Table of contents
Feature selection filter corpus
1. Word frequency inverse document evaluation rate
Recently, I am doing the classification of CSDN library tags. The data of the library is shorter than the blog data, the features are scattered, and the time is tight and the task is heavy. It is definitely too late to go through the labeling process. As an algorithm engineer, after analyzing the data in detail, I can still find some solutions that can be tried, so I started to make adjustments.
Like blogs, library downloads have user-defined tags, but this tag is based on the user's subjective ideas. Due to the inconsistent cognition/knowledge level of the user, or for other purposes, the custom tag cannot be used directly. To use is a kind of weakly labeled data. The effect of directly throwing them into the classifier will not be guaranteed, and some processing is required to filter the weakly labeled data into strong labeled data.
Analyze existing data
The data in the data warehouse is counted, and the analysis finds that the data has the following characteristics:
1. The distribution of label data is uneven. Keyword searches based on user-defined tags and titles yield a general distribution of data.
2. The quality of user-defined labels varies.
3. Each piece of data has a title and a description field. Some of the description fields are real descriptions, and some are just copied titles. Not all data have effective classification features. The title and description of many software download resources are an English file name, for example: webcampic.zip.
4. The data span is large. Data from all walks of life are involved. If the classifier can cover all the data, the existing labels need to be expanded.

solution
1. For uneven data, according to the coverage of the data, select the labels with data, which can cover at least 60-70% of the data. This part of the label data builds a model prediction to solve the label problem, and the remaining 30- 40% are solved by configuring synonyms.
2. The quality of user tags is not high. You can use feature selection to select the characteristic words of each tag, and filter the corpus according to these characteristic words.
3. Try to extract the characteristic data fields to assist in classification, such as title/user tag/description/file name, etc. If the content of the file can be parsed, it is also a very useful feature.
4. For areas that are not covered by existing labels, the business operator needs to expand the existing label system. There is no way to do this, and it needs the assistance of other teams to complete it.
Initial Corpus Construction
For the tags predicted by the classifier, 1-2 synonyms are marked for each tag, and the user-defined tags and titles are searched for data containing tag synonyms in the database, and about 3000 entries are extracted for each tag.
Clean the content, remove line breaks, convert uppercase to lowercase, convert full-width to half-width, etc., and segment words. Before word segmentation, tag synonyms are added to the user-defined dictionary. Tag synonyms are feature words selected manually. Adding word segmentation dictionaries to avoid feature loss caused by incorrect word segmentation. The word segmentation uses the jieba Chinese word segmentation tool. There are a few points to note when using jieba word segmentation. If you use hanlp or other Chinese word segmentation tools, please ignore it.
1. Questions about English self-defined words. When there are English custom words, it will disassemble a complete English, for example: add vr to the custom dictionary, if the word segmentation later encounters words containing vr such as vrrp/vrilog, it will be split into vr and rp , vr and ilog. It is best not to add English to the word segmentation dictionary. If there are other solutions, please leave a message for discussion.
def _add_user_dict(self):
"""将tag加入自定义词典"""
for tag in self._tag_dict:
# 纯英文字符不加词典
if not tag.isalpha():
self.tag_classify_helper.add_word(tag)
for word in self._tag_similar_dict:
if not word.isalpha():
self.tag_classify_helper.add_word(word)2. If the customization contains special characters such as spaces, you need to add the following code after import.
# 解决自定义词中有空格或者特殊字符分不出来的问题
jieba.re_han_default = re.compile('([\u4E00-\u9FD5a-zA-Z0-9+#&\._% -]+)', re.U)3. You can use jieba's multi-process to speed up the word segmentation speed. The CPU utilization of word segmentation is still quite high. Here, you can fill in as many processes as there are cores in the computer.
jieba.enable_parallel(4) # 多进程Or use the process pool to implement a customized multi-process word segmentation method:
def _simple_cut(self, line):
id, tag, content = line[0], line[1], line[2]
seg_list = self.tag_classify_helper.word_cut(content)
seg_data = " ".join(seg_list)
new_line = str(id) + "\t" + str(tag) + "\t" + seg_data
return new_line
def _cut_data(self, processes=4):
"""对语料进行分词"""
new_data = []
pool = Pool(processes)
data_list = []
with open(self._download_data_selected_path) as file:
for line in file:
id, tagstr, content = line.strip().split("\t")
data_list.append((id, tagstr, content))
new_data = pool.map(self._simple_cut, data_list)
with open(self._download_data_seg_path, "w") as file:
file.writelines([line + "\n" for line in new_data])
return TrueThe cleaned data looks like this:

Feature selection filter corpus
In the past, when using machine learning methods for text classification, it was necessary to manually select and adjust features. Commonly used feature selection methods include term frequency inverse document frequency (TF-IDF), chi-square test (Chi-square), and information gain method (Information Gain). Gain)
1. Word frequency inverse document evaluation rate
How to measure the importance of a word for a document? The more times it appears in the current document (TF), but the less it appears in other documents (IDF), the more important the representative word is to the document.

