How to install Torch

study method
- 1. Learn while using, torch is just a tool, and the process of actually using it is the process of learning
- 2. Just go to the case directly, run first, and solve what you encounter
Mnist classification task:
-
Basic network construction and training methods, common function analysis
-
torch.nn.functional module
-
nn.Module module
Read the Mnist dataset
- will automatically download
# 查看自己的torch的版本
import torch
print(torch.__version__)
%matplotlib inline
# 前两步,不用管是在网上下载数据,后续的我们都是在本地的数据进行操作
from pathlib import Path
import requests
DATA_PATH = Path("data")
PATH = DATA_PATH / "mnist"
PATH.mkdir(parents=True, exist_ok=True)
URL = "http://deeplearning.net/data/mnist/"
FILENAME = "mnist.pkl.gz"
if not (PATH / FILENAME).exists():
content = requests.get(URL + FILENAME).content
(PATH / FILENAME).open("wb").write(content)
import pickle
import gzip
with gzip.open((PATH / FILENAME).as_posix(), "rb") as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
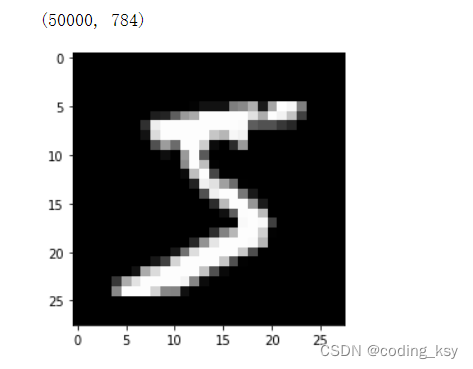
784 is the number of pixels per sample in the mnist dataset
from matplotlib import pyplot
import numpy as np
pyplot.imshow(x_train[0].reshape((28, 28)), cmap="gray")
print(x_train.shape)
The structure of the fully connected neural network
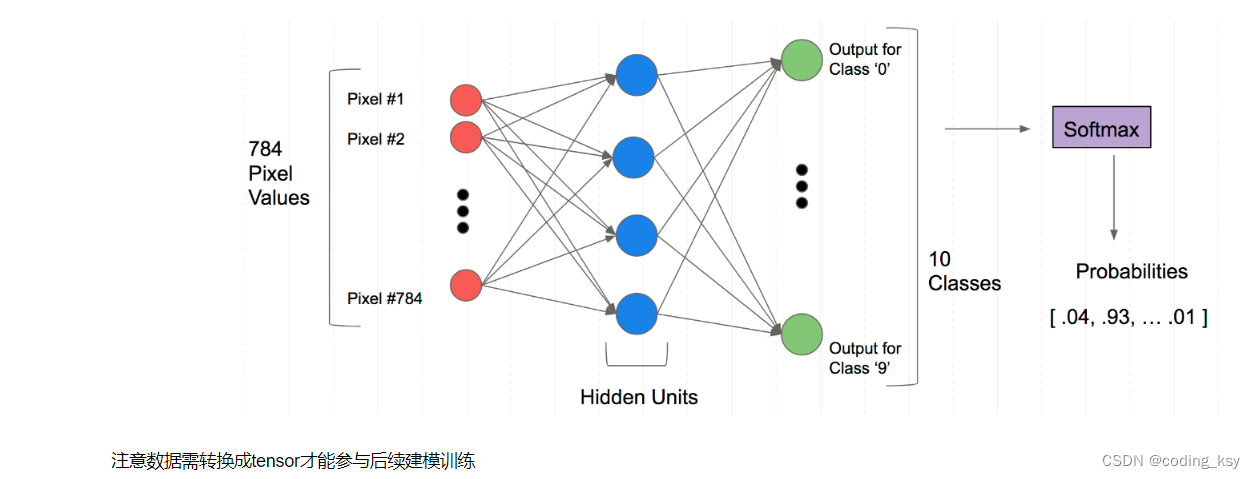 Note that the data needs to be converted into tensor to participate in subsequent modeling training
Note that the data needs to be converted into tensor to participate in subsequent modeling training
import torch
x_train, y_train, x_valid, y_valid = map(
torch.tensor, (x_train, y_train, x_valid, y_valid)
)
n, c = x_train.shape
x_train, x_train.shape, y_train.min(), y_train.max()
print(x_train, y_train)
print(x_train.shape)
print(y_train.min(), y_train.max())
torch.nn.functional Many layers and functions will be seen here
