Bert
First use unsupervised corpus to train the general model, and then conduct special training and learning for small tasks.
- ELMo
- Bert
- ERNIE
- Grover
- Bert&PALS
Outline
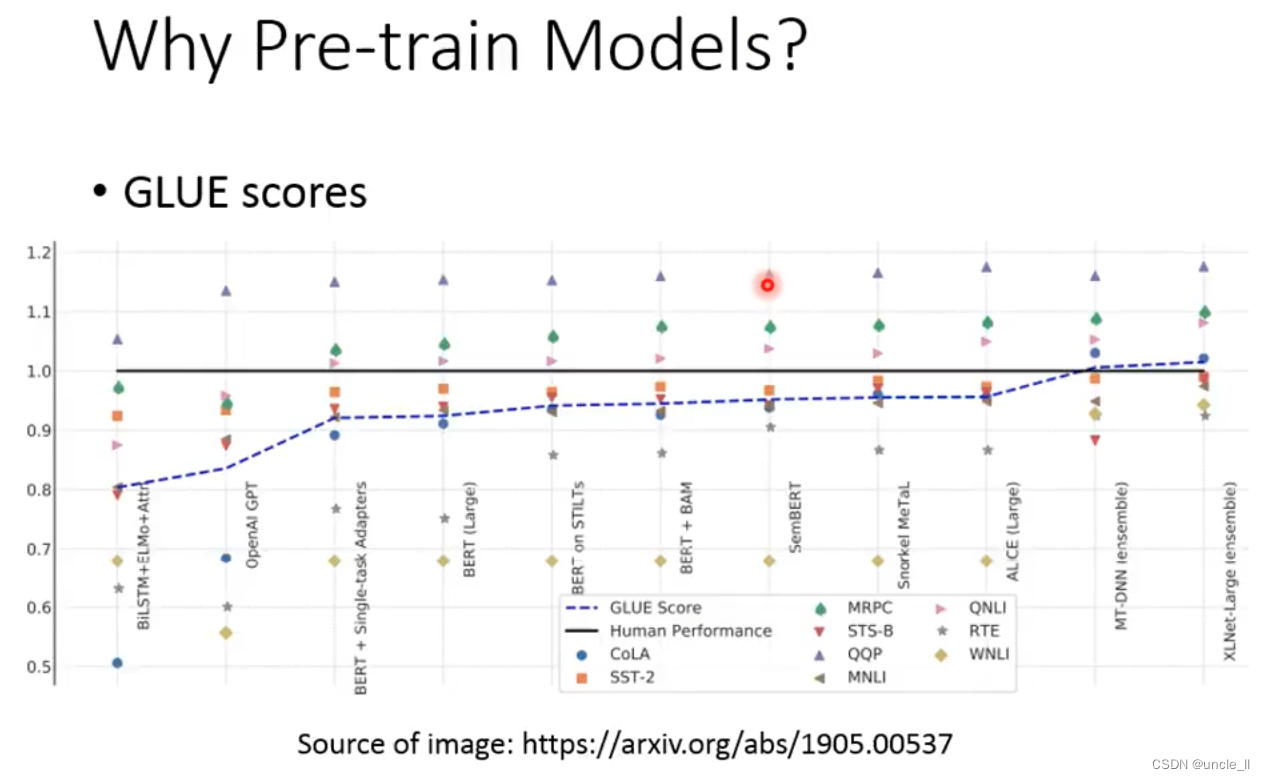
Pre-train Model

First introduce the pre-training model, the role of the pre-training model is to represent some tokens as a vector
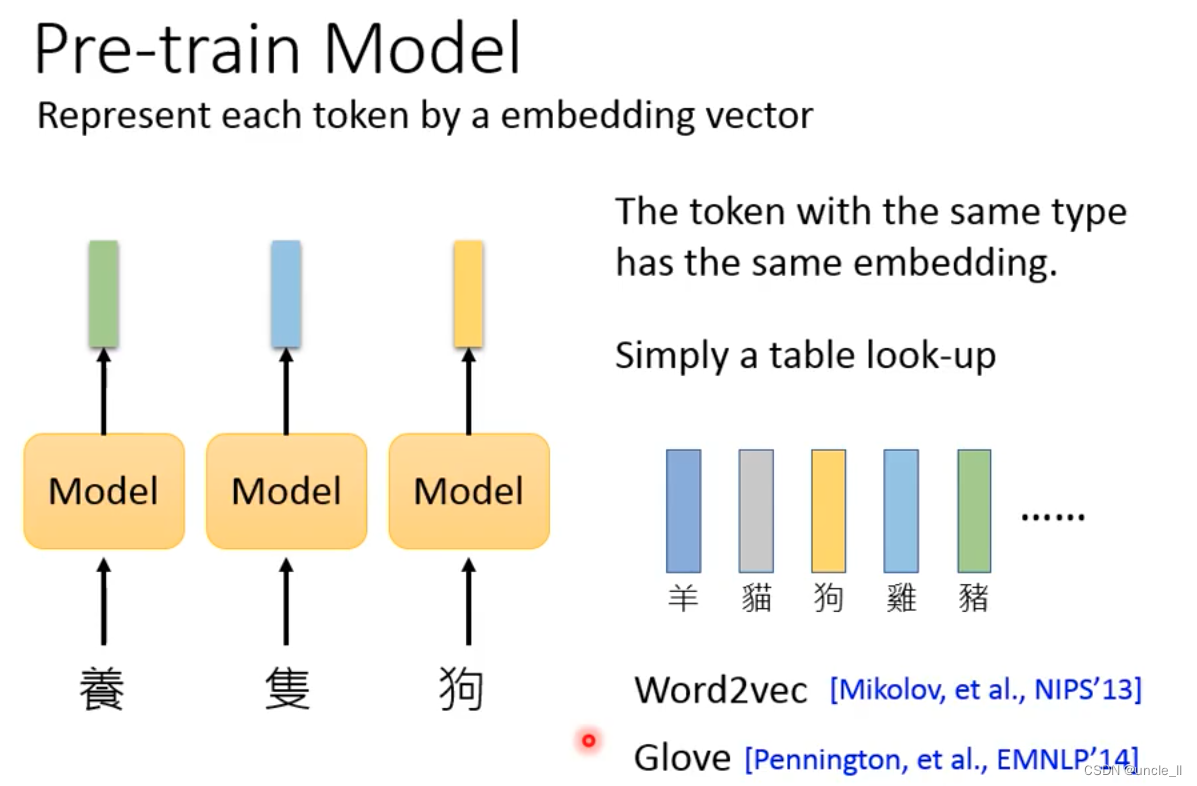
for example:
- Word2vec
- Glove
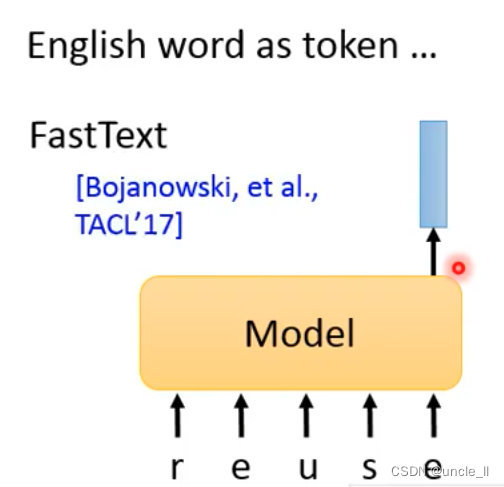
But for English, there are too many English words, and a single character should be encoded at this time:
- FastText
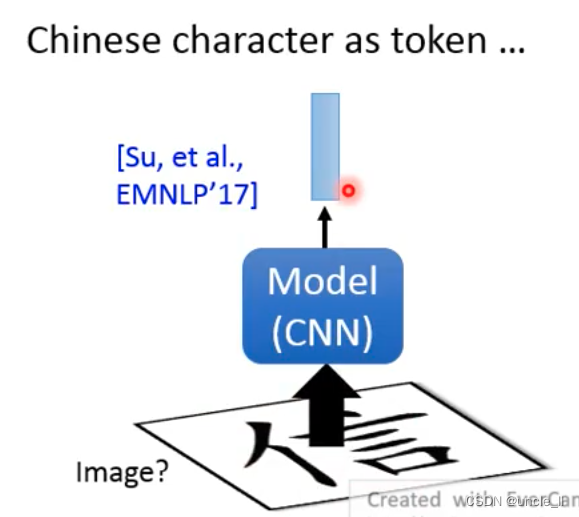
For Chinese, you can add radicals, or send Chinese characters as pictures to the network for output:
the problem with the above method will not consider that the same word in each sentence will have different meanings, and the same token will be generated:
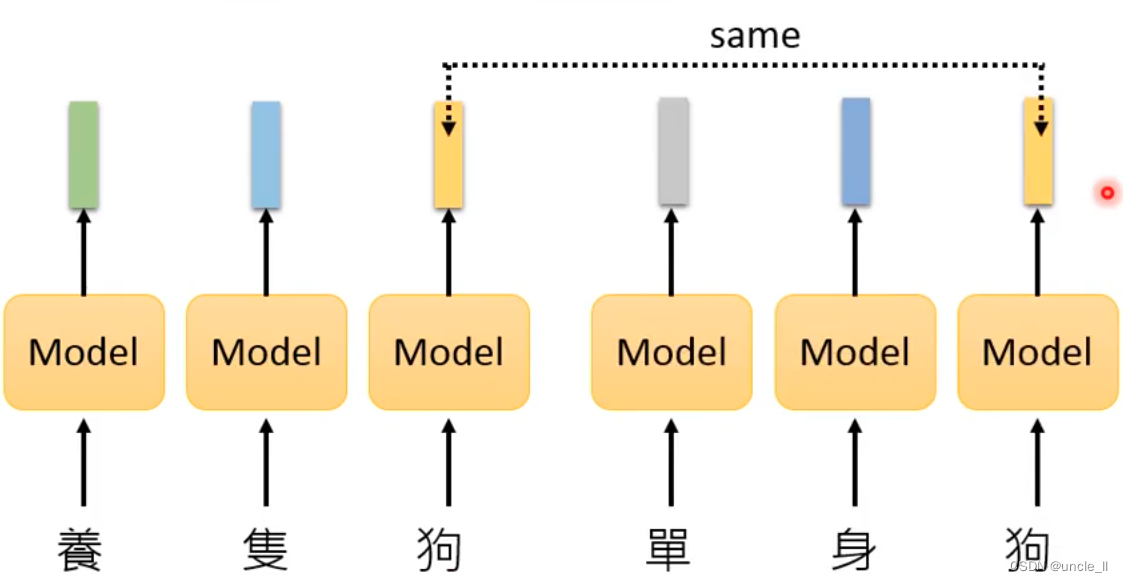
contextualized word embedding
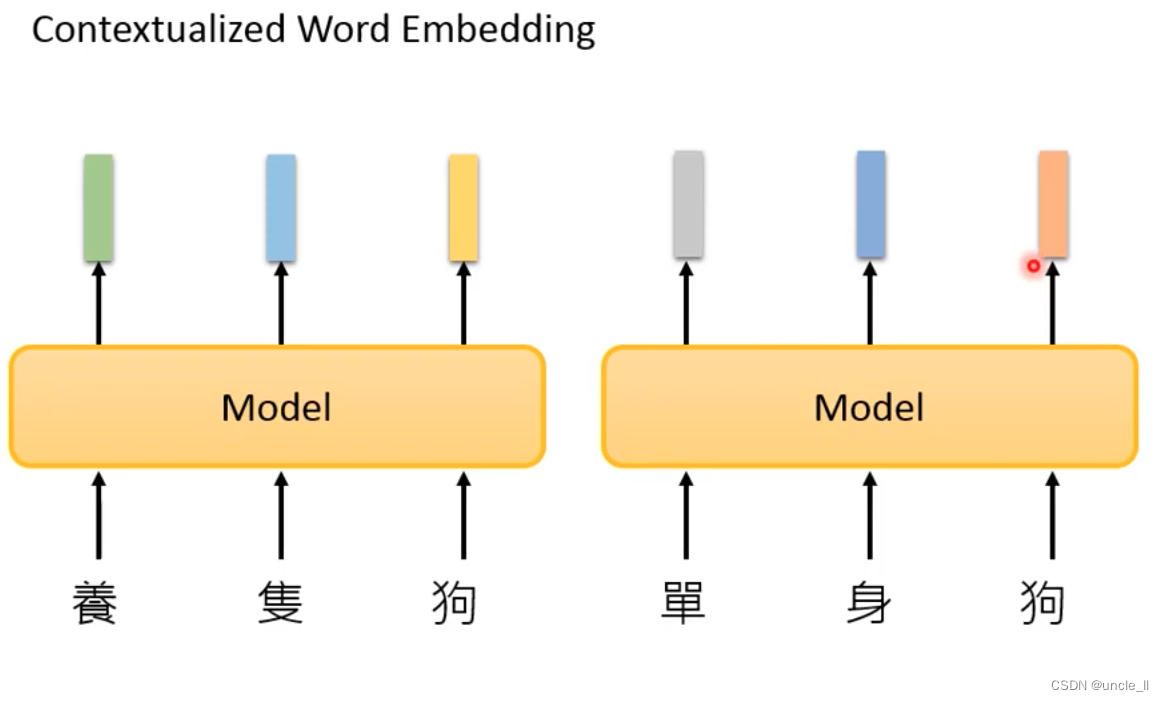
Similar to the encoder of the sequence2sequence model.
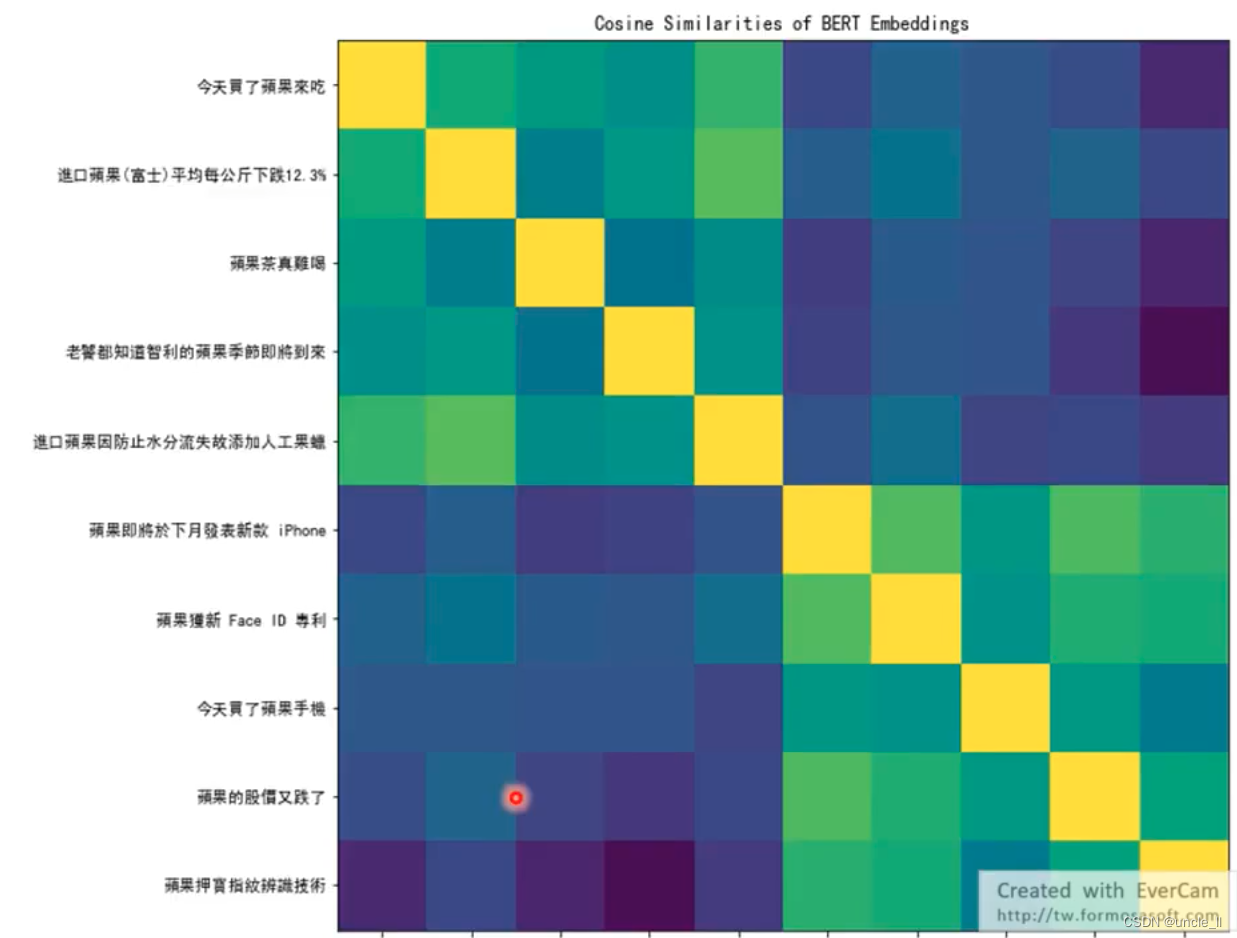
The same token gives different embeddings, and the above sentence contains the word Apple.
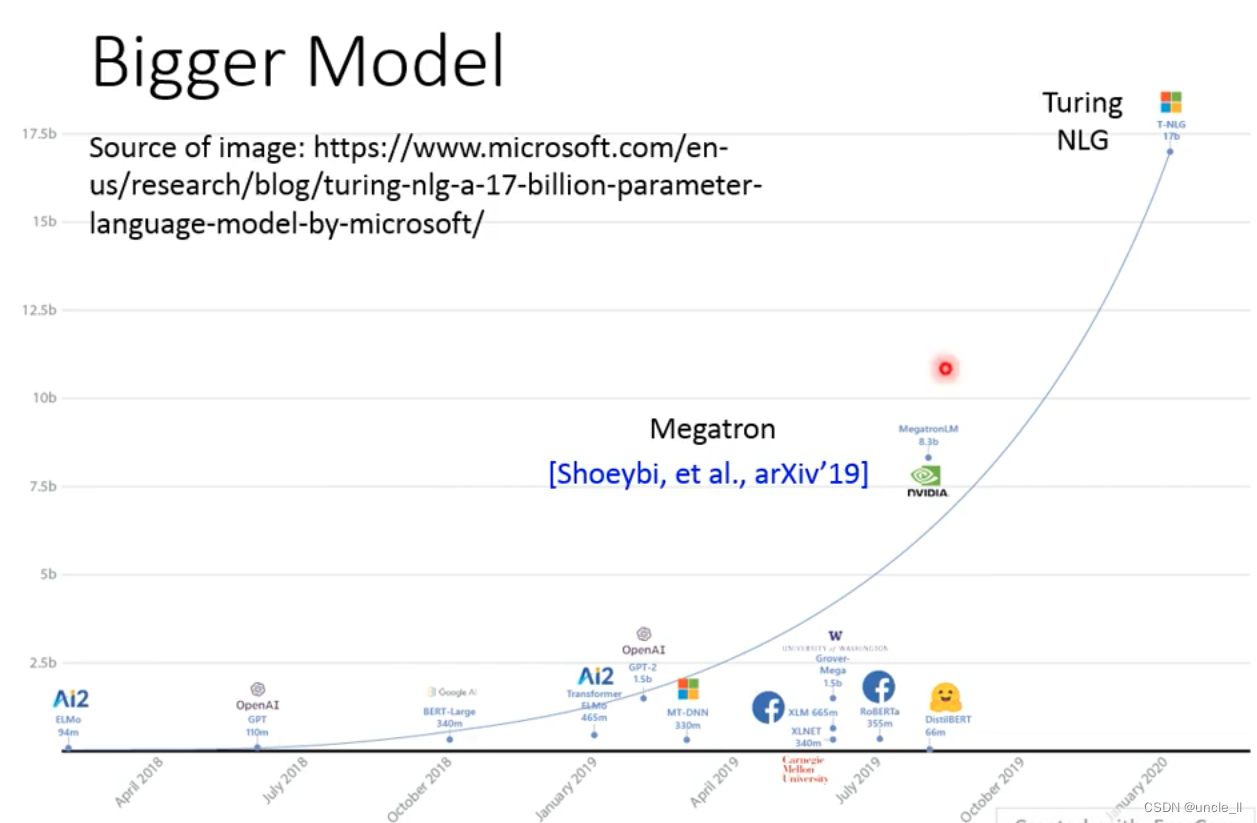
- Bigger Model
- Smaller Model

focuses on ALBERT, the technology to make the model smaller:
network architecture design:
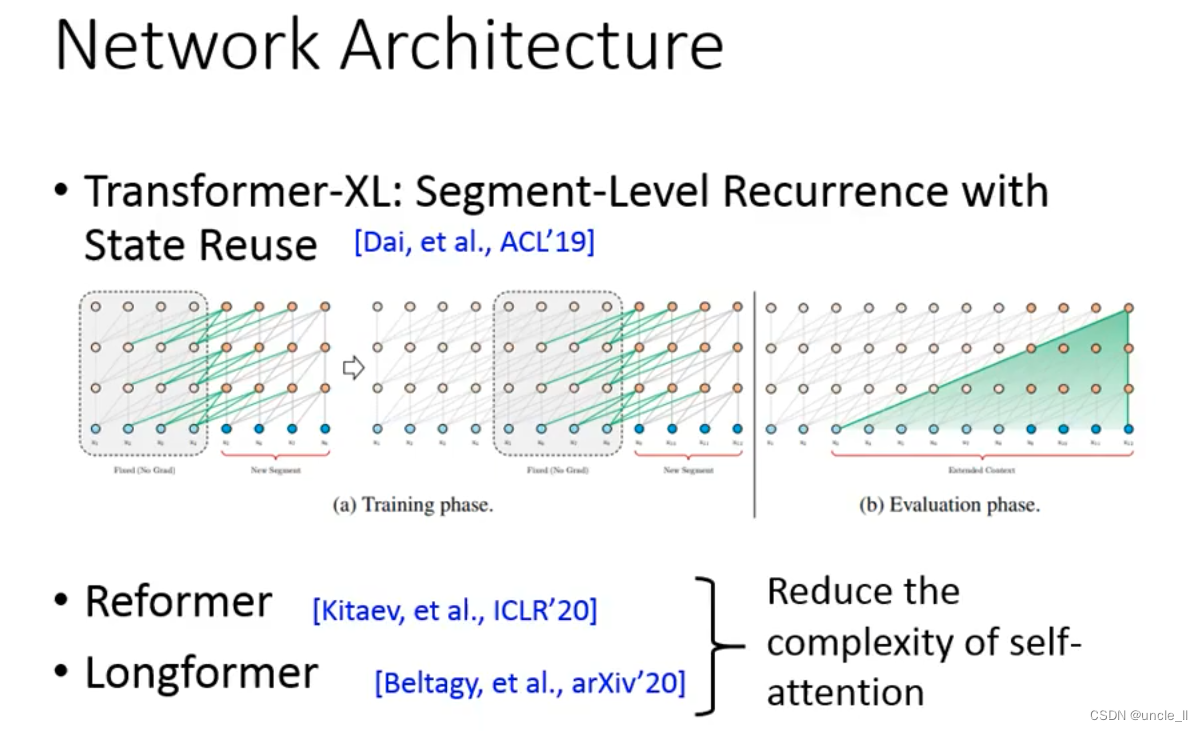
let the model read a long content, not just an article, it may be a book. - Transformer-XL
- Reformer
- Longformer
The computational complexity of self-attention is O ( n 2 ) O(n^2)O ( n2)
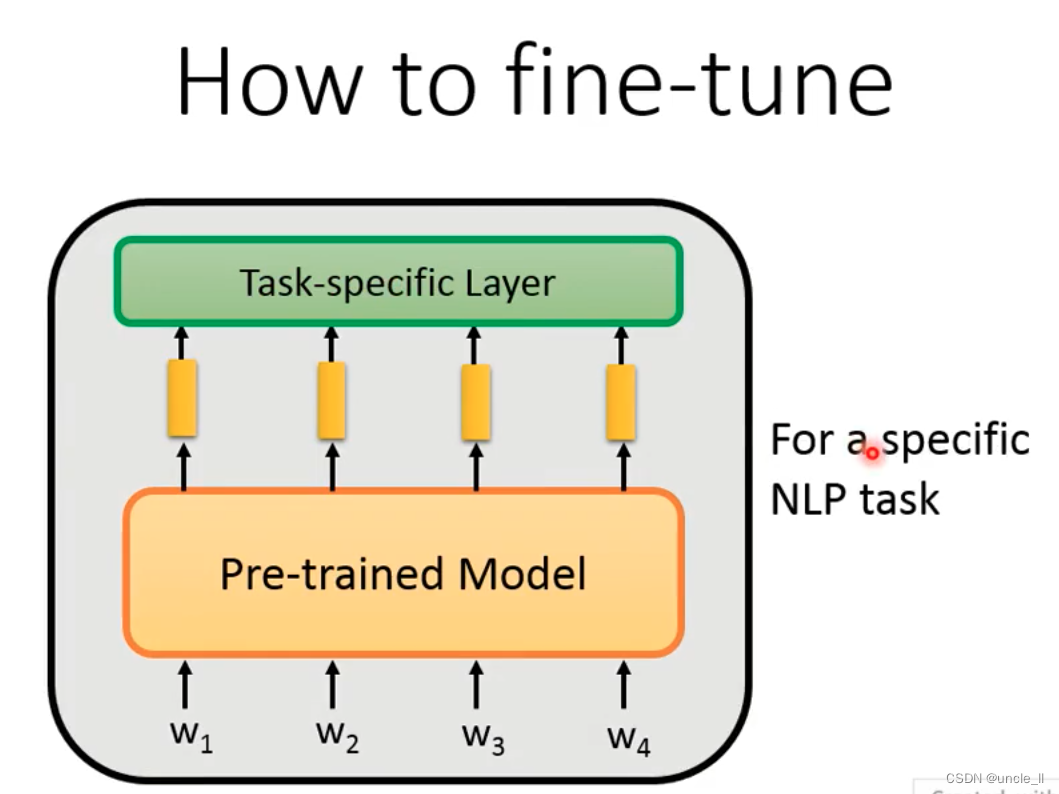
How to fine-tune
How to pre-train
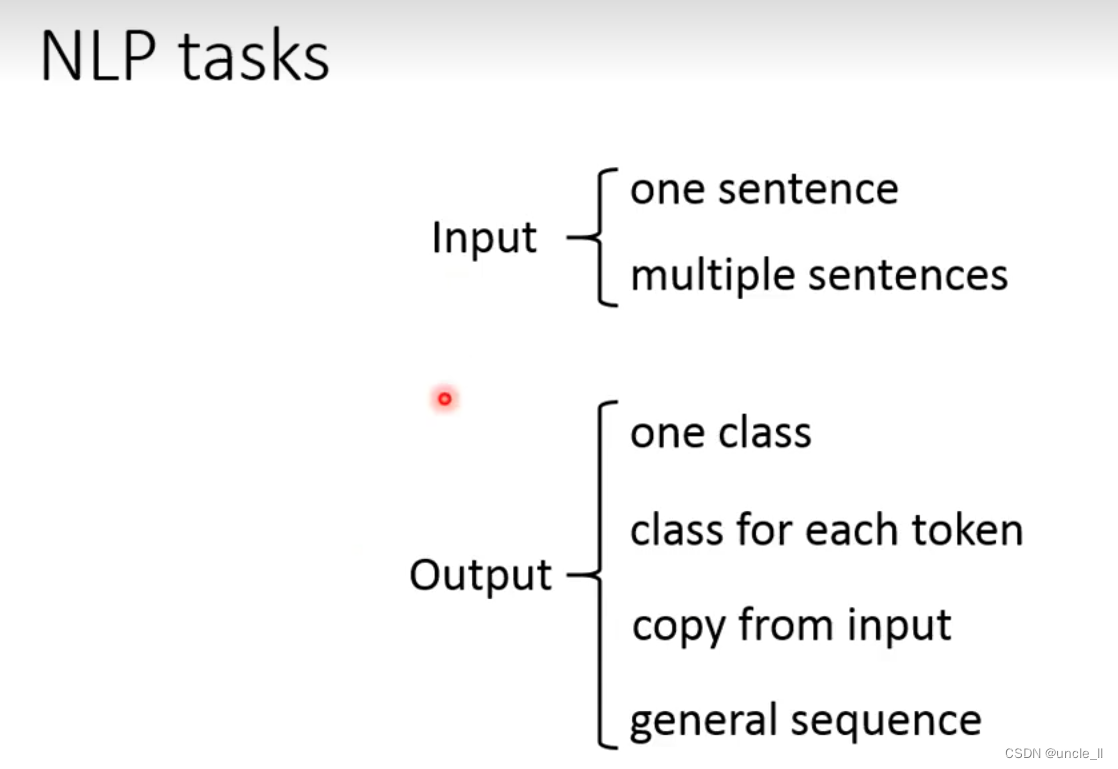
- Input:
one sentence or two sentences, [sep] for segmentation.
