introduction
Xiongguan Road is really like iron, and now it is over from the beginning. This chapter will start to learn the binary tree (the full text is 12,000 words in total). Compared with the previous data structure, the binary tree will have a lot of difficulty, but as long as you follow the in-depth study of this blog, you can basically master the basic binary tree.
Not much to say, fasten your seat belt, let's start the car (recommended to watch on computer) .

Attachment: red, the part is the key part; the blue color is the part that needs to be memorized (not rote memorization, knock more); black bold or other colors are the secondary key points; black is the description need
Table of contents
2.1 The concept of binary tree
2.2 Sequential structure of binary tree
Implementation of the heap (function to be implemented):
Application of up and down adjustments:
1. Upward and downward adjustment methods of direct heap building:
2. Realize ascending and descending order by size heap
2.3 Chain structure of binary tree
2.3.1 Preorder, inorder and postorder
2.3.2 Find the number of nodes in the binary tree:
2.3.3 Find the height of the binary tree
2.3.4 Find the Kth layer node in the binary tree
2.3.5 Finding Nodes in a Binary Tree
Exercise: Determine whether a binary tree is a complete binary tree
1. The concept of a tree
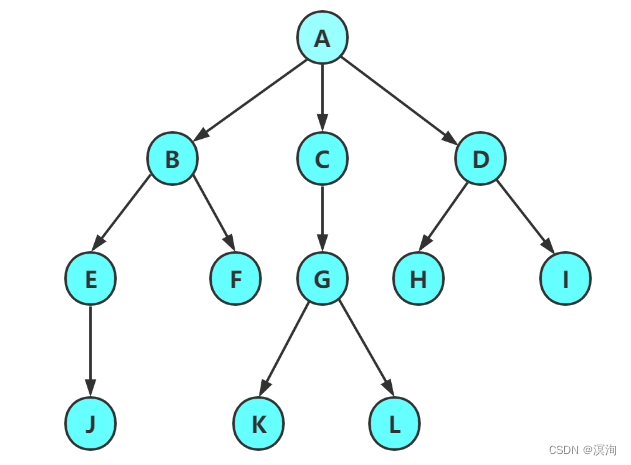
A tree is a non-linear data structure. It is called a tree because its structure is very similar to the reversed form of a tree in reality. Each data is called a node. In a tree The top node is also called the root node (the root node has no predecessor node), and each node can be called a tree (or subtree). Each tree is composed of multiple subtrees. And each node will have one and only one predecessor node and multiple or zero successor nodes. Each subtree in the tree cannot have an intersection (disjoint with each other), a tree with n nodes has n-1 parent nodes (it is often used to describe the relationship in the tree)
- Parent node (parent node): the predecessor node of a node (A in the above figure is the parent node of BCD)
- Child node: the successor node of a node (the child node of A has BCD)
- Degree : the number of child nodes each node has (the degree of A is 3)
- The degree of the tree : the maximum degree of all nodes in a tree (the above tree is the largest degree of A, so the degree of the tree is 3)
- The level of the node: counting from the root, the level of the root is 1 and then backward.... (so the level of A is 1, and the level of j is 4)
- Height (depth) : Generally speaking, it also starts from 1, and the depth/height of the above picture is 4 (there will be some disputes that start from 0)
- Leaf (child) node (terminal node): A node with a degree of 0 or a node that can be regarded as having no child nodes is a leaf node (such as J, K, L, H, I, F)
- Branch node (non-terminal node): Nodes that are not leaf nodes are considered branch nodes or nodes with a non-zero degree (the rest of the nodes in the above figure except leaf nodes can be regarded as branch nodes)
- Brother nodes: nodes with the same parent node (as in the BCD above, they are all sibling nodes)
- Cousin node: a node whose parent node is at the same level (such as F and G)
- Ancestor node: all nodes passed from the root to this node
- Descendants: All the nodes after the node can be regarded as the descendants of the node (all nodes in the above figure are A)
- Forest: multiple disjoint trees
Application: directory tree (represented by left-child right-sibling structure)
2. Binary tree
2.1 The concept of binary tree
Binary tree is a special kind of tree in the tree, in which the maximum degree of binary tree is 2, and the child nodes of each node at this time are called left child and right child (left subtree, right subtree)
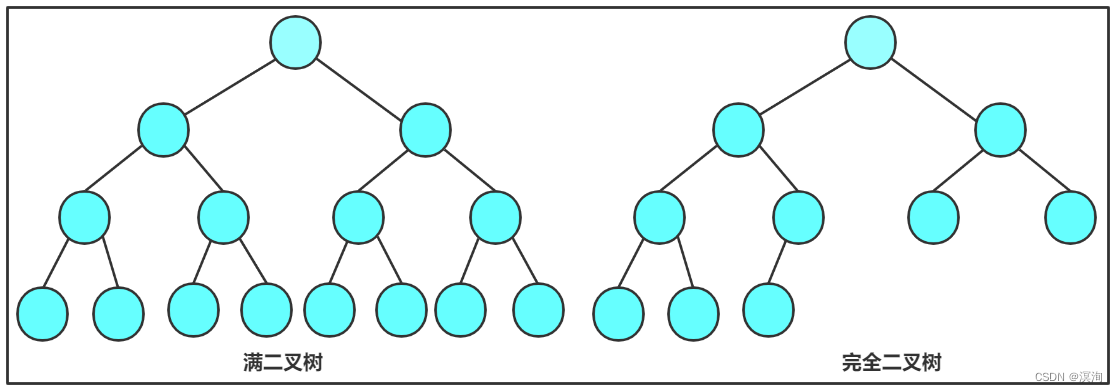
