The whole point of traditional multimodal learning.
downstream task
Before talking about the model, let's talk about traditional multimodal tasks as downstream tasks.
Image Text Retrieval
It contains image-to-text retrieval and text-to-image retrieval. Given a database, search for image-text pairs with ground truth. Because it is a retrieval, the metric is the recall rate (recall).
Visual Question Answering (VQA)
Given a question, given a picture, see if you can answer the question based on the picture.
Closed set VQA: Classification problem, fixed answer set from which to choose the answer. multi answer classification.
Open Set VQA: Text Generation Task
Visual Reasoning
Predict whether a text can simultaneously describe a pair of images. Two classification problems.
Visual Entailment
Given a hypothesis, see if the premise can be inferred. If it can be deduced, it means that it contains the relationship of entailment, and the contradictory cannot be deduced, and the neutral cannot be judged. So it can be said to be a three-category problem.
Multimodal FAQs and Directions
1) The problem to be solved in feature extraction is how to quantify text and images separately, and then send them to the model for learning?
Feature extraction:
Text: tend to large models such as bert
Image: Neural Networks, VIT, etc.
2) The problem to be solved in feature fusion is how to make the representations of text and images interact?
The simplest: addition/splicing, but more ingenious structures can also be designed
3) The pre-training task is how to design some pre-training tasks (PreTask) to assist the model in learning the alignment information of images and texts?
Cross-modal feature fusion, etc.
Mainstream methods of pre-training
feature extraction
The standard representation on the text side is Bert’s tokenizer, and LSTM may have been used earlier; for images, some traditional and classic convolutional networks are used, and there are three main forms of extraction: Rol, Pixel, and Patch.
feature fusion
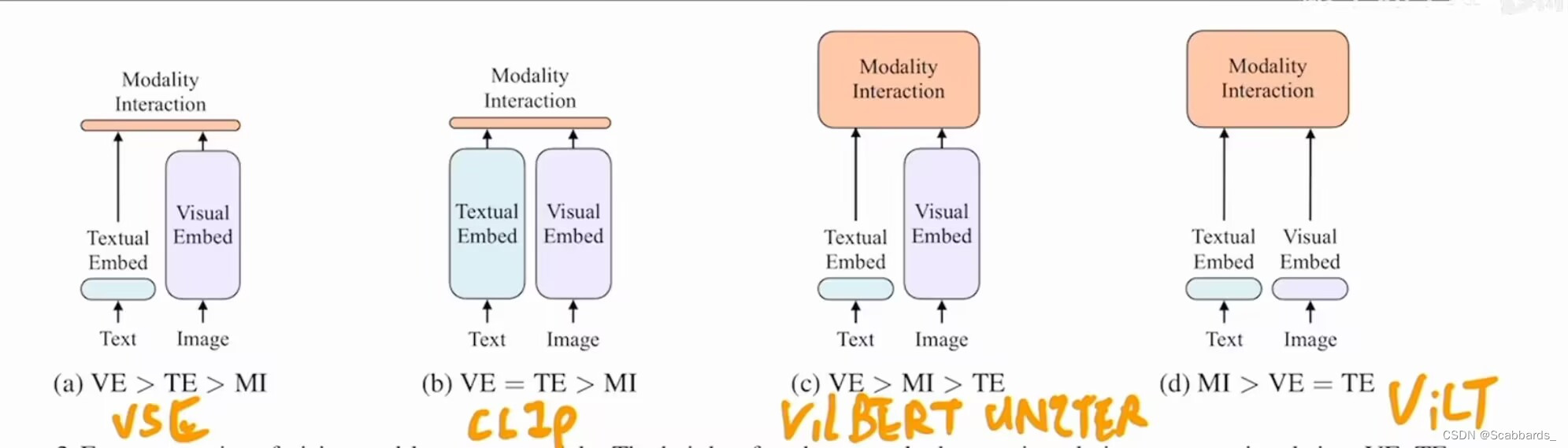
The current mainstream approach is nothing more than two kinds, namely, two-stream or single-stream; the former is basically a two-tower network, and then some layers are designed for interaction at the end of the model, so the time when the interaction of the two-stream structure occurs later. The latter is a network such as a transformer, which enters a network for interaction from the very beginning, so the interaction time of the single-stream structure occurs earlier and throughout the process, which is more flexible.
