
Article directory
foreword
As a programmer, it is very important to understand the composition of the computer and how the computer works, because only by understanding the computer can we better use the characteristics of the computer through code. Today I will share with you one of the core of the computer: the process.
what is a process
A process is an instance of a program that is running on a computer system. In an operating system, a process is an independent execution unit that has its own memory space, program code, and running state. A process can include one or more threads, each thread performs a different task, but they share the resources and context of the process.
When each application program runs on a modern operating system, the operating system provides an abstraction, as if only this program is running on the system, and all hardware resources are used by this program. This illusion is accomplished by abstracting the concept of a process, arguably one of the most important and successful concepts in computer science.
A process is an abstraction of a running program by the operating system. In other words, a process can be regarded as a running process of a program; at the same time, within the operating system, a process is the basic unit for resource allocation by the operating system.
how to describe the process
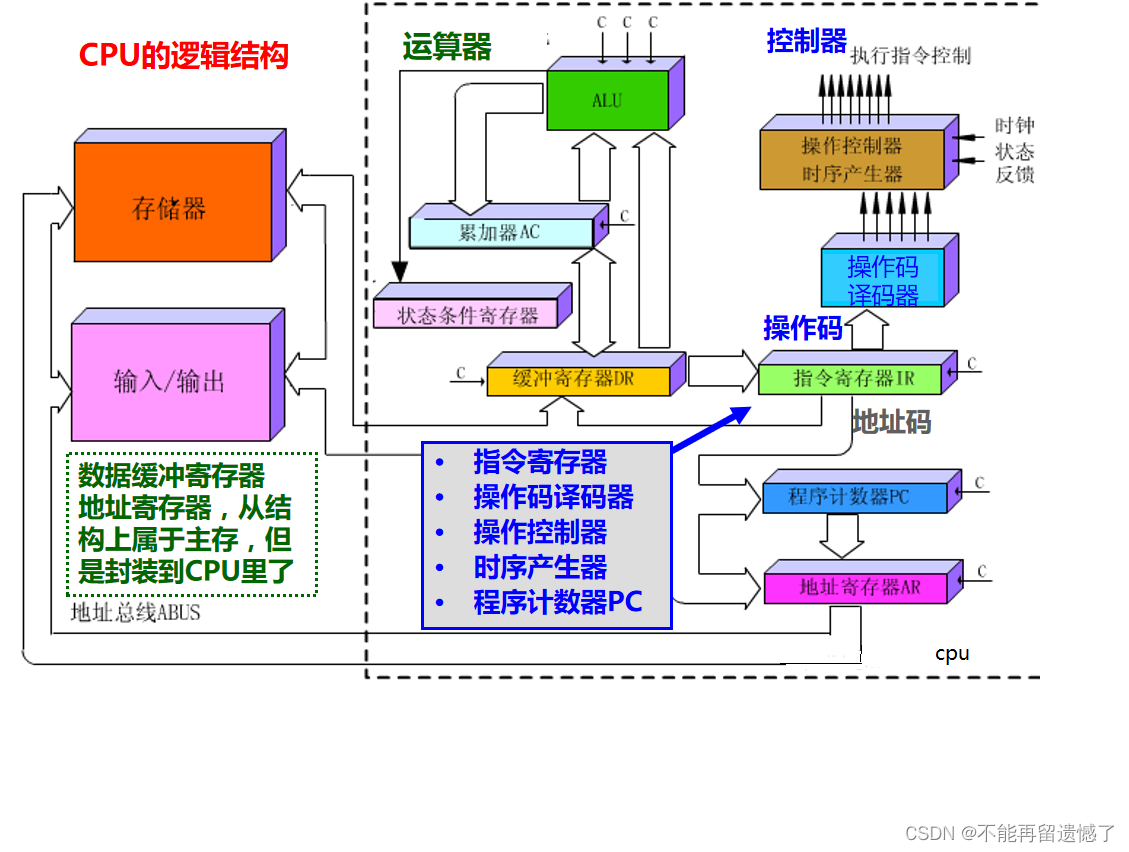
In the computer, a structure (structure in C language) is used to describe the properties of the process, and this structure is also called a process control block (PCB).
