In the last article , I left you a thought question: how to design sub-database and sub-table?
In today's article, let's talk about how to plan and design sub-database and sub-table, and what issues to consider.
introduction
To solve the problem of massive data, you must use a distributed storage cluster, because MySQL is essentially a stand-alone database, so in many scenarios it is not suitable for storing data above the terabyte level.
However, most of the major e-commerce companies still cannot abandon MySQL for their online transaction business, such as order and payment related systems. The reason is that only relational databases such as MySQL can provide financial-level business guarantee . For distributed transactions, the so-called distributed transactions provided by the new distributed databases are more or less bloody, and currently cannot meet the data consistency requirements of these transactional systems.
Since MySQL cannot support such a large amount of data and such a high concurrency, it must be used, how to solve this problem? Still follow the idea we told you in the previous article, sharding, that is, splitting the data. 1TB of data cannot be supported by one library. I split it into 100 libraries, and each library has only 10GB of data. Isn’t that all right? This split is the so-called MySQL sub-database sub-table.
However, the idea is that it is true that sub-database sub-table is not easy in practice, and there are many problems that need to be considered and solved.
How to plan sub-database and sub-table?
Let's take the order table as an example. The first question that needs to be considered is whether to sub-database or sub-table? As for the sub-database, it is to split the data into different MySQL databases, and the sub-table is to split the data into multiple tables in the same database.
Before considering whether it is a sub-database or a sub-table, we need to clarify a principle first:
That is, if you can’t dismantle it, you don’t dismantle it, and if you can dismantle it less, you don’t dismantle it more.
The reason is also very simple. The more scattered you split the data, the more troublesome it will be to develop and maintain, and the greater the probability of system failure.
Based on this principle, let's think about when it is suitable to divide the table, and when it is necessary to divide the database?
The purpose of our sub-database sub-table is to solve two problems:
- The problem is that the amount of data is too large and the query is slow. The "query" we talk about here is mainly the query and update operations in the transaction, because the read-only query can be solved by separating the cache and the master-slave. To solve the slow query, just reduce the total amount of data in each query, that is to say, sub-table can solve the problem.
- It is to deal with the problem of high concurrency. In response to the idea of high concurrency, if a database instance can't support it, the concurrent requests are distributed among multiple instances. Therefore, to solve the problem of high concurrency, it is necessary to divide the database.
Simply put, if the amount of data is large, divide the table; if the concurrency is high, divide the database.
Under normal circumstances, our solution needs to divide databases and tables at the same time. At this time, how many databases and how many tables to divide can be calculated by the estimated concurrency and data volume respectively. The estimated amount is recommended to be the existing 5-10 times the amount.
In addition, I personally do not recommend that you consider the issue of secondary expansion in the plan, that is, consider the future data volume, and how to split the data again after filling up the capacity of the sub-database and sub-table design.
Now that technology and business are changing so fast, by the time it really comes, the business has already changed, and new technologies may have come out. There is a high probability that the secondary expansion plan you designed before will not be used, so there is no need for this. Increase the complexity of the program.
It is emphasized here that the simpler the design, the higher the reliability.
How to choose a Sharding Key?
Another important issue in sub-database sub-table is to select an appropriate column or attribute as the basis for sub-table. This property is generally called Sharding Key. Like the method of archiving historical orders we mentioned in the last article , its Sharding Key is the order completion time. Every time you query, you must include this time in the query conditions. Our program knows that the data before three months is checked in the order history table, and the data within three months is checked in the order table. This is a simple time range Algorithm for sharding.
It is very important to choose the appropriate Sharding Key and sharding algorithm, which directly affects the effect of sharding database and sharding tables. Let's first talk about how to choose a Sharding Key.
The most important reference factor for choosing this Sharding Key is how our business accesses data.
For example, we use the order ID as the Sharding Key to split the order table. After splitting, if we check the order according to the order ID, we need to first calculate the order I want to check based on the order ID and the sharding algorithm. On the shard, that is, in which database and which table, and then go to that shard to execute the query.
However, when I open the "My Orders" page, its query condition is the user ID. There is no order ID here, so there is no way to know which shard the order we want to check is on, and there is no way to check it. Of course, if you want to search forcibly, you can only search all the fragments once, and then merge the query results. This is very troublesome, and the performance is very poor, and you cannot page.
What if the user ID is used as the Sharding Key? You will also face the same problem. When you use the order ID as the query condition to check the order, there is no way to find out which shard the order is in. The solution to this problem is to use the last few digits of the user ID as part of the order ID when generating the order ID. For example, it can be stipulated that the 10th-14th digits of the 18-digit order number are the last four digits of the user ID. bit, so that when you query by order ID, you can find the shard according to the user ID in the order ID.
Then our system's way of querying orders is definitely not just by order ID or by user ID. For example, what merchants want to see are the orders of their own stores, as well as various orders-related reports. For these query requirements, once we sub-database and sub-table the order, there is no way to solve it. then what should we do?