Pre-training PreTask
This is the most interesting place, and it is also the embodiment of the idea of most multimodal papers. Here is a summary of some common standard configuration tasks:
Masked Language Modeling ( MLM )
Masked Region Modeling(MRM)
Image Text Maching (ITM)
I will talk about it later
We can divide the traditional multimodal model into two categories, one is only using the transformer encoder, and the other is using both the transformer encoder and the transformer decoder
Model using only Transformer Encoder (Twin Towers model)
Want
 model structure
model structure
Feature extraction:
Align also has two models, one for text and one for vision, both are transformers, and the image uses patch
*image encoder can be resnet and vit
Pre-training tasks:
ImageText Matching + Masked Language Modeling
main contribution
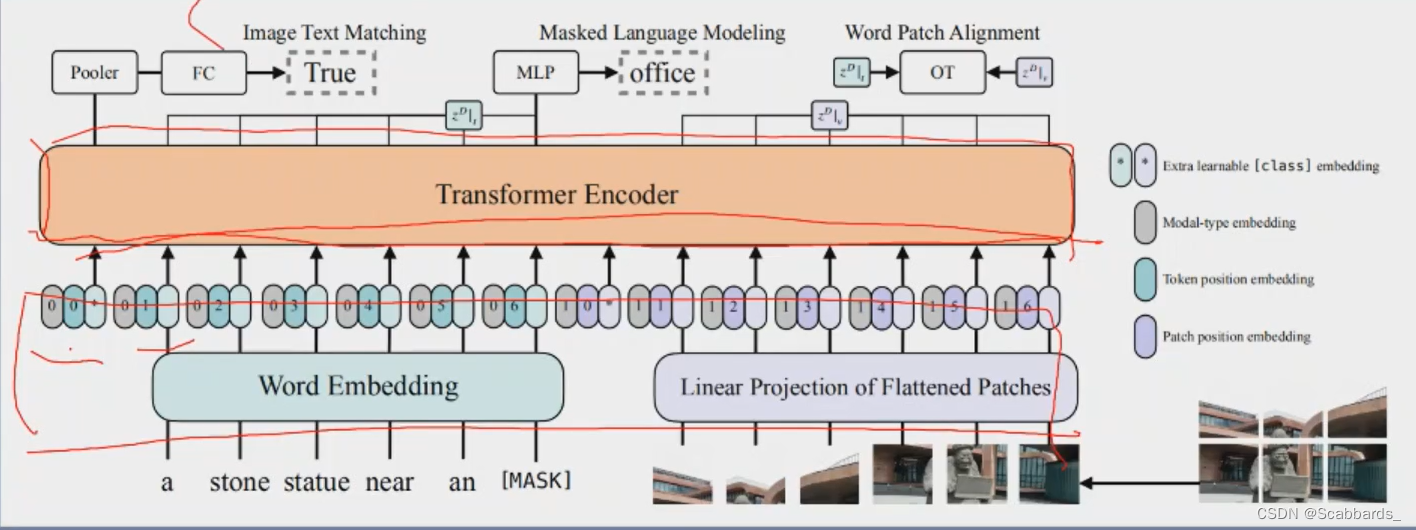
Remove the pre-trained target detector and replace it with a learnable Patch Embedding Layer
The patch-based visual features of vit are not much different from the previous bounding box-based visual features, so that the super-large pre-trained target detector can be replaced with patch embedding
shortcoming
1. The performance is not high enough. In short, the visual model must be larger than the text model to have a good effect
2. Fast inference time, very slow training time
Therefore, the visual model should be larger than the text model, and the fusion model between modalities should be as large as possible. Good objective functions include ITC, ITM and MLM
Clip
model structure
Feature extraction:
Clip is a typical twin-tower model. There are two models, one for text and one for vision, both of which are transformers. The image uses patch
*image encoder can be resnet and vit
Pre-training tasks:
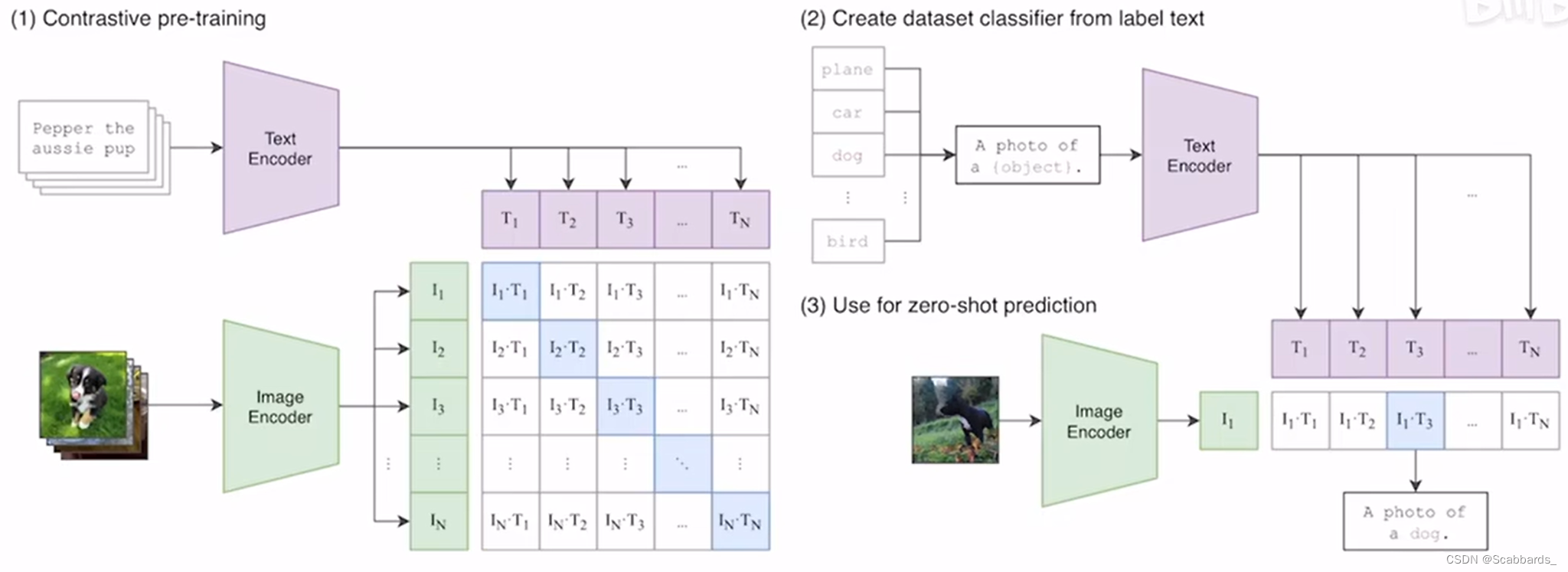
The clip pre-training uses contrastive learning because it can have a smaller amount of calculation. Among them, the positive samples are on the diagonal, and the features of the image and the text are used for cosin similarity, and the sentences corresponding to the text features most similar to the image are selected to complete the classification task. It works quite well for image-text matching and image-text retrieval. But for VQA, VR, and VE, the effect is not good.
*Similarity calculation is vector inner product
main contribution
1) Cross-modal representation learning
The CLIP model encodes images and text into a shared feature space by using the encoder part of the Transformer. This enables the CLIP model to learn the semantic alignment between images and text, and to understand their relationship even in different modalities. Such cross-modal representation learning provides a strong foundation for mutual understanding of images and texts.
2)zeroshot
One of the highlights of clip is zeroshot, and few shot can be used in certain areas of expertise
-