Process Control Block (PCB) is a data structure that contains the status information of a running process or task, as well as other information required by the process or task, such as process ID, program counter, registers, memory management information, etc. The PCB is usually maintained by the operating system kernel, which acts as an intermediary between the process and the operating system, helping the operating system manage the operation of the process and resource allocation, and ensuring concurrent execution and independent operation of multiple processes. Each process has its own independent PCB. When the kernel switches processes, it saves the PCB of the current process, then loads the PCB of the next process, and switches the control of the CPU to the next process.
In the underlying process, a node is a PCB linear table, search tree, etc. to organize.
properties of the process
1. Process identifier
A process identifier (Process Identifier, PID) is a digital identifier used to uniquely identify a running process in the operating system. Each process has a unique PID in the operating system.
PID is a non-negative integer, which is unique on most operating systems. When a process is created, the operating system assigns it a new PID. This PID remains constant throughout the lifetime of the process until the process terminates.
The function of the process identifier is to uniquely identify a process in the operating system, so that the operating system can manage and control the operation of the process.
2. Memory pointer

In the operating system, each process has its own independent virtual address space, and the memory pointer is a variable or data structure used to access and manage the memory of the process. A memory pointer stores a memory address that can be used to read or write data at that address.
The values of these memory pointers change continuously during the execution of the process, according to the control flow of the program and the operation of memory management. They allow processes to access various memory areas, such as code area, heap area, stack area, and data area, so as to realize program execution and data storage and access.
It should be noted that the memory pointer of a process can only be valid in its own virtual address space, and other processes cannot directly access or modify the memory pointers of other processes. The operating system provides memory isolation and protection functions between processes through address mapping and access control mechanisms, ensuring that the memory spaces of each process are independent and safe.
3. File descriptor table
A file descriptor table is a data structure used in the operating system to track and manage the files opened by a process. Each process has its own independent file descriptor table, which records information about files or other I/O resources opened by the current process.
A file descriptor is an integer used to represent an open file or other I/O resource. The operating system uses file descriptors to track the association between processes and open files for I/O operations, data transfer, and resource management.
The specific file descriptor table structure and implementation may vary by operating system, but generally, the operating system maintains a fixed-size array for each process to store file descriptors. The index of this array is the value of the file descriptor, and the corresponding open file can be accessed and operated through the index.
4. Status of the process
In an operating system, a process can be in different states, which describe the current situation or stage of operation of the process. Common process states include:
-
Created: When a process is just created, it is in the created state. In this phase, the operating system allocates the necessary resources for the process and sets the initial state of the process.
-
Ready: A process is in the ready state when it has acquired all the resources it needs to execute and is waiting for the operating system to allocate a CPU time slice. A process in the ready state waits for the scheduler to execute on one or more available CPUs.
-
Running: A process in the running state means that it is currently executing instructions. At a time, only one process can run on a CPU, which is scheduled as the currently running process. A process can spend some time in the running state, executing its instructions.
-
Blocking: When a process encounters certain events during execution, such as waiting for input/output, waiting for resource allocation, or waiting for a signal, it enters a blocked state. In the blocking state, the process suspends execution and waits for a certain condition to be met before re-entering the ready state.
-
Termination: A running process may terminate after execution completes or due to exceptional conditions such as errors, termination signals, etc. When a process is in the terminated state, all its resources are freed, including allocated memory and open files.
5. Priority
Process priority is a mechanism used by the operating system to determine the scheduling order of processes, which determines the priority and order in which processes are assigned when competing for limited resources (such as CPU time slices). Different processes can have different priorities, and high-priority processes get more CPU time for faster execution.
In most operating systems, a process is usually assigned a numerical priority, which can be an integer within a range, usually a larger value indicates a higher priority. For example, the priority range in Windows systems is 0-31, and the priority range in Linux systems is -20 to +19.
