1 Basic concepts

2 Cache working principle
In a cache storage system, both cache and main memory are divided into blocks of the same size.
The main memory address is composed of block number B and block address W, and the cache address is composed of block number b and block address w.
When the CPU accesses the cache, the CPU sends the main memory address and puts it in the main memory address register. The block number B in the main memory address is transformed into the block number b of the cache through the address conversion unit, and puts it in the cache address register. At the same time, the address W in the block in the main memory address is directly loaded into the cache address register as the address w in the cache block. If the conversion is successful (also called cache hit), use the obtained cache address to access the cache and take it out from the cache. The data is sent to the CPU;
If the transformation is unsuccessful (cache miss), a cache failure message will be generated, and the main memory address will be used to access the main memory, a word will be read from the main memory and sent to the CPU, and a whole block of data including this word will be sent to the CPU. Read it from the main memory and load it into the cache. At this time, if the cache is full, some kind of cache replacement strategy should be used to transfer the uncommonly used blocks to the corresponding blocks in the main memory to make room for new ones. Called block.
Due to the locality of the program, each time a block fails, a block (composed of multiple words) is transferred into the cache, which can improve the hit rate of the cache.
3 Cache address mapping and transformation method
The mapping and conversion of addresses are closely related, and what kind of address mapping method is adopted must have an address conversion method corresponding to this mapping method.
No matter what address mapping method and address conversion method is used, the main memory and cache must be divided into storage units of the same size, and each storage unit is called a "block". When performing address mapping and conversion, the block is used as the carried out by the unit. There are three commonly used mapping methods and transformation methods:
- ■ Fully associative mapping method
Any block in the main memory can be mapped to any block in the cache. - ■ In the direct mapping method,
a block in the main memory can only be mapped to a specific block in the cache. Assuming that the block number of the main memory is B, the block number of the cache is b, and the total number of blocks in the cache is Cb, the mapping between them The relationship can be expressed by the following formula:
b = B mode Cb - ■ Group associative mapping method
In this associative address mapping and transformation method, the main memory and cache are divided into groups (sets) of the same size, and each group consists of the same number of blocks.
The direct mapping method is adopted from the main memory group to the cache group. After the mapping relationship between the main memory group and the cache group is established, the full associative mapping method is used inside the two corresponding groups.
In the ARM processor, the main memory and the cache adopt the group-associative address mapping and transformation method. If the block size of the cache is 2L, the bit[31:L] of each address in the same block is the same.
If the size of the group in the cache (the number of blocks contained in each group) is 2S,
the bit[L+S-1:L] of the virtual address is used to select a group in the cache,
while other bits in the virtual address [31 :L+S] contains some flags.
The number of blocks in each group of the cache is called set-associativity. When the set-associativity is equal to the total number of blocks in the cache, the corresponding mapping method is the full associative mapping method;
When the group capacity is equal to 1, the corresponding mapping method is the direct mapping method;
When the group capacity is other values, it is called group associative mapping.
In the group associative mapping mode, the cache size CACHE_SIZE (number of bytes) can be calculated by the following formula:
CACHE_SIZE = LINELEN*ASSOCIATIVITY*NSETS
in,
- LINELEN is the cache block (line) size;
- ASSOCIATIVITY is the group capacity;
- NSETS is the number of cache groups.
4 Cache classification
Cache can be classified according to the following three methods according to different classification standards.
- 1) Data cache and instruction cache
- ● Instruction cache: cache used for instruction prefetching.
- ● Data cache: the cache used when reading and writing data.
If the instruction cache and the data cache in a storage system are the same cache, it is said that the system uses a unified cache. On the contrary, if it is separated, it is said that the system uses an independent cache; if the system only contains instruction cache or data cache, then it can be used as an independent cache when configuring the system.
Using independent data cache and instruction cache, instructions and data can be read in the same clock cycle without the need for a dual-port cache, but at this time, care must be taken to ensure the consistency of instructions and data.