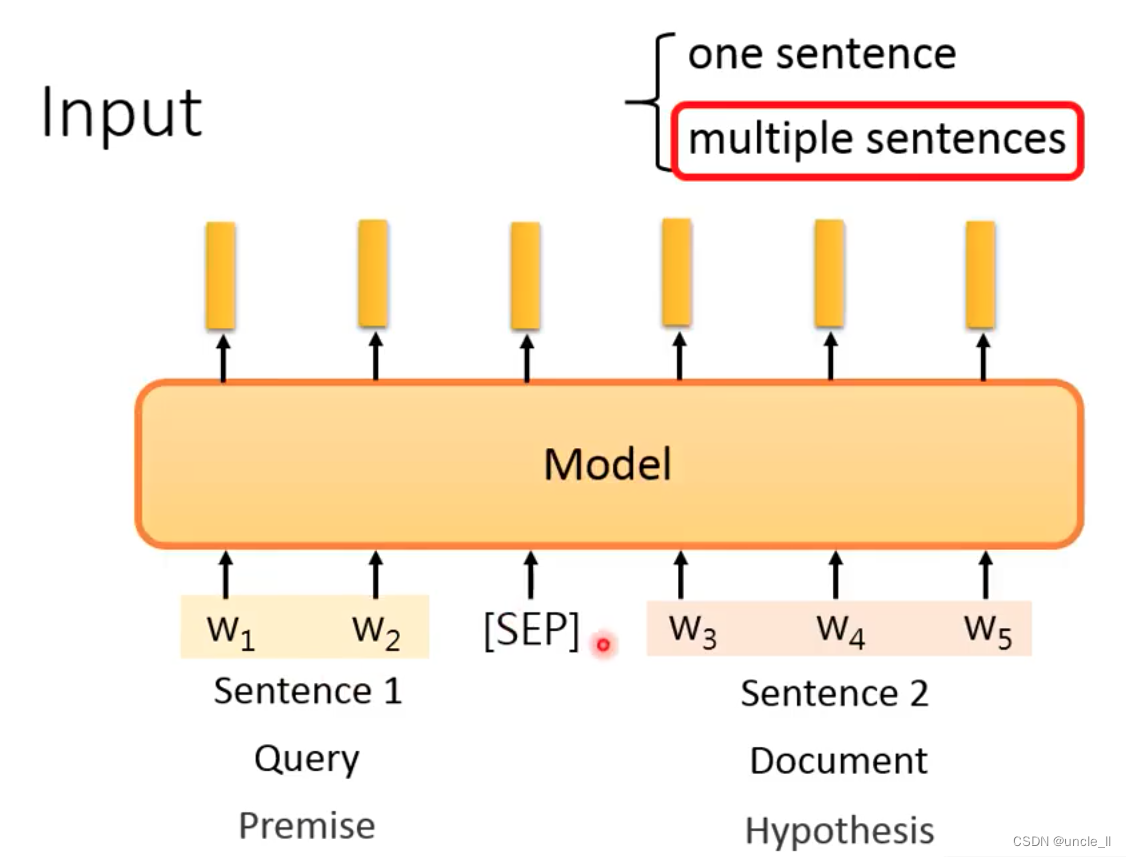
- Output part:
output a class, add a [cls], and generate an embedding related to the entire sentence.
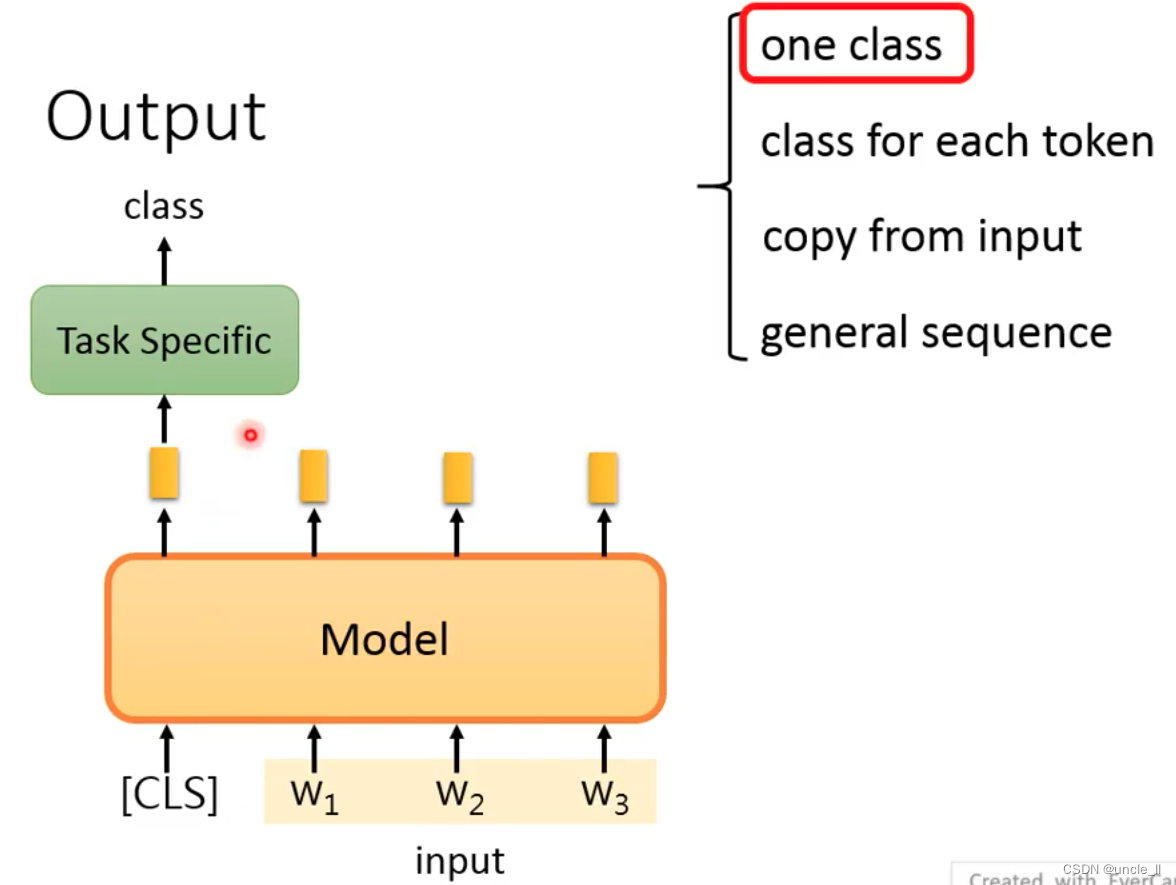
If there is no cls, it is to put all the embeddings together and send them to the model to get an output.
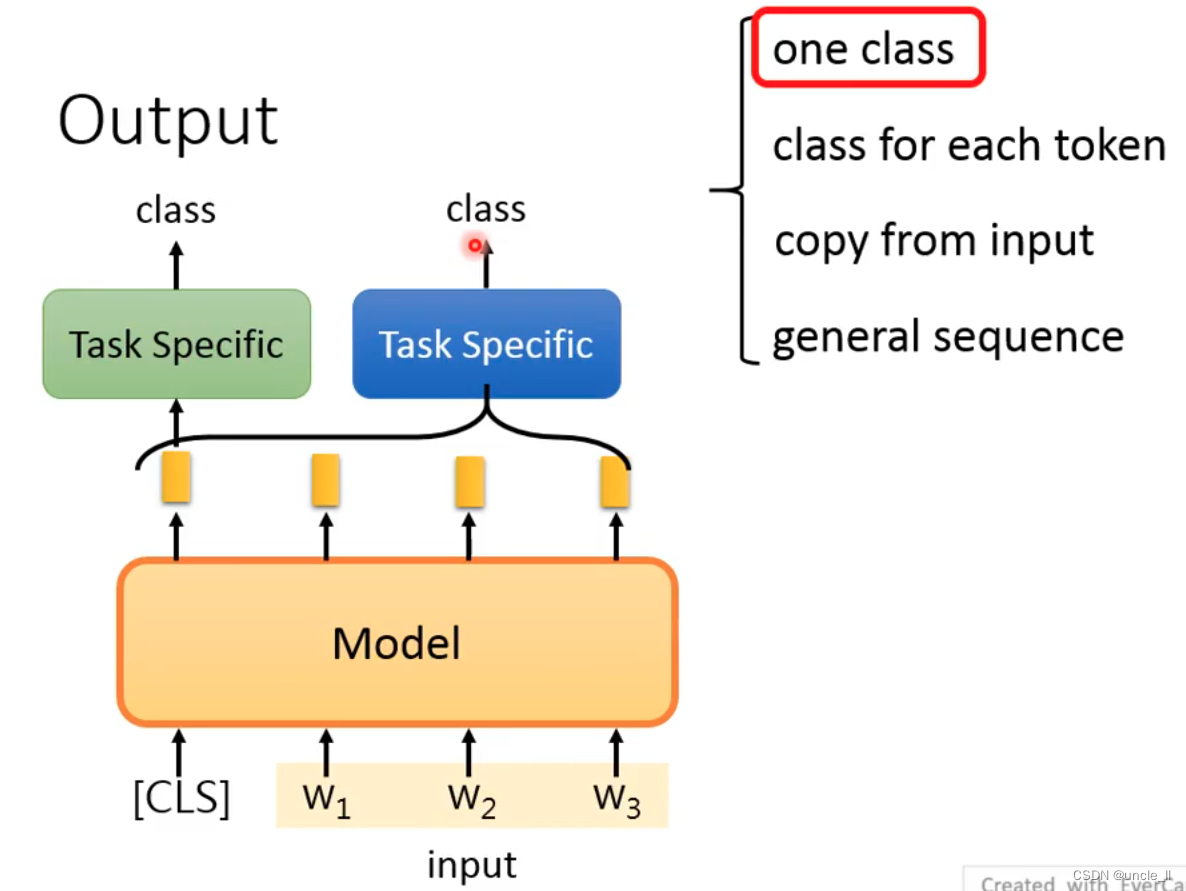
The second is to give each token a class, which is equivalent to a class for each embedding. How does
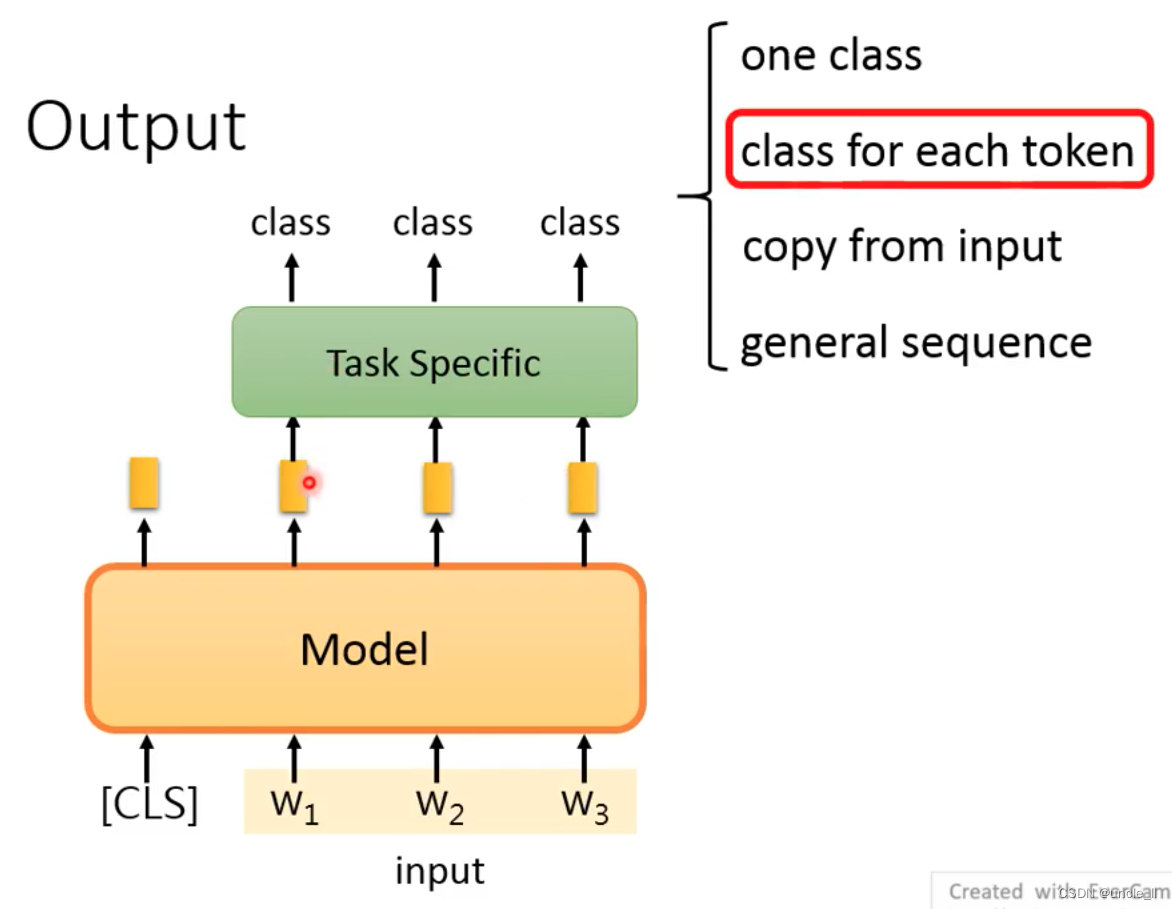
the Extraction-based QA

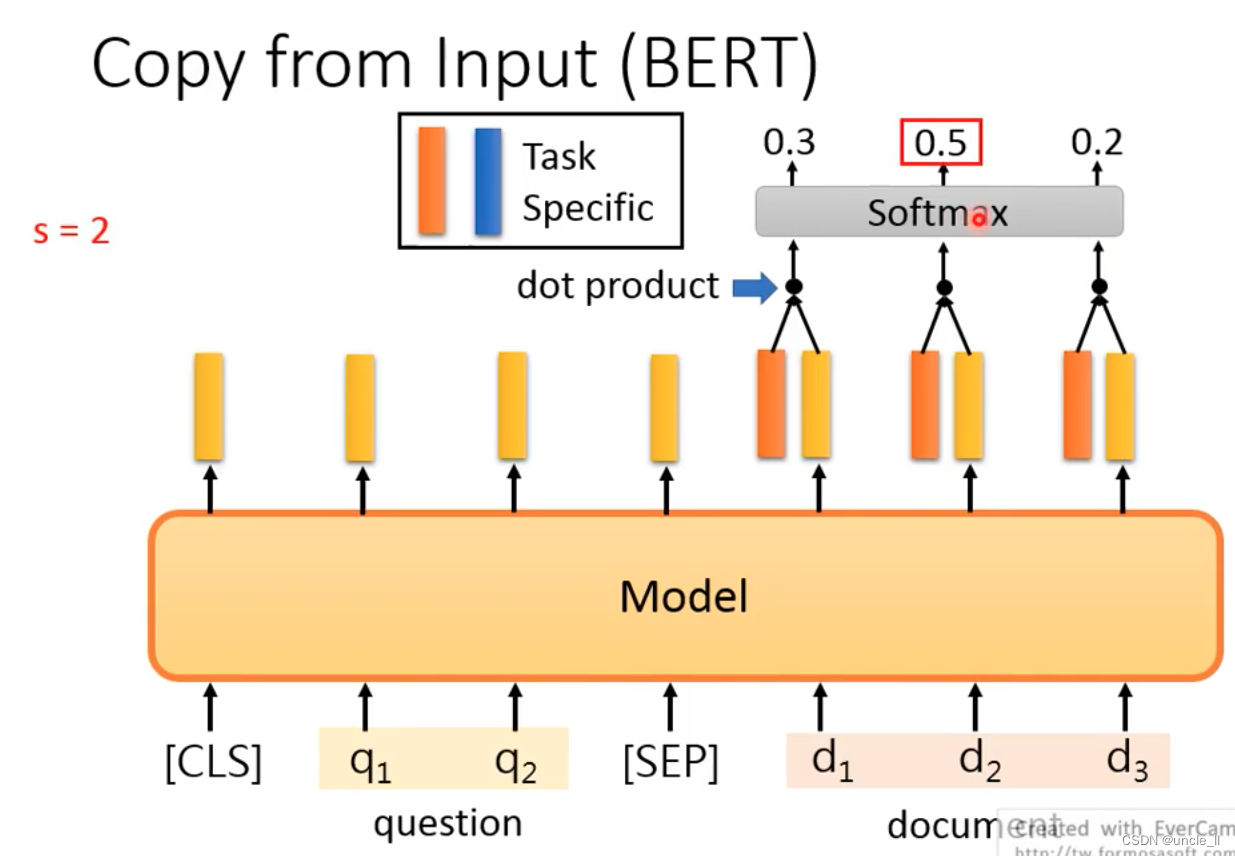
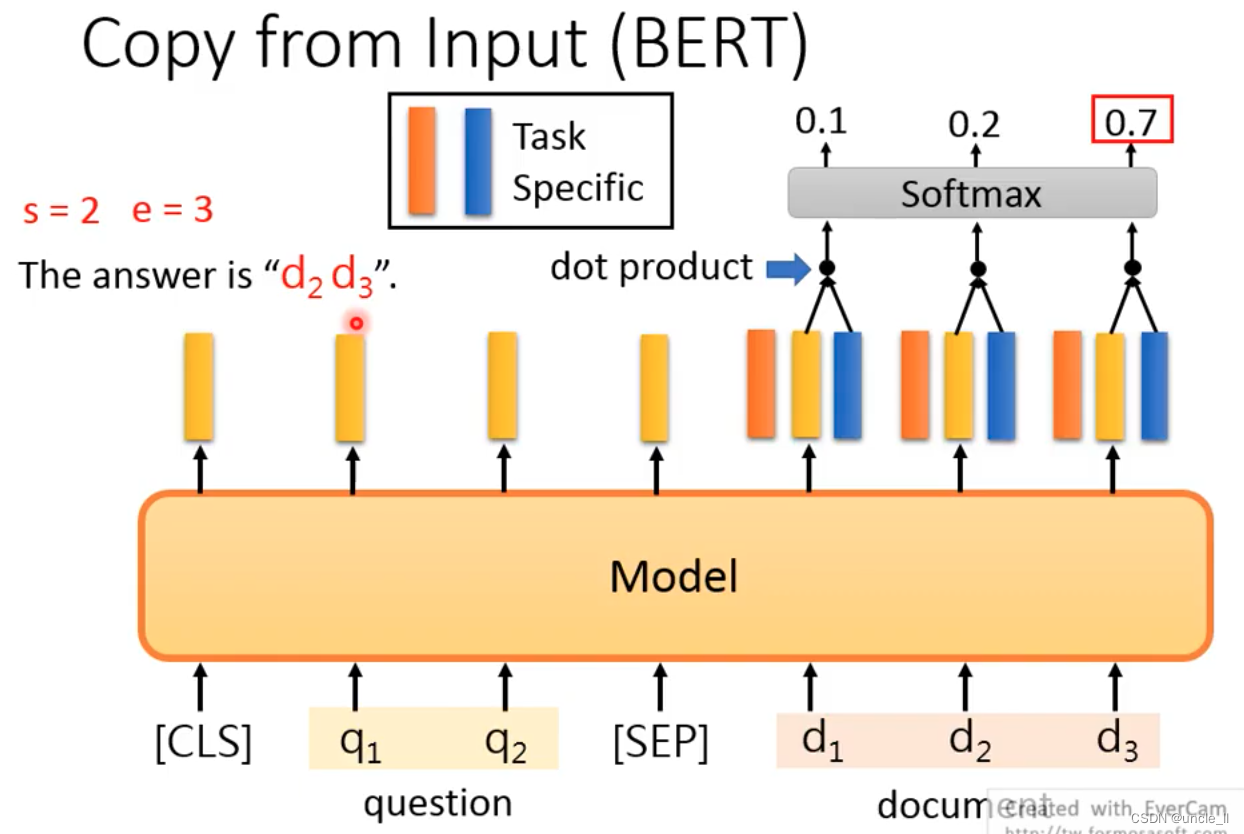
General Sequence be used to generate text? The encoder of the above structure cannot be used well
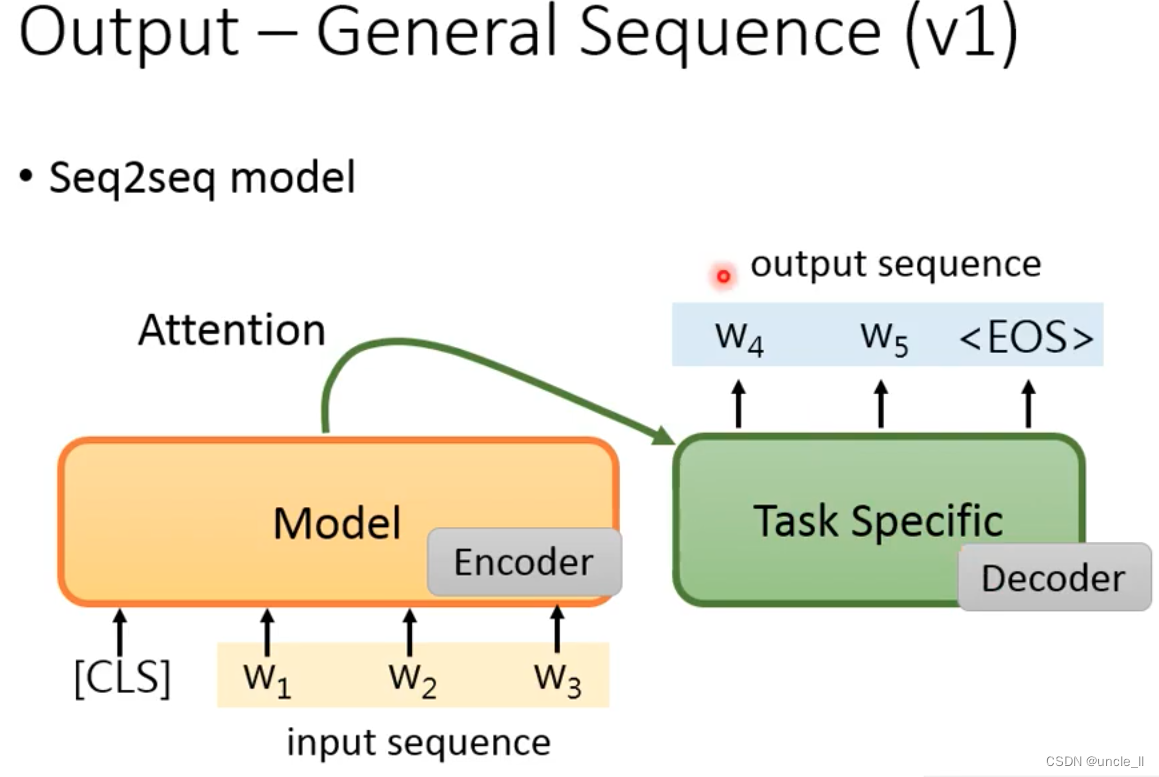
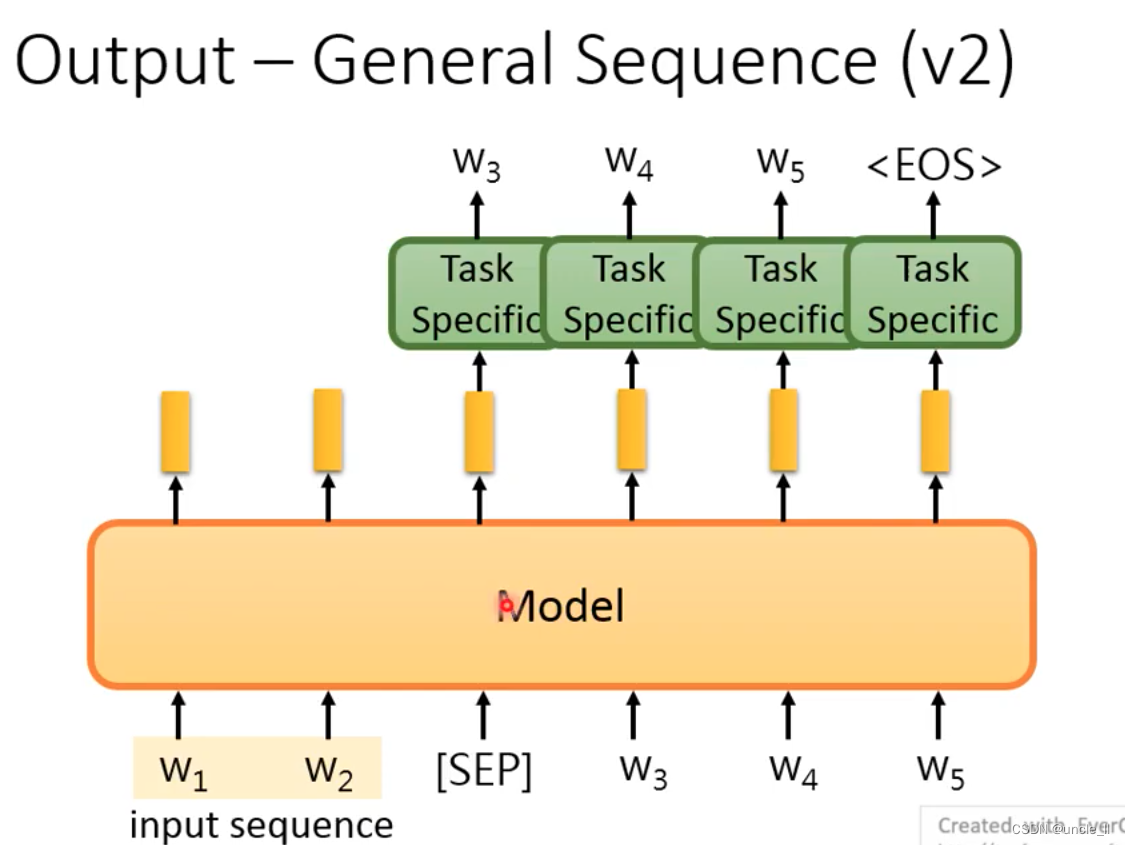
Use the pre-trained model as an encoder. After generating a word each time, send it to the model to continue generating until the eos terminator is generated.
