After labeling the semantically segmented data set, it is as follows:
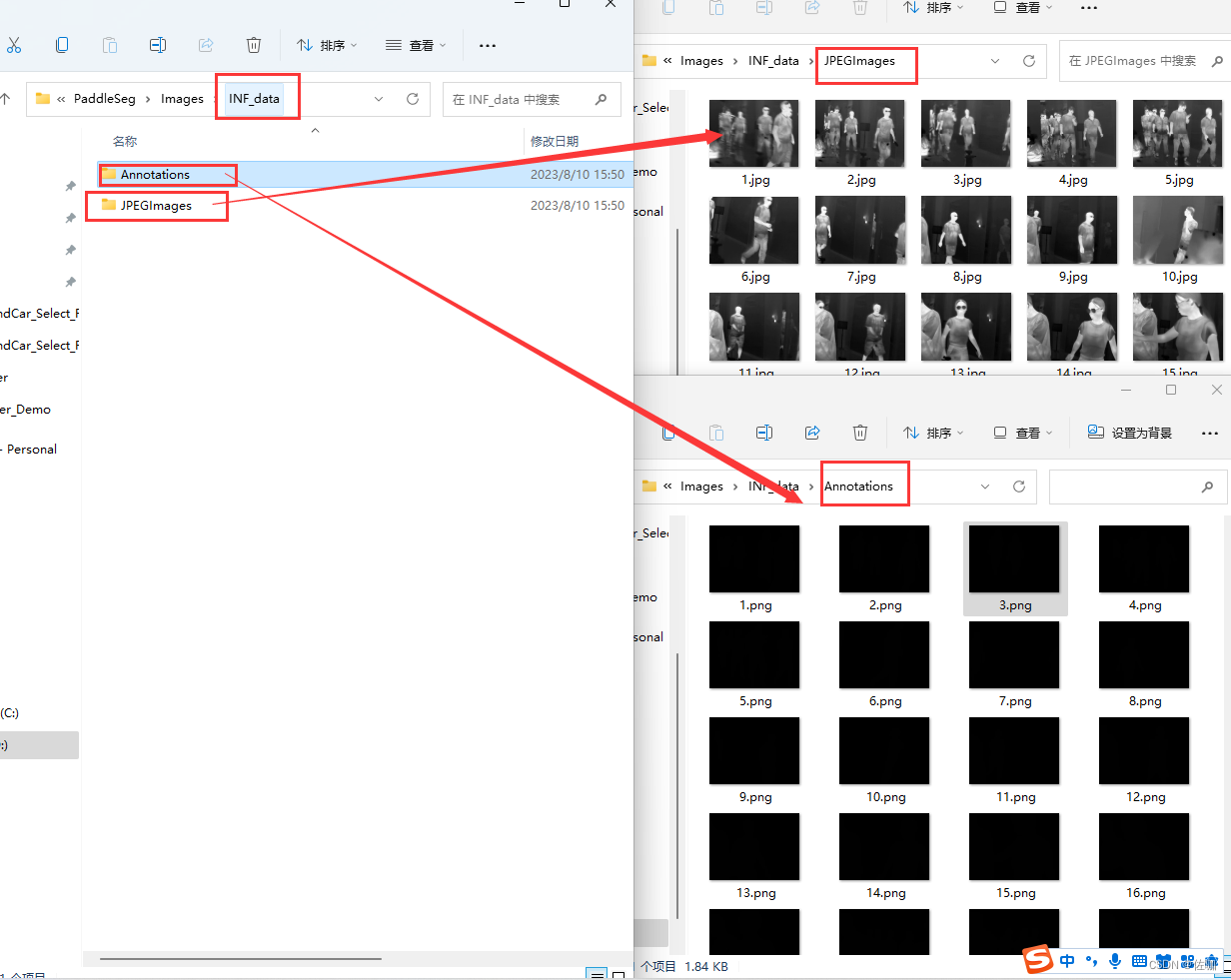
After sorting out the pictures and tagged text, it needs to be divided into training set, verification set, and test set according to the proportion.
The specific division code is as follows:
import glob
import os.path
import argparse
import warnings
import numpy as np
def parse_args():
parser = argparse.ArgumentParser(
description='A tool for proportionally randomizing dataset to produce file lists.'
)
parser.add_argument('dataset_root', help='the dataset root path', type=str) # 数据集根目录路径
parser.add_argument('images_dir_name', help='the directory name of images', type=str) # 图片所在的文件路径
parser.add_argument('labels_dir_name', help='the directory name of labels', type=str) # 标签所在的文件路径
parser.add_argument(
'--split', help='', nargs=3, type=float, default=[0.7, 0.3, 0]) # 此代码为默认比例7 :3 :1 可以自定义修改比例
parser.add_argument(
'--separator',
dest='separator',
help='file list separator',
default=" ",
type=str)
parser.add_argument(
'--format',
help='data format of images and labels, e.g. jpg, tif or png.',
type=str,
nargs=2,
default=['jpg', 'png'])
parser.add_argument(
'--postfix',
help='postfix of images or labels',
type=str,
nargs=2,
default=['', ''])
return parser.parse_args()
def get_files(path, format, postfix):
pattern = '*%s.%s' % (postfix, format)
search_files = os.path.join(path, pattern)
search_files2 = os.path.join(path, "*", pattern) # 包含子目录
search_files3 = os.path.join(path, "*", "*", pattern) # 包含三级目录
filenames = glob.glob(search_files)
filenames2 = glob.glob(search_files2)
filenames3 = glob.glob(search_files3)
filenames = filenames + filenames2 + filenames3
return sorted(filenames)
def generate_list(args):
separator = args.separator
dataset_root = args.dataset_root
if abs(sum(args.split) - 1.0) > 1e-8:
raise ValueError("The sum of input params `--split` should be 1")
image_dir = os.path.join(dataset_root, args.images_dir_name)
label_dir = os.path.join(dataset_root, args.labels_dir_name)
image_files = get_files(image_dir, args.format[0], args.postfix[0])
label_files = get_files(label_dir, args.format[1], args.postfix[1])
if not image_files:
warnings.warn("No files in {}".format(image_dir))
if not label_files:
warnings.warn("No files in {}".format(label_dir))
num_images = len(image_files)
num_label = len(label_files)
if num_images != num_label:
raise Exception(
"Number of images = {}, number of labels = {}."