Among them, for a certain label t , N represents the number of text data marked with the label t in the sample text data set, m represents the number of text data with the label t, and tf represents the frequency of the word t in the blog post under the label .
def stat_word_count(self, path, tags_words_dict, word_set):
with open(path) as file:
count = 0
for line in file:
count += 1
if count % 10000 == 0:
logger.info(count)
id, tags, context = line.strip().split("\t")
words = context.split(" ")
count_dict = dict()
for word in words:
word_set.add(word)
if word in count_dict:
count_dict[word] += 1
else:
count_dict[word] = 1
for word in count_dict:
for tag in tags.split(","):
if tag not in tags_words_dict:
tags_words_dict[tag] = dict()
if word not in tags_words_dict[tag]:
tags_words_dict[tag][word] = 1
else:
tags_words_dict[tag][word] += 1
def compute_tfidf(self, tags_words_dict, word_set):
tag_words_tfidf_dict = dict()
logger.info(f"tags_words_dict size:{len(tags_words_dict)}")
for word in word_set:
d = len(tags_words_dict)
count = 0
for tag in tags_words_dict:
if word in tags_words_dict[tag]:
count += 1
for tag in tags_words_dict:
if tag not in tag_words_tfidf_dict:
tag_words_tfidf_dict[tag] = dict()
if word not in tags_words_dict[tag]:
continue
tag_words_tfidf_dict[tag][word] = tags_words_dict[tag][word] * math.log(d/count)
return tag_words_tfidf_dictTFIDF is simple to calculate, and the calculation speed is faster on large-scale corpus, but it is not good enough for low-frequency words.
2. Information gain
Information gain measures the importance of features to the overall classification system, that is, the degree to which the appearance of features reduces the overall uncertainty.

Information gain is said to be the best, but the features selected are global features, not local features (each category has its own set of features), which does not fit our current scene.
3. Chi-square test
The idea of statistical hypothesis testing is to assume that words are not related to categories, and use the chi-square formula to calculate the CHI value. The larger the value, the less valid the hypothesis is, and the more relevant the word is to the category. First look at the confusion matrix:
| belongs to K | does not belong to K | total | |
| does not contain t | A | B | A+B |
| does not contain t | C | D | C+D |
| Total | A+C | B+D | N |
t represents a word, K represents a category, N represents the number of all documents in the training set;
A represents the number of documents that belong to K and contain t;
B represents the number of documents that do not belong to K and contain t;
C represents the number of documents that belong to K and do not contain t;
D Indicates the number of documents that do not belong to K and do not contain t.
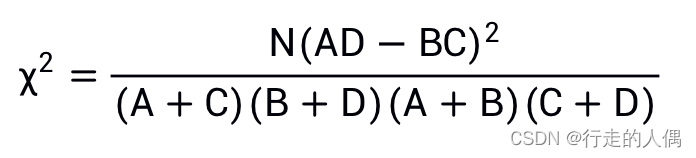
N, A+C, and B+D in the formula are the same for all words in the same category of documents. Most of the time we only do feature selection and don’t care about specific values, so the formula can be simplified:
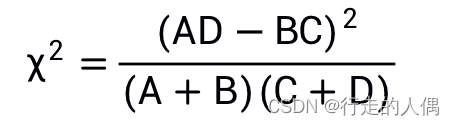
def _choice_feature_word(self, data, tags, min_count=5,topN=1000):
"""特征词挑选,这里采用卡方检验"""
feature_words_dict = dict()
# 先统计所有词
all_words_dict = set()
for seg_words in data:
for word in seg_words:
if word in all_words_dict:
all_words_dict[word] += 1
else:
all_words_dict[word] = 1
# 对每一个类别统计计算chi值
for tag in set(tags):
tag_words_map = dict()
chi_words = []
feature_words_dict[tag] = dict()
for word in all_words_dict:
# 指定最小频数
if all_words_dict[word] < min_count:
continue
chi_A = 0
chi_B = 0
chi_C = 0
chi_D = 0
for index, seg_words in enumerate(data):
category = tags[index]
if tag == category and word in seg_words:
chi_A += 1
elif tag == category and word not in seg_words:
chi_C += 1
elif tag != category and word in seg_words:
chi_B += 1
elif tag != category and word not in seg_words:
chi_D += 1
chi = math.pow(chi_A * chi_D - chi_B * chi_C, 2) / \
(chi_A + chi_B)*(chi_C + chi_D)
tag_words_map[word] = chi
for word, value in sorted(tag_words_map.items(), key=lambda item: item[1], reverse=True):
if len(feature_words_dict[tag]) < topN:
feature_words_dict[tag][word] = value
else:
break
return feature_words_dictAccording to the feature selection algorithm, the topn feature words of each category can be selected, and then according to the position and quantity of the feature words contained in the corpus, it can be judged whether the label of the corpus is correct, whether it can be corrected if it is incorrect, and so on. You can filter out random tags.
training model
The model still chooses the multi-label classifier used in the previous blog label classification , so I won’t explain it in detail here. There are detailed source codes in the blog. About 20 batches of training can converge. Conditions allow to save the results of each batch, and comprehensively evaluate the accuracy and recall on the test set to select the model.
Missing label data processing
For data that is not covered by the classifier, it will not be labeled. Here we use the method of configuring label synonyms and word2vec extended synonyms to extract labels from titles and user-defined labels. According to the number of words, positions, types (title, user Custom tags, abstracts, filenames) to give different weights.
Summarize
As a fast version, it already has certain effects in terms of coverage and accuracy, but if there are high requirements for recall and accuracy, continuous iterative optimization is required, preferably with manually labeled data.
From experience, there are a few things worth noting:
1. In the case of label polysemy, it is best to solve it through a classifier, such as the "container" category.
2. When adding classifier labels, it is best to cover all the data of a class. For example, if the keywords containing "novel" include "novel" and "novel reader", adding only one of them to the training corpus will cause the classifier to learn incorrectly. Inaccurate classification due to all features.
3. The choice of the classifier has a certain impact on the results, because feature engineering is involved. Choose a Chinese word segmenter that has been updated in recent years. Of course, it is best to write one yourself if you have the conditions. After all, there are many open source word segmenters.
4. It is very important to make a classifier corpus. If you have the conditions, you can dig more corpus.