Zero-shot learning: In zero-shot learning, a model can make inferences and predictions without being explicitly trained for a specific task. It uses previously learned knowledge and general background information to solve new tasks. This means that the model can reason and predict by understanding the semantics or structure of the problem. Typically, a model needs to understand a new task by reading instructions or examples, and use its prior knowledge to make predictions. Zero-shot learning is a technique for transfer learning in new domains.
-
Few-shot (few-shot) learning: In few-shot learning, the model needs to use a small number of training samples to learn new tasks. This number can range from a few samples to dozens of samples, and is usually far less than the large number of training samples required in traditional machine learning. In few-shot learning, models need to be able to reason and generalize from limited samples in order to achieve good performance on new tasks. To improve generalization, few-shot learning usually uses techniques such as meta-learning, model parameter sharing, and data augmentation.
q: Are the prefixes of all sentences converted by prompt* template the same?
a: - yes
clip advantage:
1. Get rid of the limitation of categorical label
2. Support a very wide range of domains
A "domain" usually refers to a specific domain or context of a dataset or problem. A domain can consist of data samples that share common characteristics, data distributions, or task definitions.
Deep learning models usually need to be trained and applied in specific fields, because data in different fields have different characteristics and distributions. The performance of a model in one domain may degrade due to domain changes, which is known as the "domain transfer" problem between domains. Therefore, knowing and understanding domain-specific features is very important for developing effective deep learning models.
In domain adaptation and transfer learning, "domain" is used to describe the relationship between different datasets or tasks. By training on one domain and transferring the model to another related domain, efficient predictions on data in the new domain can be achieved.
self-monitoring
Self-supervised learning (Self-Supervised Learning) is a training method that does not require manual labeling, in which the model uses the automatically generated targets of the data itself to learn. It provides an efficient approach for unsupervised learning with unlabeled data and shows potential in improving model performance and generalization.
In traditional supervised learning, we need to provide data with artificial labels as targets, such as classifying images into different categories or assigning labels to text. But in self-supervised learning, the data itself is used as the generative target without human labels.
The core idea of self-supervised learning is to design automatically generated tasks by exploiting the inherent structure or pattern in the data. For example, in the field of images, the original image can be used as input by random occlusion, rotation, color transformation and other operations on the image, and the model is required to reconstruct or predict the modified image part. The model is trained with self-generated objectives during the learning process by attempting to reconstruct or predict the modified parts.
