Sensitive word detection
The detection of sensitive words is generally to establish a sensitive lexicon, and then judge whether there are certain words in the sensitive lexicon in the string, and then filter or replace them with other texts, which is extremely important for a harmonious network environment. Necessary, let's take a look at the implementation methods of sensitive word detection.
traditional way
For traditional sensitive word detection, it is generally to put all sensitive words in a set, and then loop through to detect sensitive words:
List<String> sensitiveList = Arrays.asList("阿巴阿巴", "花姑娘", "吊毛吃猪肉");
String text="花姑娘吃猪肉";
for (String s : sensitiveList) {
boolean hit = text.contains(s);
System.out.println(hit);
}
Obviously, although this implementation method is very simple, when the sensitive lexicon is too large, tens of thousands or even hundreds of thousands of loop judgments are required for one judgment, which is very time-consuming. Therefore, we introduce the second method of sensitive word detection.
Finite State Machine (DFA)
In DFA, given an input sequence, DFA determines the next state by looking up the rules in the state transition function according to the input and the current state, and finally judges whether to accept the input. How did you do it? To put it simply, the prefixes of all sensitive words are reused to construct a prefix tree, which records all possible states of all words in the sensitive lexicon.
prefix tree
For example, there are several sensitive words now: Diao Mao eats pork, Diao Mao is handsome, you are handsome, you are stupid, ctm... We can structure them in a tree structure like this:
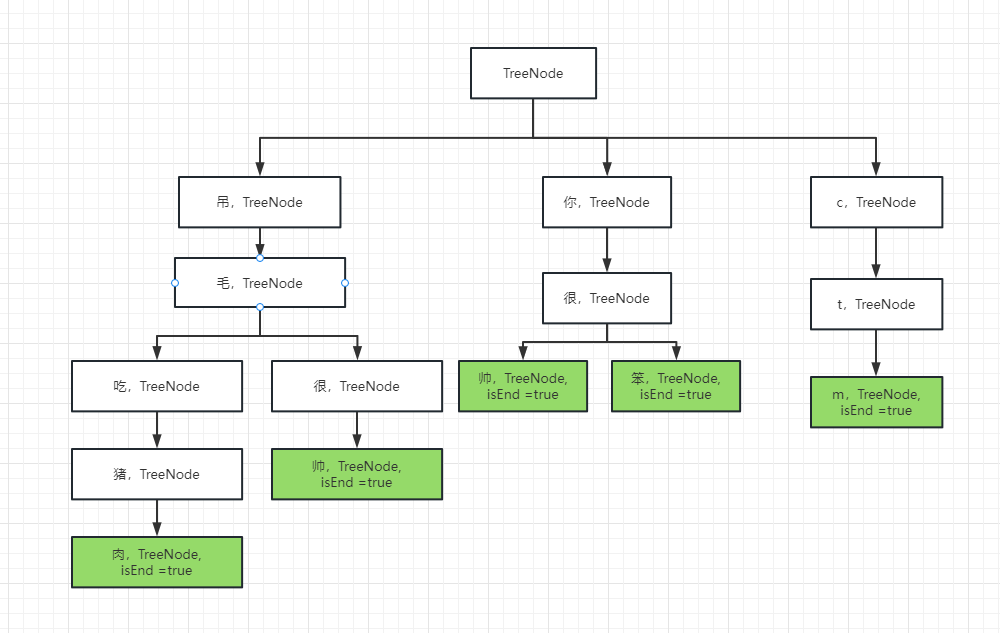
During the detection, the character string is cyclically detected. As long as there is an end mark (the green part in the figure), it indicates that there are sensitive words. In this way, not only can memory space be saved, but also the number of judgments can be reduced.