- Full binary tree: except the leaf node degree is 0, the degree of other nodes is 2, each layer is full
- A full binary tree of h levels, with (2 ^ h) - 1 nodes
- Complete binary tree: For a complete binary tree of height h, the first h-1 layers are full, and the last layer can be full, but the last layer must be continuous from left to right
- A complete binary tree with h layers has 2 ^ ( h - 1 ) ~ ( 2 ^ h ) - 1
- In the binary tree, the maximum number of nodes in the hth layer is: 2 ^ (h - 1) (if the binary tree is full, it is directly equal to it)
- A binary tree with h layers has a maximum number of nodes ( 2 ^ h ) - 1
- For a non-empty binary tree, node n0 with degree 0 = node n2 + 1 with degree 2: n0 = n2 + 1
- In a complete binary tree, a node with a degree of 1 can only be 1 / 0; when the number of nodes in the tree is even, the number of nodes with a degree of 1 is 1, and when it is odd, it is 0

2.2 Sequential structure of binary tree
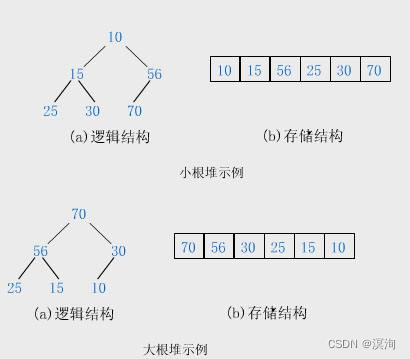
The structure of the binary tree can be realized by the sequence and linked list structure. For the general binary tree, it is not suitable to use the sequential structure to store, because there will be a lot of waste of space for some places without nodes. The complete binary tree is very suitable for the sequential structure. In reality, usually Store the heap (a binary tree) in an array of sequential structures
2.2.1 Heap:
- is a complete binary tree
- Large heaps : all parent nodes in the tree are larger than child nodes
- Small heaps : all parent nodes in the tree are smaller than child nodes
- Relationship between parent node and child node
- Parent node to left child: leftchild = parent * 2 + 1
- Parent node to left child: leftchild = parent * 2 + 2
- Left and right children to parent node: parent = (child - 1) / 2
- For the heap structure, we need to understand its logical structure and physical structure
- In terms of logical structure, he is a complete binary tree
- In terms of physical structure, its bottom layer is stored in an array
- We need to remember his underlying array to describe this complete binary tree
Implementation of the heap (function to be implemented):
- Initialization (mainly for the space required by the sequential structure)
- destroy
- insert data
- Heap Upscaling Algorithm
- Approximate algorithm principle: compare the position of the given child with the parent node, and if it is greater than/less than, exchange (large heap/small heap) Loop judgment If the child reaches the top of the heap, stop
- The time complexity is: O(N*logN)
- delete data
- heap adjustment algorithm
- Approximate algorithm principle: given the number of parent nodes and the tree, then let the parent node and child nodes compare, if greater/less than, exchange (small heap/large heap) loop judgment, stop if the child node does not exist
- The time complexity is: O(N)
- Get the data at the top of the heap, check how many data are in the heap, and judge the heap as empty
The specific details will have detailed notes in the implementation (notes are very important in our future work, so it can be written as a habit)
#define _CRT_SECURE_NO_WARNINGS 1 #include"Heap.h" void If_Add_Capacity(HP* php) { if (php->_size == php->_capacity)//判断已有成员个数是否等于容量,若等则进去 { HPDataType* ptr = (HPDataType*)realloc(php->_a, sizeof(HPDataType) * php->_capacity * 2);//进来后就说明空间不够了,需要开空间 //一般多直接开辟比容量大两倍的空间 即 对a开辟结构体大小为原capacity两倍的空间 if (ptr == NULL) { perror("realloc"); return; } php->_a = ptr;//因为可能是异地扩容所以还要将ptr赋值给数组a php->_capacity *= 2;//容量 乘于 2 ptr = NULL;//无用的指针置为NULL(好习惯) } } //对于堆的初始化和销毁就不过多赘述了相信通过我前面的几篇文章已经能很好的了解其原理了! void HeapInit(HP* php) { assert(php); php->_capacity = 4; php->_a = (HPDataType*)malloc(sizeof(HPDataType)* (php->_capacity)); if (php->_a == NULL) { perror("php::malloc"); return; } php->_size = 0; } void