The general approach is to synchronize order data to other storage systems and solve problems in other storage systems. For example, we can build a read-only order library with the store ID as the Sharding Key, which is specially used by merchants. Or, synchronize the order data to HDFS, and then use some big data techniques to generate order-related reports.
So you see, once the database and table are divided, the query ability of the database will be greatly limited. The simple query before may not be realized after the database and table are divided.
You have to remember one sentence: sub-database and sub-table must be the last trick we come up with when the amount of data and concurrency are so large that all tricks (such as caching) are no longer easy to use.
How to choose a sharding algorithm?
For example, can we use the order completion time as the Sharding Key? For example, I have 12 shards, one shard per month, which is much more compatible with queries. After all, it is relatively easy to include a time range in the query conditions so that the query only falls on a certain shard. Just force the user to specify a time range on the query interface.
There is a big problem with this approach. For example, it is March now, so basically all queries are concentrated on this shard in March, and the other 11 shards are idle. This is not only a waste of resources, but it is very likely that your March That shard can't resist almost all concurrent requests. This issue is the "hot issue".
In other words, we hope that concurrent requests and data can be evenly distributed to each shard, and hot spots should be avoided as much as possible. This is an important factor to consider when choosing a sharding algorithm. Generally, there are only a few commonly used sharding algorithms, and the method of sharding according to the time range just mentioned is one of them.
Fragmentation based on ranges is prone to hotspot issues, and is not suitable as a fragmentation method for orders. However, the advantages of this fragmentation method are also very prominent, that is, it is very friendly to queries. Basically, you only need to add a query condition of a time range. How to check in the original, and how to check after fragmentation. Range sharding is especially suitable for ToB systems that have a very large amount of data but a small amount of concurrent access. For example, the monitoring system of a telecom operator may collect the signal quality of all mobile phones and then do some analysis. The amount of data is very large, but the users of this system are the staff of the operator, and the amount of concurrency is very small. This case is a good fit for range sharding.
Generally speaking, the order table adopts a more uniform hash sharding algorithm. For example, if we want to divide into 24 shards and select the Sharding Key as the user ID, the algorithm for us to decide which shard a user’s order should fall on is to divide the user ID by 24, and the remainder is the shard film number. This is the simplest modulo algorithm, which can generally meet most requirements. Of course, there are also some more complex hashing algorithms, such as consistent hashing, which can also be used in special cases.
One thing to note is that the prerequisite for the hash sharding algorithm to be evenly distributed is that the last few digits of the user ID must be evenly distributed. For example, when you generate a user ID, you customize a user ID rule. The last digit of 0 is male and 1 is female. Such user IDs may not be hashed uniformly, and hot spots may appear.
There is also a fragmentation method: look-up table method. The look-up table method actually does not have a sharding algorithm. It is determined which shard a certain Sharding Key falls on, and it is all allocated manually, and the allocation result is recorded in a table. Every time you execute a query, first go to the table to check which shard the data you are looking for is in.
The advantage of the table lookup method is that it is flexible and can be divided in any way. If you cannot evenly divide the data with the above two sharding algorithms, you can use the table lookup method to artificially divide the data evenly. Another advantage of the table lookup method is that its fragmentation can be changed at any time. For example, if I find that a certain shard is already a hotspot, then I can split this shard into several shards, or move the data of this shard to other shards, and then modify the shard mapping table. Data splitting can be done online.