The advantage of self-supervised learning is that it does not require human labels, so it can be trained on large-scale unlabeled data. This is very valuable for many domains, where labeling large amounts of data is often expensive. With self-supervised learning, a model can be trained on unlabeled data and then transferred to a dataset with limited labels to improve model performance.
One of the most important concepts in self-training is the pseudo-label↓
Pseudo-label
In the pseudo-labeled approach, the model is initially trained with a small amount of labeled data. Then, use this initially trained model to make predictions on the unlabeled data, and use these predictions as pseudo-labels (or pseudo-objects). The unlabeled data together with its pseudo-labels are used as an extended training set to train the model again to further improve the performance of the model.
The idea of pseudo-labeling is based on an assumption: given unlabeled data, the prediction result of the model may be correct. By using these pseudo-labels for training, the model can be adapted to the distribution and characteristics of unlabeled data as much as possible, thereby improving the generalization ability of the model.
The advantages of pseudo-labeling include:
-
Utilize unlabeled data: Pseudo-labeling allows the utilization of a large amount of unlabeled data, which helps to increase the training sample size of the model to better capture the distribution and characteristics of the data.
-
Self-generated targets: Pseudo-labels use the model's own predictions as training targets, avoiding the cost and subjectivity of manually annotated data.
-
Improve model performance: By iteratively training with pseudo-labels, the model can gradually improve and achieve better performance on unlabeled data.
However, pseudo-labeling also has some limitations and risks:
-
Error Propagation: Since pseudo-labels are generated by the model's predictions, if the model's predictions are wrong, these errors may be propagated to subsequent training, resulting in a decline in model performance.
-
Label noise: Pseudo-labels of unlabeled data are not necessarily accurate, and there may be a certain degree of label noise. This may have a certain negative impact on the learning of the model.
As mentioned before, clip is a comparison task, so what are comparison tasks and prediction tasks?
Comparison and Prediction Tasks
A "contrastive task" is a form of task for learning representations or features. Its goal is to separate dissimilar samples from each other by bringing similar samples close to each other in order to construct a meaningful representation space during learning.
Contrast tasks typically involve two critical steps:
-
Positive sample contrast: Select a pair of similar samples (positive samples) and encourage the model to place them close to each other in the representation space. This means that the model should be able to capture common features and similarities between these samples.
-
Negative Contrast: Choose a pair of dissimilar samples (negative samples) and encourage the model to separate them from each other in the representation space. This means that the model should be able to distinguish samples of different classes or different characteristics.
Through the training of positive sample comparison and negative sample comparison, the model can learn more discriminative feature representation. These feature representations can be used in many machine learning tasks such as similarity search, clustering, classification, etc.
Among them, the loss of comparative learning in clip is called ITC loss (Image Text Contrastive Loss)
Image Text Contrastive Loss is a loss function for learning the similarity relationship between images and text. It is widely used in multimodal retrieval, alignment and association tasks between images and texts.
The goal of this loss function is to drive the learning of correspondences between images and text by maximizing the similarity of pairs of positive samples while minimizing the similarity of pairs of negative samples. During training, each positive pair consists of an image and an associated text, while each negative pair consists of an image and an unrelated text.
Specifically, for positive sample pairs, the goal is to make the feature representations between image and text closer in the embedding space. Whereas for negative pairs, the goal is to make the feature representations between image and text farther apart in the embedding space.
Usually, the feature representation of images and texts is extracted by deep learning models such as convolutional neural network (CNN) and recurrent neural network (RNN). Then, use measures such as Euclidean distance or cosine similarity to measure the similarity between image and text features.
In the paper, the clip model uses mixed precision training to reduce the amount of calculation
Mixed precision training
Mixed precision training (Mixed Precision Training) is a technique for deep learning model training by using both low precision (such as half precision) and high precision (such as single precision) data types.
In mixed-precision training, model parameters and gradients are usually stored as low-precision data types, such as half-precision floating-point numbers (FP16), while input data and intermediate activation values use high-precision data types, such as single-precision floating-point numbers. Points (FP32). This can reduce the memory space occupied by the parameters in the model, and at the same time speed up the calculation speed of the model.
The advantages of mixed precision training include:
-
Save memory: Using low-precision parameters can greatly reduce the memory space occupied by the model, which is especially important for large models and large-scale data sets. This makes it possible to train with larger batch sizes, thus speeding up the training process.
-
Improve computational efficiency: Calculations with low precision can be performed faster on hardware accelerators such as GPUs. Since low-precision operations require less computation, more computation can be performed in the same amount of time, speeding up model training.