HeapDestroy(HP* php) { assert(php); free(php->_a); php->_capacity = php->_size = 0; php->_a = NULL; } //---------------------------------------------------------------- void swap(HPDataType* t1, HPDataType* t2) { HPDataType tmp = *t1; *t1 = *t2; *t2 = tmp; } //对于向上调整来说,他能形成大堆/小堆 //此处我们先实现一个小堆 // //小堆:树中任意一个位置的父节点都要比子节点小 //父子节点的关系: leftchild = parent * 2 + 1 、rightchild = parent * 2 + 2 、parent = (child - 1)/ 2 void AdjustUp(HPDataType* a, int child) { while (child > 0)//循环来进行调整,从数组最后一直要调整到堆顶,顶部时child为0 所以条件是要大于0 { int parent = (child - 1) / 2;//找到父节点 if (a[parent] > a[child])//判断自己是否小于父节点 { swap(&a[parent], &a[child]);//若小于则进行交换 } else { break;//反之只要不小于就退出 } child = parent;//修改子节点的下标,让其不断往上走 } } //对于堆的插入我们要知道的是其实他是把数据插入到了一个数组中 //但是要注意的是,如果需要实现一个堆的话 , 那就必须是大堆 / 小堆 //所以我们不仅仅只是把数据插入数组中,而且还需要对数组中的数据进行排序 //通过排序后让他变成大、小堆 //此处就需要用到 向上调整算法 //向上调整算法的前提是在调整的树(除去刚刚插入的数据外)已经满足大堆/小堆 //而此处的数据是一个个插入的(向上调整后就形成了大堆/小堆)所以就能很好的满足这个前提条件 void HeapPush(HP* php, HPDataType x) { assert(php); If_Add_Capacity(php);//判断容量是不是满了 //首先将数据插入顺序表的尾部 php->_a[php->_size] = x; AdjustUp(php->_a, php->_size);//就行向上排序让新插入的数据也成功的融入到这个堆中 php->_size++;//一定不要忘记要增加一下size } //-------------------------------------------------------------------- //向下调整成小堆 //向下调整的原理和向上调整差不多 //只不过反了过来 void AdjustDown(int* a, int n, int parent) { //找到小的那个孩子 //建小堆的话需要父节点小于子节点 //为什么要找小的孩子呢,因为我们要找到子节点中小的那个孩子,才能避免大的孩子如果大于父节点而小的孩子却小于父节点的情况 //此处用了一种特殊的方法 //先将左孩子看成小的,再判断如果左孩子小于右孩子的话再改变child即可 int child = parent * 2 + 1; while (child < n)//要判断一下孩子节点是否在size范围内 { if (child+1 < n && a[child + 1] < a[child])//细节判断一下child+1这个节点是否存在 { child++; } if (a[child] < a[parent]) { swap(&a[child], &a[parent]); parent = child; child = parent * 2 + 1; } else{ break; } } } //堆的删除数据是将堆顶的数据删除 //而这个删除并不是像顺序表一样的进行覆盖,而是 //先将堆顶的数据和最后的数据进行交换 //交换后size--,这样就表示成把数据删除了,因为访问时是在size范围内进行的 //然后对交换到堆顶的数据进行向下调整(让他保持还原成一个堆,满足堆的条件) void HeapPop(HP* php) { assert(php); assert(!HeapEmpty(php)); swap(&php->_a[0], &php->_a[php->_size - 1]); php->_size--; AdjustDown(php->_a, php->_size ,0); } HPDataType HeapTop(HP* php){ assert(php); assert(!HeapEmpty(php)); return php->_a[0]; } bool HeapEmpty(HP* php){ assert(php); return php->_size == 0; } int HeapSize(HP* php){ assert(php); return php->_size; }
Application of up and down adjustments:
1. Upward and downward adjustment methods of direct heap building:
Upward adjustment: it is performed in a heap, we start to adjust from the second data of the array so that this precondition is ignored (because a single node can be regarded as a heap if you look up)
Downward adjustment: the left and right nodes are made in the heap, we can start to adjust from the parent node of the last leaf node so that we don’t need to consider the prerequisites (because a single node can be regarded as a heap when looking down)
In this way, if an array is given to make it into a large and small heap, a heap can be constructed by adjusting the loop up or down.
details as follows:
Build a small heap: (If you want to build a large heap, you can change the size and relationship in the up and down adjustment function to build a large heap)
void HeapSort(int* a, int n) { //原理和在堆中插入数据差不多 //向上调整建小堆 //从第二个数据开始然后不断往后 for (int i = 1; i < n; i++) { AdjustUp(a, i); } //向下调整建堆 //从最后的叶子节点的开始然后不断往前 for (int i = (n - 2) / 2; i >= 0; i--) // 最后一个叶子节点 n - 1 的父节点(( n - 1 ) - 1 )/ 2 { AdjustDown(a,n,i); } }
2. Realize ascending and descending order by size heap
Build large heaps in ascending order and small heaps in descending order
Because when we build a large pile, the parent node w point must be larger than the child node, so the root node is also the largest node at this time, you can exchange the root node and the last node, so that the largest one will be sent, and then size-- put this node first Excluding and then adjusting downwards can restore the heap, and finally loop the above process to finally achieve ascending order.
