Model introduction
The main idea of DenseNet is dense connection, which introduces dense blocks (Dense Block) in convolutional neural network (CNN), in these blocks, each layer is directly connected to all previous layers. This design allows information to disseminate more quickly, helps to solve the problem of gradient disappearance, and can also increase the parameter sharing of the network, reduce the number of parameters, and improve the efficiency and performance of the model.
Principle of Desnet
The principle of DenseNet can be summarized as the following key points:
-
Densely connected blocks : DenseNet divides the network into multiple dense blocks (Dense Block). Within each dense block, each layer is connected to all previous layers, not just the previous one. This connection allows information to spread more quickly, allowing the network to fuse features from different layers at an earlier stage.
-
Skip connections : Each layer receives features from all previous layers as input. These inputs are stacked to form a dense feature map. This skip connection helps to solve the gradient disappearance problem, because each layer can directly access the gradient information of the previous layer, making the training more stable.
-
Feature reusability : Since each layer is connected to all previous layers, the network can automatically learn richer and more complex feature representations. Such feature reuse helps to improve the performance of the network while reducing the number of parameters that need to be trained.
-
Transition layer : Between dense blocks, a transition layer (Transition Layer) is usually used to control the size of the feature map. The transition layer consists of a convolutional layer and a pooling layer to reduce the size of the feature map, thereby reducing the amount of computation.

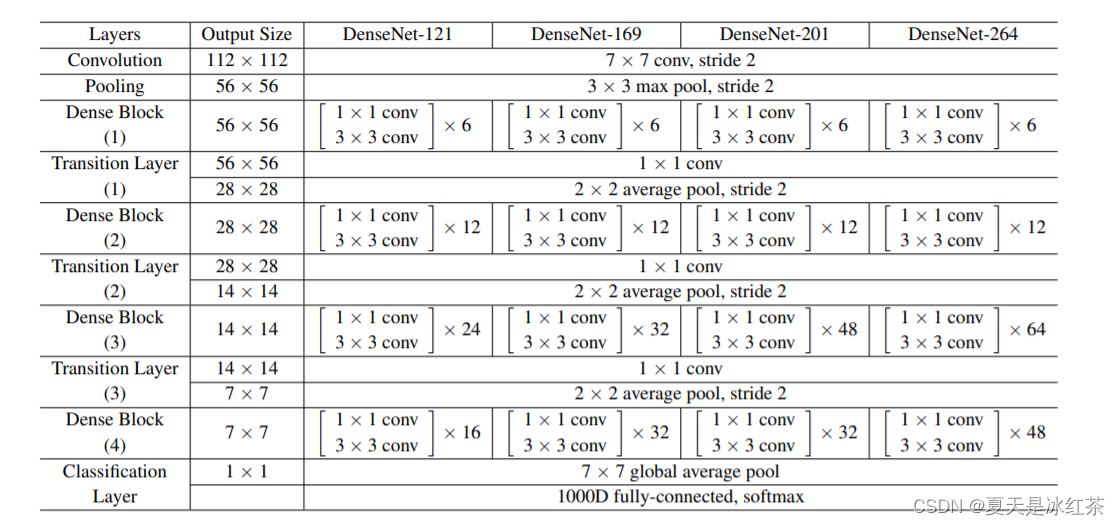
Structure of Desnet
Regarding the structure of DenseNet, we mainly focus on three main components in the network: dense block (Dense Block), transition layer (Transition Layer) and global average pooling layer.
dense block
The dense block is the core part of DenseNet and consists of several layers. In dense blocks, each layer is directly connected to all previous layers. This densely connected approach enables information to be delivered and reused more fully. The output of each layer is the connection of the outputs of all previous layers, which also means that the input of each layer includes the features of all previous layers. This connection method builds a dense feature map by stacking layers.
transition layer
Between dense blocks, transition layers can be used to control the size of the feature maps, thus reducing the computational cost. The transition layer consists of a convolutional layer and a pooling layer. Convolutional layers are used to reduce the number of channels, thereby reducing the dimensionality of feature maps. Pooling layers (usually average pooling) are used to reduce the size of feature maps. These operations help reduce computational requirements while maintaining network performance.
Global average pooling layer
At the end of the overall DenseNet structure, a global average pooling layer is usually added. The role of this layer is to convert the final feature map into globally summarized features, which are very useful for classification tasks. A global average pooling layer computes the average over each channel, converting each channel to a scalar, which forms the final prediction.
The characteristic of the DenseNet structure is not only the dense connection of features within each dense block, but also the use of transition layers between different dense blocks to control the size and complexity of the network. This allows DenseNet to perform well on highly complex tasks while keeping relatively few parameters.
These are also reflected in the paper:
Comparison of advantages and disadvantages of Desnet
advantage
-
Dense connections facilitate information transfer and feature reuse, improving network performance.
-
Skip connections reduce vanishing gradients and help train deep networks.
-
Dense connections reduce the number of parameters and improve model efficiency.
-
Early fusion of multi-scale features enhances representation capabilities.
-
It performs better in the case of small samples and makes full use of limited data.
shortcoming
-
Dense connections can lead to increased memory requirements.
-
More connections lead to increased computation and longer training and inference time.
-
Overfitting may be caused by complexity, and regularization needs to be considered.
In fact, considering it comprehensively, Desnet is still a good choice in image recognition and computer vision tasks.