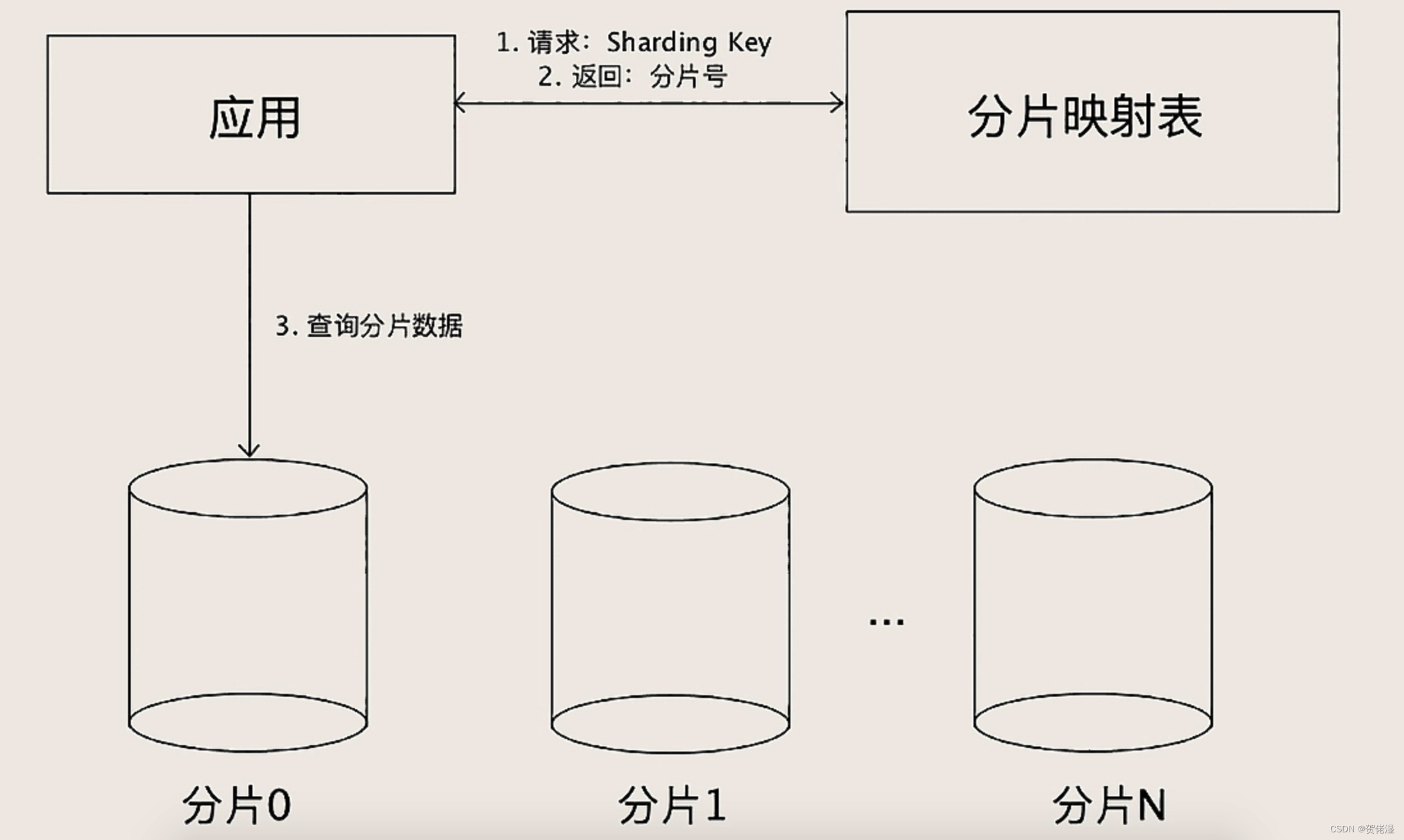
But what you need to pay attention to is that the data in the shard mapping table itself should not be too much, otherwise the table will become a hotspot and a performance bottleneck instead. Compared with the other two sharding algorithms, the table lookup method has the disadvantage of requiring secondary query, which is more complicated to implement and slightly slower in performance. However, the shard mapping table can be cached to speed up queries, and the actual performance will not be much slower.
Summarize
For stand-alone databases like MySQL, sub-databases and tables are the last resort to cope with massive data and high concurrency. After sub-databases and tables are divided, there will be very large restrictions on data queries.
The number of libraries to be divided needs to be estimated by the amount of concurrency, and the number of tables to be divided needs to be estimated by the amount of data. When choosing a Sharding Key, it must be compatible with the most commonly used query conditions of the business, so that the query falls in one shard as much as possible. After the sharding is not compatible, the data can be synchronized to other storage to solve this problem.
We commonly use three sharding algorithms. Range sharding is prone to hot spots, but it is more friendly to queries and is suitable for scenarios with low concurrency; hash sharding is easier to distribute data and queries evenly among all shards; query The table method is more flexible, but slightly less performant.
For the sub-database and sub-table of the order table, the user ID is generally used as the Sharding Key, and the hash sharding algorithm is used to evenly distribute the user order data. In order to support the query by order number, it is necessary to put the last few digits of the user ID into the order number.
Finally, it needs to be emphasized that the sharding-related knowledge we mentioned is not only applicable to the sub-database and sub-table of MySQL. When you use other distributed databases, you will also encounter how to shard and how to choose The principles of Sharding Key and sharding algorithm are the same, so the methods we mentioned are also common.
Thanks for reading, if you think this article has inspired you, please share it with your friends.
thinking questions
How can I avoid writing slow SQL?
Looking forward to, you are welcome to leave a message or contact online, discuss and exchange with me, "learn together, grow together".
previous article
recommended reading
- [Architecture] High availability and high concurrency system design principles
- [Summary] Summary of commonly used sub-database and sub-table schemes in Internet technology architecture
- Technological breakthrough, performance soaring tenfold: the reconstruction of the billion-level e-commerce platform reveals the secret
- When we talk about high concurrency, what are we talking about? How to really master the ability of high concurrency design?
- Microservice architecture practice - my experience sharing summary 2019 (system architect) architecture evolution process - from information flow architecture to e-commerce middle platform architecture
Series sharing
- Elasticsearch Tutorial
- Microservice architecture in practice
- Architectural Thinking Growth Series
- E-commerce system architecture design series
------------------------------------------------------
------------------------------------------------------
About me (personal domain name, more information about me)
My open source project collection Github
I look forward to learning, growing and encouraging together with everyone , O(∩_∩)O thank you
If you have any suggestions, or knowledge you want to learn, you can discuss and exchange with me
Welcome to exchange questions, you can add personal QQ 469580884,
Or, add my group number 751925591 to discuss communication issues together
Don't talk about falsehood, just be a doer
Talk is cheap,show me the code