The method of Xiaodui is the same so I won’t go into details. Look through the code
//通过向下调整建小堆
for (int i = (n - 2) / 2; i >= 0; i--) // 最后一个叶子节点 n - 1 的父节点(( n - 1 ) - 1 )/ 2
{
AdjustDown(a,n,i);
}
int end = n - 1;//找到最后一个节点
while (end > 0)
{
swap(&a[0], &a[end]);//将最后的节点和堆顶元素交换下
AdjustDown(a, end, 0);//再还原一下堆
--end;//改变尾
}The time complexity here is: O(N + N*logN)==O(N*logN)
Heap's TopK problem:
Take the largest/smallest top K from the heap, build a large heap to find the largest top K, and build a small heap to find the smallest top K
Method 1: Pop k times in the large heap to find the largest top K, and pop k times in the small heap to find the smallest top k
But this method has some disadvantages: it needs to build the heap first, and when the amount of data is very large, it needs a lot of space, which will lead to insufficient memory, (applicable to the case where K is relatively small)
Method 2: If we want to find the top K largest ones, we can create a small heap of K size to store these data (so as to avoid all the data applying for space), and let them compare one by one when they are bigger than the top of the heap The reason why you can enter the heap and build a small heap: because you are looking for the largest top K, the root node of the small heap is the smallest data, only in this way can you put the large data you are looking for (the root node of the large heap is the largest of)
accomplish:
void TopK(int K) { FILE* p = fopen("TopK.txt", "r"); if (p == NULL) { perror("p"); return; } //建K大小的小堆 HPDataType* heap_arr = (HPDataType*)malloc(sizeof(HPDataType) * K); if (heap_arr == NULL) { perror("heap_arr::malloc"); return; } int i = 0; for ( i = 0;i < K; i++) { fscanf(p, "%d", &heap_arr[i]); } for (int i = (K - 2) / 2; i >= 0; i--) // 最后一个叶子节点 n - 1 的父节点(( n - 1 ) - 1 )/ 2 { AdjustDown(heap_arr, K, i);//对数组进行下下调整建堆 } //查看剩下的数据 HPDataType t = 0; while(!feof(p))//fscanf将文件中的数据读完后会设置feof的置为非0的值,故对feof取反 { fscanf(p, "%d", &t); if (heap_arr[0] < t)//查看文件中的值是否大于堆顶的数据 { heap_arr[0] = t;//大于的话这进堆 AdjustDown(heap_arr, K, 0);//然后向下调整,将堆中最小的放到堆顶 } } //打印堆的数据 for (i = 0; i < K; i++) { printf("%d\n", heap_arr[i]); } fclose(p); } void testtopk() { //生成数据放进文件中 FILE* p = fopen("TopK.txt", "w"); srand((unsigned int)time(0)); //生成一百万个随机数据放进文件中 for (int i = 1; i <= 1000000; i++) { int r = rand() % 10000; fprintf(p, "%d\n", r); } fclose(p); TopK(10);//从小堆中找最大的前k(10)个 }
2.3 Chain structure of binary tree
The structure of the chained binary tree: int val, int* right, int* left, when the left and right subtrees are NULL, it means that it has reached the end, that is, for the chained binary tree, it is mainly to check its left and right subtrees.
2.3.1 Preorder, inorder and postorder
Preorder: root, left subtree, right subtree, inorder: left subtree, root, right subtree, postorder: left subtree, right subtree, root
The root here means to access the data of the root node, while the left subtree and right subtree mean to access the nodes of the left and right subtrees through the structure.