The level of process priority can affect the scheduling of the process. The scheduler will give preference to processes with higher priority and allocate more CPU time to them. This means that high-priority processes may be executed more frequently, while low-priority processes will be executed relatively rarely.
By adjusting the process priority, system resources can be allocated and scheduled in a more targeted manner to meet the needs of different processes. For example, for mission-critical or real-time applications, their priority can be set higher to ensure that they are allocated CPU resources in a timely manner.
It should be noted that the process priority is only a reference index for the scheduler, and the actual scheduling is also affected by other factors, such as the status of the process, the resources the process is waiting for, and so on. In addition, excessive reliance on process priority may cause other processes to get very little execution time, thus affecting the fairness and stability of the system. Therefore, careful consideration should be given when setting process priority.
To sum up, the priority of the process is the mechanism used by the operating system to determine the scheduling order of the process, and the high priority process will get more CPU time. By adjusting the process priority, more flexible allocation and scheduling of system resources can be realized.
6. Context
The context of a process refers to the state information related to the process that the operating system needs to save and restore when scheduling and executing the process. This state information includes the process's register contents, program counter, stack pointer, and other data related to the process's execution.
In an operating system, when a process is scheduled for execution, it restores the context from its previous execution state and continues execution. When the operating system decides to switch to another process, it saves the context of the current process, then loads and restores the context of another process to ensure that the next time the process is executed, it can continue to execute from where it left off last time.
The context of a process usually includes the following important parts:
-
Register content: including general-purpose registers, program counter (PC), stack pointer (SP), etc. These registers hold the execution state of the process before it was interrupted or switched so that execution can continue accurately when resumed.
-
Memory management information: including page tables, segment tables, or other data structures related to memory management. This information describes the memory layout and permissions of the process, as well as the mapping relationship between physical memory pages or virtual memory pages associated with the process.
-
File descriptor table: records information about the files opened by the process and I/O resources, including file descriptors, file status flags, open file lists, etc. Saving the file descriptor table ensures that the process can properly manage open files when it resumes.
-
Process state: Records the current state of the process, such as running, ready, blocked, etc. Saving process state can determine the priority and execution order of processes when scheduling.
Saving and restoring the context of a process is a key operation of the operating system for process switching and scheduling. When the operating system decides to switch to another process, it saves the context of the current process, transfers control to the other process, and restores its context. In this way, multiple tasks can be executed concurrently, so that multiple processes can share system resources and execute according to a certain scheduling strategy.
7. Billing information
In operating systems, process accounting information is used to record and track statistics about process execution and resource usage. This information can be used for performance analysis, resource management, and system monitoring purposes.
Accounting information for a process usually includes the following:
-
Process execution time: Record the execution time of the process on the CPU, including the total execution time, user mode execution time, and kernel mode execution time. These data can be used to calculate the CPU utilization of the process and evaluate the execution efficiency of the process.
-
Process waiting time: Record the time that the process waits for the CPU time slice in the ready state. This can be used to analyze the distribution of process wait times, discover possible resource bottlenecks and optimize scheduling algorithms.
-
Process scheduling times: record the number of times a process is scheduled to execute. This can be used to evaluate the execution priority of processes, the effectiveness of scheduling algorithms, and the responsiveness of processes.
-
System resources used by the process: record various system resources used by the process, such as memory usage, number of open files, number of network connections, etc. This can be used for resource management and throttling to prevent processes from overusing or abusing system resources.
-
Process Errors and Exceptions: Logs errors, exceptions, and interruptions encountered by a process. This can be used for troubleshooting and error handling to help analyze and resolve problems in process execution.
Among them, the status, priority, context, and accounting information of the process are related attributes of process scheduling, and are also core attributes of the process.
memory allocation
Process memory allocation refers to the process by which the operating system allocates memory space for the process so that the process can store and access the required data and code. Process memory allocation includes two aspects: the division of process address space and the management of virtual memory.
- Division of process address space
Process address space refers to the virtual memory space that a process can access, and is usually divided into the following parts:
- Code segment: store program code.
- Data segment: store initialized global variables and static variables.
- BSS segment: store uninitialized global variables and static variables.