-
Accelerated model deployment: Using mixed-precision training can reduce the size of the model, so that the memory usage and computing time of the model in the inference stage are significantly reduced. This is very beneficial for deploying deep learning models on embedded or edge devices.
It should be noted that mixed precision training also introduces a certain loss of numerical precision. Since parameters and gradients are stored with low precision, some uncertainty and error accumulation in numerical calculations may result. Therefore, careful handling of numerical instabilities with appropriate numerical adjustments and gradient scaling is required when applying mixed-precision training.
Multi-GPU operation can refer to ↓
How to Train Really Large Models on Many GPUs? | Lil'Log
Align

model structure
Feature extraction:
Align also has two models, one for text and one for vision, both are transformers, and the image uses patch
*image encoder can be resnet and vit
Pre-training tasks:
Contrastive learning is also employed,
Differences from clip:
1.8 billion pictures and texts were used
Flip

model structure
Two models, one for text and one for vision, both are transformers
Similarity:
Contrastive learning also uses cosine similarity
main contribution
It is considered that the global similarity of the previous models (Clip, Align) lacks fine-grained comparison, so a novel fine-grained comparative learning monthly standard is introduced, plus a cross-modal post-interaction mechanism, which can take image patches and text tokens into account fine-grained interaction between
ALBEF
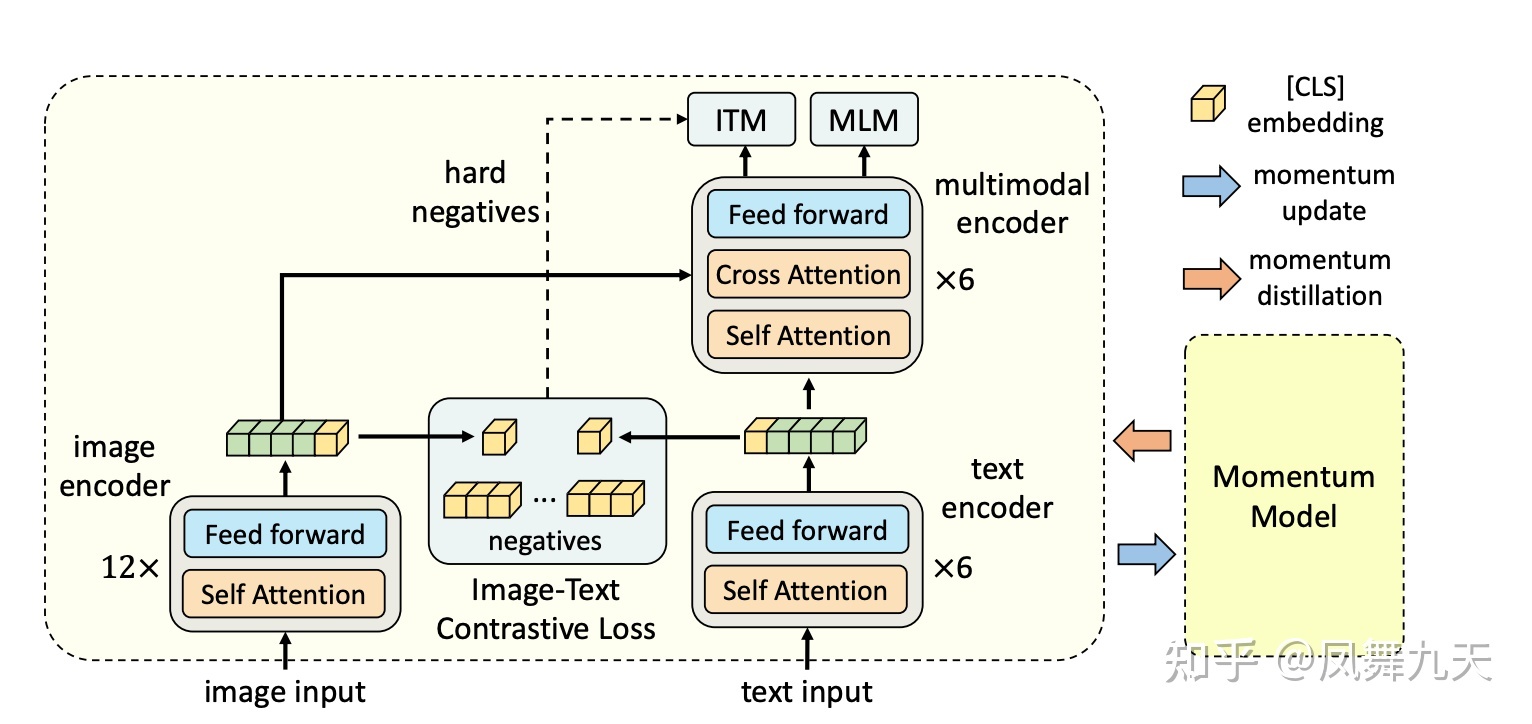
model structure
Composed of an image encoder, a text encoder and a multimodal encoder, an image-text contrastive loss is proposed to model the unified representation of image-text before image-text fusion
Image: 12-layer Transformer base Model (n)
Initialize it with weights pretrained on ImageNet-1k. An input image I is encoded into a sequence of feature tokens, aligned using the embeddings of the [CLS] tokens.