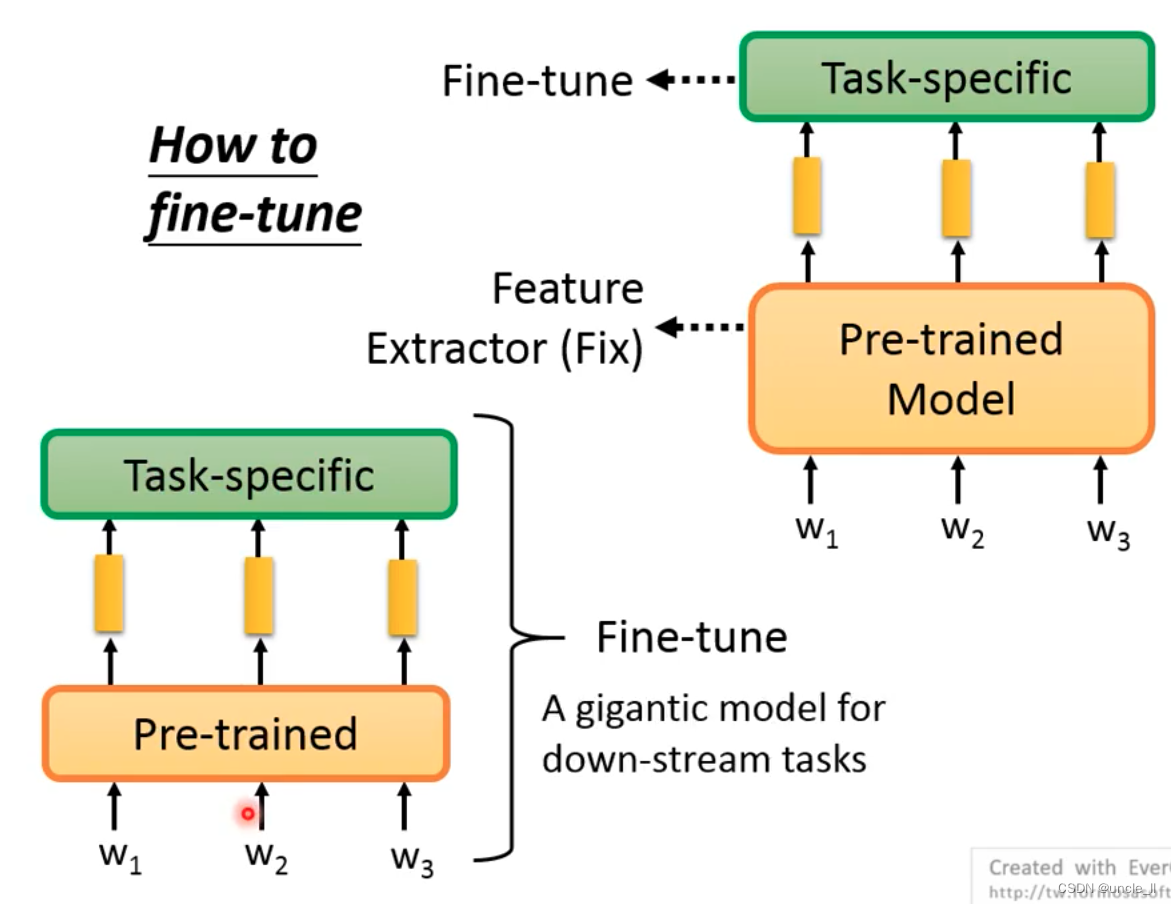
There are two methods of fine-tuning:
- The first one: the pre-training model does not move, and the embedding generated by it is trained for specific tasks, and only the upper model is fine-tuned;
- The second method: the pre-training model and the specific task model are combined for training, and the consumption will be higher; the
second method will achieve better results than the first method, but there are some problems encountered in training the entire model :
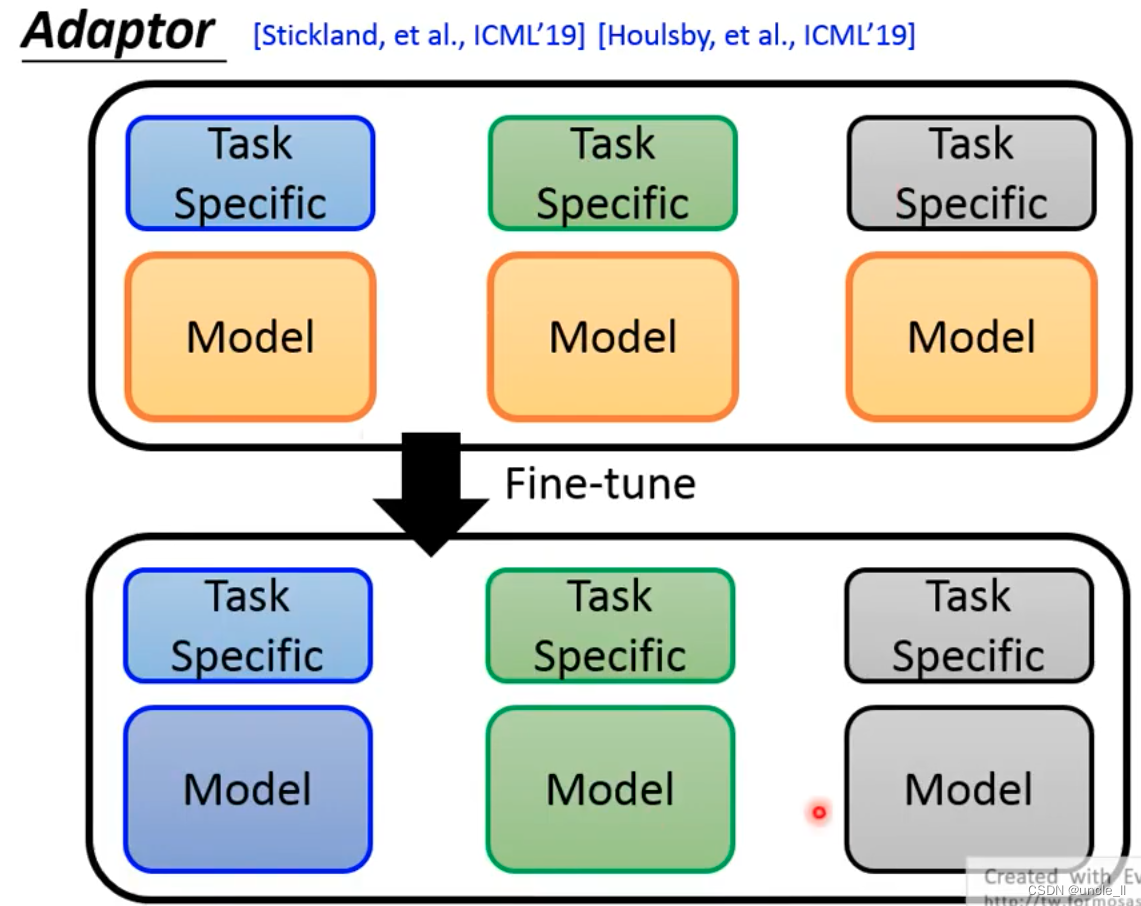
- After training, the pre-training model has also changed, which means that each task will have a different pre-training model, and each model is relatively large, which is very wasteful.
For the above problems, solutions:
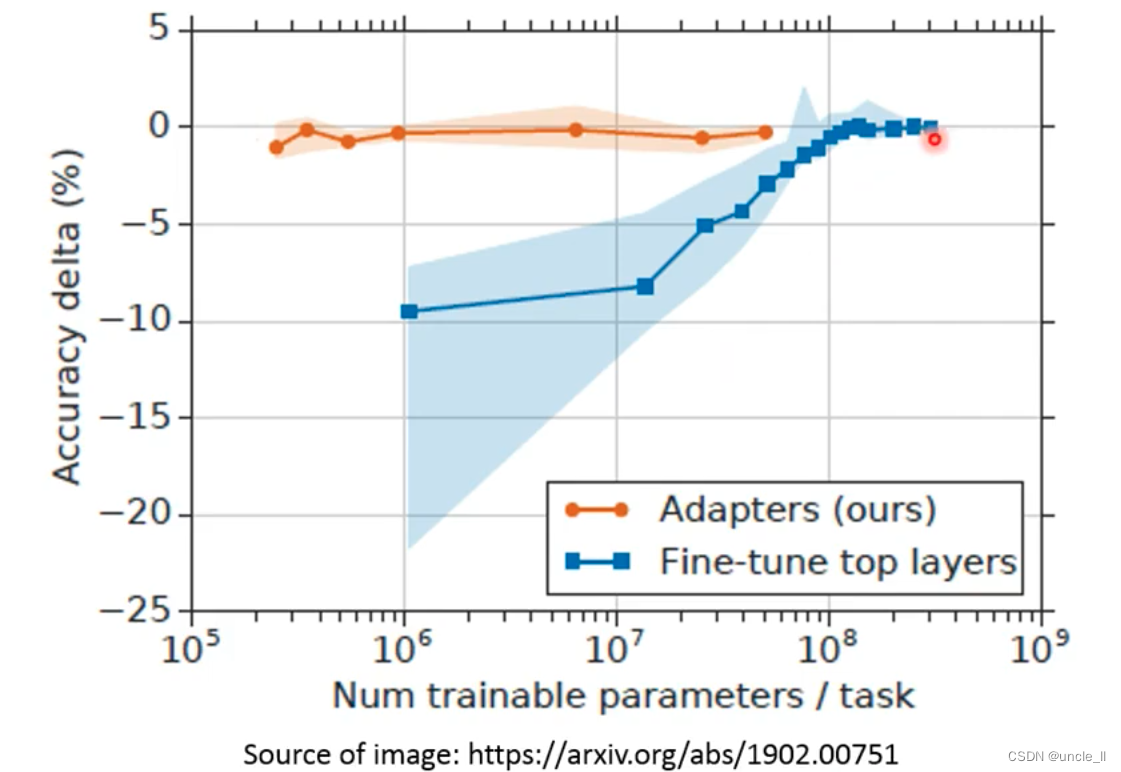
- Adapter: Only train a small amount of parameter structure APT

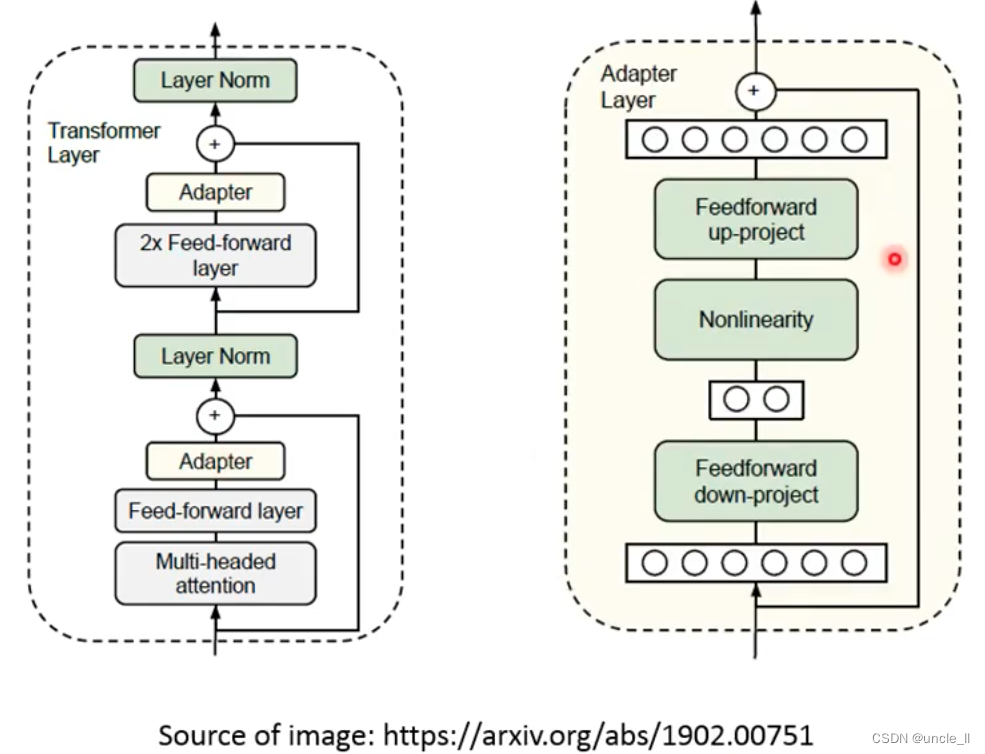
When fine-tune, only the parameters of the APT structure will be adjusted, but it will be inserted into the transformer structure to deepen the network:
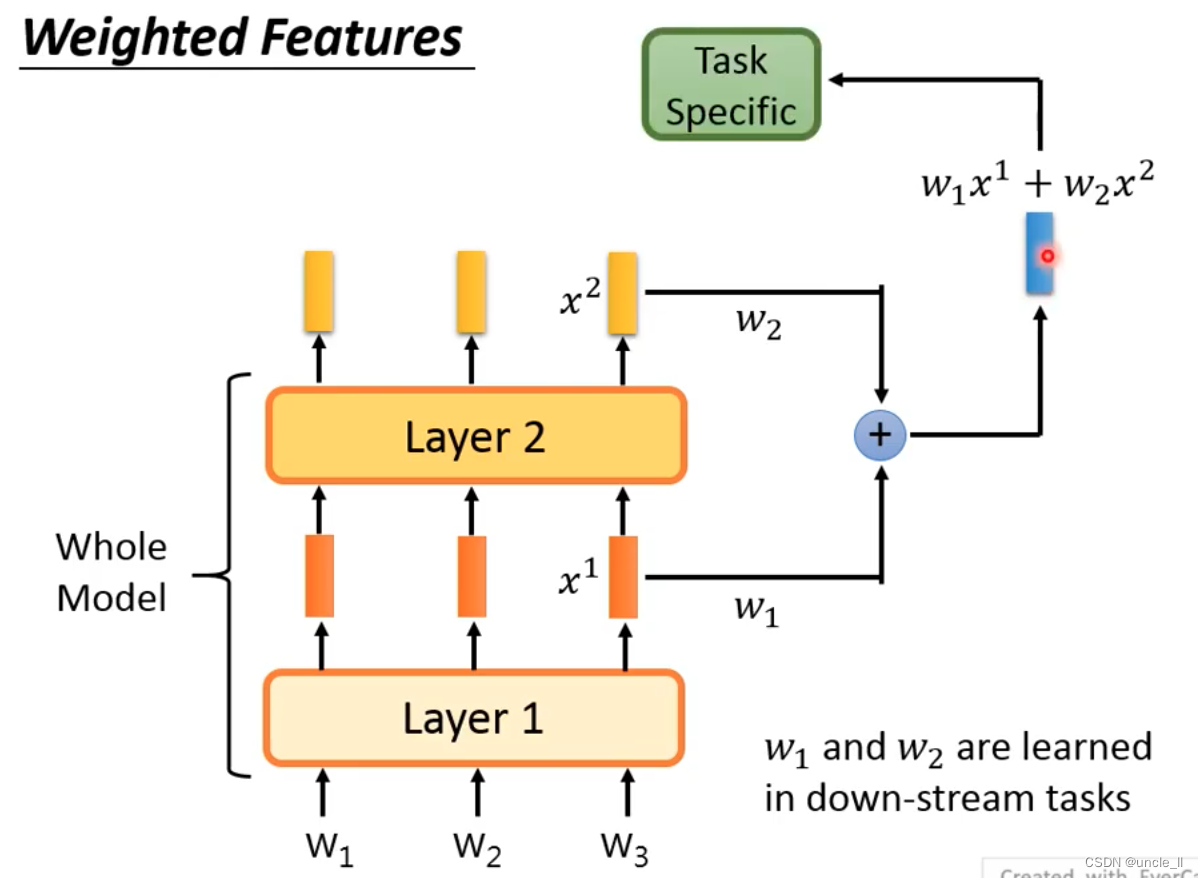
- Weighted Features
synthesizes the embedding of each layer and sends them to specific tasks for learning, and the weight parameters can be learned.
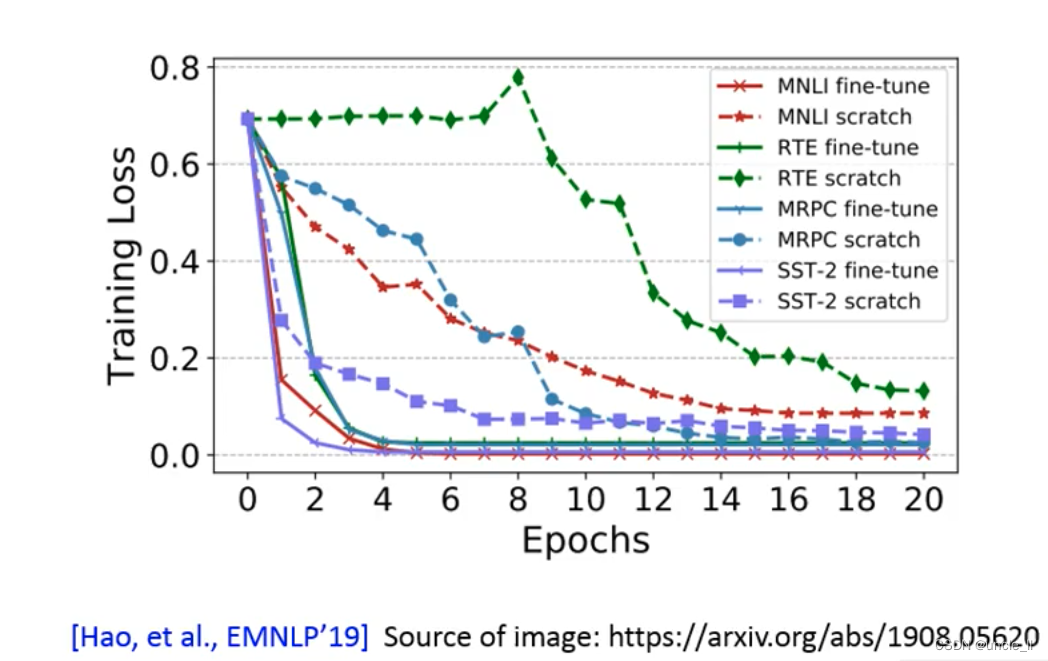
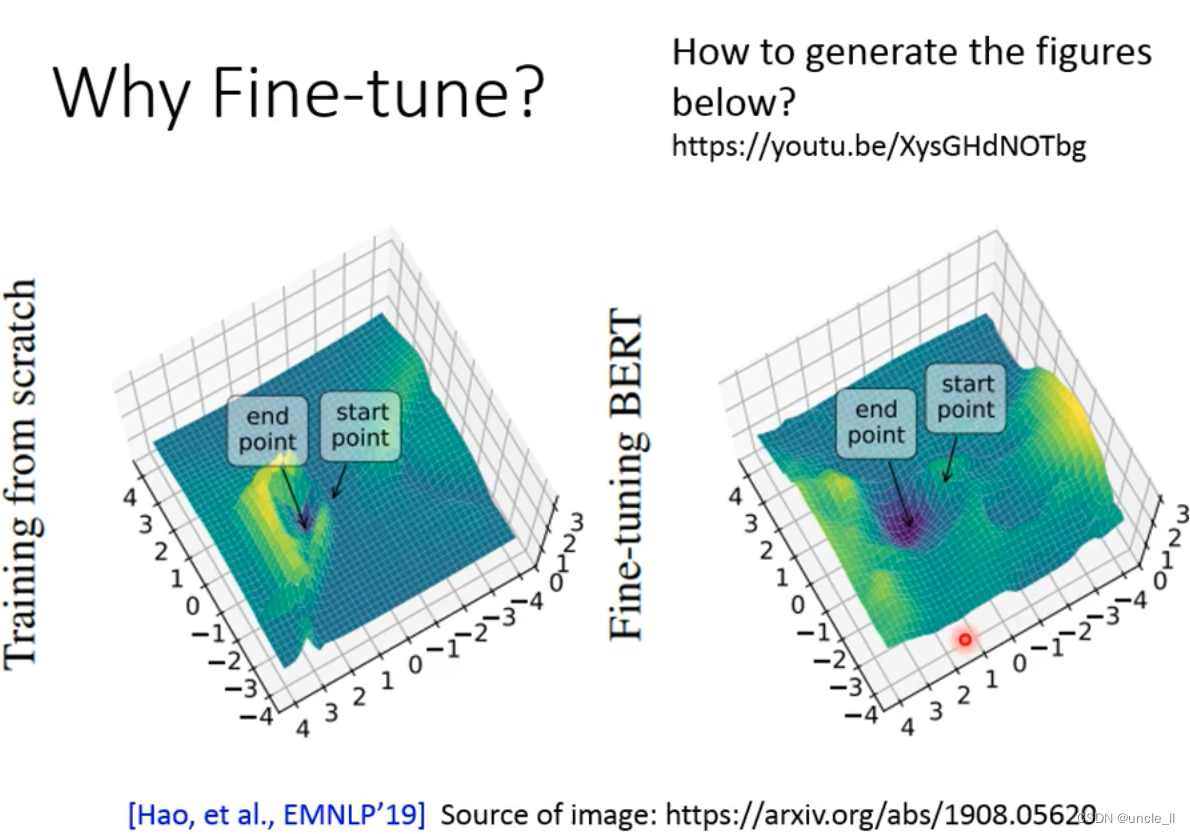
The loss of the model, the generalization ability. From start-point to end-point, the wider the distance between the two points and the shallower the concave, the more general the generalization ability; the closer the distance between the two points, the deeper the concave, the better the generalization ability.
How to pre-train
How to pre-train:
translation task
- Context Vector (Cove)
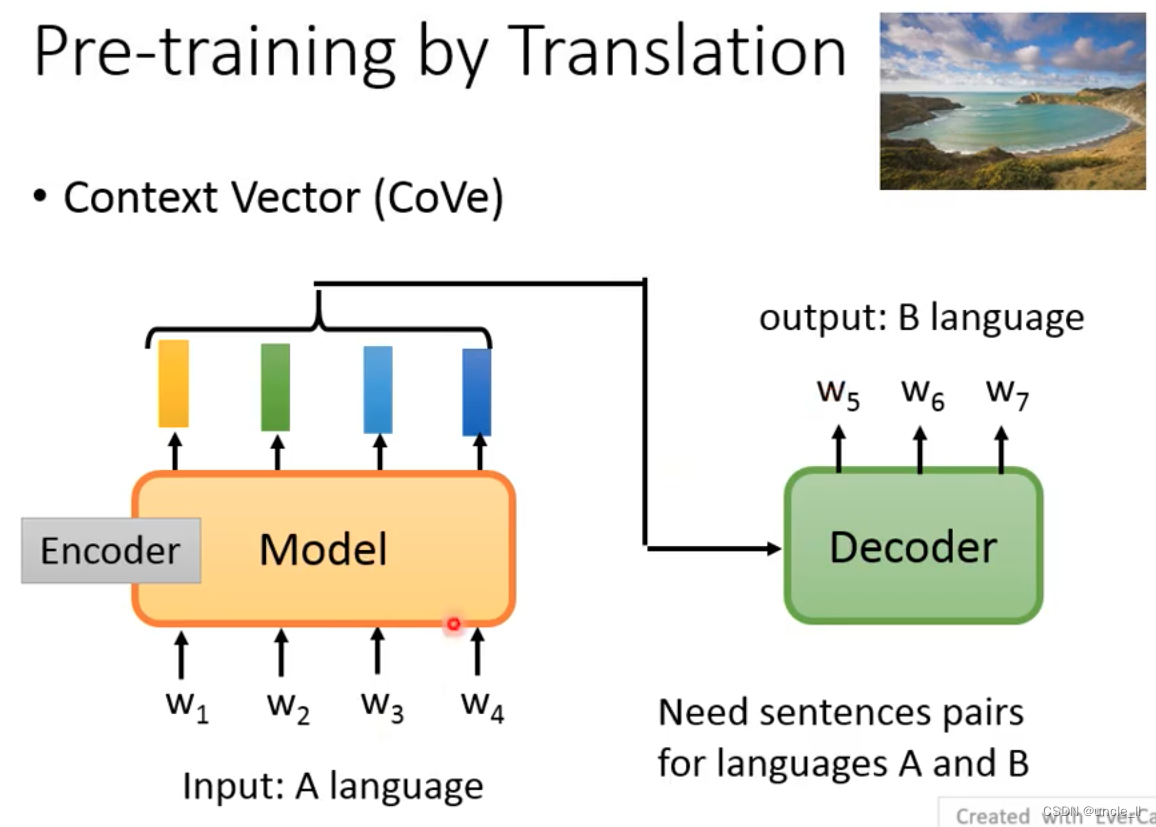
sends the input sentence A to the encoder, and then the decoder gets the sentence B, which requires a lot of pair data
Self-supervised Learning
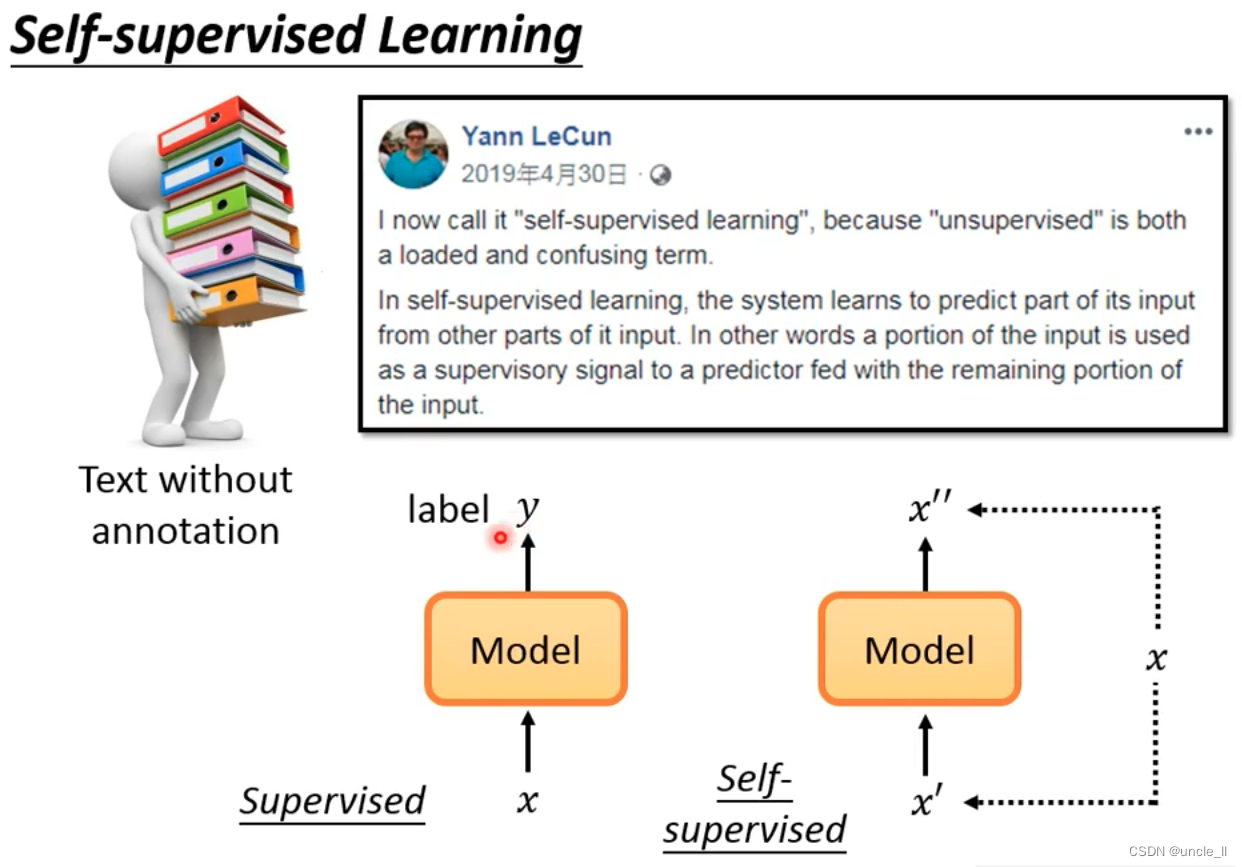
The input and output of self-supervised are generated by themselves.