- Heap area: stores dynamically allocated memory, such as memory allocated by functions such as malloc.
- Stack area: store information such as temporary variables and return addresses when the function is called.
- Virtual memory management
Virtual memory refers to an abstract memory provided by the operating system to the process through address translation technology, so that the memory space seen by the process does not necessarily correspond to the actual physical memory. The management of virtual memory mainly involves the following aspects:
- Page replacement: When the physical memory is insufficient, the operating system needs to swap out part of the process data from the physical memory to the hard disk to free up the physical memory space for other processes to use. This process is called page replacement.
- Paging: Paging refers to the process by which the system manages the virtual pages that are requested to be accessed. When a process accesses a virtual page, if the page is not already in physical memory, it needs to get the page from the hard disk and load it into physical memory. This process is called paging.
- Page size: The page size is the series of equal-sized blocks into which a process's virtual memory space is divided. Common page sizes include 4KB, 8KB, etc.
- Page table: A page table is a data structure that records the correspondence between virtual addresses and physical addresses. When a process accesses a virtual address, it needs to translate the virtual address into a physical address through the page table.
The memory address obtained in the program is not a real physical memory address, but a virtual address after a layer of abstraction.
The speed of accessing data at any address on the memory is extremely fast, and the time is almost the same. It is precisely because of this characteristic of memory that subscript access to arrays appears. If there is a bug in the code of the current process, it will cause the accessed memory to go out of bounds, which may affect other processes
"Isolating" the memory space used by a process introduces a virtual address space. The code no longer directly uses real physical addresses, but uses virtual addresses, and the operating system and specialized hardware devices (MMU) are responsible for converting virtual addresses to physical addresses.
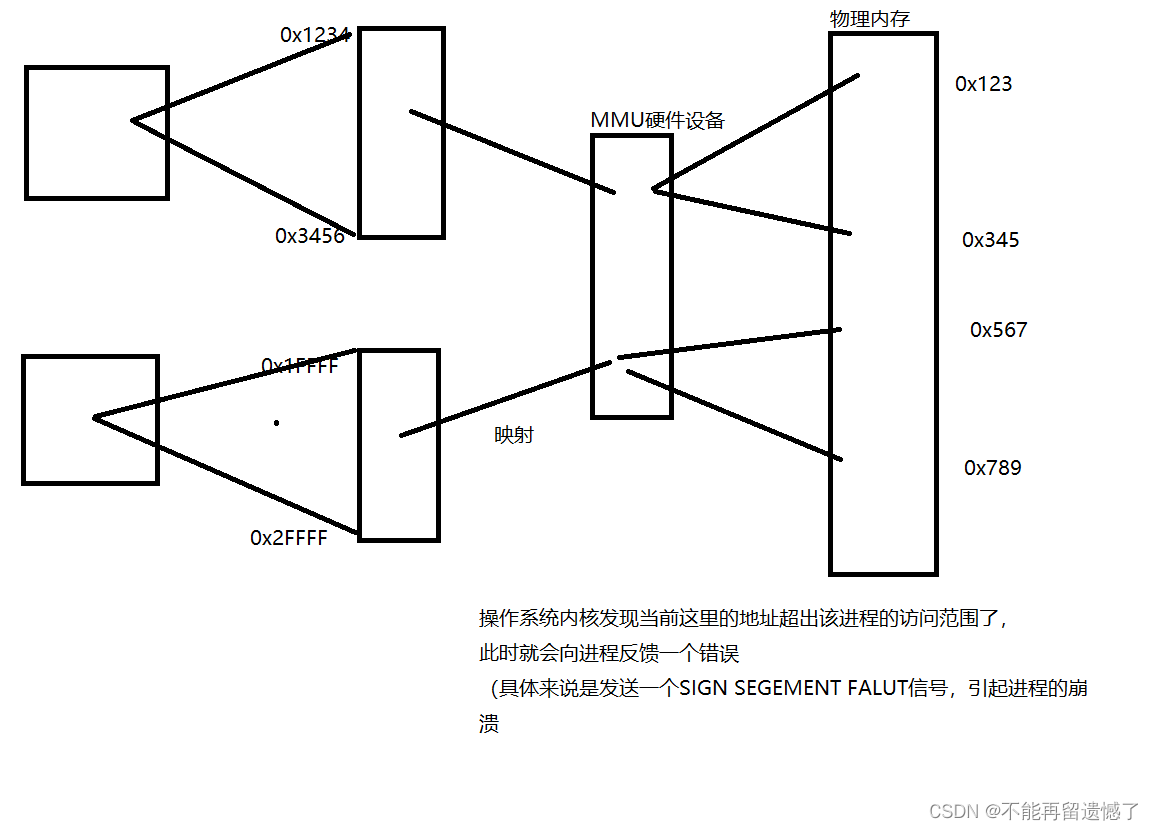
Which process has a bug, which process will crash, without affecting other processes.