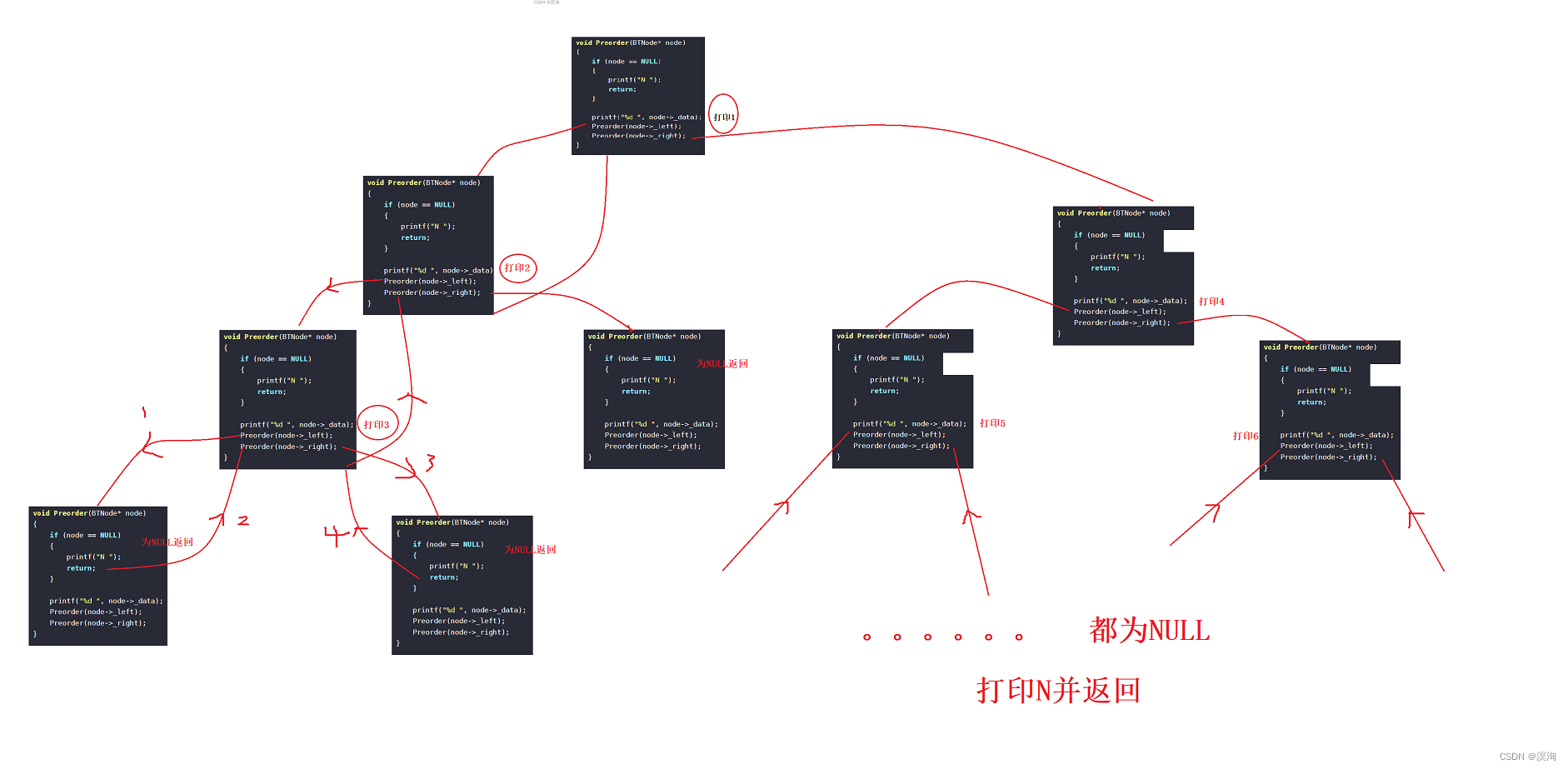
As shown in the figure above, when the left and right subtrees are NULL, it starts to return
The pre-middle and post-order are all carried out on the basis of recursion
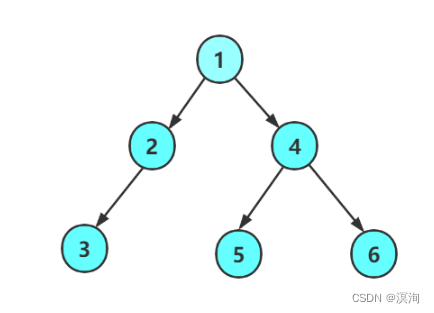
- The preorder traversal is: 1 2 3 NULL NULL NULL 4 5 NULL NULL 6 NN
- Analysis: The pre-order traversal is to print the data of the reached node first, then go to the left and right subtrees and return when encountering NULL
- The inorder traversal is: N 3 N 2 N 1 N 5 N 4 N 6 N
- Analysis: In-order traversal is to go to the left subtree and return when encountering NULL, then print the data of the node reached, and then go to the right subtree and return when encountering NULL
- The post-order traversal is: NN 3 N 2 NN 5 NN 6 4 1
- Analysis: post-order traversal is to go to the left subtree and return when encountering NULL, then go to the right subtree and return when encountering NULL, and then print the data of the node reached
Implemented with code:
#define _CRT_SECURE_NO_WARNINGS 1 #include<stdio.h> #include<stdlib.h> #include<assert.h> typedef int BTDataType; typedef struct BinaryTreeNode { BTDataType _data; struct BinaryTreeNode* _left; struct BinaryTreeNode* _right; }BTNode; BTNode* BuyNode(int x) { BTNode* t = (BTNode*)malloc(sizeof(BTNode)); if (t == NULL) { perror("malloc"); return NULL; } t->_data = x; t->_left = NULL; t->_right = NULL; return t; } void Preorder(BTNode* node) { if (node == NULL) { printf("N "); return; } printf("%d ", node->_data); Preorder(node->_left); Preorder(node->_right); } void Inorder(BTNode* node) { if (node == NULL) { printf("N "); return; } Inorder(node->_left); printf("%d ", node->_data); Inorder(node->_right); } void Postorder(BTNode* node) { if (node == NULL) { printf("N "); return; } Postorder(node->_left); Postorder(node->_right); printf("%d ", node->_data); } BTNode* CreatBinaryTree() { BTNode* node1 = BuyNode(1); BTNode* node2 = BuyNode(2); BTNode* node3 = BuyNode(3); BTNode* node4 = BuyNode(4); BTNode* node5 = BuyNode(5); BTNode* node6 = BuyNode(6); node1->_left = node2; node1->_right = node4; node2->_left = node3; node4->_left = node5; node4->_right = node6; return node1; } int main() { Preorder(CreatBinaryTree()); printf("\n"); Inorder(CreatBinaryTree()); printf("\n"); Postorder(CreatBinaryTree()); return 0; }Recursive expansion diagram (through this to understand its principle carefully):
prologue:
I will not draw the middle sequence and the post sequence. It is recommended that beginners must draw
2.3.1.1 When the preorder/postorder + inorder is given, the only binary tree can be determined (common test site for the exam)
And when the preorder + postorder is given, it is not necessarily possible to determine the unique binary tree
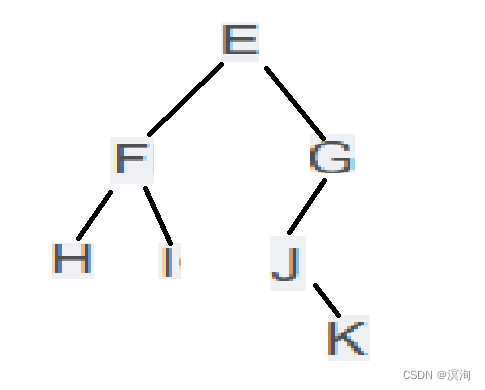
Example: preorder: EFHIGJK, inorder: HFIEJKG
Because the preorder is: root, left, right; the inorder is: left, root, right
- Then the preorder can judge the root first, and the inorder can judge the left and right subtrees
- At this time, the preorder is first E
- Then the left subtree of inorder E is HFI and the right subtree of E is JKG
- Then look at the root through the preorder: F is in the left subtree of the middle order E and the preorder is F first, so it is the root of the left subtree
- Then check the left and right subtrees of F through inorder: left: H; right: I (because there is only one node inside, there is no need to arrange it again, so it is completed)
- At this time, the left subtree of the tree has been completed, then exclude the left (EHFI) and continue to look at the right subtree (JKG)
- The same method: look at the root from front to back through the preorder, look at the left and right subtrees through the middle order, and then keep going down until there are no nodes