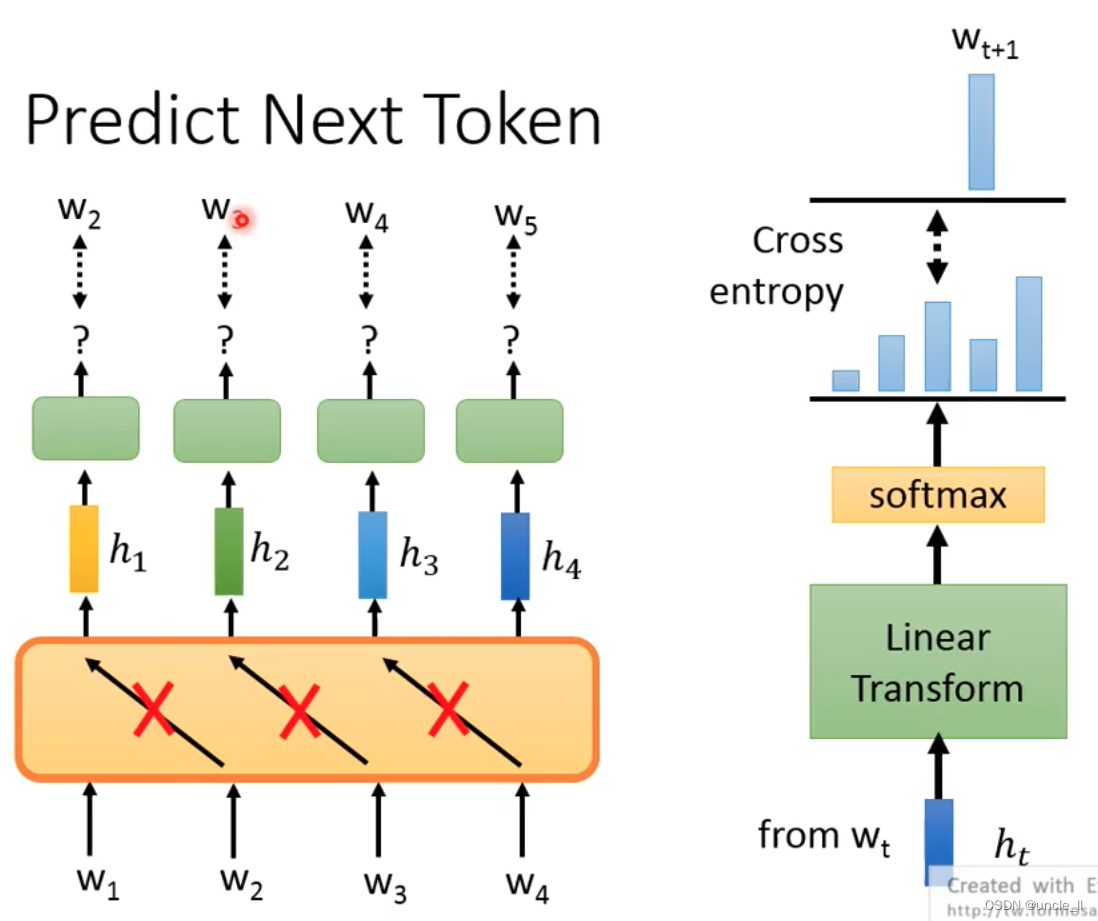
Predict Next Token
Given an input, predict the next token
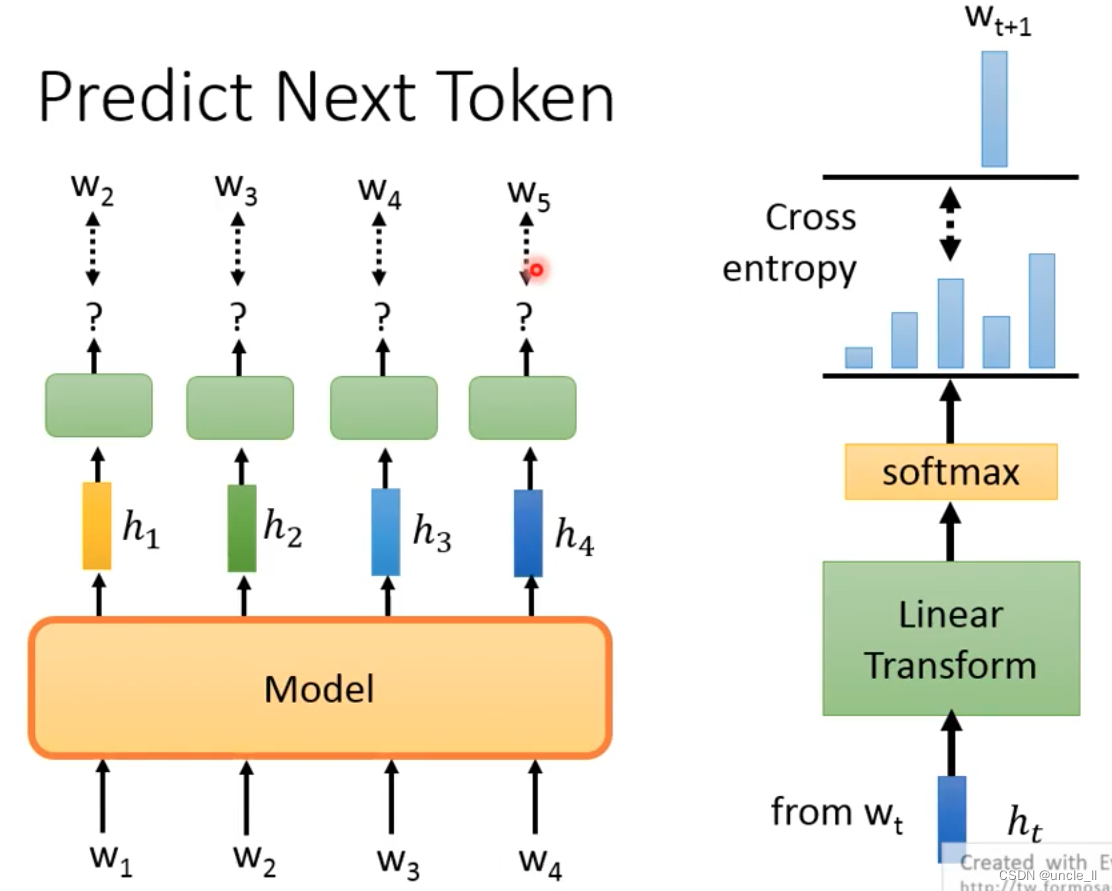
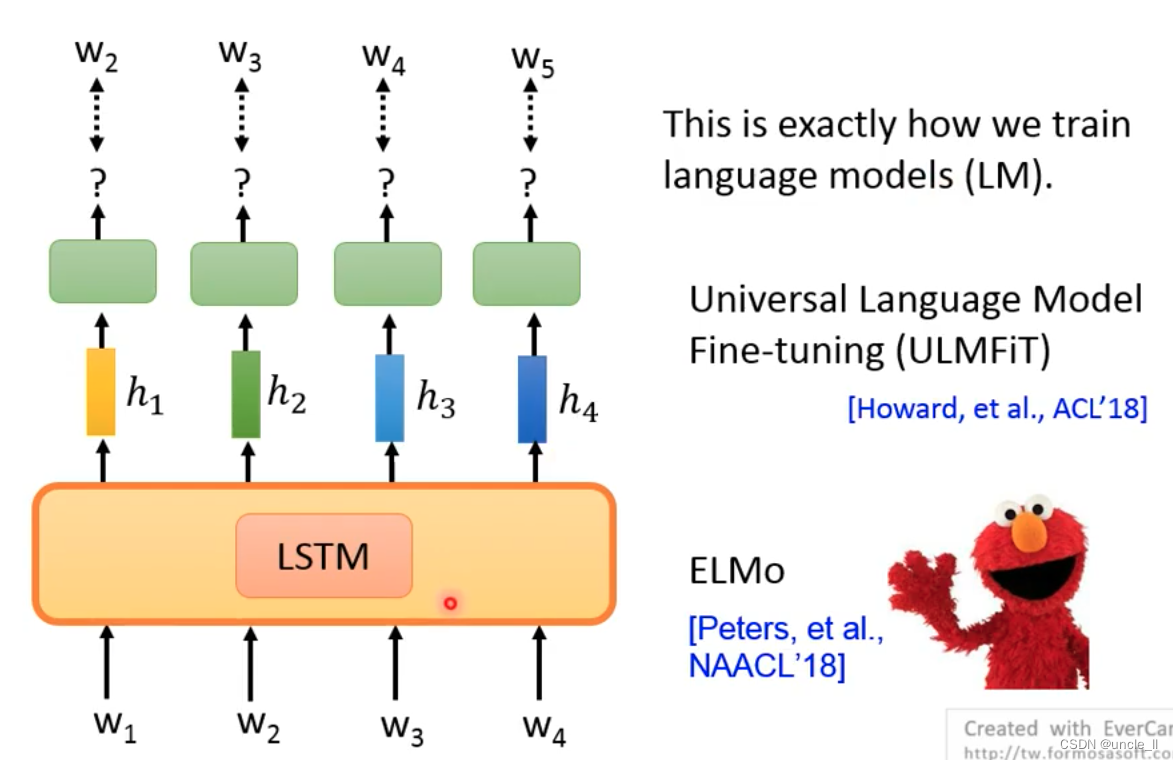
With w1 predicting w2, using w1, w2 to predict w3, and then using w1, w2, w3 to predict w4, but the data on the right cannot be used to predict the data on the left: the infrastructure network uses LSTM
:
- LM
- ELMo
- ULMFiT
Some subsequent algorithms replace LSTM with Self-attention
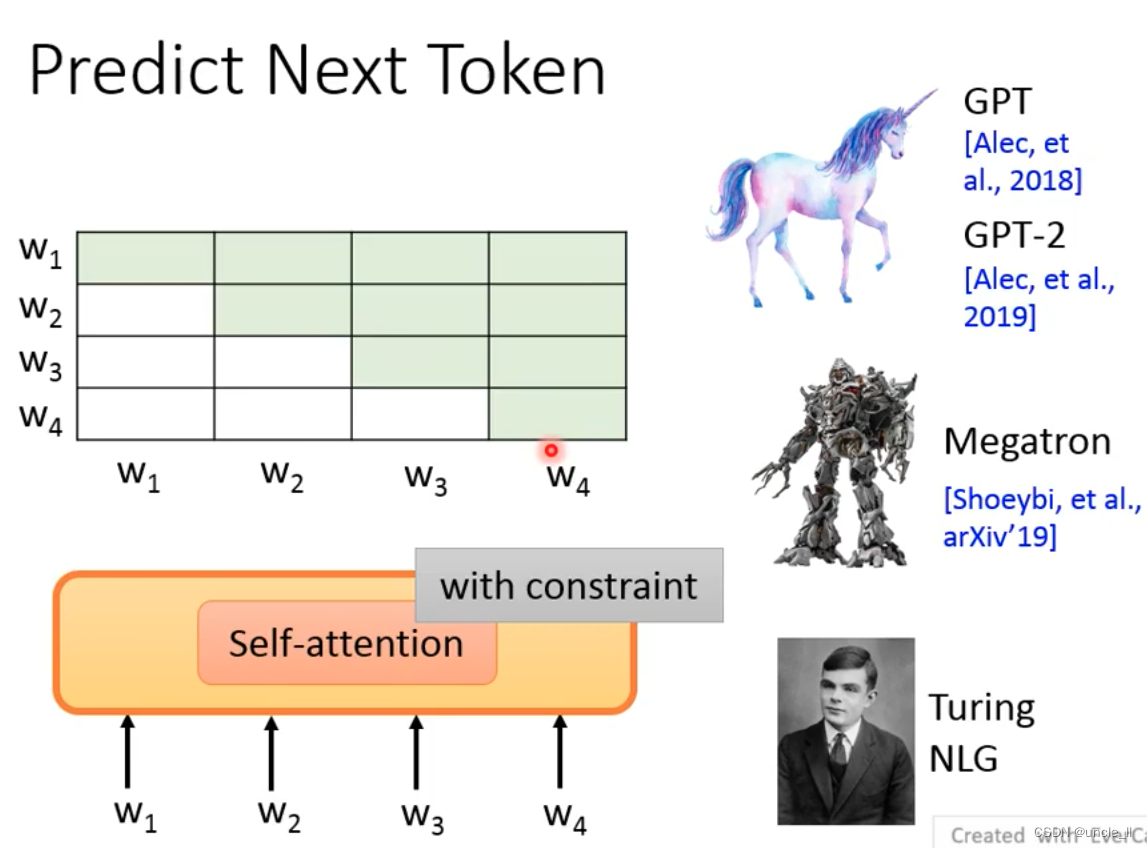
- GPT
- Megatron
- Turing NLG
Note: Control the scope of Attention

Can be used to generate articles: talktotransformer.com



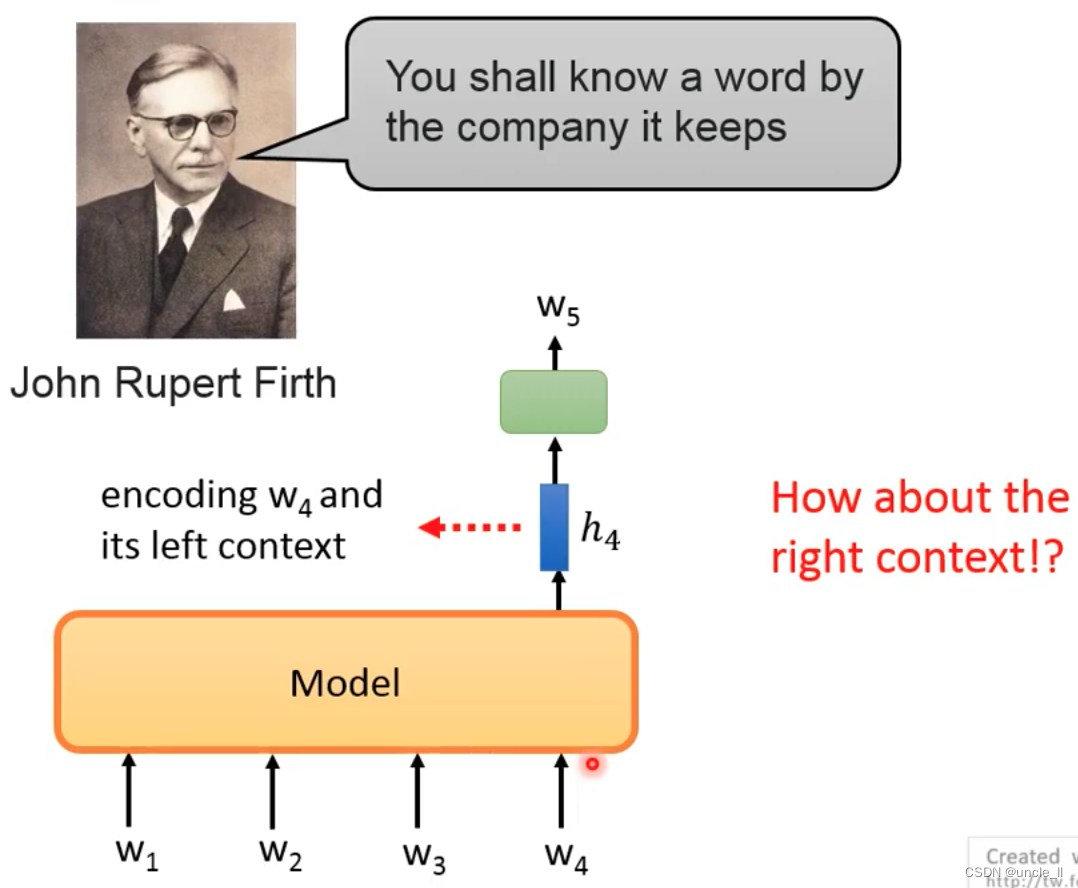
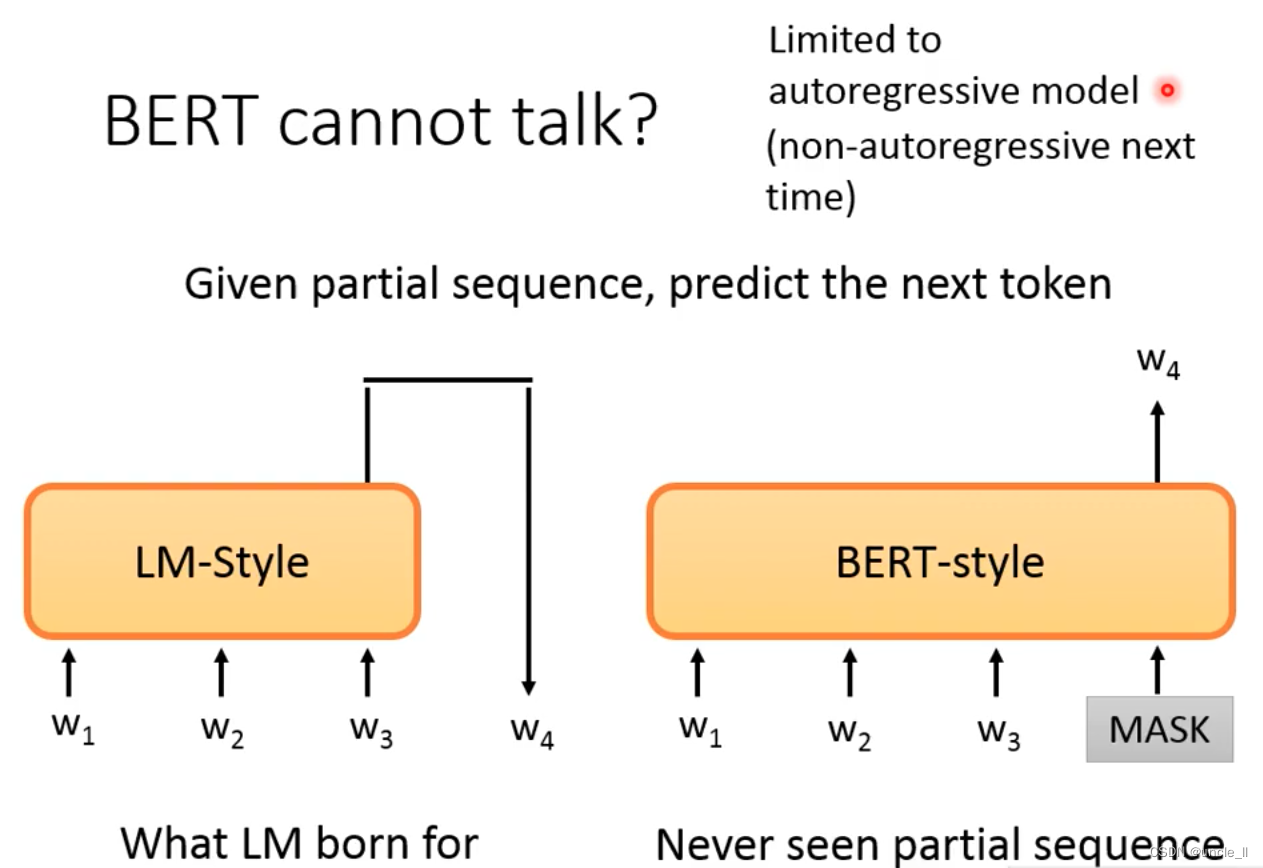
If only the occurrence relationship on the left is considered, why not the text on the right?
Predict Next Token-Bidrectional
The contexts generated on the left and right sides are combined as the final representation:
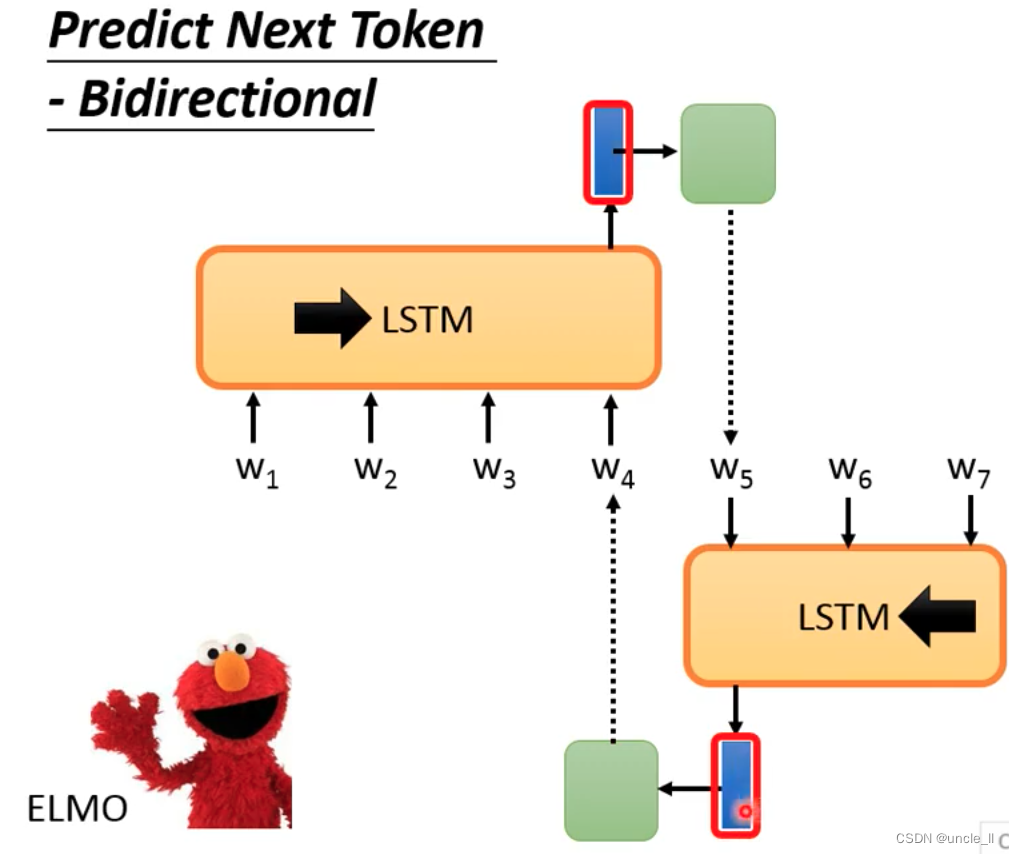
But the problem is that the left can only see the left, but cannot see the end of the right, and the right can only see the right, but cannot see the beginning of the left.
Masking input
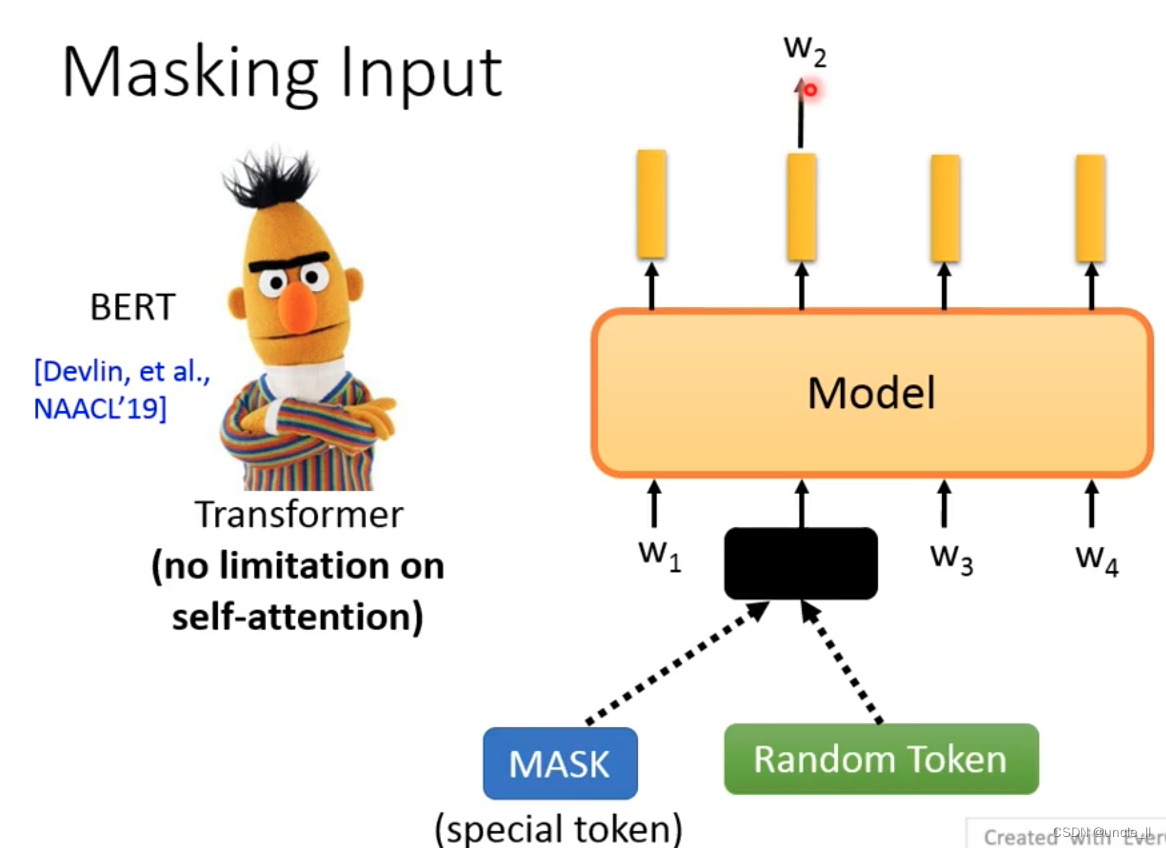
Randomly cover a certain word, it is to see the complete sentence to predict what the word is.