There are many functions in torch.nn.functional, which will be commonly used in the future. So when to use nn.Module and when to use nn.functional? In general, if the model has learnable parameters, it is best to use nn.Module, and nn.functional is relatively simpler in other cases
import torch.nn.functional as F
loss_func = F.cross_entropy
def model(xb):
return xb.mm(weights) + bias
bs = 64
xb = x_train[0:bs] # a mini-batch from x
yb = y_train[0:bs]
weights = torch.randn([784, 10], dtype = torch.float, requires_grad = True)
bs = 64
bias = torch.zeros(10, requires_grad=True)
print(loss_func(model(xb), yb))
Create a model to simplify the code more
- Must inherit nn.Module and call the constructor of nn.Module in its constructor
- No need to write backpropagation function, nn.Module can use autograd to automatically implement backpropagation
- The learnable parameters in the Module can return an iterator through named_parameters() or parameters()
from torch import nn
class Mnist_NN(nn.Module):
# 构造函数
def __init__(self):
super().__init__()
self.hidden1 = nn.Linear(784, 128)
self.hidden2 = nn.Linear(128, 256)
self.out = nn.Linear(256, 10)
self.dropout = nn.Dropout(0.5)
#前向传播自己定义,反向传播是自动进行的
def forward(self, x):
x = F.relu(self.hidden1(x))
x = self.dropout(x)
x = F.relu(self.hidden2(x))
x = self.dropout(x)
#x = F.relu(self.hidden3(x))
x = self.out(x)
return x
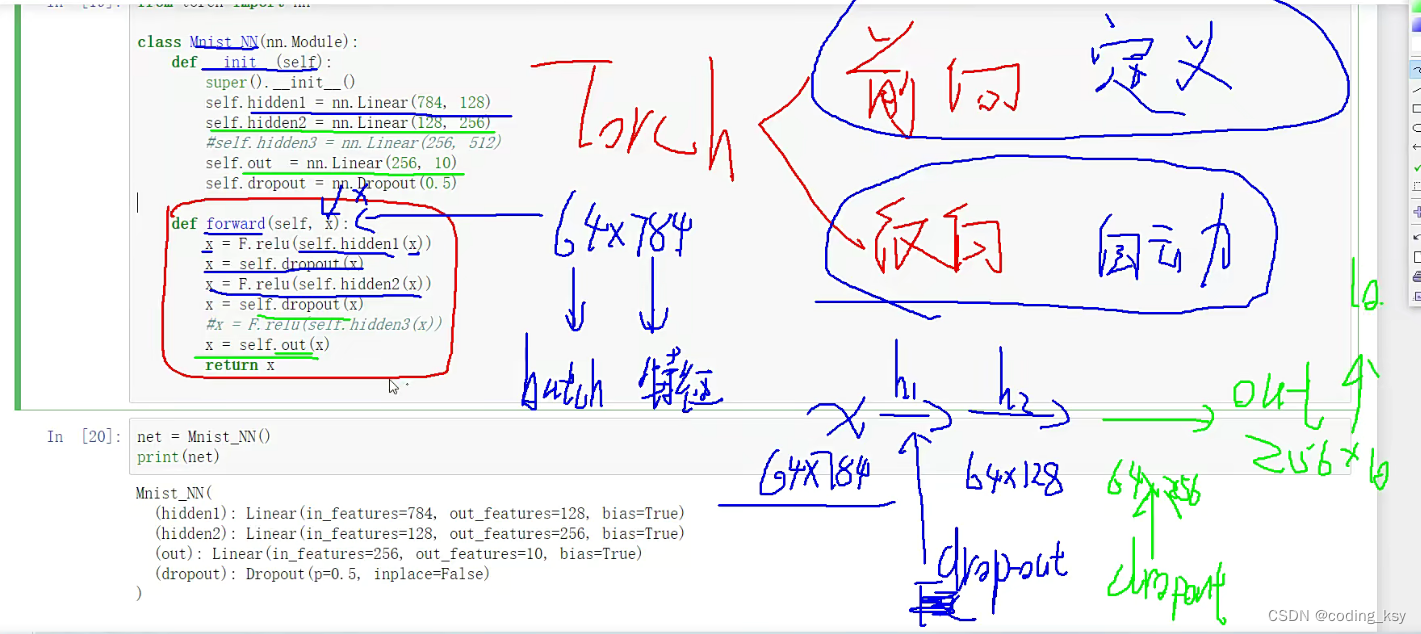
net = Mnist_NN()
print(net)
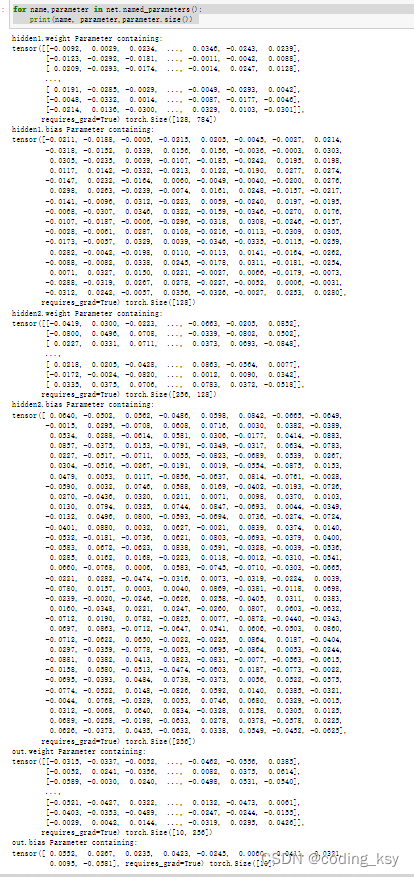
You can print the weights and biases in the names we defined
for name,parameter in net.named_parameters():
print(name, parameter,parameter.size())
Use TensorDataset and DataLoader to simplify
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
train_ds = TensorDataset(x_train, y_train)
train_dl = DataLoader(train_ds, batch_size=bs, shuffle=True)
valid_ds = TensorDataset(x_valid, y_valid)
valid_dl = DataLoader(valid_ds, batch_size=bs * 2)