parallelism and concurrency
what is parallelism
Parallelism refers to the ability to perform multiple tasks or operations simultaneously. In the field of computers, especially in multi-core CPUs or distributed systems, parallelism can be used to speed up the execution speed of tasks and improve the computing power of the system. At the same moment in parallel microcosm, the processes on the two cores are executed at the same time
In parallel processing, multiple tasks or operations are assigned to different processing units or computing resources to execute simultaneously. These processing units may be independent CPU cores, different cores in a multi-core CPU, different computer nodes or servers, and the like. Each processing unit performs tasks independently, and calculations and data operations can be performed in parallel between them.
Parallel processing is often used to solve tasks that require high performance and computing power, such as scientific computing, large-scale data processing, image and video processing, etc. By breaking the problem into smaller sub-problems and assigning each sub-problem to a different processing unit for parallel processing, the execution time of the task can be significantly reduced.
what is concurrency
Concurrency refers to the execution of multiple independent tasks or operations by a system or program within the same time period. In the computer field, concurrency is a mechanism for processing multiple tasks at the same time, and the alternate execution of tasks is realized through task switching and scheduling.
The main goal of concurrency is to improve the efficiency and resource utilization of the system. By processing multiple tasks simultaneously, the system can more fully utilize CPU, memory, and other resources in order to better respond to user needs and increase overall throughput.
Concurrency can be implemented on a single processing unit, such as a single-core CPU or a single thread, or between multiple processing units, such as a multi-core CPU, multi-threaded or distributed system. The specific way to achieve concurrency includes time slice round-robin scheduling, thread switching, process switching, etc.
The difference between parallelism and concurrency
Concurrency is simultaneous at the macro level, and serial at the micro level
Parallel is simultaneous at the macro level, but simultaneously on different cores at the micro level
- meaning:
- Parallel (Parallel): Refers to the simultaneous execution of multiple tasks, each task is performed simultaneously on multiple processing units, and each processing unit can be an independent CPU core or a core in a multi-core CPU.
- Concurrency: refers to processing multiple tasks at the same time, executing multiple tasks alternately, and switching between multiple tasks through time slicing or task scheduling.
- Implementation modalities:
- Parallelism: Multiple tasks are executed at the same time, and each task is performed in parallel on an independent processing unit.
- Concurrency: Multiple tasks are executed alternately, and each task is executed in turn on the same processing unit. Time slices or task switching are used to implement concurrent execution of tasks.
- Purpose:
- Parallelism: By executing multiple tasks at the same time, the overall computing power and execution speed are improved, and the completion of tasks is accelerated.
- Concurrency: Through the alternate execution and scheduling of tasks, the fair sharing of resources between multiple tasks is realized, and the efficiency and throughput of the system are improved.
- Method to realize:
- Parallelism: through multi-core CPU, multi-CPU or distributed computing, different tasks are assigned to different processing units and processed at the same time.
- Concurrency: Alternate execution between tasks is achieved through task scheduling, thread or process switching.
- context switch:
- Parallelism: Since each task is executed on an independent processing unit, there is no context switching overhead.
- Concurrency: Due to the need to switch execution between tasks, there is the overhead of context switching, including saving and restoring the execution context information of tasks.