prefix tree structure
As a tree, its structure is also very simple:
/**
* 前缀树
*/
private static class TrieNode {
// 关键词结束标识
private boolean isKeywordEnd = false;
// 子节点(key是下级字符,value是下级节点)
private final Map<Character, TrieNode> subNodes = new HashMap<>();
}
Build a prefix tree
We only need to obtain all sensitive words, judge each character in turn, and complete the construction:
/**
* 将一个敏感词添加到前缀树中
*
* @param keyword 敏感词
*/
private void addKeyword(String keyword) {
TrieNode tempNode = ROOT_NODE;
for (int i = 0; i < keyword.length(); i++) {
char c = keyword.charAt(i);
TrieNode subNode = tempNode.getSubNode(c);
if (subNode == null) {
// 初始化子节点
subNode = new TrieNode();
tempNode.addSubNode(c, subNode);
}
// 指向子节点,进入下一轮循环
tempNode = subNode;
// 设置结束标识
if (i == keyword.length() - 1) {
tempNode.setKeywordEnd(true);
}
}
}
Sensitive word judgment
When we get the string to be detected, we need to traverse the string, and then start from the root node of the tree to continuously obtain child nodes. When the current node reaches a certain node and the end flag is true, it means that the current position is a String sensitive word, replace it with ***; then continue to start from the next character, point the node of the tree to the root node, and continue to detect until the string traversal is completed. The specific code is as follows:
/**
* 过滤敏感词
*
* @param text 待过滤的文本
* @return 过滤后的文本
*/
public static String filter(String text) {
if (StringUtils.isEmpty(text)) {
return null;
}
// 指针1
TrieNode tempNode = ROOT_NODE;
// 指针2
int begin = 0;
// 指针3
int position = 0;
// 结果
StringBuilder sb = new StringBuilder();
while (position < text.length()) {
char c = text.charAt(position);
// 跳过符号
if (isSymbol(c)) {
// 若指针1处于根节点,将此符号计入结果,让指针2向下走一步
if (tempNode == ROOT_NODE) {
sb.append(c);
begin++;
}
// 无论符号在开头或中间,指针3都向下走一步
position++;
continue;
}
// 检查下级节点
tempNode = tempNode.getSubNode(c);
if (tempNode == null) {
// 以begin开头的字符串不是敏感词
sb.append(text.charAt(begin));
// 进入下一个位置
position = ++begin;
// 重新指向根节点
tempNode = ROOT_NODE;
} else if (tempNode.isKeywordEnd()) {
// 发现敏感词,将begin~position字符串替换掉
sb.append(REPLACEMENT);
// 进入下一个位置
begin = ++position;
// 重新指向根节点
tempNode = ROOT_NODE;
} else {
// 检查下一个字符
position++;
}
}
// 将最后一批字符计入结果
sb.append(text.substring(begin));
return sb.toString();
}
/**
* 判断是否为符号
*
* @param c 字符
* @return 判断
*/
private static boolean isSymbol(Character c) {
// 0x2E80~0x9FFF 是东亚文字范围
return !isAsciiAlphanumeric(c) && (c < 0x2E80 || c > 0x9FFF);
}
public static boolean isAsciiAlpha(char ch) {
return isAsciiAlphaUpper(ch) || isAsciiAlphaLower(ch);
}
public static boolean isAsciiAlphaUpper(char ch) {
return ch >= 'A' && ch <= 'Z';
}
public static boolean isAsciiAlphaLower(char ch) {
return ch >= 'a' && ch <= 'z';
}
public static boolean isAsciiNumeric(char ch) {
return ch >= '0' && ch <= '9';
}
public static boolean isAsciiAlphanumeric(char ch) {
return isAsciiAlpha(ch) || isAsciiNumeric(ch);
}
epilogue
So far, we can conclude that using the construction of a prefix tree to complete sensitive word detection can save a little memory space and improve query efficiency compared with traditional traversal collection detection. But there are still some small problems, such as the inability to complete multi-pattern matching.
What is multimode matching?
For example sensitive words abc and bcd.
Matches the string abcde.
After single-mode matching: ***de
After multi-mode matching: ****e
If you are interested, you can continue to study it.