Pushing this idea forward, it is very similar to the previous cbow:
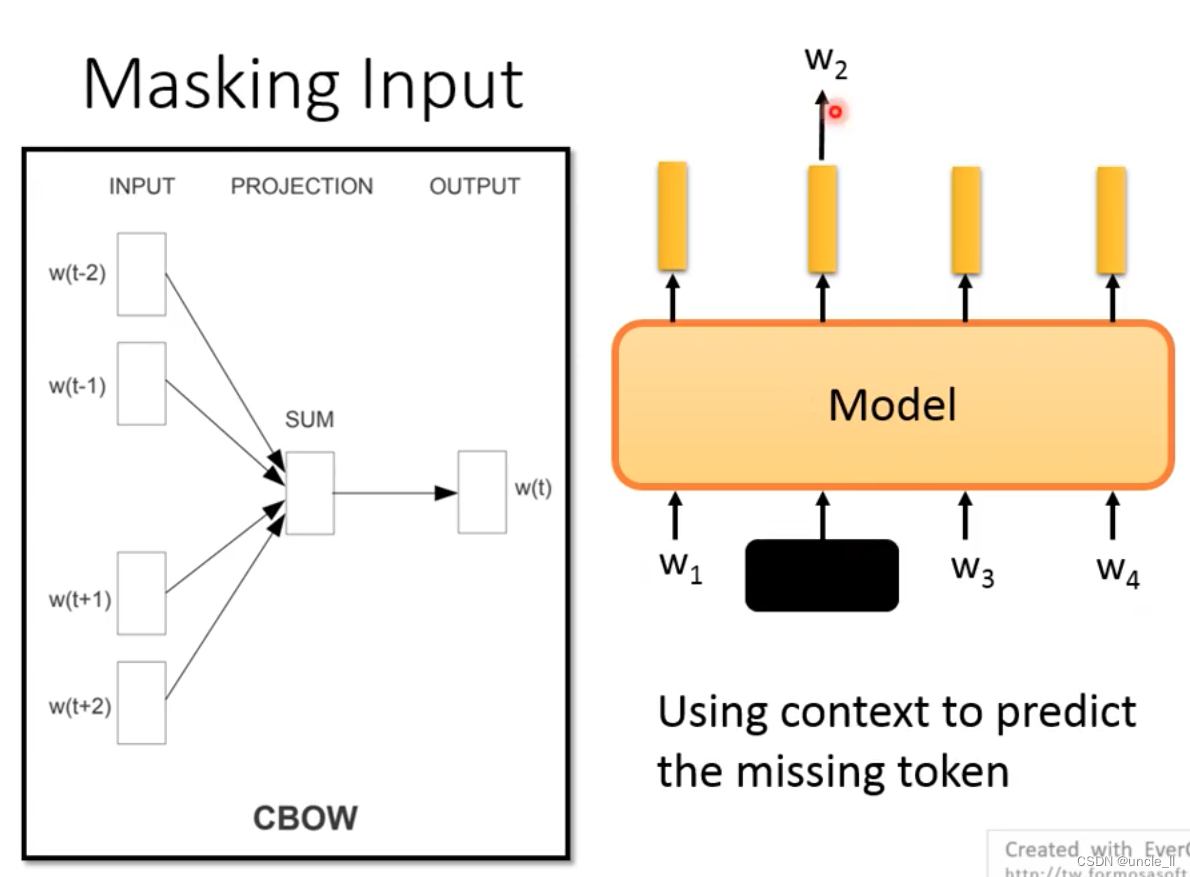
The difference between Bert and cbow is that the length of the left and right sides can be infinite, instead of having a window length.
Is a random mask good enough? There are several mask methods:
- wwm
- ERNIE
- TeamBert
- SBO

covers an entire sentence or covers several words. Or find out the Entity first, and then cover these words:

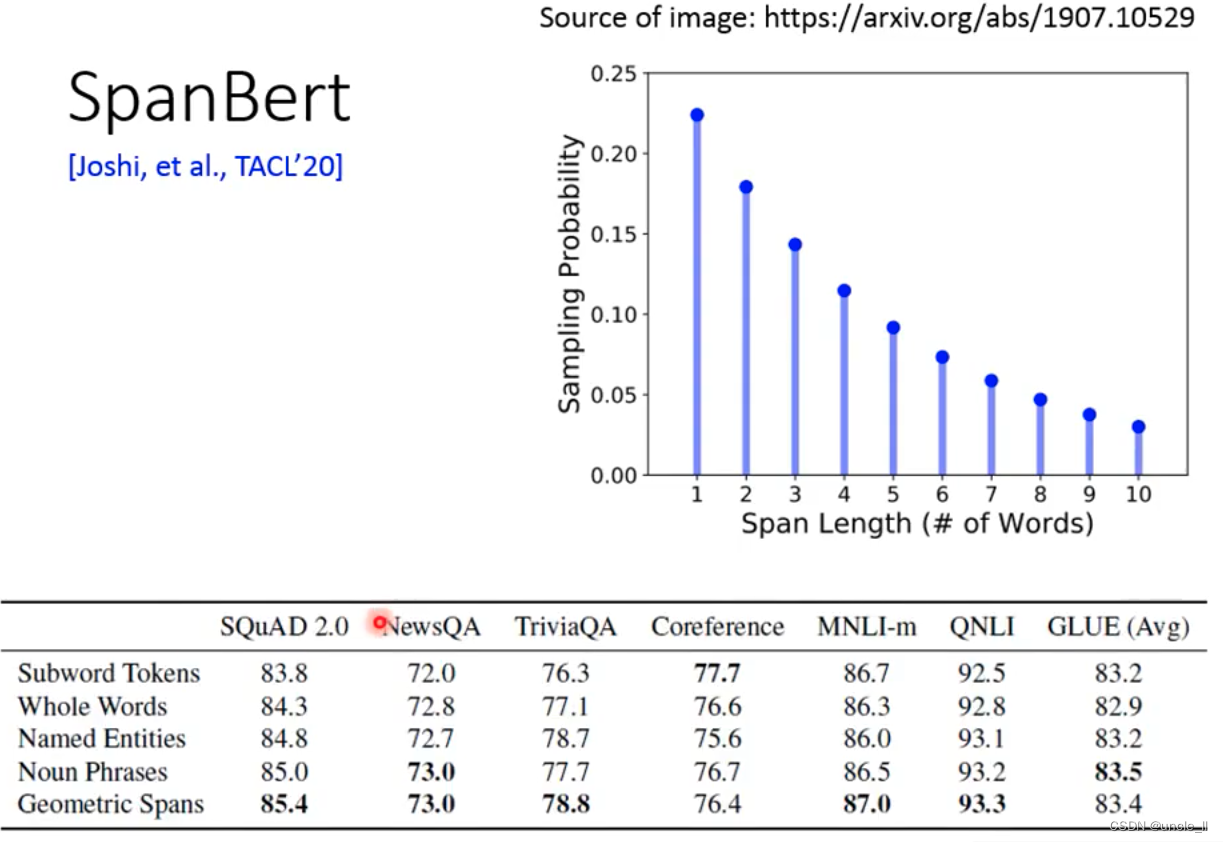
the length of the cover is according to the probability of appearance in the above picture.
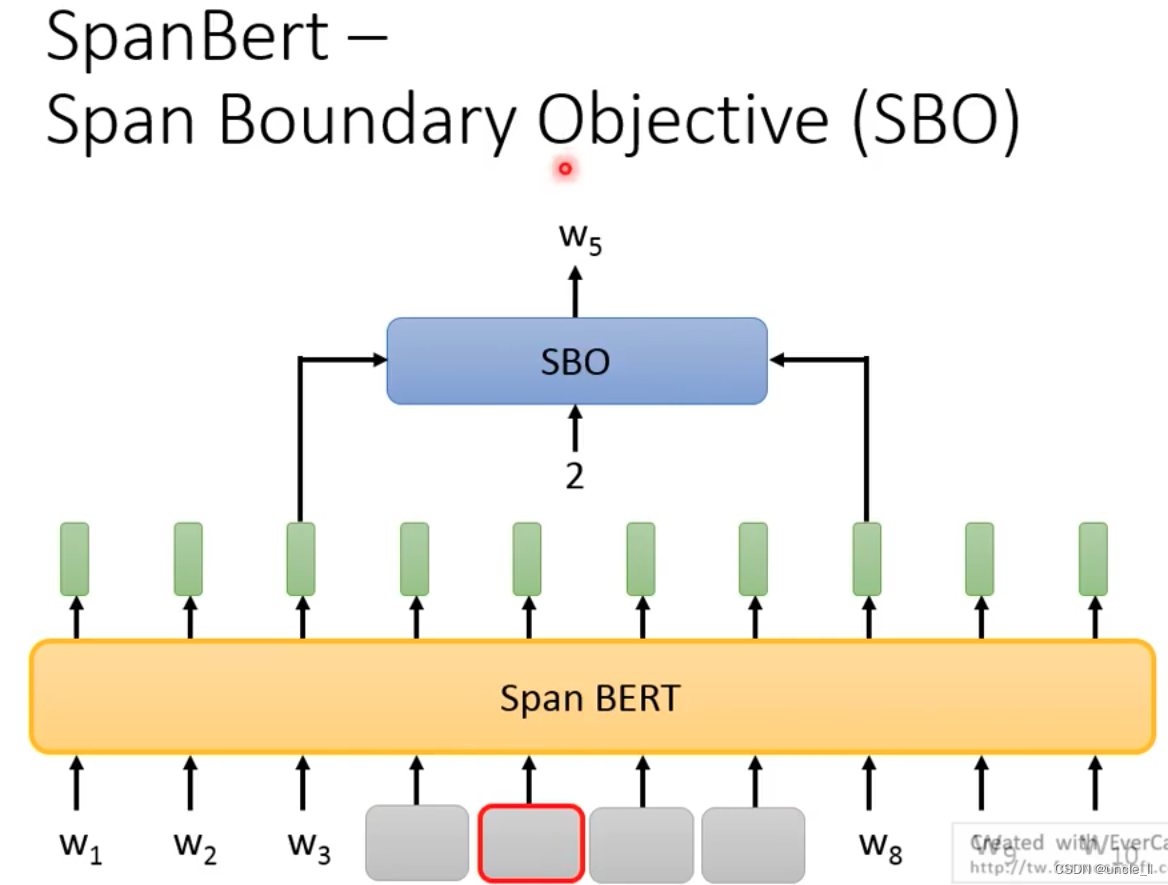
Cover the embeddings on the left and right sides to predict, and the input index to restore which word in the middle.
The design of SBO expects the token embedding on the left and right to contain the embedding information on the left and right.
XLNet
The structure is not using Transformer, but using Transformer-XL
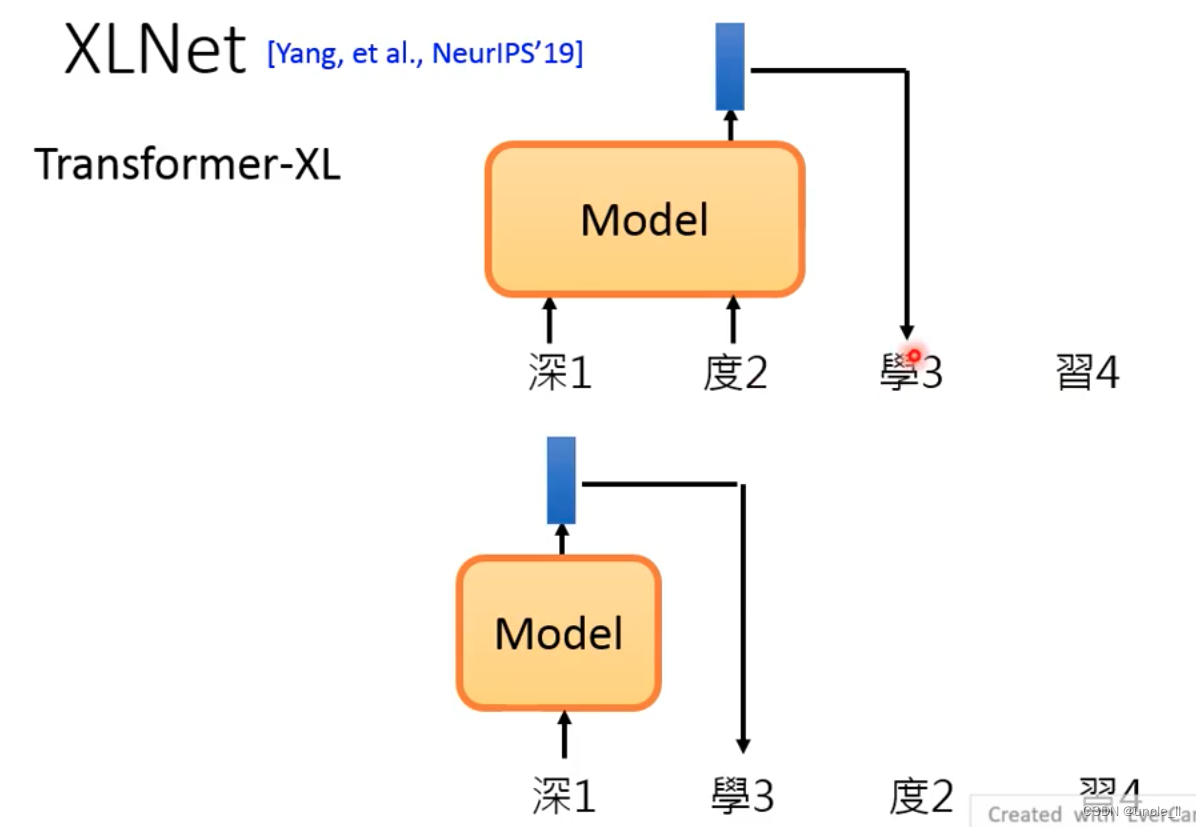
Randomly shuffle the order and train a token with a variety of different information.
Bert's training corpus is relatively regular:
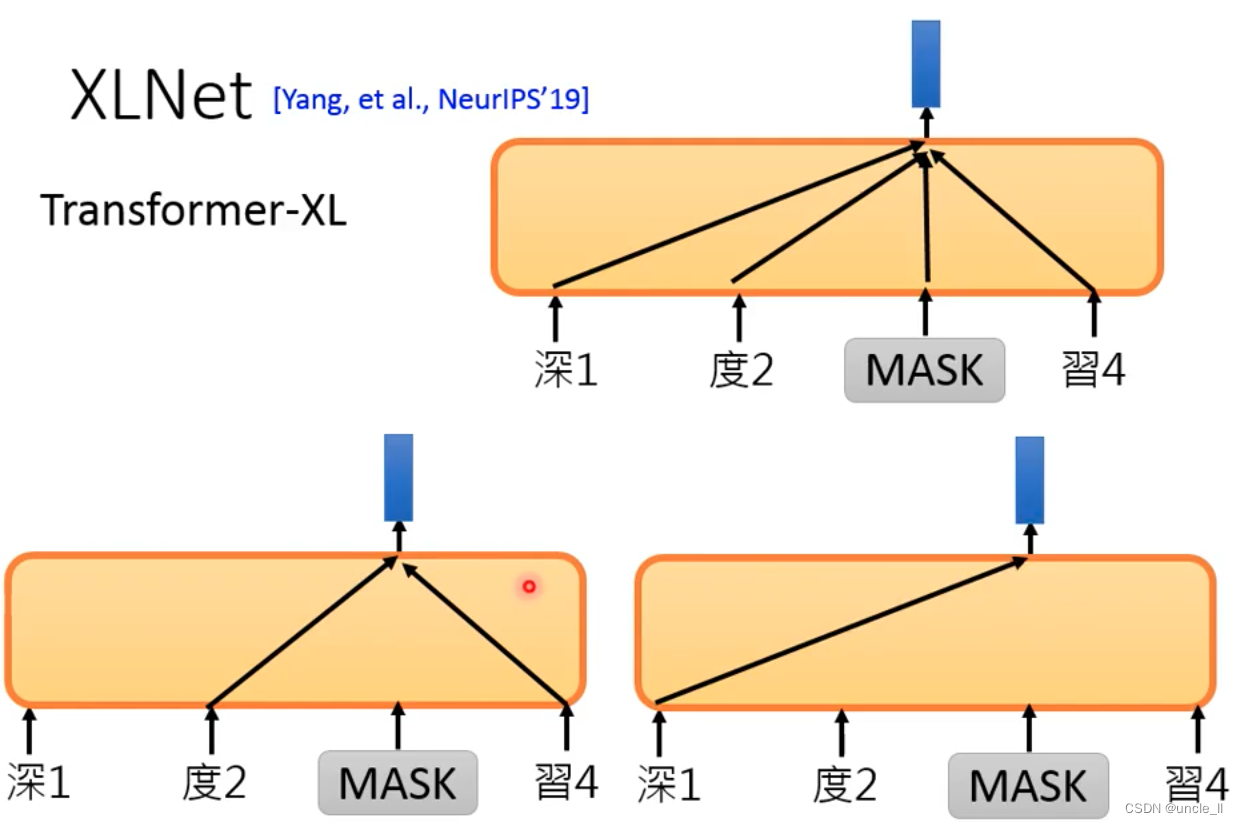
Bert is not good at doing Generative tasks, because Bert gives the whole sentence during training, while Generative only gives a part, and then predicts the next token from left to right
MASS/BART
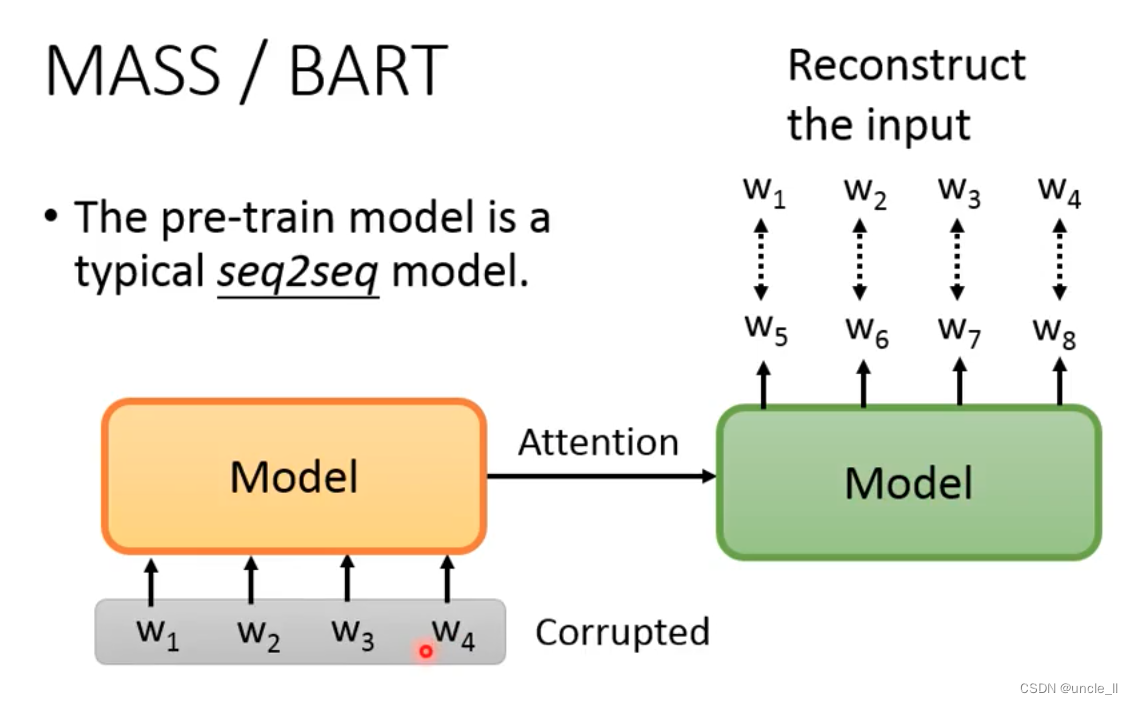
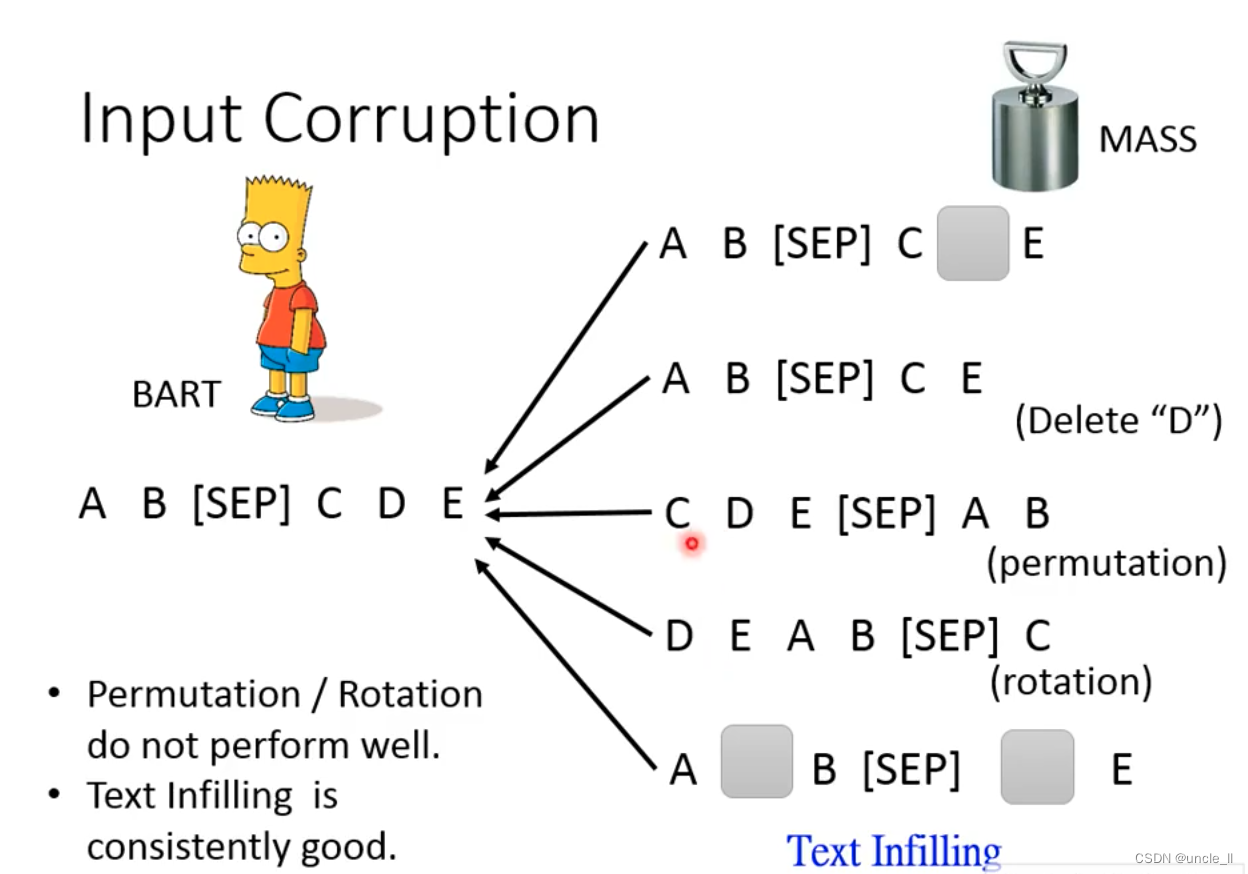
Do some damage to w1, w2, w3, w4, otherwise the model can't learn anything, the method of destruction:

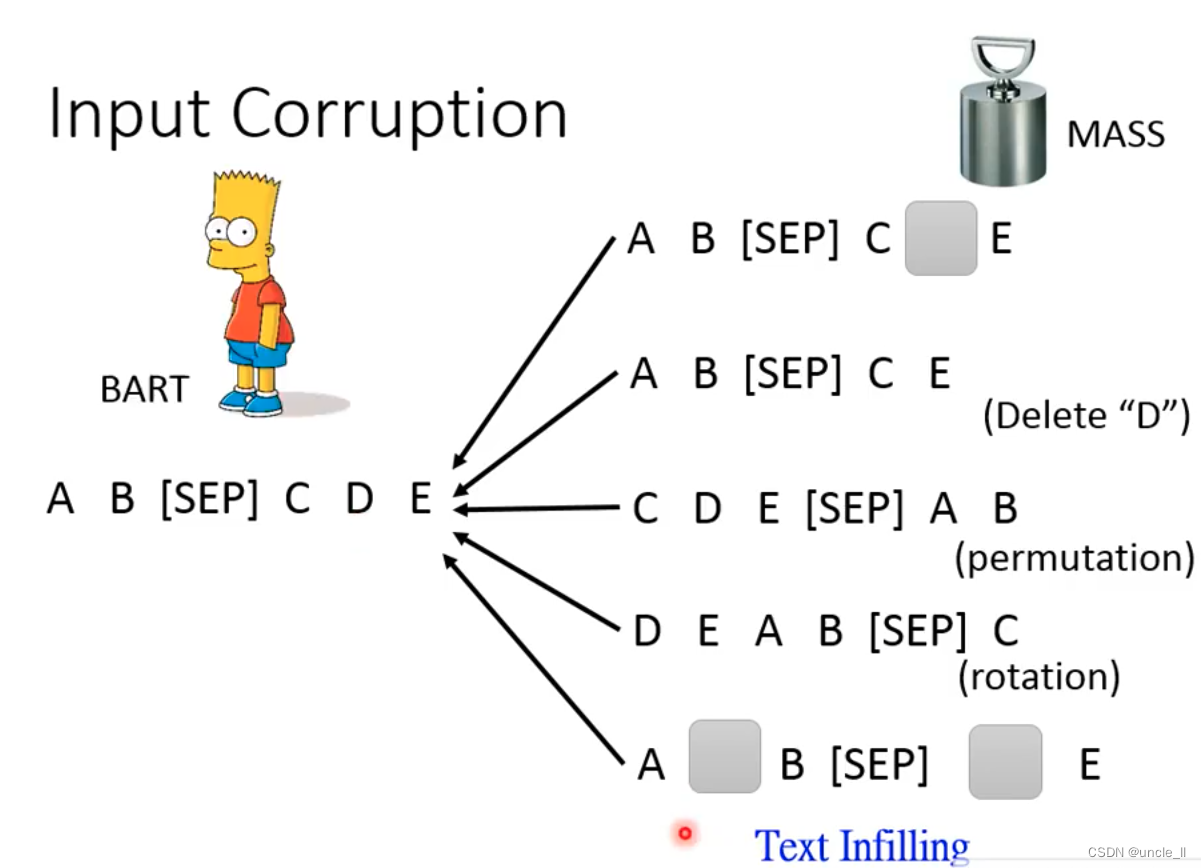
- mask (random mask)
- delete (delete directly)