-
2) Write-through cache and write-back cache
-
● Write back to the cache
When the CPU performs a write operation, the written data is only written into the cache and not into the main memory. Only when it needs to be replaced, the modified cache block is written back to the main memory. In the cache fast table of the update algorithm, there is generally a modification bit. When any unit in a block is modified, the modification bit of this block is set to 1, otherwise the modification bit of this block remains 0; when it is necessary to replace
this For one block, if the corresponding modification bit is 1, this block must be written into the main memory before a new block can be transferred, otherwise, just overwrite the block with the newly transferred block. -
● Write-through cache
When the CPU performs a write operation, it must write data into the cache and the main memory at the same time. In this way, there is no need to "modify the bit" in the fast table of the cache. When a block needs to be replaced, it is not necessary to change this
block Write back to the main memory, and the newly transferred block can immediately overwrite this block.
-
The advantages and disadvantages of write-back cache and write-through cache are compared in the following table.

-
3) Read-allocate cache and write-allocate cache
- ● Allocate cache when reading
When performing a data write operation, if the cache misses, the data is simply written into the main memory, and the cache content is prefetched mainly when the data is read.
- ● Allocate cache on write
When performing a data write operation, if the cache misses, the cache system will prefetch the cache content, read the corresponding block from the main memory to the corresponding location in the cache, and perform a write operation to write the data into the cache middle. For a write-through type cache, the data will be written to the main memory at the same time, and for a write-back type cache, the data will be written back to the main memory at an appropriate time.
Since the write operation allocation cache increases the number of cache content prefetch, increases the overhead of write operations, but at the same time may increase the hit rate of the cache, so the impact of this technology on the overall performance of the system is related to the number of read operations and write operations in the program related.
5 Cache replacement algorithm
random replacement algorithm
A pseudo-random number is generated by a pseudo-random number generator, and the cache block whose new block number is the pseudo-random number is replaced. This algorithm is very simple and easy to implement, but it does not consider the locality of the program, nor does it use the distribution of the block address flow in history, so the effect is poor. At the same time, this algorithm is not easy to predict the performance of the cache in the worst case.
Round Robin Algorithm
A logical counter is maintained, and the cache blocks to be replaced are sequentially selected by using the counter. This algorithm easily predicts the worst-case cache performance. However, when a small change occurs in the program, it may cause a sharp change in the average performance of the cache, which is an obvious shortcoming of it.
6 Cache content locking
The blocks "locked" in the cache will not be replaced in the normal cache replacement operation, but when the specific blocks in the cache are controlled by C7, such as when a specific block is invalidated, these are "locked" in the cache Blocks will be affected accordingly.
Use LINELEN to represent the block size of the cache, use ASSOCIATIVITY to represent the number of blocks in each cache group, and use NSETS to represent the number of groups in the cache.
The "locking" of the cache is performed in units of lock blocks (lockdown blocks). Each locked block includes one block in each group in the cache, so there can be at most ASSOCIATIVITY locked blocks in the cache, numbered 0~ASSOCIATIVITY-1.
The locked block numbered 0 includes block 0 in cache group 0, block 0 in group 1, and block 0 in ASSOCIATIVITY-1.
"N locked blocks are locked" means that the locked blocks numbered 0~N-1 are locked in the cache,
Lock blocks numbered N~ASSOCIATIVITY-1 can be used for normal cache replacement operations.
The operation steps to realize that the N-lock block is locked are as follows:
-
1) Ensure that no abnormal interruption occurs during the entire locking process, otherwise it must be ensured that the code and data related to the abnormal interruption are located in an uncachable storage area.
-
2) If the instruction cache or unified cache is locked, it must be ensured that the code executed during the locking process is located in a non-buffered storage area.
-
3) If the data cache or unified cache is locked, it must be ensured that the data involved in the locking process is located in a non-buffered storage area.
-
4) Make sure that the code and data to be locked are located in a cacheable storage area.
-
5) Make sure that the code and data to be locked are not already in the cache. This can be achieved by invalidating blocks in the corresponding cache.
