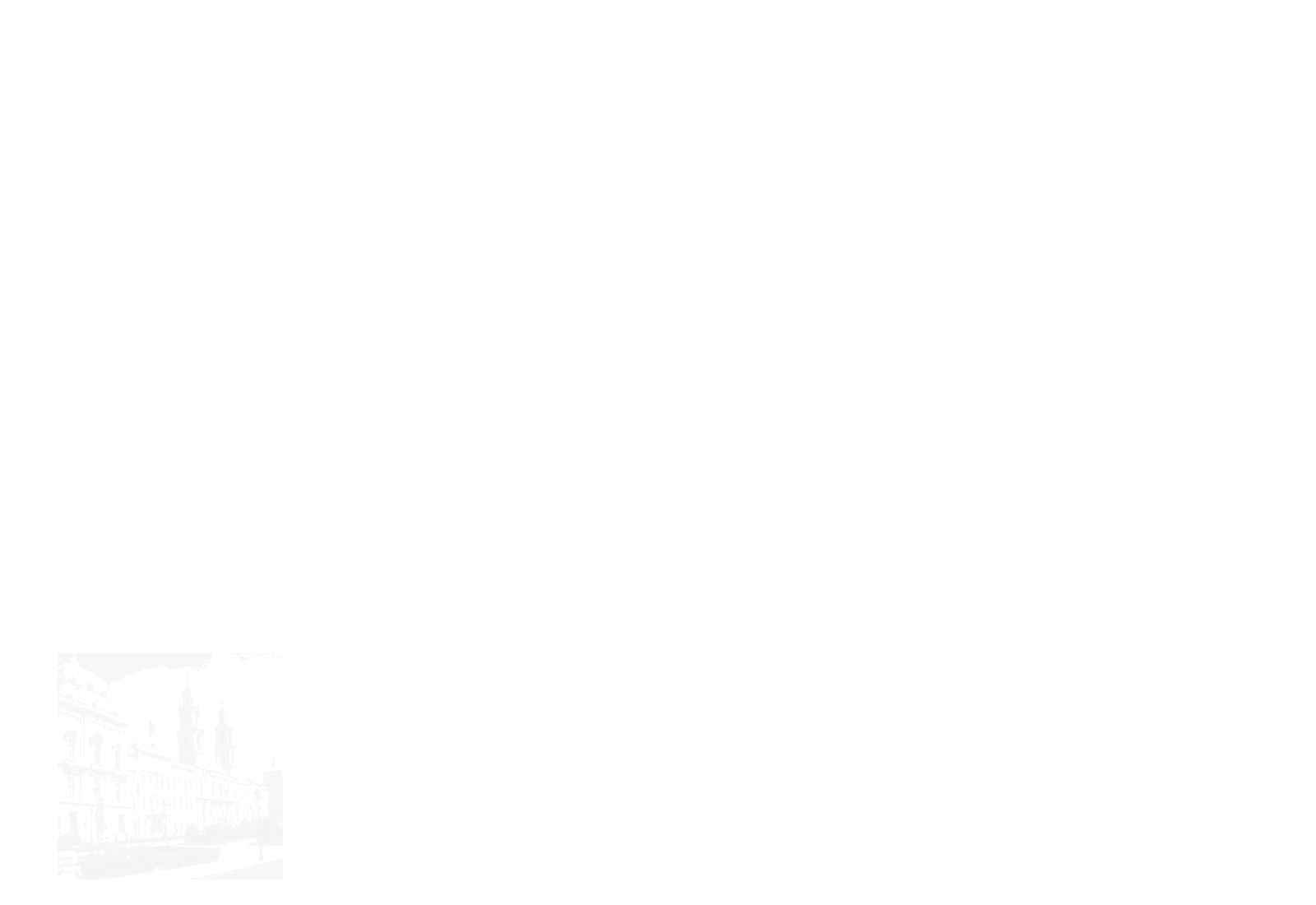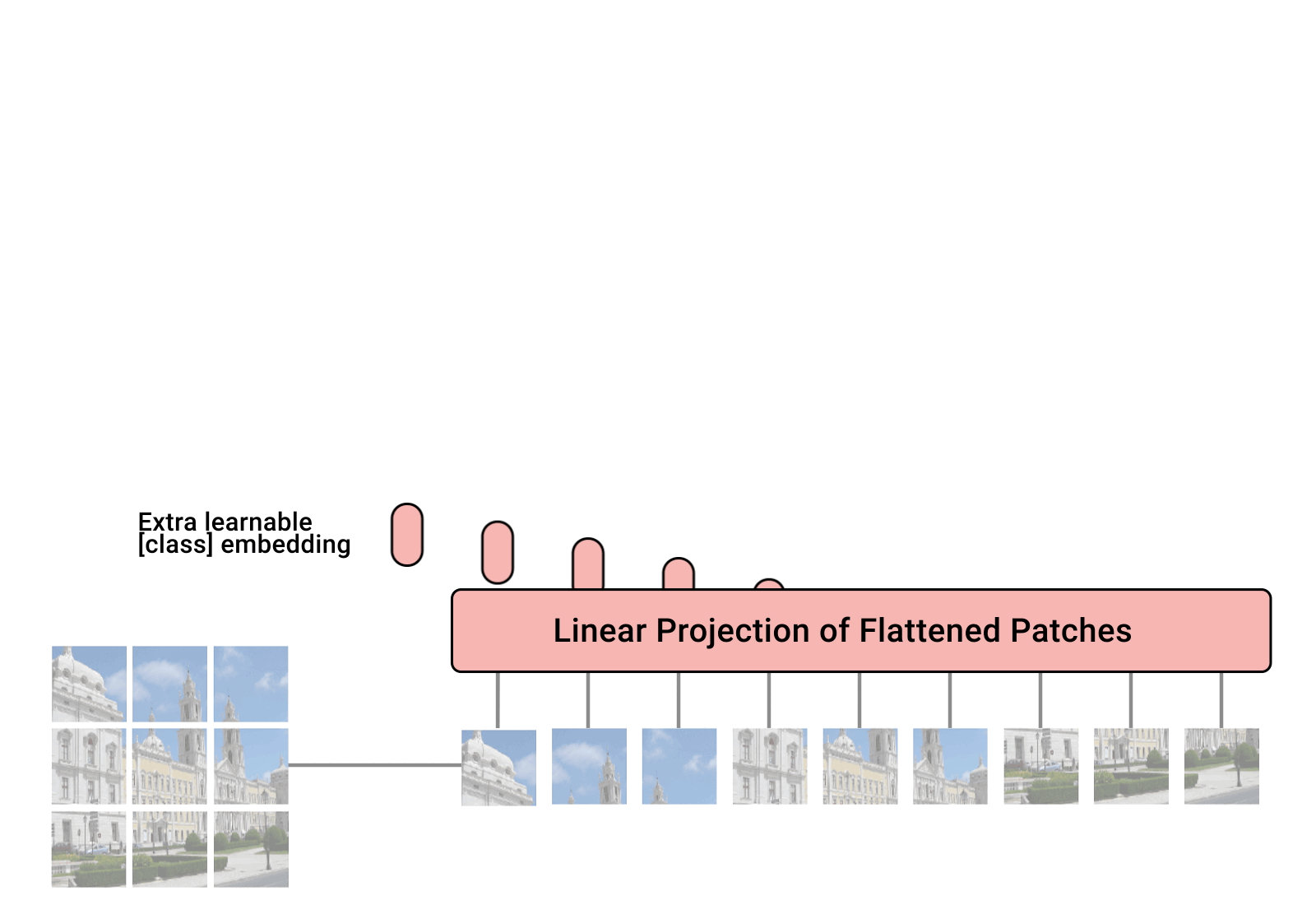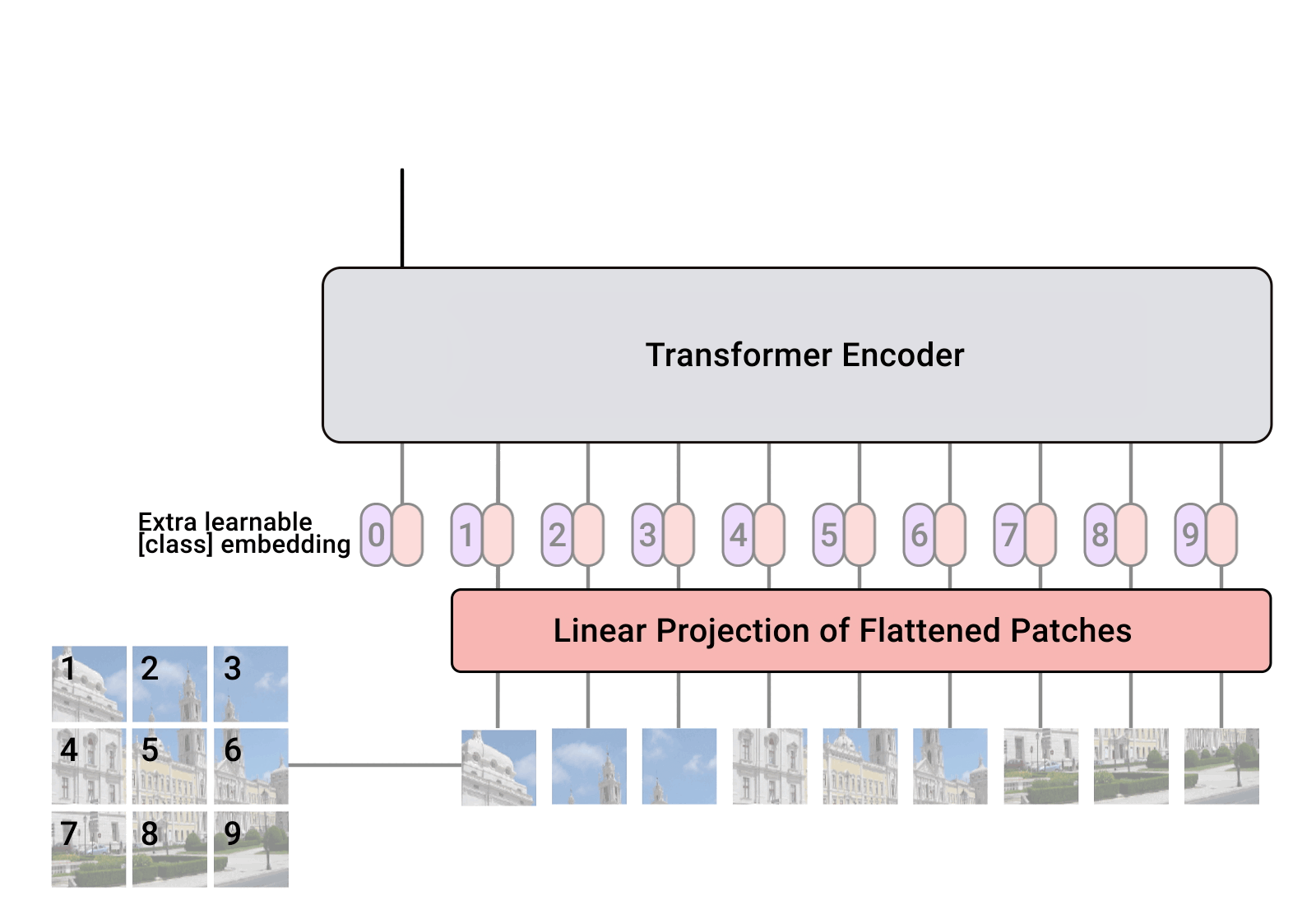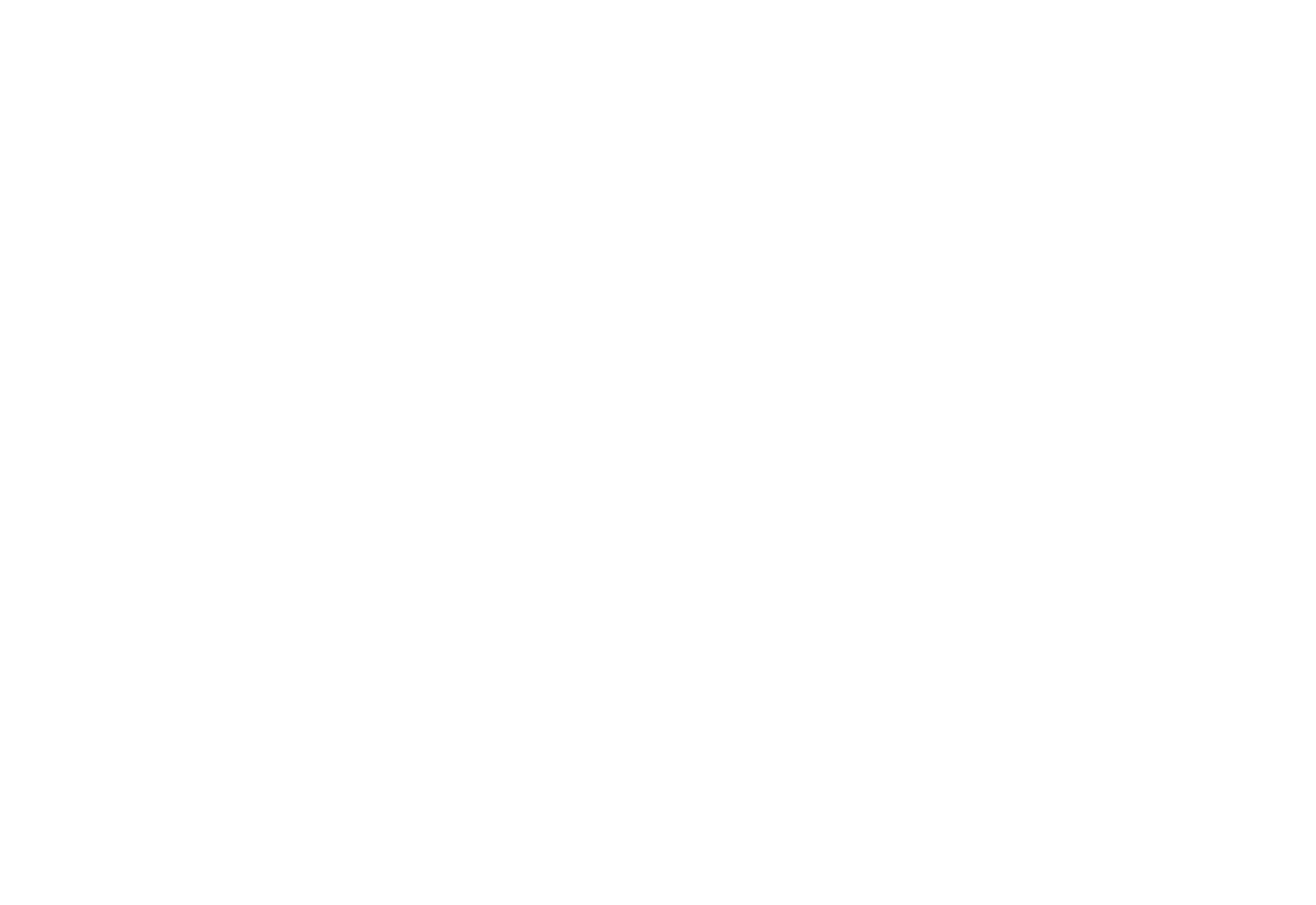In 2022, Vision Transformers (ViT) will become a serious competitor to Convolutional Neural Networks (CNNs), which are now state-of-the-art in computer vision and widely used in many image recognition applications. The ViT model outperforms the current state-of-the-art (CNN) by almost four times in terms of computational efficiency and accuracy .
1. How does the Vision Translator (ViT) work?
The performance of the visual translator model is determined by decisions such as optimizer, network depth, and dataset-specific hyperparameters. CNN is easier to optimize than ViT. The difference between a pure Transformer and a CNN front-end is combining a Transformer with a CNN front-end. Standard ViT stemming uses 16*16 convolutions with a stride of 16. In contrast, a 3*3 convolution with a stride of 2 improves stability and accuracy.