- permutation
- rotation (change the starting position)
- Text Infilling (insert another misleading, missing a mask)
turn out:
UniLM
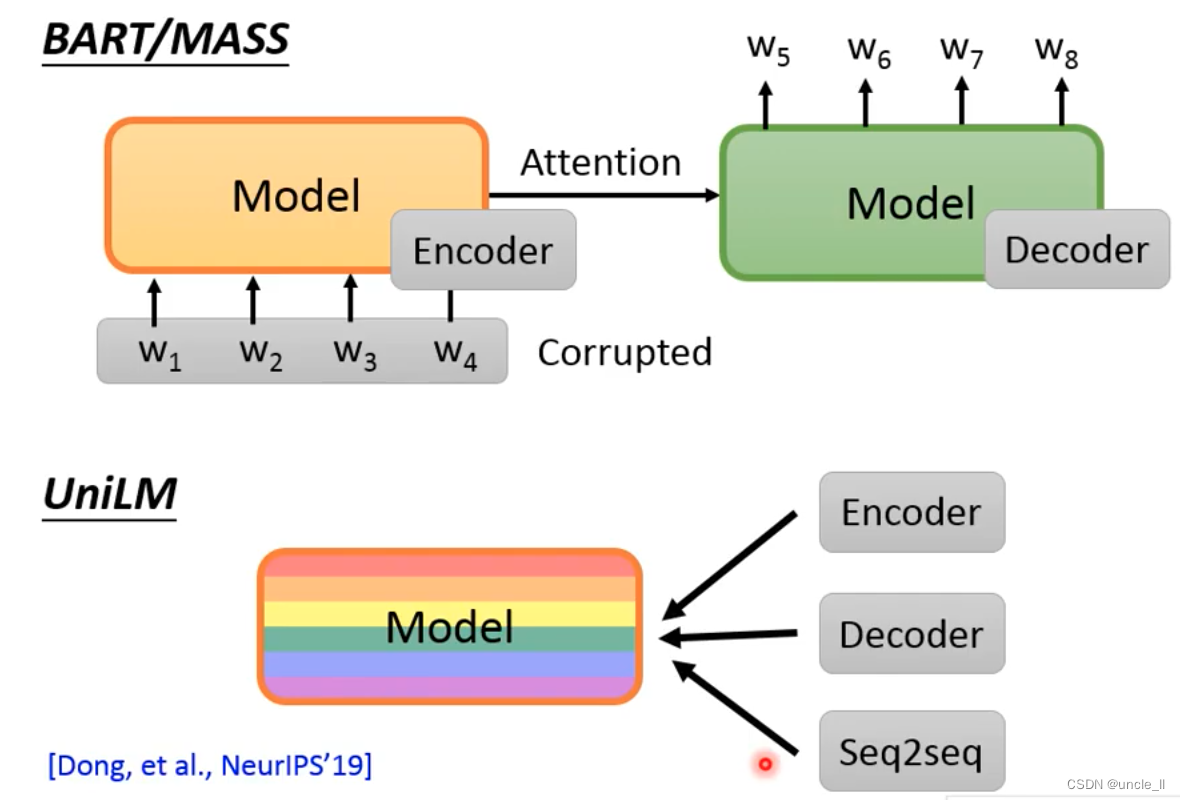
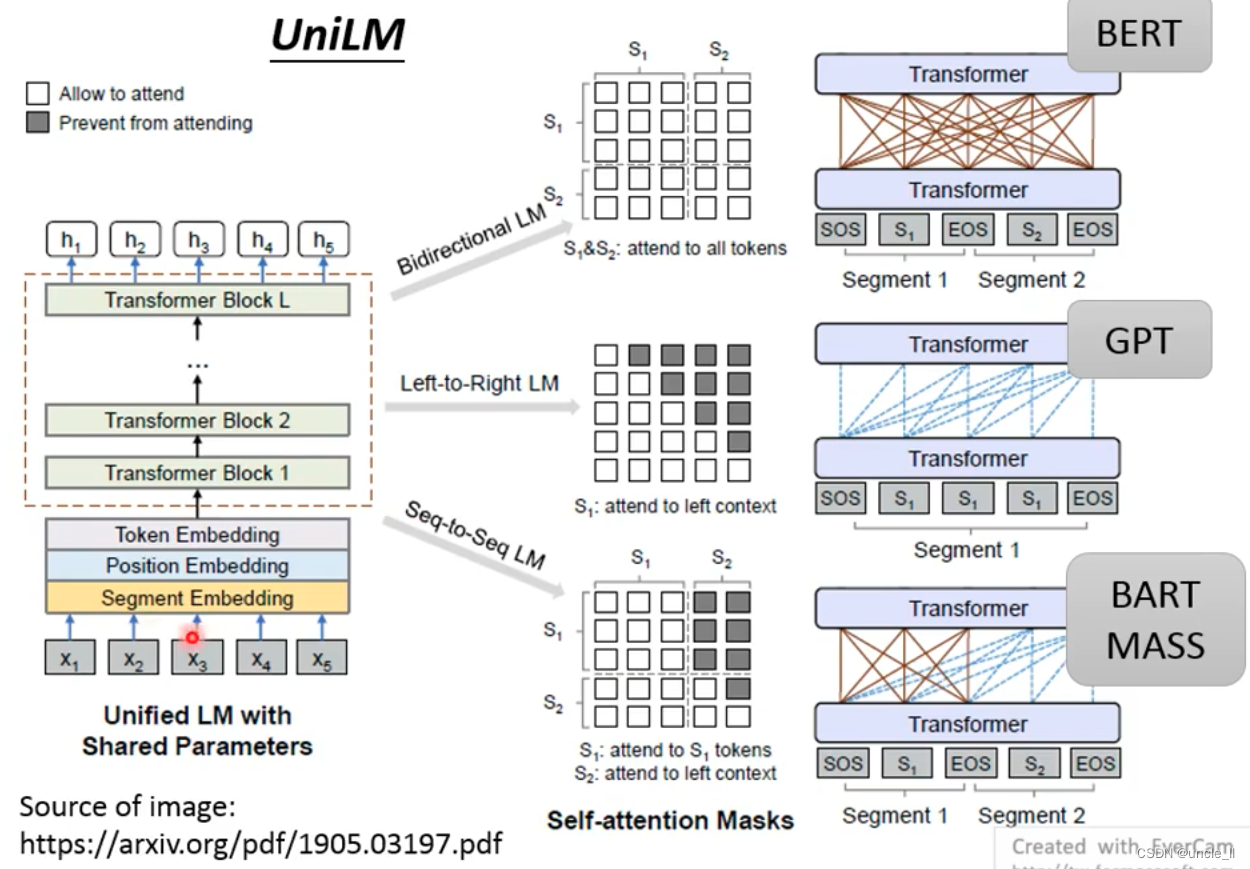
UniLM for multiple training
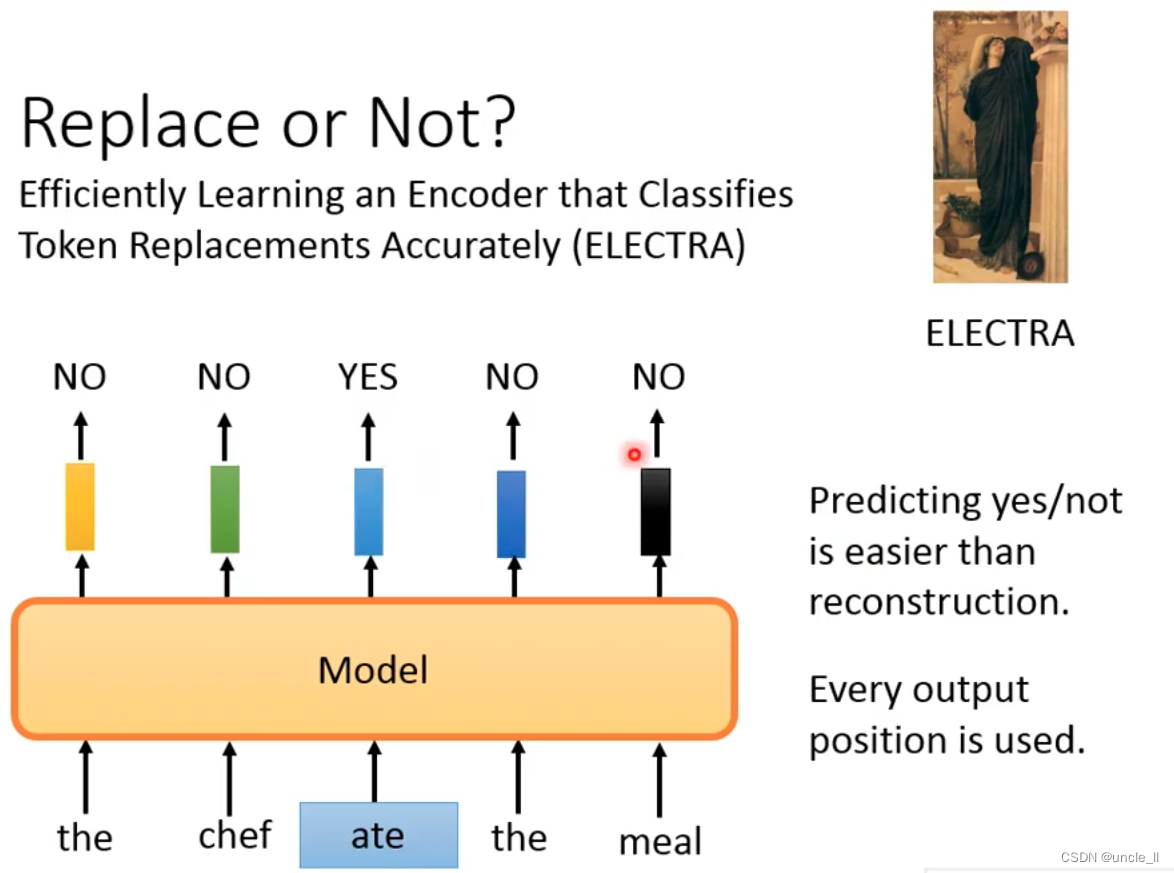
Replace or Not
- ELECTRA avoids the things that need to be trained and generated, and judges which position is replaced. The training is very simple, and every output is used.
*
The replacement words are not easy to get, if it is replaced casually, it will be easy to know. So with the following results, use a small bert predicted result as the replacement result. The small bert effect should not be too good, otherwise the predicted result will be the same as the real one, and the replacement effect will not be obtained, because the replacement result is exactly the same of.
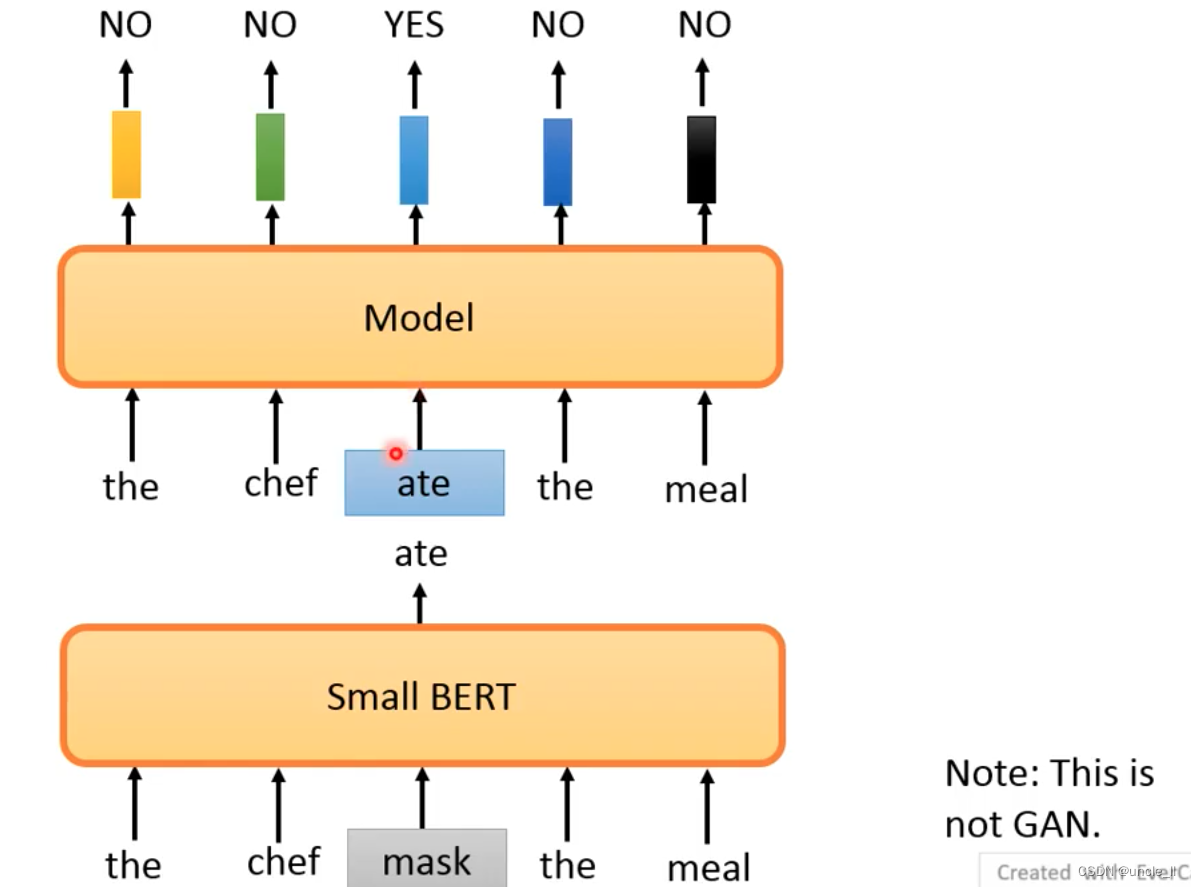
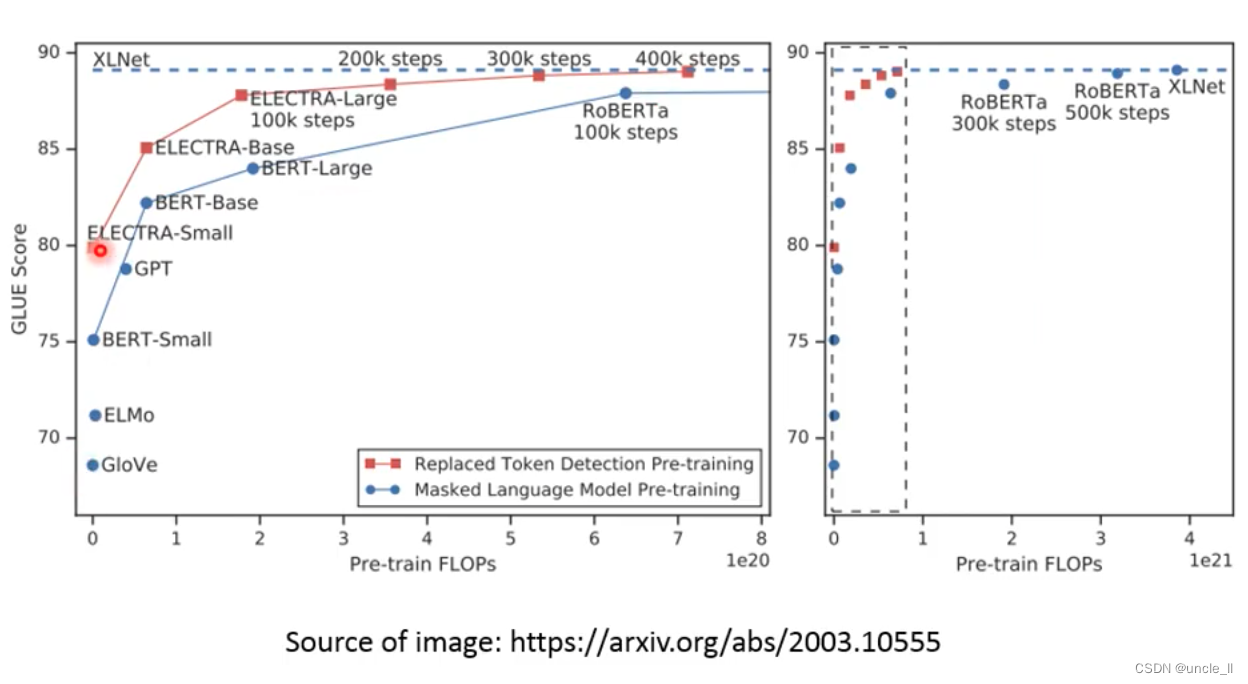
Only a quarter of the calculation is needed to achieve the effect of XLNet.
Sentence Level
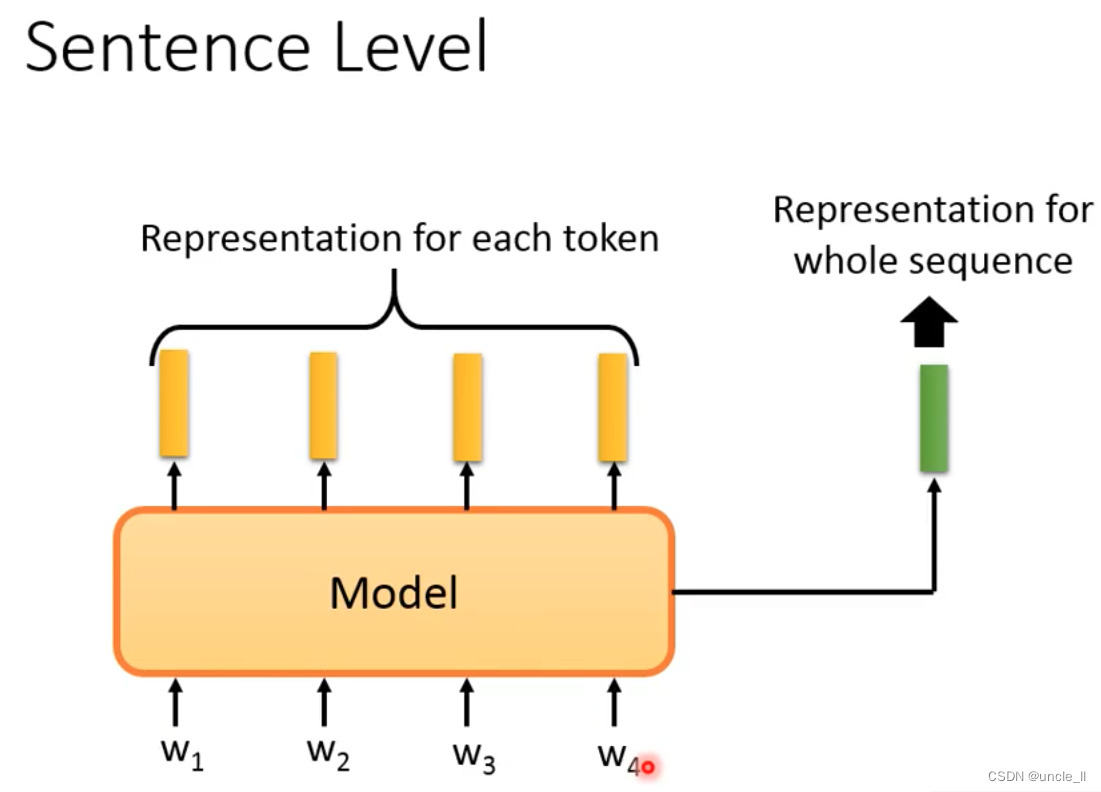
The embedding of the entire sentence is required.
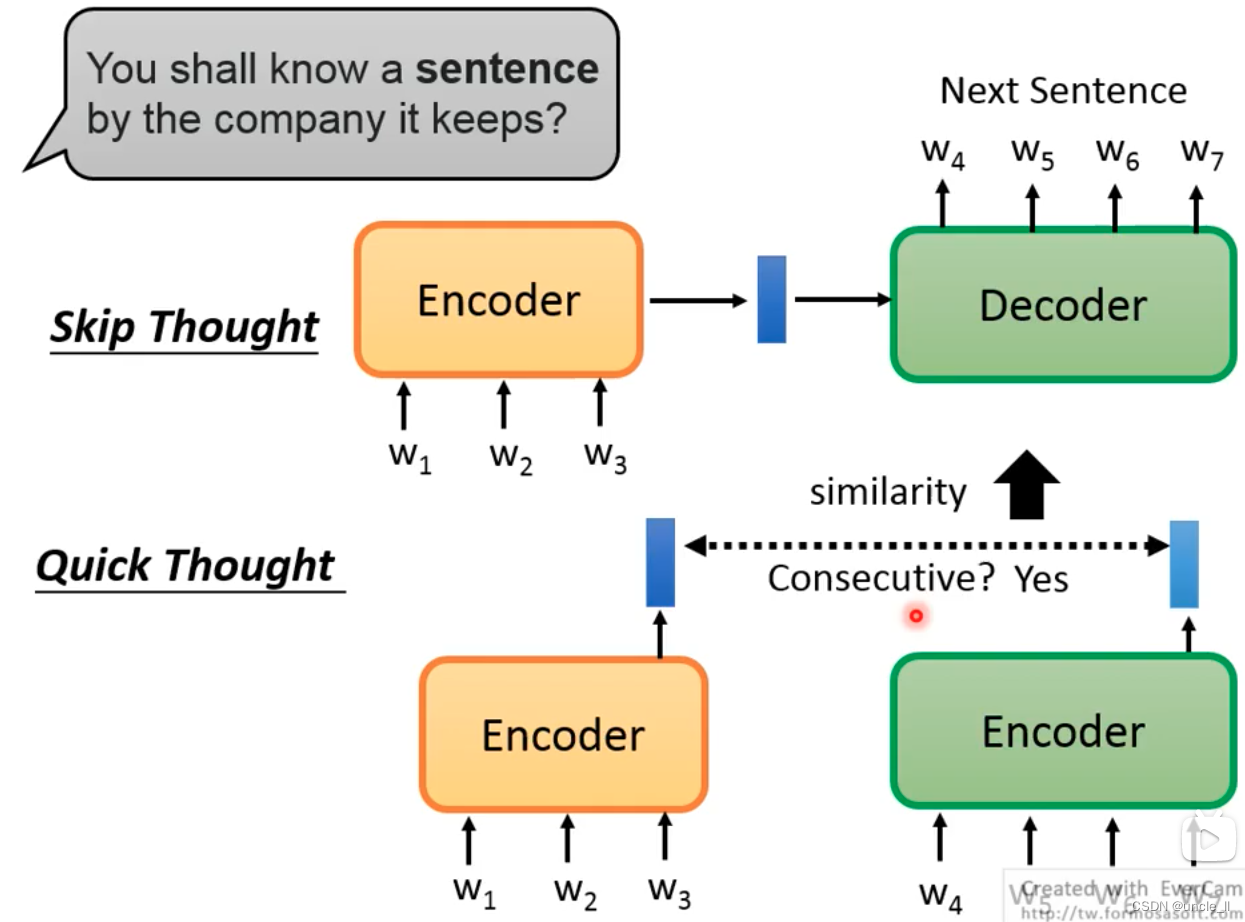
- Using skip thought, if the prediction results of two sentences are more similar, then the two input sentences are more similar.
- Quick thought, if the output of two sentences is connected, the closer the similar sentences are, the better.
The above approach avoids doing the generated task.
The original Bert actually has a task NSP, predicting whether two sentences are connected or not. Separate the two sentences with the sep symbol.