Text: The 12-layer bert model is split into two parts, the first six layers are used as a text encoder (l), and the last six layers are used as a multimodal fusion encoder (nl)
The text encoder converts the input text T into text embedding tokens, which are fed into the multimodal encoder. Fusing image features with text features via cross-attention at each layer of the multimodal encoder
Momentum Model: It is also a combination of vit + bert, but the parameters are obtained through the main model moving average, which occupies relatively less memory than the gradient
Loss:
2*ITC(Image Text Contrastive): Comparison tasks, comparing (cosine) similarity between samples
Input: (Image, Text)
ITM (Image Text Maching): Two classification tasks, judging whether the samples match. Because it is easy to converge, the negative sample with the highest cosine similarity (the negative sample closest to the positive sample) will be obtained through ITC except the positive sample.
Input: (Image, Text)
2*MLM (Mask Language Modeling): The cloze used in BERT to fill in the blanks. But in this model, the masked model will be restored through the image
Input: (Image, Masked Text)
*ITC and MLM are not only in the basic model, but also in the momentum model. ITC itself is based on ground truth, so there is no momentum model
main contribution
1) A contrastive loss ITC is introduced to guide visual and language representation learning by adapting image and text representations by fusion before cross-modal attention (ALBEF)
Propose loss (actually ITC), align before fusing: before Mutli-Model Encoder, the features of the input image and text will be aligned
2)momentum distillation
 Because most of the collected image-text pairs are very noisy, the one-hot ground truth is not necessarily the optimal solution. In order to effectively learn text image features from noisy data, learning in a self-training manner also uses pseudo labels. Use momentum model (momentum model) to generate pseudo target, so as to achieve self-training. As shown in the figure, sometimes the pseudo target generated on the momentum model can describe the picture more accurately than the ground truth. The exponential moving average EMA is used on the existing model, so that it is not only close to the one hot label of the ground truth, but also matches the pseudo target as much as possible.
Because most of the collected image-text pairs are very noisy, the one-hot ground truth is not necessarily the optimal solution. In order to effectively learn text image features from noisy data, learning in a self-training manner also uses pseudo labels. Use momentum model (momentum model) to generate pseudo target, so as to achieve self-training. As shown in the figure, sometimes the pseudo target generated on the momentum model can describe the picture more accurately than the ground truth. The exponential moving average EMA is used on the existing model, so that it is not only close to the one hot label of the ground truth, but also matches the pseudo target as much as possible.
Function: Generate different perspectives for the same image-text pair, and do data argumentation in disguise, so that the trained model has the function of Semantic Preserving
Achievement: The image-text retrieval effect is outstanding, and the training is close to the people
shortcoming
The effect of VQA is very poor, because there is no good interaction between multi-modal information, and it is only suitable for single-modal tasks such as retrieval.
VLMo
In the model mentioned above, the two-tower model such as clip will be fast and good for matching with cosine similarity, but it will perform poorly in other tasks; while using transformer will be very slow in matching tasks. VLMo improves the model for this problem, which is Mixture of Modality Expert. Generally speaking, it is a work of Uni Modality to help Multi Modality.
model structure

objective function
ITC(Image Text Contrastive) ,ITM(Image Text Maching),MLM(Mask Language Modeling)
main contribution
1) Model structure improvement: Mixture of Modality Expert. All modes of self-attention are shared, but in the Feed Forward FC layer, each mode will correspond to its own expert. During training, the expert of which modality is trained when the modal data comes, and the model to be used is determined according to the input data during inference.
2) Staged model pre-training: solves the problems of hard to find data sets and high production costs.
First train the vision expert on the vision data set
Then freeze the vision ffn and self attention, and then train in the language expert in the language data set (text-only data). At this time, the model parameters have been initialized very well.