- Right subtree: At the beginning of the preorder, G intentionally G is the root node of the subtree, then look at the inorder only left node, then they are all on the left, then look at J as the beginning of the preorder, then take J as the root, and then look at the inorder K in On the right, then K is the right subtree
- Finally got:
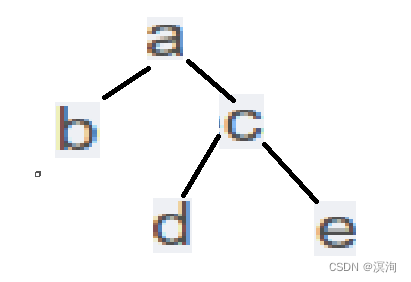
Example: posterior order: bdeca, middle order: badce
At this time, the post-sequence and the pre-sequence are slightly different, we need to look at it from the back to the front
Because postorder: left, right, root; inorder is: left, root, right
- The root of the tree from the back to the front in the postorder is a
- Then look at the inorder only b is in the left subtree, then there is only b in the left subtree, and then look at the right subtree (dce)
- After determining the nodes of the left and right subtrees, look at the second-to-last one in the sequence from the back to the front, then it means that c is the root of the right subtree (note here that it is different from the previous sequence, which requires looking at the right tree first. root is c)
- Looking at the inorder, you can see that d is the left node of the right subtree, and e is the right node
- Finally got:
2.3.2 Find the number of nodes in the binary tree:
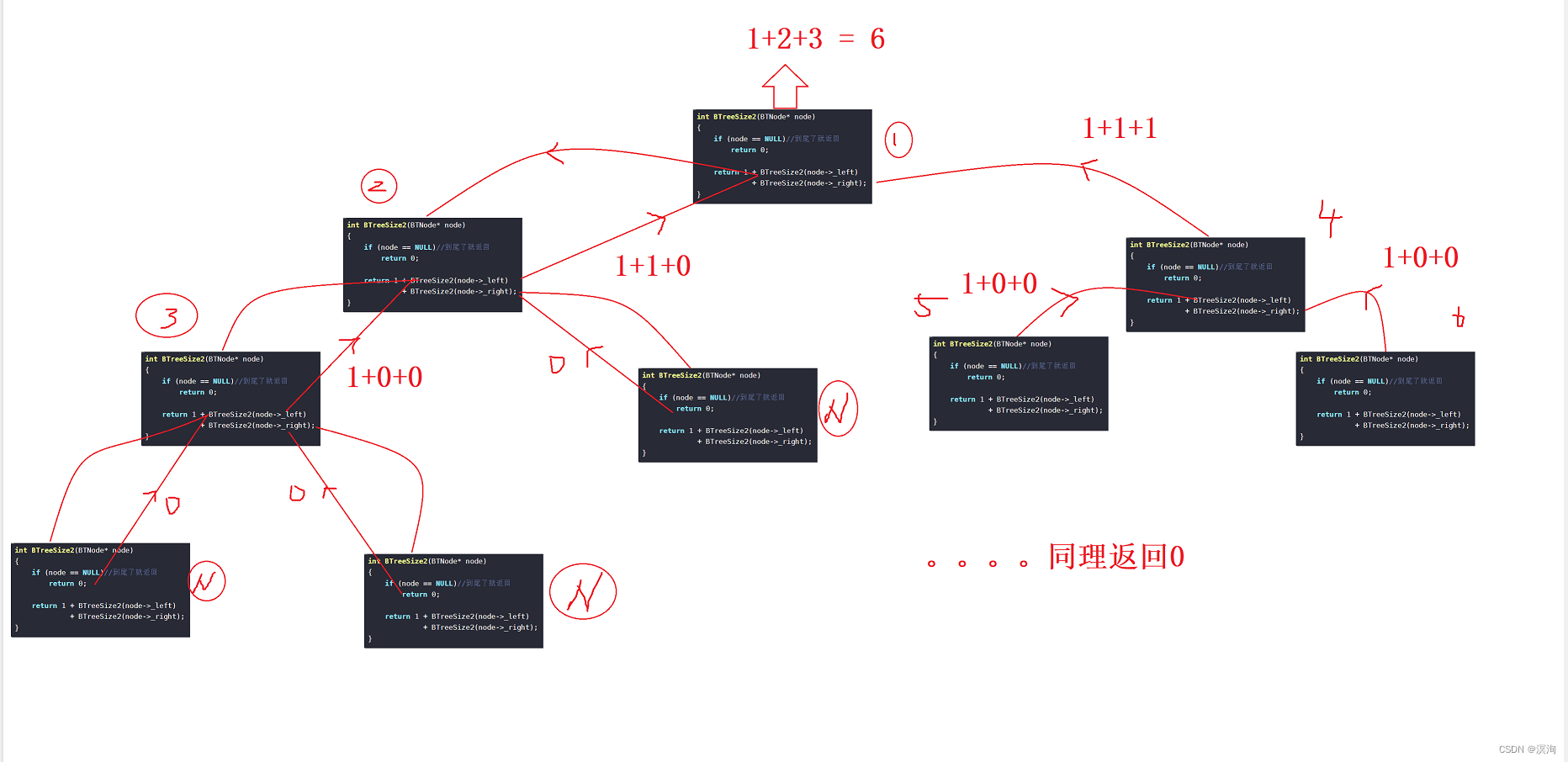
The principle of method 1 is the same as the front, middle and back sequence
int size = 0;//用全局变量来记录节点个数 void BTreeSize1(BTNode* node) { if (node == NULL)//当遇到NULL则返回且不记录 return; ++size; BTreeSize1(node->_left); BTreeSize1(node->_right); }Principle of method 2: return itself + all nodes of the left tree + all nodes of the right tree, so that the recursion continues and returns 0 when it reaches NULL
int BTreeSize2(BTNode* node) { if (node == NULL)//到尾了就返回 return 0; return 1 + BTreeSize2(node->_left) + BTreeSize2(node->_right); }
Beginners suggest that you must draw a recursive diagram so that you can understand it more clearly! I won’t draw below. If you don’t understand, you can draw a picture or ask a question in the comment area, and I will read it!