def get_data(train_ds, valid_ds, bs):
return (
DataLoader(train_ds, batch_size=bs, shuffle=True),
DataLoader(valid_ds, batch_size=bs * 2),
)
- Generally, model.train() is added when training the model, so that Batch Normalization and Dropout will be used normally
- When testing, generally choose model.eval(), so that Batch Normalization and Dropout will not be used
import numpy as np
def fit(steps, model, loss_func, opt, train_dl, valid_dl):
for step in range(steps):
model.train() # 训练的时候需要更新权重参数
for xb, yb in train_dl:
loss_batch(model, loss_func, xb, yb, opt)
model.eval() # 验证的时候不需要更新权重参数
with torch.no_grad():
losses, nums = zip(
*[loss_batch(model, loss_func, xb, yb) for xb, yb in valid_dl]
)
val_loss = np.sum(np.multiply(losses, nums)) / np.sum(nums)
print('当前step:'+str(step), '验证集损失:'+str(val_loss))
usage of zip
a = [1,2,3]
b = [4,5,6]
zipped = zip(a,b)
print(list(zipped))
a2,b2 = zip(*zip(a,b))
print(a2)
print(b2)
from torch import optim
def get_model():
model = Mnist_NN()
return model, optim.SGD(model.parameters(), lr=0.001)
def loss_batch(model, loss_func, xb, yb, opt=None):
loss = loss_func(model(xb), yb)
if opt is not None:
loss.backward()
opt.step()
opt.zero_grad()
return loss.item(), len(xb)
Three lines get it done!
train_dl,valid_dl = get_data(train_ds, valid_ds, bs)
model, opt = get_model()
fit(100, model, loss_func, opt, train_dl, valid_dl)

correct = 0
total = 0
for xb,yb in valid_dl:
outputs = model(xb)
_,predicted = torch.max(outputs.data,1)
total += yb.size(0)
correct += (predicted == yb).sum().item()
print(f"Accuracy of the network the 10000 test imgaes {
100*correct/total}")
![Insert picture description here](https://img-blog.csdnimg.cn/89e5e749b680426c9700aac9f93bf76a.png
Those who are interested in the later period can compare the two optimizers of SGD and Adam, which one is better
-SGD 20epoch 85%
-Adam 20epoch 85%