-
6) For I=0 to N-1, repeat the following operations:
- a) Index=I is written to the C9 register of CP15. When using the lock register in B format, set L=1;
- b) The content of each cache block in the locked block I is prefetched from the main memory into the cache. For the data cache and the unified cache, the LDR instruction can be used to read a data located in the block, and the block is prefetched into the cache; For the instruction cache, the corresponding block is prefetched into the instruction cache by operating the C7 register of the CP15.
-
7) Write index=N into the C9 register of CP15, and set L=0 when using the lock register in B format. To unlock the N lock block, you only need to perform the following operations: write index=0 into the C9 register of CP15, and set L=0 when using the lock register in B format.
7 The content of B bit and C bit in MMU mapping descriptor
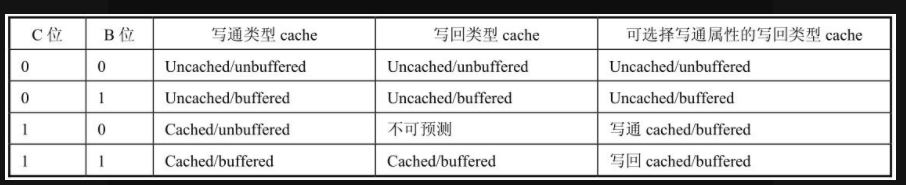
8 Cache and Writer Buffer programming interface
The Cache and Write Buffer operations in the ARM processor are realized by writing the C7 register of CP15. The instruction format for accessing the C7 register of CP15 is as follows:
mcr p15, 0, <rd>, <c7>, crm, <opcode_2>
The Cache and Write Buffer operation instructions in the ARM processor are as follows.
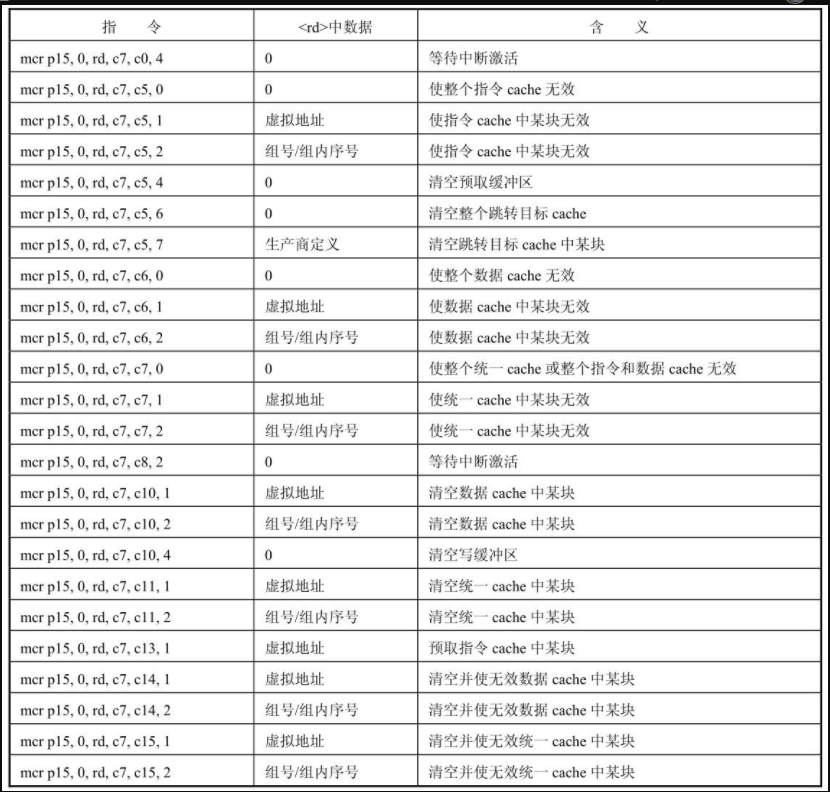
References:
- "Embedded System Linux Kernel Development Practical Combat"