Problem Description
When running the ORB_SLAM3 Example, I use the euroc dataset to run the example routine; I can guarantee that there is no problem with my path, and the txt and the .png files in the dataset are also corresponding, and the png files in the dataset can also be opened normally , but I always prompt me to read the file failed when I run:
./Examples/Monocular/mono_euroc ./Vocabulary/ORBvoc.txt ./Examples/Monocular/EuRoC.yaml ./datasets/V201 ./Examples/Monocular/EuRoC_TimeStamps/V201.txt

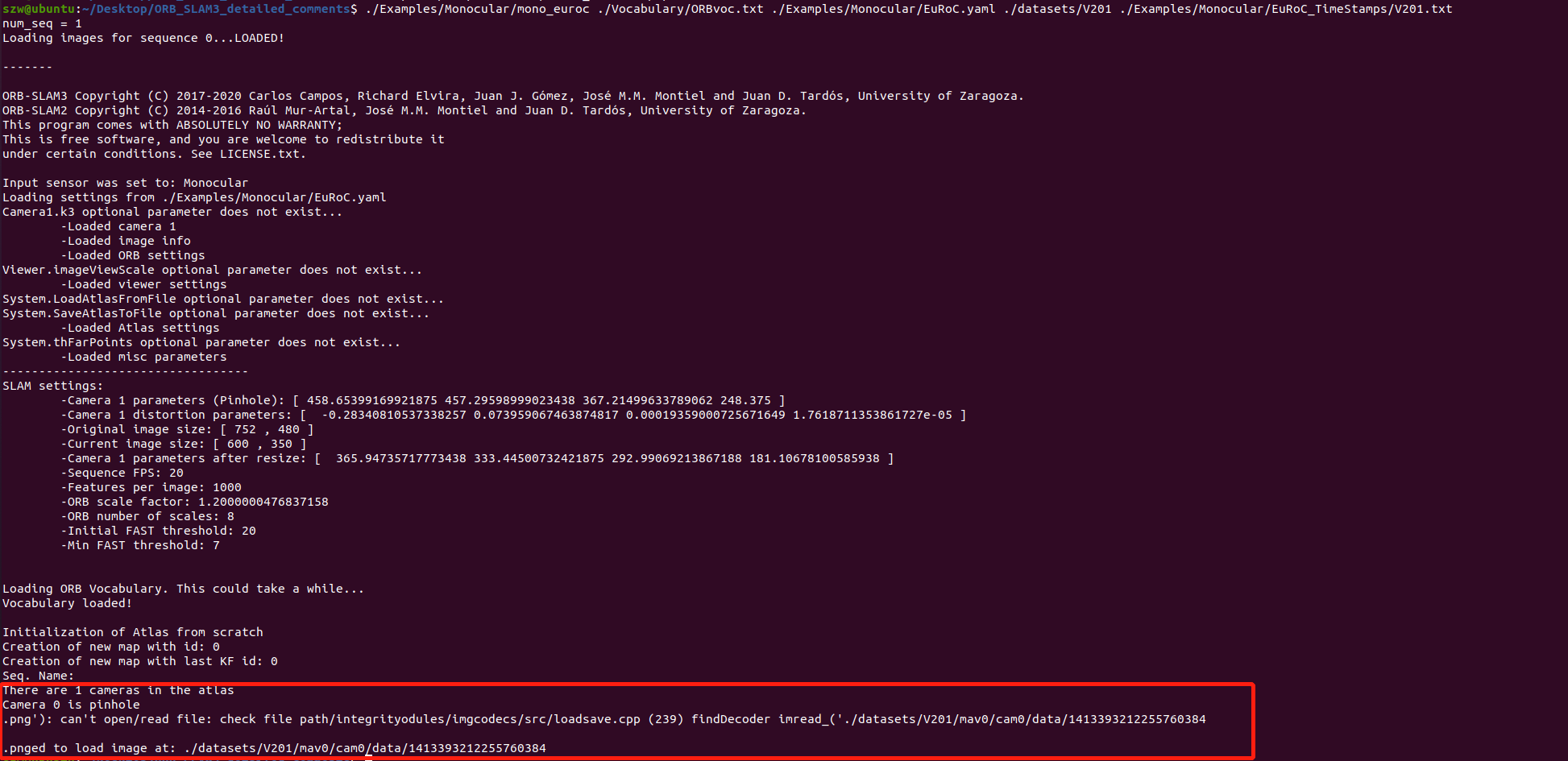
There is a problem with the display of the png format output here, I don’t know why ! !
problem causes
The author's virtual machine cannot download ORB_SLAM3, so it is downloaded in Windows, and then dragged to the virtual machine
Ubuntu and Windows .txt files differ in the following ways :
- Text encoding: Windows uses ANSI encoding by default, while Ubuntu uses UTF-8 encoding by default. This may cause some special characters to display differently when used across platforms.
- File end of line mark: Windows uses carriage return and line feed (\r\n) as the end of line mark, while Ubuntu uses line feed (\n) as the end of line mark. This may cause line breaks to be displayed differently when opening the same txt file on different platforms
After analyzing the error report, it was found that the output of the png path was abnormal. At first, it was suspected that the path was too long, but later it was found that it had nothing to do with the path length; then it may be that the file downloaded by Windows could not be read correctly after it was placed on.txt Ubunutu .
Vocabulary.txtThere is no problem because this file is decompressed in Ubuntu
Solution
Copy the text file directly, then create a new one .txtand paste it. There should
be a method for batch processing, but the author has not investigated