Finally, do pretraining on the multimodal data set.
future work
1. Make the model larger (scale): Beit v3
2. Do more downstream vision language tasks: VL-BeiT, BeiT v3
3. Multi Modality help Uni Modality: BeiT v3
4. More modes and application scenarios: speech: WAVLM; Structure Knowledge: LayoutLM v1v2v3; general purpose: MetaLM
Transformer Encoder and Decoder together model
Also called single tower model
BLIP
model structure

It can be said to be a combination of ALBEF and VLmo models
*The same color in this picture is a shared parameter
Image (layer n): a standard vit model
Text: Depending on the input modality and objective function, select different parts of the large model to make the model forward
Model 1 Text Encoder (n layer): Do understanding classification according to the input content. After getting the text features, do ITCloss with the visual features. Token:CLS
Model 2 Image-grounded Text encoder: Use image information to complete multimodal tasks. Token: Encode
If you don’t look at Model 3, it’s ALBEF! However, it borrows from the self attention in VLMO that can share parameters.
Model 3 Image-grounded Text decoder: used to generate text. Its first layer uses causal self-attention, causal attention Token: Decoder
Objective function LM: The objective function of the GPT series, given some words, predict some words
main contribution
1)Cap filter Model / Caption filtering
First train a model Cap with noisy data, then use this model to train a cleaner model on a cleaner data set, and then see if you can train a better model with cleaner data

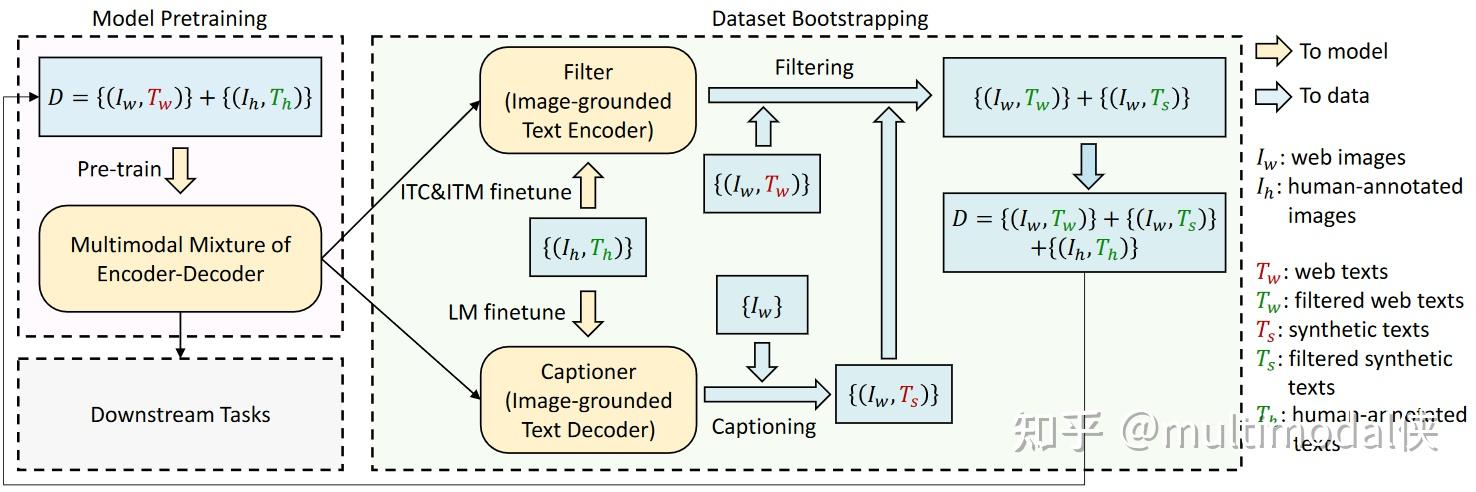
step1:
First train a model Cap with noisy data
step2:
Use this model to train a filter on a cleaner data set (Coco), and then use this filter to process the original data to obtain cleaner data. At the same time, the text generated by the Captioner:blip model may match the original ground truth better, so the new text is used as the data set.
step3:
Use the newly generated data set of step2 to train the blip model.
These three steps can be trained separately.
2)Unified
Modifications on the model to enable it to be generated.