2.3.3 Find the height of the binary tree
Idea: Recursive idea, each node records the value returned by its left and right subtrees, judges that the value returned by the left and right children is larger, and finally returns the larger side.
accomplish:
int BTreeHight(BTNode* node) { if (node == NULL) return 0; //记录左右子树返回的值 int left = BTreeHight(node->_left); int right = BTreeHight(node->_right); //返回大的一边,+1是为了算自身 return left > right ? left + 1 : right + 1; }
2.3.4 Find the Kth layer node in the binary tree
Idea: Use a variable to record that if it reaches the Kth layer, it will return 1, otherwise it will return 0
accomplish:
int BTreeLevelKSize(BTNode* node,int k) { assert(k > 0);//防止K不符合实际 if (node == NULL) {//同样的当遇NULL就要返回 return 0; } //到达第K层时,k为1 if (k == 1) { return 1; } //左右子树都要加上 return BTreeLevelKSize(node->_left, k - 1) + BTreeLevelKSize(node->_right, k - 1); }
2.3.5 Finding Nodes in a Binary Tree
Idea: Similar to the height of the binary tree above, first recurse continuously and then judge whether the value of the node is equal to the one you want to find during the recursion process, and return the address of the node if it is equal, otherwise return NULL only when it is empty, and finally By recording the return status of the left and right subtrees, if it is NULL, it is not used; if it is not NULL, it means that a node pointer is returned
accomplish:
BTNode* BinaryTreeFind(BTNode* root, BTDataType x) { //查看节点是否为NULL若为则返回 if (root == NULL) { return NULL; } //判断节点数据是否等于要查找的数据 if (root->_data == x) { return root; } //记录左右子树的返回 BTNode* left = BinaryTreeFind(root->_left, x); BTNode* right = BinaryTreeFind(root->_right, x); //若不为NULL则表示找到了节点返回节点指针即可 if (left) return left; //用了三目、原理一样 return right != NULL ? right : NULL; }
Advanced Exercises:
Idea: analyze the topic, in order to prove the symmetry of the tree, you can find out: to judge whether the left node of the left subtree is equal to the right node of the right subtree, whether the right node of the left subtree is equal to the left node of the right subtree.
Then the first problem to be solved is to abandon the inherent thinking and only look at one node. At this time, you can write a function so that it can query whether they are equal from the left and right subtrees at the same time.
And you can have recursive ideas: return _isSymmetric(Leftroot->left, Rightroot->right) && _isSymmetric(Leftroot->right, Rightroot->left); left tree left child-right tree right child, left tree right child- - right tree left child
Then there is the idea of restricting recursion:
At the same time, when NULL is encountered, it means equality (the front is equal to the empty tree), then it means that it is equal, return true,
if only one side is NULL, it is not equal, so return false,
and then judge whether the values are equal
Final code:
//关键的如何可以同时在一棵树中往左右走 bool _isSymmetric(struct TreeNode* Leftroot ,struct TreeNode* Rightroot){ //两个都为NULL if(Leftroot == NULL && Rightroot == NULL){ return true; } //其中一个为NULL if(Leftroot == NULL || Rightroot == NULL){ return false; } if(Leftroot->val != Rightroot->val){ return false; } return _isSymmetric(Leftroot->left,Rightroot->right ) && _isSymmetric(Leftroot->right,Rightroot->left); } bool isSymmetric(struct TreeNode* root){ return _isSymmetric(root->left , root->right); }
2.3.6 Layer order traversal
The method of hierarchical traversal: store the nodes in the queue in the form of a queue , and bring in its own left and right nodes whenever a node leaves the queue, so that the hierarchical traversal of the binary tree can be realized.
Code:
void LevelOrder(BTNode* root) { Queue q; QueueInit(&q); //若为NULL就不进去了 if(root) QueuePush(&q, root); //判断条件队列不为NULL while (!QueueEmpty(&q)) { //记录在队列最前面的节点 BTNode* front = QueueFront(&q); //出队列 QueuePop(&q); //打印该节点的值 printf("%d ", front->_data); //front的左右节点不是NULL则将节点带入 if (front->_left) QueuePush(&q, front->_left); if(front->_right) QueuePush(&q, front->_right); } }
Exercise: Determine whether a binary tree is a complete binary tree
View the binary tree with the idea of sequence
For the characteristics of a complete binary tree: nodes are full except for the last layer and are continuous from left to right
It means that all nodes in the sequence queue are stored continuously and there will be no NULL insertion
bool BTreeCompare(BTNode* root)
{
Queue q;
QueueInit(&q);
if (root)
QueuePush(&q, root);
//把节点逐一放进队列中
while (!QueueEmpty(&q))
{
BTNode* front = QueueFront(&q);
QueuePop(&q);
//只要第一次NULL就退出
if (front == NULL)
break;
QueuePush(&q, front->_left);
QueuePush(&q, front->_right);
}
//查看队列后面是否全部为NULL若不是就表示不是完全二叉树
//因为完全二叉树的节点是连续的
while (!QueueEmpty(&q))
{
BTNode* front = QueueFront(&q);
QueuePop(&q);
if (front != NULL)
return false;
}
return true;
}If you have any questions, welcome to discuss!
If you think this article is helpful to you, please like it!
Continuously update a large amount of data structure and detailed content, early attention will not get lost.