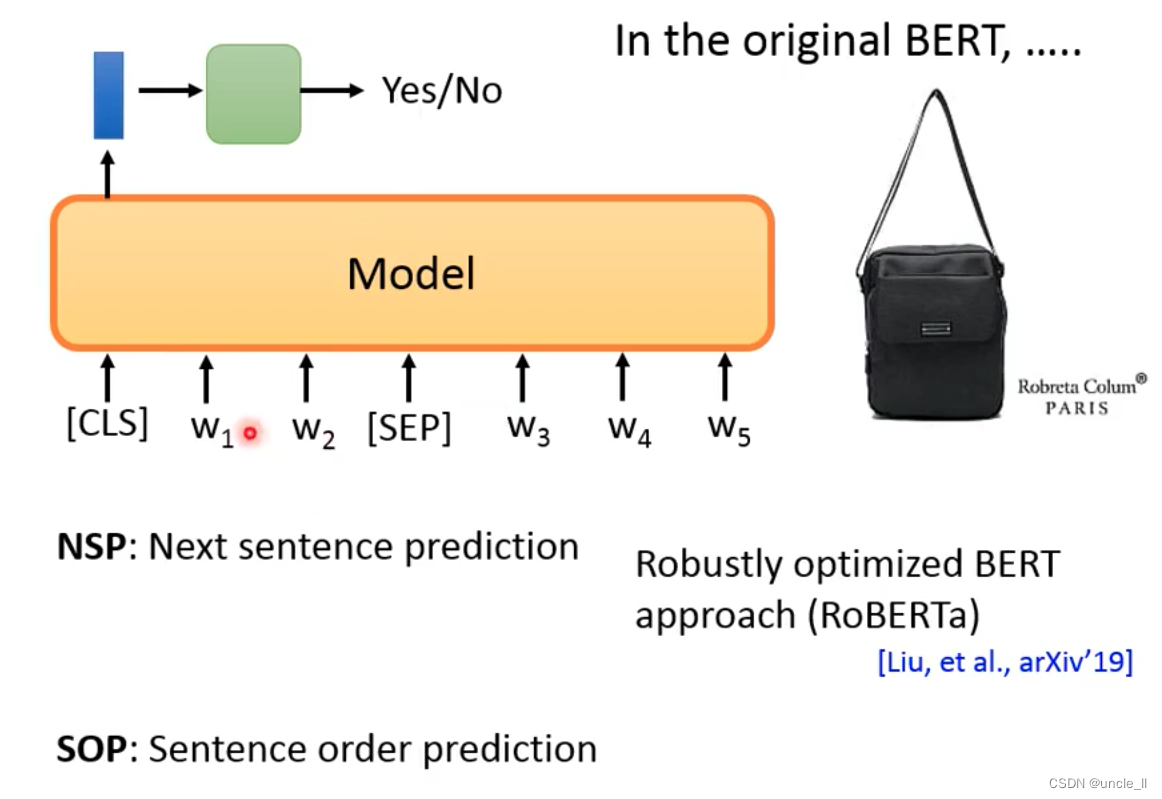
- nsp: the effect is not good
- Roberta: Average effect
- sop: Forward is connected, reverse is not connected, used in ALBERT
- structBert:Alice,
T5 Comparison
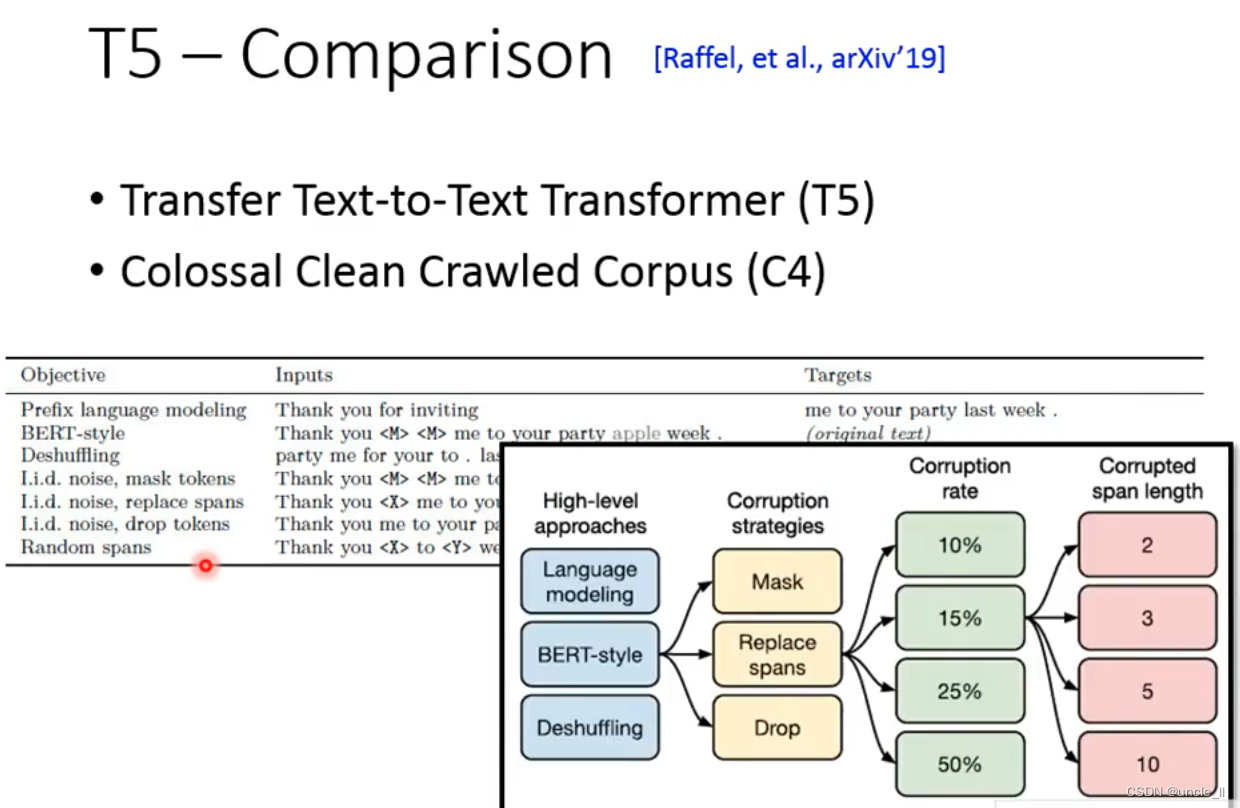
5 Ts are called T5,
4 Cs are called C4
ERNIE
I hope to add knowledge during the train

Audio Bert
Multi-lingual BERT
Multilingual BERT

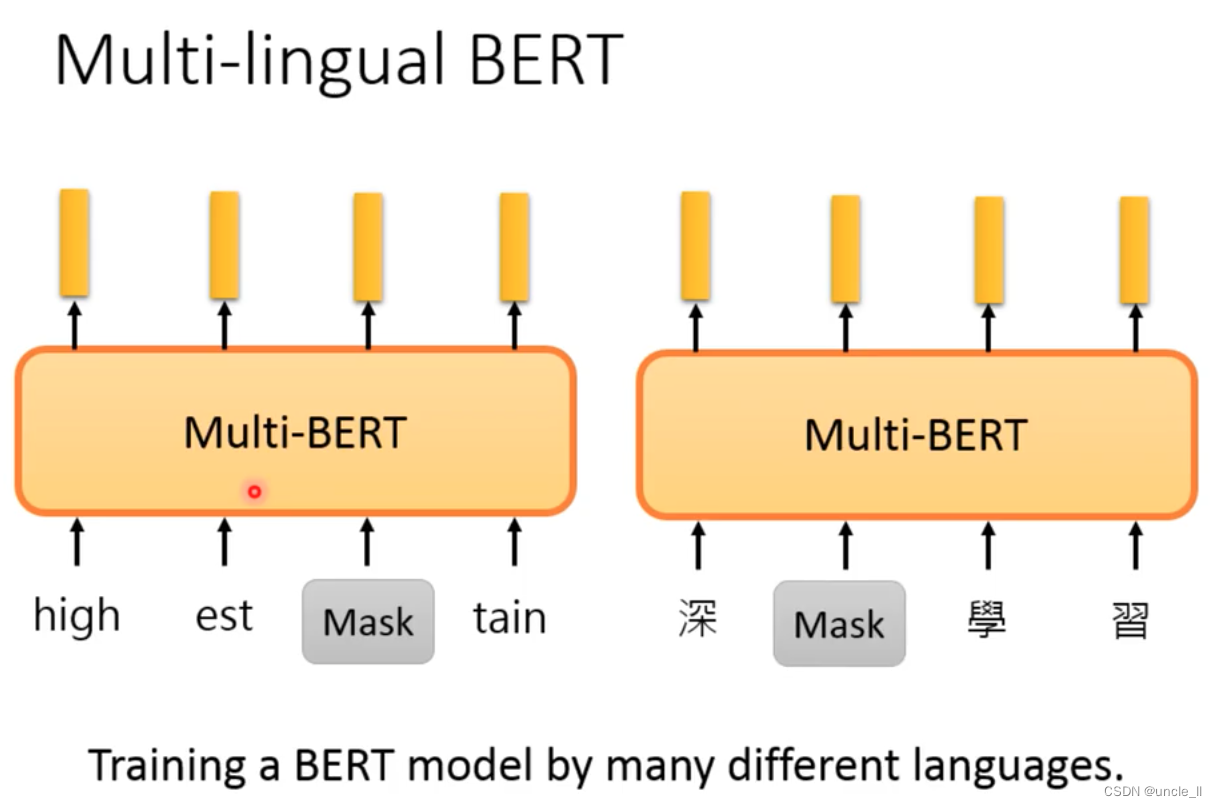
Using multiple languages to train a Bert model in

104 languages can achieve zero-shot reading comprehension.
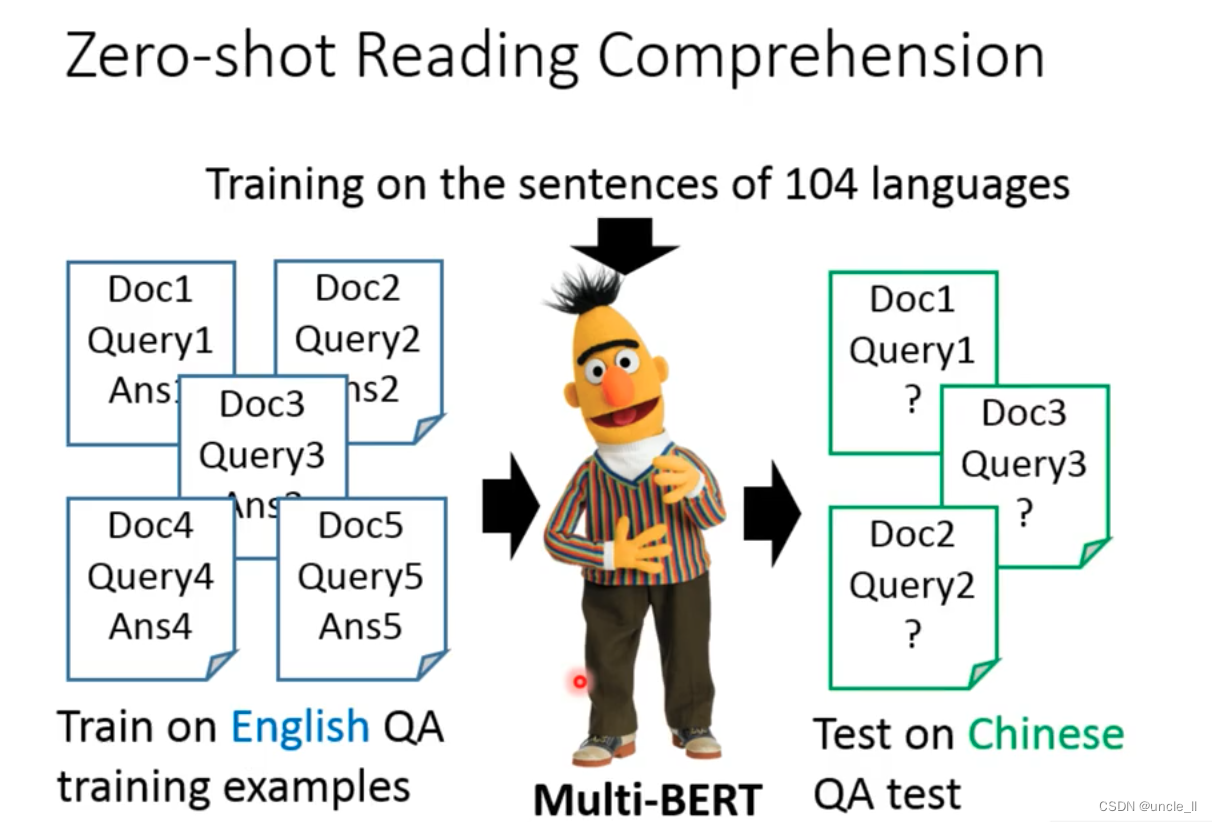
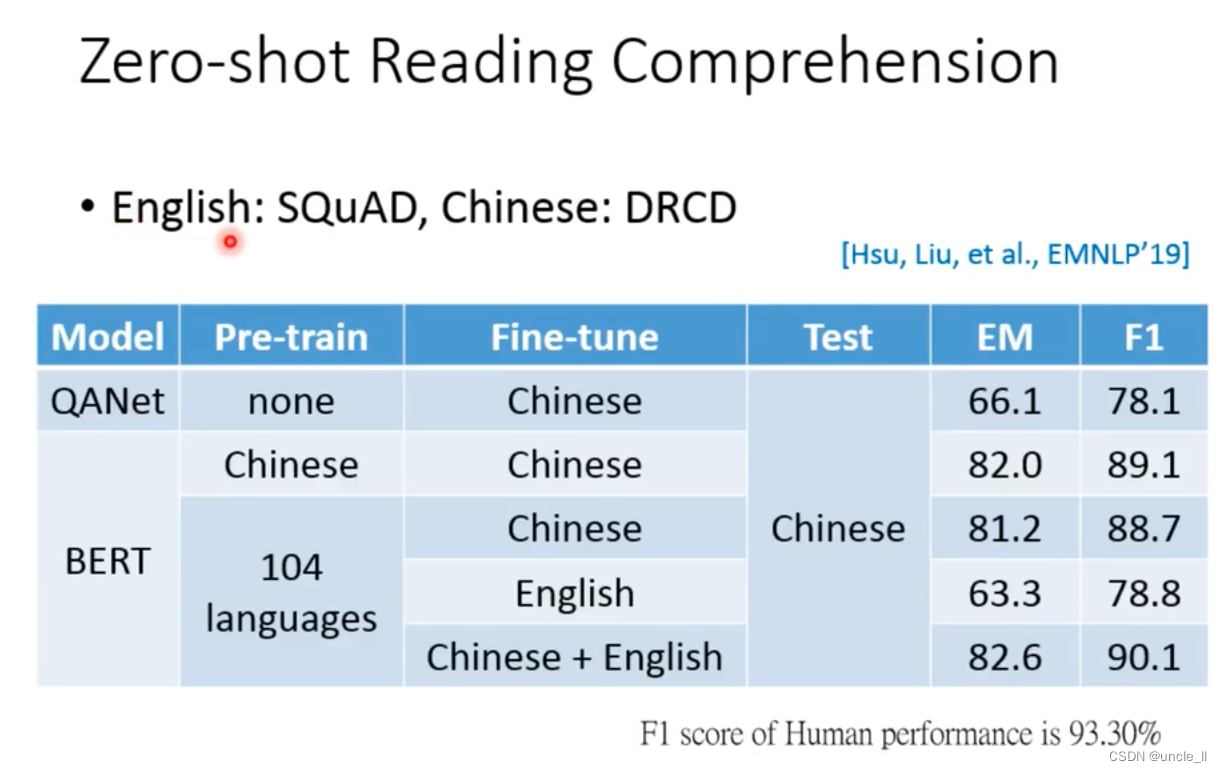
Trained on English corpus, but on Chinese QA tasks, the effect is not bad
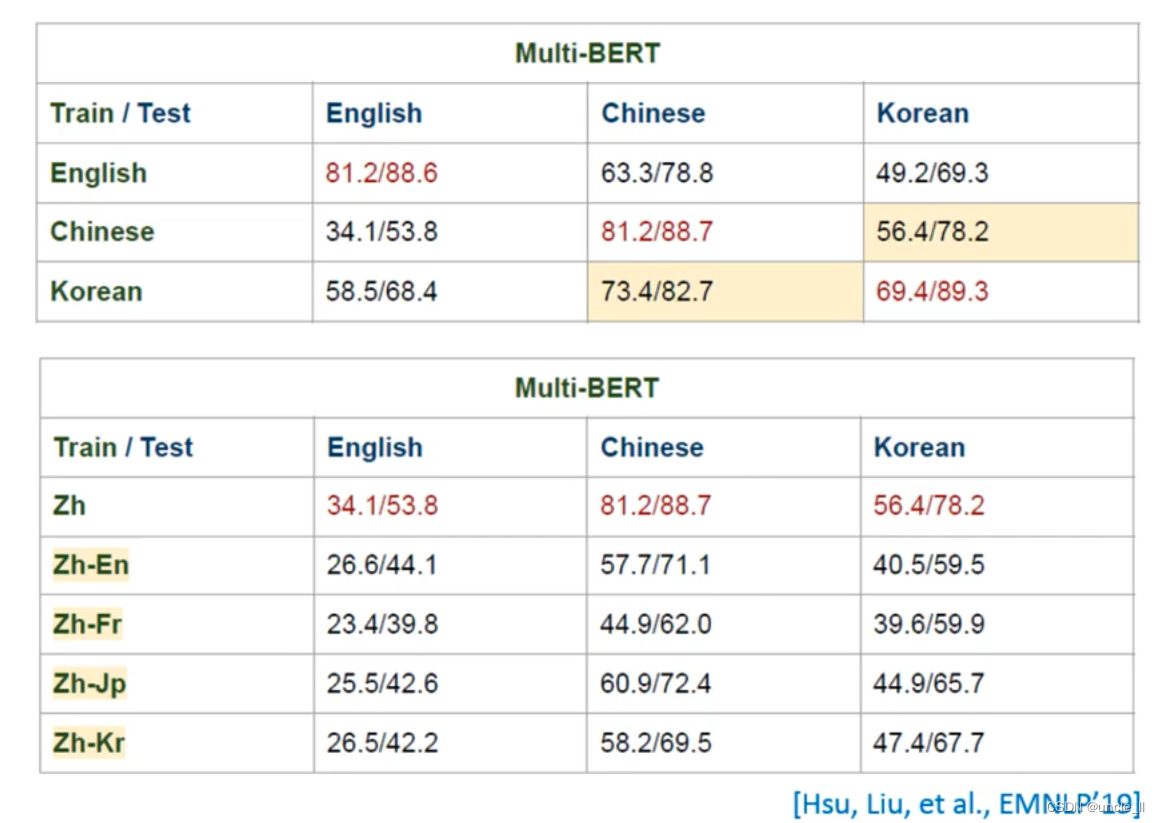
After translating Chinese into English, and then conducting English training, it was found that there was no model directly trained in Chinese.
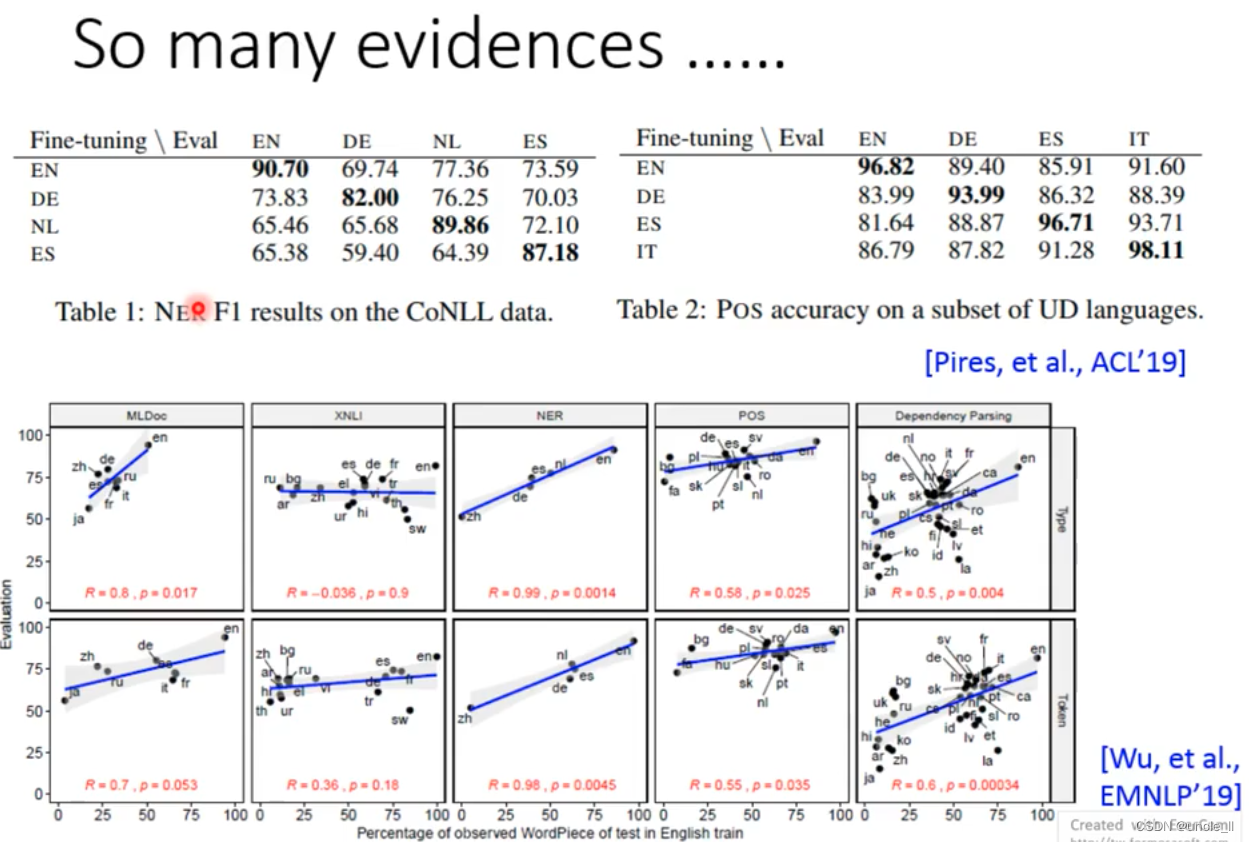
- NER
- Pire: part-of-speech tagging
Both the NER task and the part-of-speech tagging task conform to the above rules, training in one language, and then performing task processing on another voice.
Is it possible to handle Oracle?
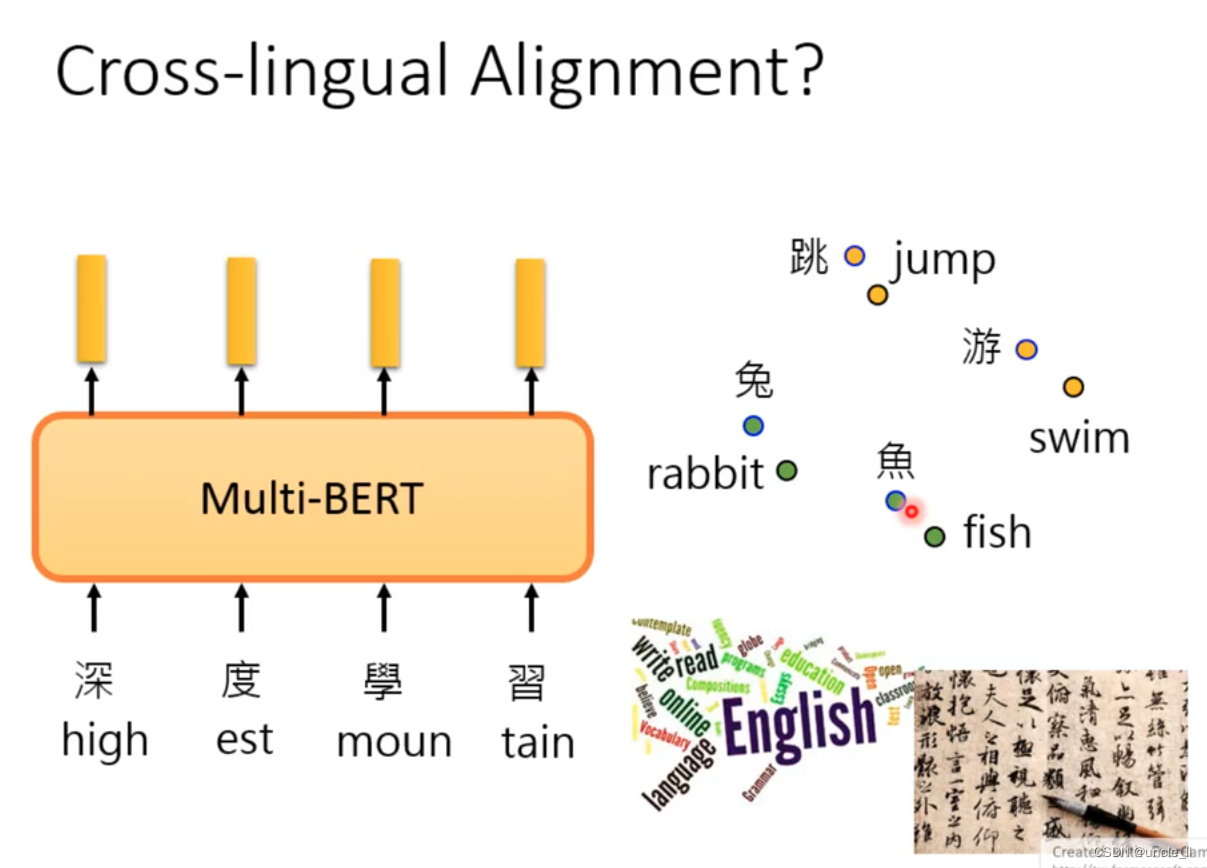
Cross-lingual Alignment
The Chinese rabbit embedding is relatively close to the English rabbit embedding. The model may have removed the characteristics of the speech and only considered the meaning.