CoCa
Follow-up work on SimVLM and ALBEF
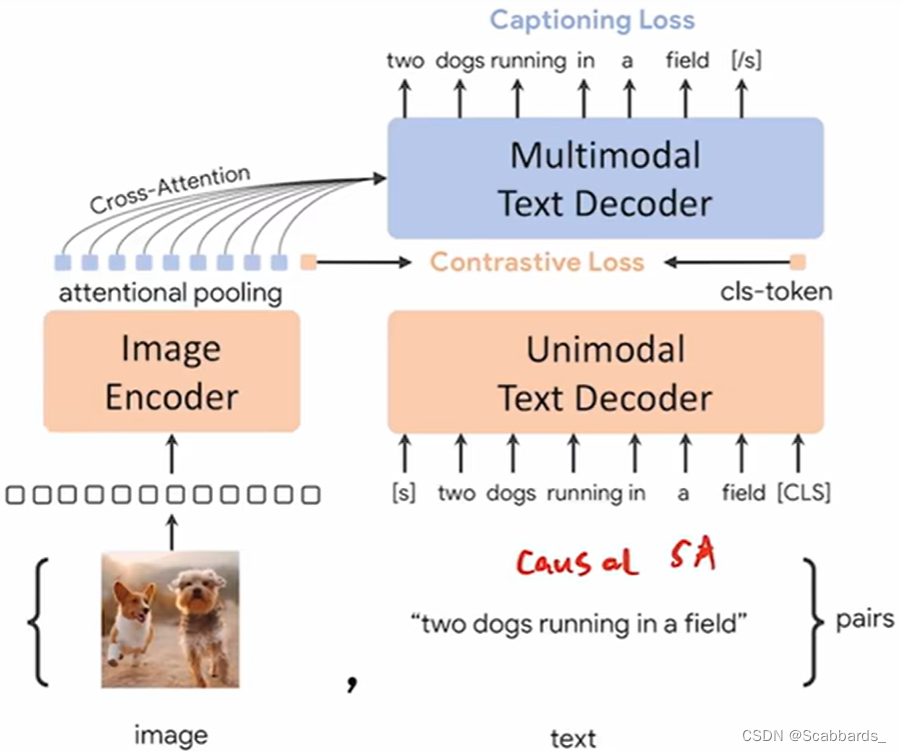
model structure
The basic structure is not much different from ALBEF
Fusion of visual and textual features with cross attention
Loss function:
captioning loss: Language modeling loss
contrastive loss: ITC
Differences from ALBEF:
1) The attentional pooling in the upper left corner can be learned
2) All text terminals use decoders
main contribution
1) In order to speed up the training, the captioning loss and contrastive loss are calculated at the same time, so the text input is causal from the beginning.
2) Training on larger and larger datasets has achieved excellent results
BEIT v3
model structure
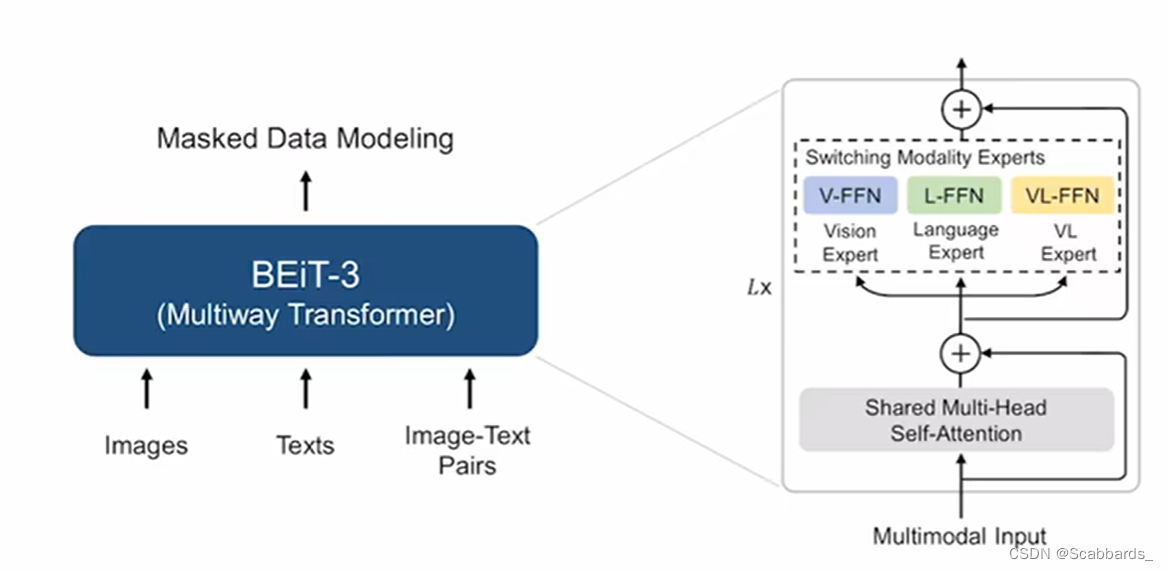
The MOME in VLMO is applied, but it is called Multiway Transformers in this article
Objective function: mask modeling

As shown in the figure, different tasks take different structures, which is very flexible
main contribution
1) Treat the visual image as a language (Imglish), and the image-text pair is called parallel sentence. At this time, both images and text can be done with mask modeling loss, so there is no need for ITC, ITM and other losses.
Reference video:
Multimodal Dissertation Lecture Part 1 [Paper Intensive Reading·46]_哔哩哔哩_bilibili
Multimodal Dissertation Lectures Part II [Paper Intensive Reading·49]_哔哩哔哩_bilibili