Pytorch implements Desnet
import torch
import torchvision
import torch.nn as nn
import torchsummary
import torch.nn.functional as F
from torch.hub import load_state_dict_from_url
from collections import OrderedDict
from torchvision.utils import _log_api_usage_once
import torch.utils.checkpoint as cp
model_urls = {
"densenet121":"https://download.pytorch.org/models/densenet121-a639ec97.pth",
"densenet161":"https://download.pytorch.org/models/densenet161-8d451a50.pth",
"densenet169":"https://download.pytorch.org/models/densenet169-b2777c0a.pth",
"densenet201":"https://download.pytorch.org/models/densenet201-c1103571.pth",
}
cfgs = {
"densenet121":(6, 12, 24, 16),
"densenet161":(6, 12, 36, 24),
"densenet169":(6, 12, 32, 32),
"densenet201":(6, 12, 48, 32),
}
class DenseLayer(nn.Module):
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate, memory_efficient = False):
super(DenseLayer,self).__init__()
self.norm1 = nn.BatchNorm2d(num_input_features)
self.relu1 = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(num_input_features, bn_size * growth_rate, kernel_size=1, stride=1, bias=False)
self.norm2 = nn.BatchNorm2d(bn_size * growth_rate)
self.relu2 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(bn_size * growth_rate, growth_rate, kernel_size=3, stride=1, padding=1, bias=False)
self.drop_rate = float(drop_rate)
self.memory_efficient = memory_efficient
def bn_function(self, inputs):
concated_features = torch.cat(inputs, 1)
bottleneck_output = self.conv1(self.relu1(self.norm1(concated_features)))
return bottleneck_output
def any_requires_grad(self, input):
for tensor in input:
if tensor.requires_grad:
return True
return False
@torch.jit.unused
def call_checkpoint_bottleneck(self, input):
def closure(*inputs):
return self.bn_function(inputs)
return cp.checkpoint(closure, *input)
def forward(self, input):
if isinstance(input, torch.Tensor):
prev_features = [input]
else:
prev_features = input
if self.memory_efficient and self.any_requires_grad(prev_features):
if torch.jit.is_scripting():
raise Exception("Memory Efficient not supported in JIT")
bottleneck_output = self.call_checkpoint_bottleneck(prev_features)
else:
bottleneck_output = self.bn_function(prev_features)
new_features = self.conv2(self.relu2(self.norm2(bottleneck_output)))
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return new_features
class DenseBlock(nn.ModuleDict):
def __init__(self,num_layers,num_input_features,bn_size,growth_rate,
drop_rate,memory_efficient = False,):
super(DenseBlock,self).__init__()
for i in range(num_layers):
layer = DenseLayer(
num_input_features + i * growth_rate,
growth_rate=growth_rate,
bn_size=bn_size,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
)
self.add_module("denselayer%d" % (i + 1), layer)
def forward(self, init_features):
features = [init_features]
for name, layer in self.items():
new_features = layer(features)
features.append(new_features)
return torch.cat(features, 1)
class Transition(nn.Sequential):
"""
Densenet Transition Layer:
1 × 1 conv
2 × 2 average pool, stride 2
"""
def __init__(self, num_input_features, num_output_features):
super(Transition,self).__init__()
self.norm = nn.BatchNorm2d(num_input_features)
self.relu = nn.ReLU(inplace=True)
self.conv = nn.Conv2d(num_input_features, num_output_features, kernel_size=1, stride=1, bias=False)
self.pool = nn.AvgPool2d(kernel_size=2, stride=2)
class DenseNet(nn.Module):
def __init__(self,growth_rate = 32,num_init_features = 64,block_config = None,num_classes = 1000,
bn_size = 4,drop_rate = 0.,memory_efficient = False,):
super(DenseNet,self).__init__()
_log_api_usage_once(self)
# First convolution
self.features = nn.Sequential(
OrderedDict(
[
("conv0", nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),
("norm0", nn.BatchNorm2d(num_init_features)),
("relu0", nn.ReLU(inplace=True)),
("pool0", nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),
]
)
)
# Each denseblock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = DenseBlock(
num_layers=num_layers,
num_input_features=num_features,
bn_size=bn_size,
growth_rate=growth_rate,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
)
self.features.add_module("denseblock%d" % (i + 1), block)
num_features = num_features + num_layers * growth_rate
if i != len(block_config) - 1:
trans = Transition(num_input_features=num_features, num_output_features=num_features // 2)
self.features.add_module("transition%d" % (i + 1), trans)
num_features = num_features // 2
# Final batch norm
self.features.add_module("norm5", nn.BatchNorm2d(num_features))
# Linear layer
self.classifier = nn.Linear(num_features, num_classes)
# Official init from torch repo.
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = F.relu(features, inplace=True)
out = F.adaptive_avg_pool2d(out, (1, 1))
out = torch.flatten(out, 1)
out = self.classifier(out)
return out
def densenet(growth_rate=32,num_init_features=64,num_classes=1000,mode="densenet121",pretrained=False,**kwargs):
import re
pattern = re.compile(
r"^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$"
)
if mode == "densenet161":
growth_rate=48
num_init_features=96
model = DenseNet(growth_rate, num_init_features, cfgs[mode],num_classes=num_classes, **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[mode], model_dir='./model', progress=True) # 预训练模型地址
for key in list(state_dict.keys()):
res = pattern.match(key)
if res:
new_key = res.group(1) + res.group(2)
state_dict[new_key] = state_dict[key]
del state_dict[key]
if num_classes != 1000:
num_new_classes = num_classes
weight = state_dict['classifier.weight']
bias = state_dict['classifier.bias']
weight_new = weight[:num_new_classes, :]
bias_new = bias[:num_new_classes]
state_dict['classifier.weight'] = weight_new
state_dict['classifier.bias'] = bias_new
model.load_state_dict(state_dict)
return model
from torchsummaryX import summary
if __name__ == "__main__":
in_channels = 3
num_classes = 10
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = densenet(growth_rate=32, num_init_features=64, num_classes=num_classes, mode="densenet121", pretrained=True)
model = model.to(device)
print(model)
summary(model, torch.zeros((1, in_channels, 224, 224)).to(device))