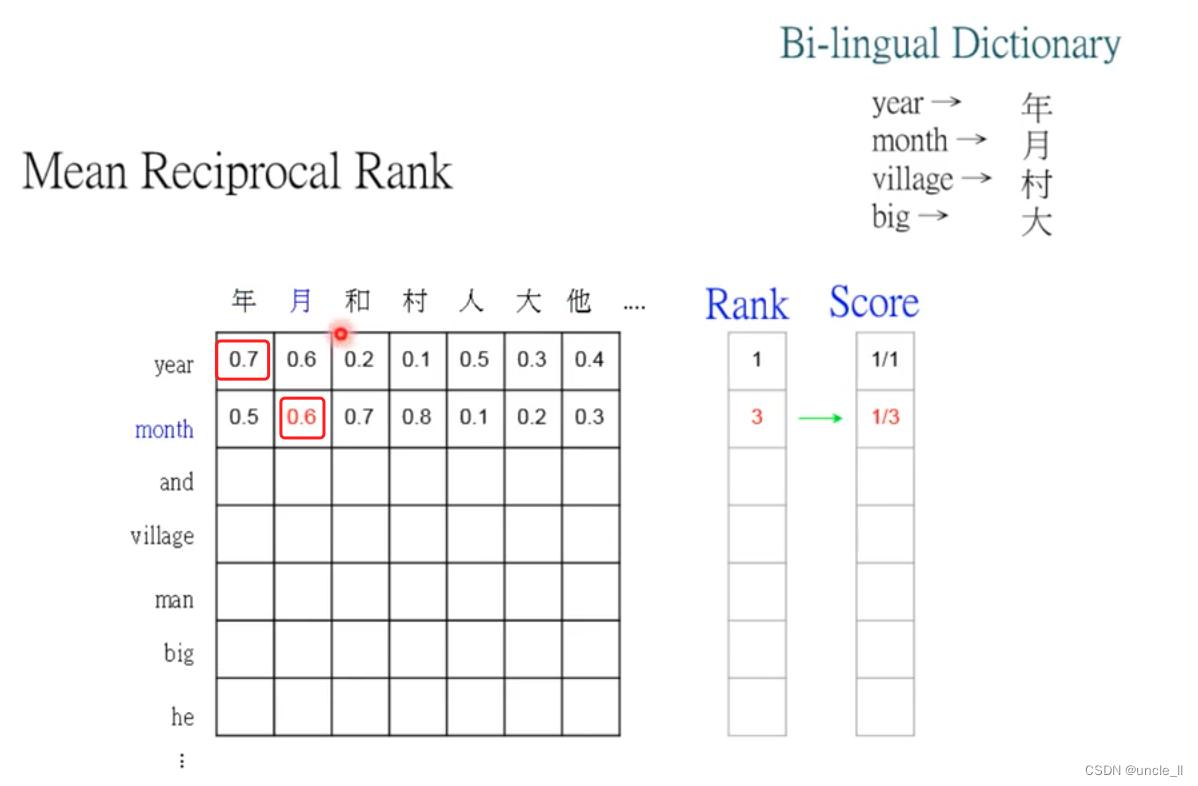
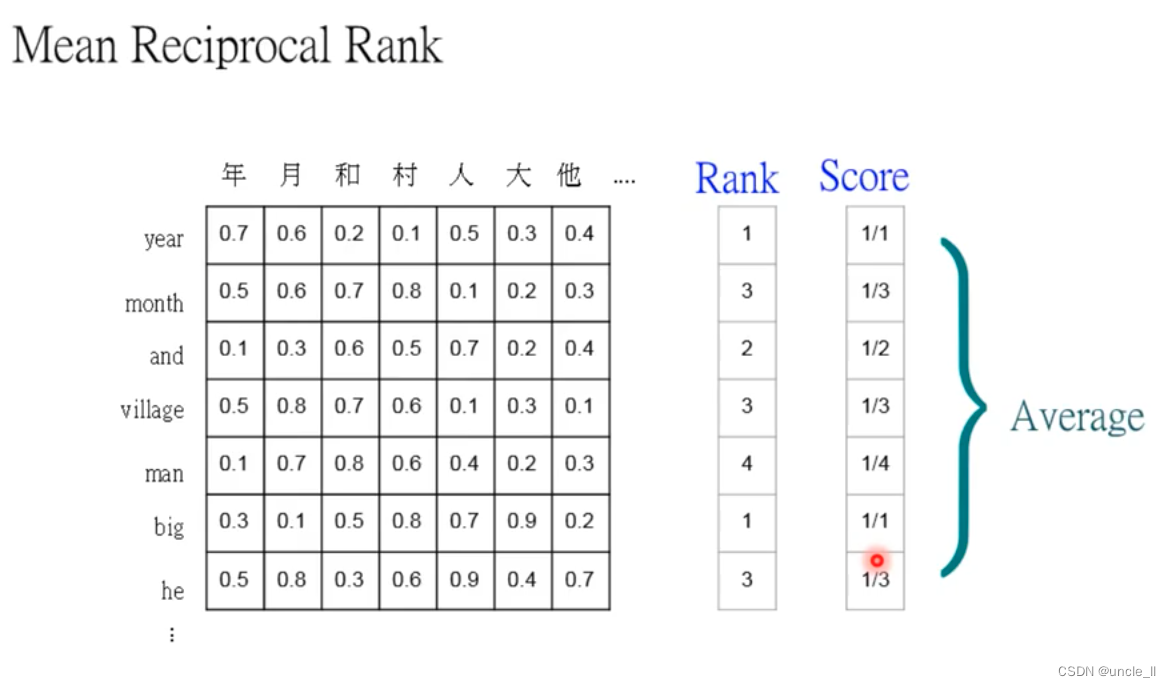
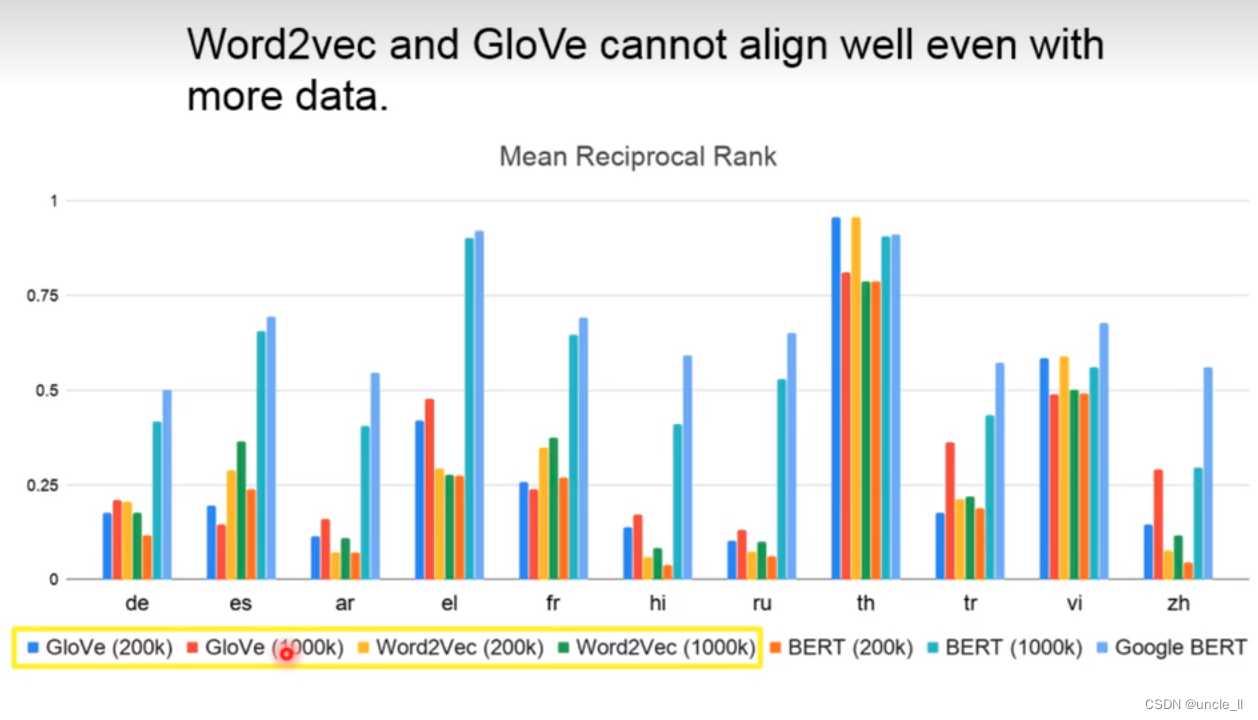
Year ranks first, month ranks third, and the corresponding score is the reciprocal of rank
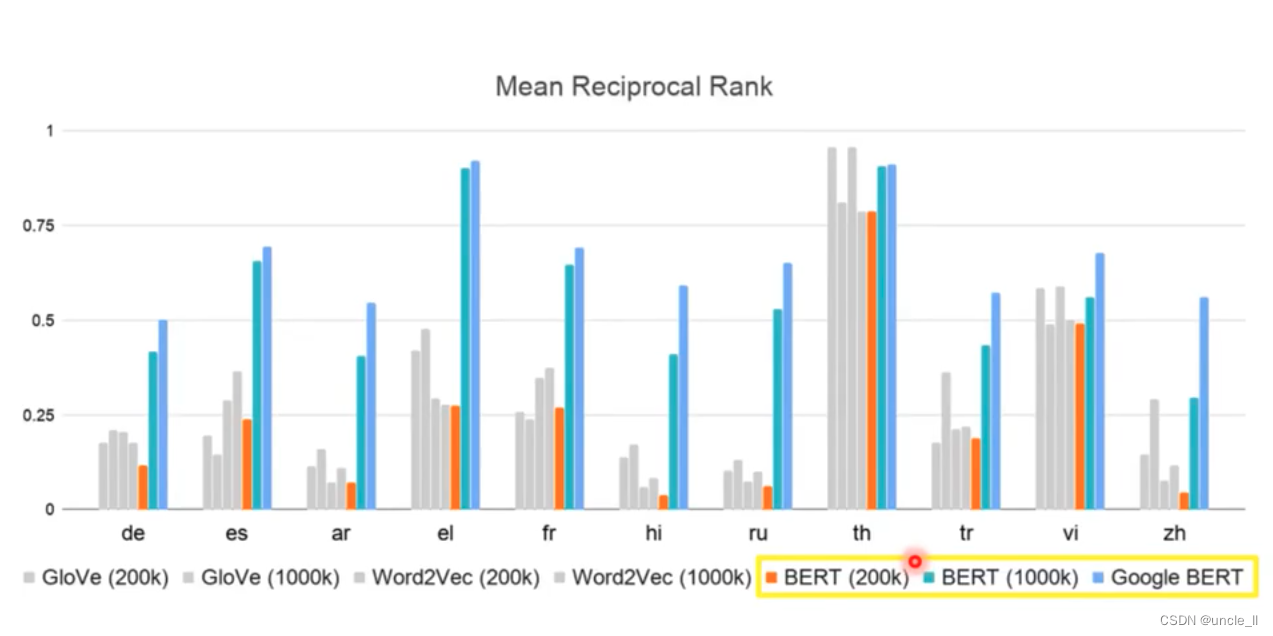
The amount of data needs to be very large to have better results, as can be seen from the results of BERT200k and BERT1000k.
The same experiment was carried out on the traditional algorithms GloVe and Word2Vec, and it was found that Bert's effect is still better than the previous algorithm.
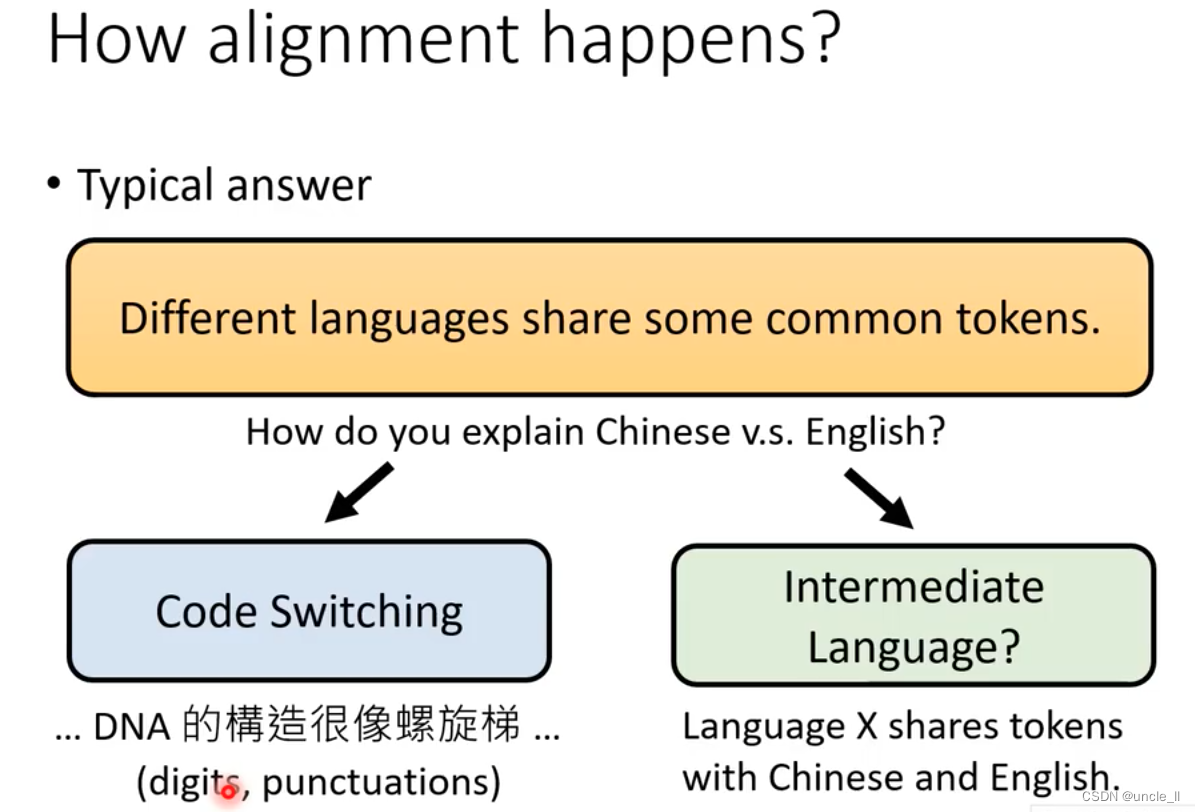
How alinment happens
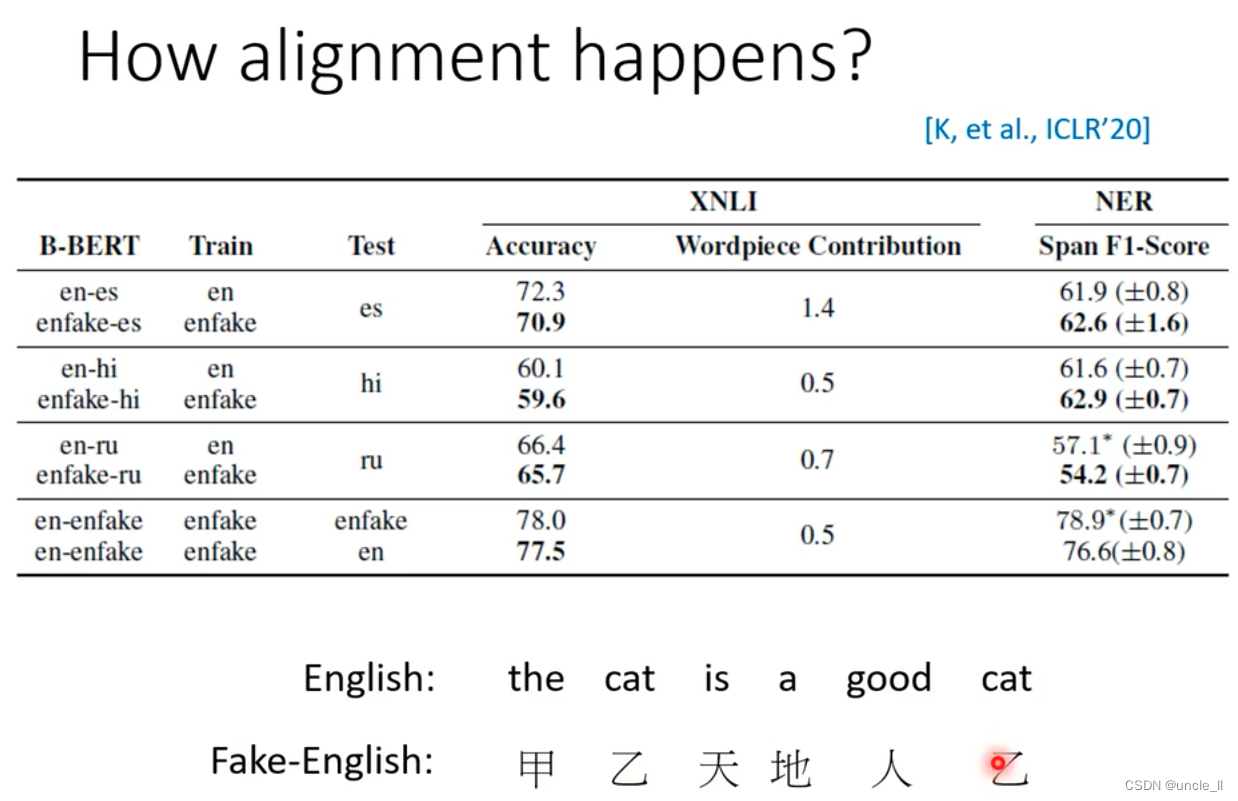
Use fake-english instead of real english, and then train. The cross-language ability does not require the existence of intermediary voice.
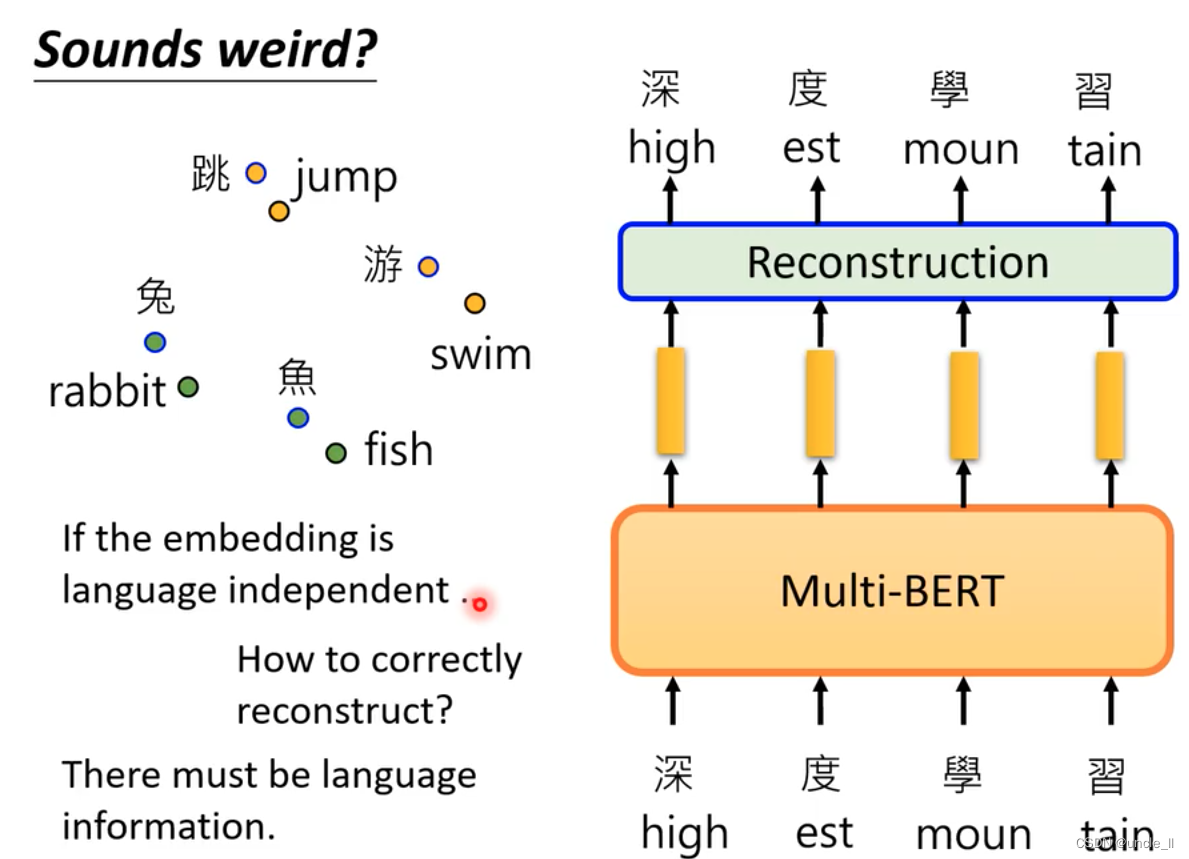
Bert knows the language information, but doesn't care much about the language type.
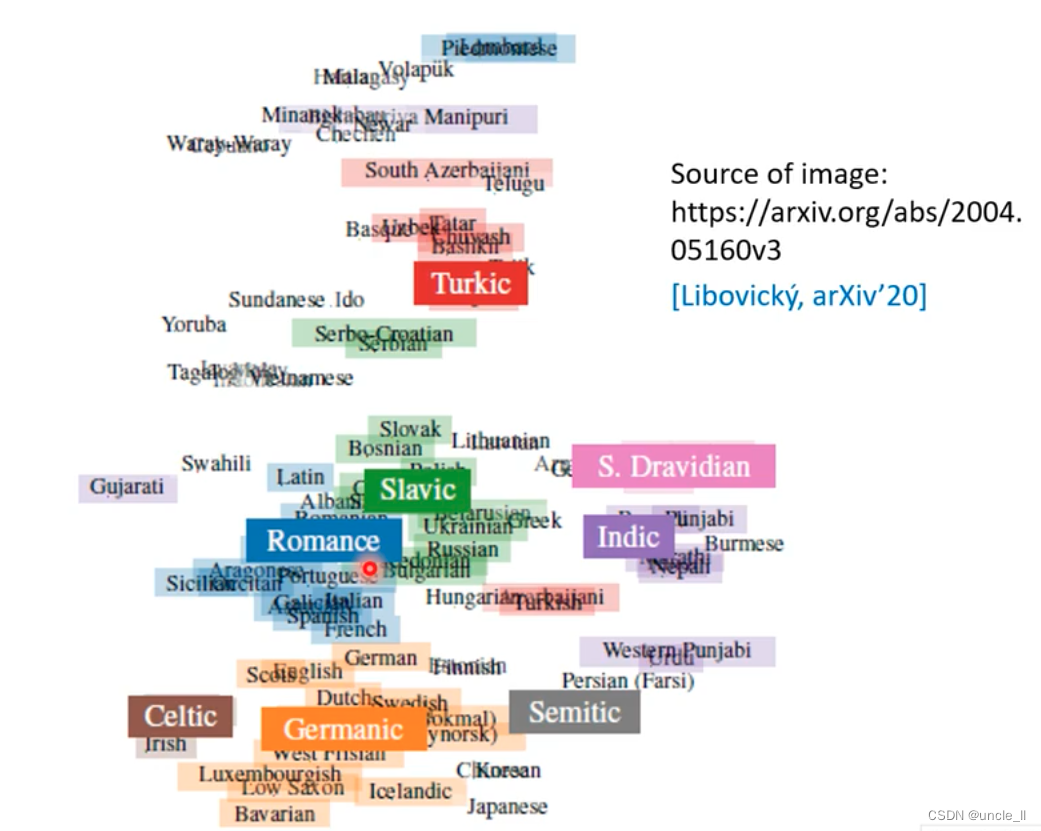
Each string of text represents a language, and there are still some gaps in the language.
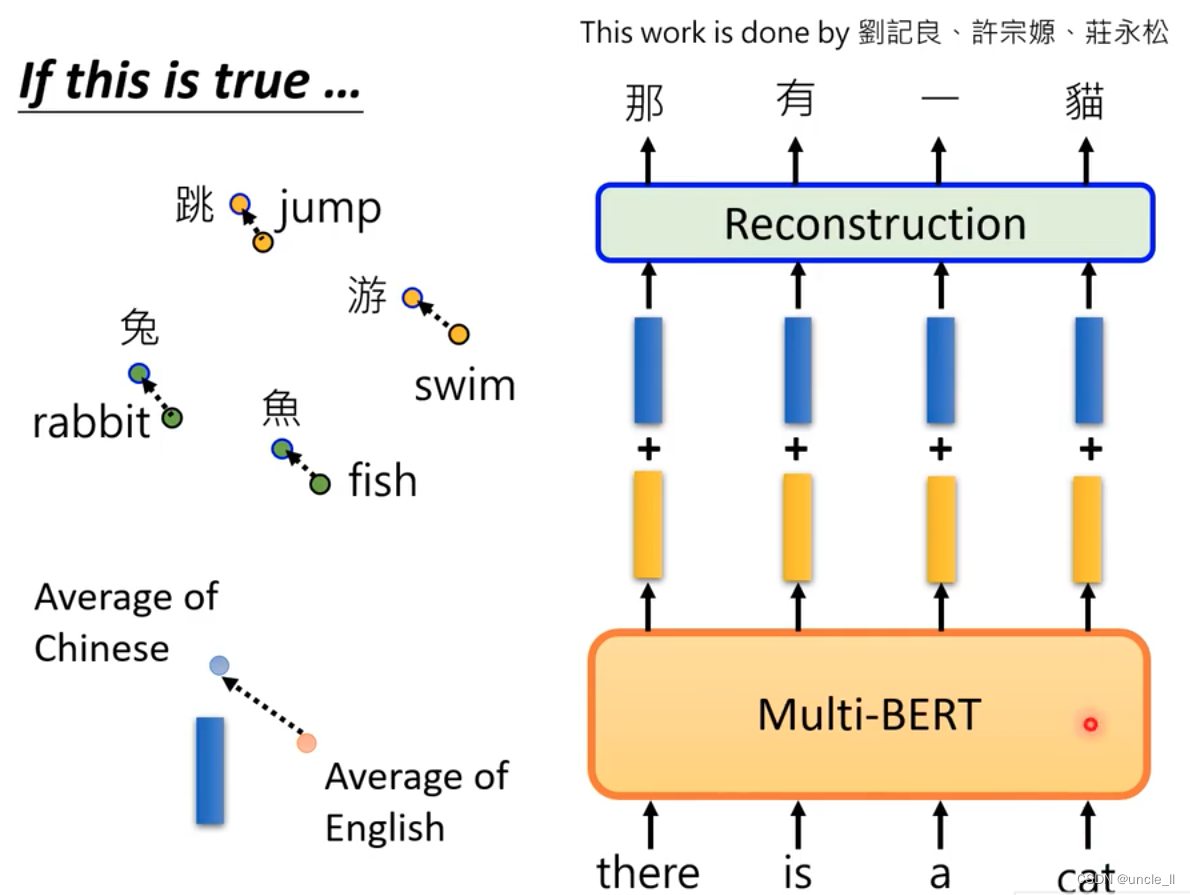

Yellow is the English code, blue is the Chinese code, the two are fused together and controlled by α:
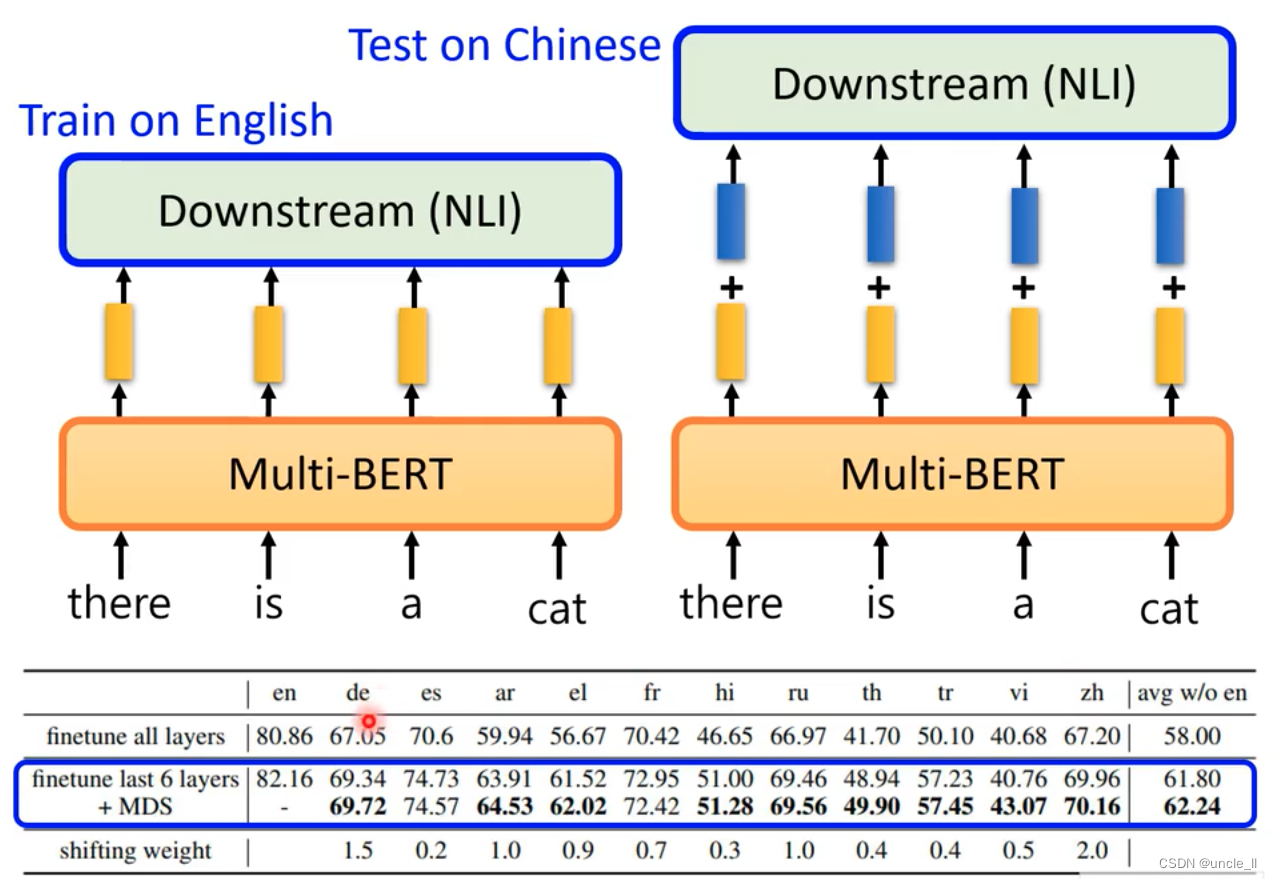
Perform fine-tune on English, and then test on Chinese to make the embedding more like Chinese. In the testing phase, adding blue vectors will improve the effect.