act=False),
conv(n_feats, 3, kernel_size, act=False) # act=False important for relu!!!
]
else:
m_tail = [
conv(n_feats, 3, kernel_size, act=False) # act=False important for relu!!!
]
self.body1 = nn.Sequential(*m_body1)
self.gcn = GCNBlock(n_feats, scale, k=n_neighbors, patchsize=patch_size, stride=gcn_stride)
self.fuse_b = nn.Sequential(*fuse_b)
self.body2 = nn.Sequential(*m_body2)
self.upsample = upsampler(n_feats, kernel_size, scale, act=False)
self.fuse_up = nn.Sequential(*fuse_up)
self.tail = nn.Sequential(*m_tail)
def forward(self, x_son, x):
score_k, idx_k, diff_patch = self.graph(x_son, x)
idx_k = idx_k.detach()
if cfg.NETWORK.WITH_DIFF:
diff_patch = diff_patch.detach()
x = self.sub_mean(x)
x0 = self.head(x)
x1 = self.body1(x0)
x1_lr, x1_hr = self.gcn(x1, idx_k, diff_patch)
x1 = self.fuse_b(torch.cat([x1, x1_lr], dim=1))
x2 = self.body2(x1) + x0
x = self.upsample(x2)
x = self.fuse_up(torch.cat([x, x1_hr], dim=1))
x= self.tail(x)
x = self.add_mean(x)
return x
SwinIR
Paper: https://arxiv.org/pdf/2108.10257.pdf
Code:
Pytorch https://github.com/JingyunLiang/SwinIR

- Innovation points : (1) Use Swin Transformer for image super-resolution, denoising and other tasks; (2) Combine Transformer with CNN.
- Benefits : (1) Transformer can effectively capture long-distance dependencies, and Swin Transformer limits self-attention calculations to segmented non-overlapping windows to reduce the amount of calculation; (2) Use CNN to avoid the hierarchical structure in the original paper after Transformer Layer, Realize plug-and-play, and research shows that CNN in Transformer can stabilize the training process and fuse features.
- Code and comment reference : https://blog.csdn.net/Wenyuanbo/article/details/121264131
6. Conclusion and discussion (personal understanding)
The Dilemma of Image Overresolution
- The improvement of quantitative indicators is becoming more and more difficult;
- Most algorithms cannot be deployed or practically applied on the mobile side;
- The super-resolution reconstruction algorithm based on pure CNN gradually loses its advantages;
- There are few networks built based on super-resolution requirements, and most of them are general-purpose architectures;
- Training results on generic datasets generalize poorly to real images or images from specialized domains;
- There are still some differences between the commonly used objective evaluation indicators and the visual effects of the human eye;
- Fully supervised algorithms often need to manually generate low-scoring or high-scoring images;
- It is difficult to obtain real-world low-scoring images and corresponding high-scoring images to construct real datasets;
- Most of the existing super-resolution reconstruction algorithms completely abandon some traditional methods, resulting in poor interpretability of these algorithms;
- There is no baseline with sufficient status in the field of image super-resolution.
The future of image super resolution
- There is still room for improvement in subjective evaluation indicators;
- There are more and more researches on video super-resolution;
- Super-scores with super-large multiples may gradually attract attention;
- The speed and computational burden of the algorithm will be considered;
- Deep learning algorithms combined with traditional methods are more likely to be recognized;
- The algorithm combining CNN and Transformer will continue in the field of image super-resolution, and may eventually be attributed to MLP (Mixer);
- There are more and more algorithms combining image super-resolution and other directions, such as super-resolution target detection, super-resolution semantic segmentation, super-resolution image repair and super-resolution image fusion, etc.;
- Due to the difficulty in improving the quantitative indicators of the old data sets, some new data sets that are more difficult and more realistic may appear;
- Unsupervised or semi-supervised directions become mainstream;
- Image super-resolution no longer focuses on the limited magnification, but on any scale;
- There are many super-resolution algorithms for more specific scenarios; etc.
other
- For beginners, here is a simple and easy-to-understand code implementation (with notes): Image super-resolution Pytorch learning code .
- With the development of deep learning frameworks, Caffe, TensorFlow, Keras, and Pytorch, which are common in the field of image super-resolution from the beginning, have basically developed into Pytorch, so it is recommended to start with Pytorch directly.