"The number of images is not equal to number of labels, "
"Please check your dataset!".format(num_images, num_label))
image_files = np.array(image_files)
label_files = np.array(label_files)
state = np.random.get_state()
np.random.shuffle(image_files)
np.random.set_state(state)
np.random.shuffle(label_files)
start = 0
num_split = len(args.split)
dataset_name = ['train', 'val', 'test']
for i in range(num_split):
dataset_split = dataset_name[i]
print("Creating {}.txt...".format(dataset_split))
if args.split[i] > 1.0 or args.split[i] < 0:
raise ValueError("{} dataset percentage should be 0~1.".format(
dataset_split))
file_list = os.path.join(dataset_root, dataset_split + '.txt')
with open(file_list, "w") as f:
num = round(args.split[i] * num_images)
end = start + num
if i == num_split - 1:
end = num_images
for item in range(start, end):
left = image_files[item].replace(dataset_root, '')
if left[0] == os.path.sep:
left = left.lstrip(os.path.sep)
try:
right = label_files[item].replace(dataset_root, '')
if right[0] == os.path.sep:
right = right.lstrip(os.path.sep)
line = left + separator + right + '\n'
except:
line = left + '\n'
f.write(line)
print(line)
start = end
if __name__ == '__main__':
args = parse_args()
generate_list(args)
Save the above code to an English path, and name it: split_dataset_list.py, enter the terminal interface where the .py file is saved through cmd, and run the following command:
python split_dataset_list.py <dataset_root> <images_dir_name> <labels_dir_name> ${
FLAGS}
Explanation of the parameters of the above command:
dataset_root: 数据集根目录
images_dir_name: 原始图像目录名
labels_dir_name: 标注图像目录名
This code is the default ratio of 7:3:1, you can customize the modified ratio
! ! ! ! ! Note: You must use an absolute path when importing the path! ! ! ! !
The specific samples are as follows:

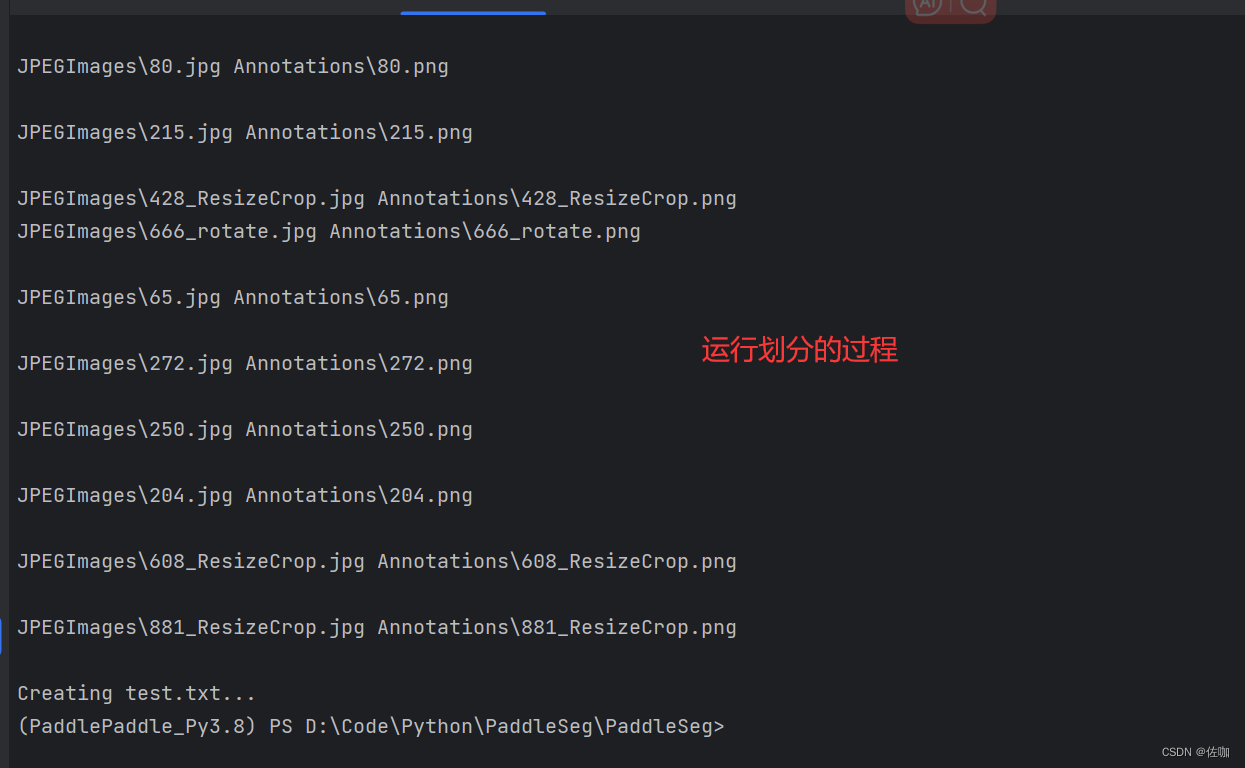
Go to the root directory of the dataset to view the divided results, as follows:
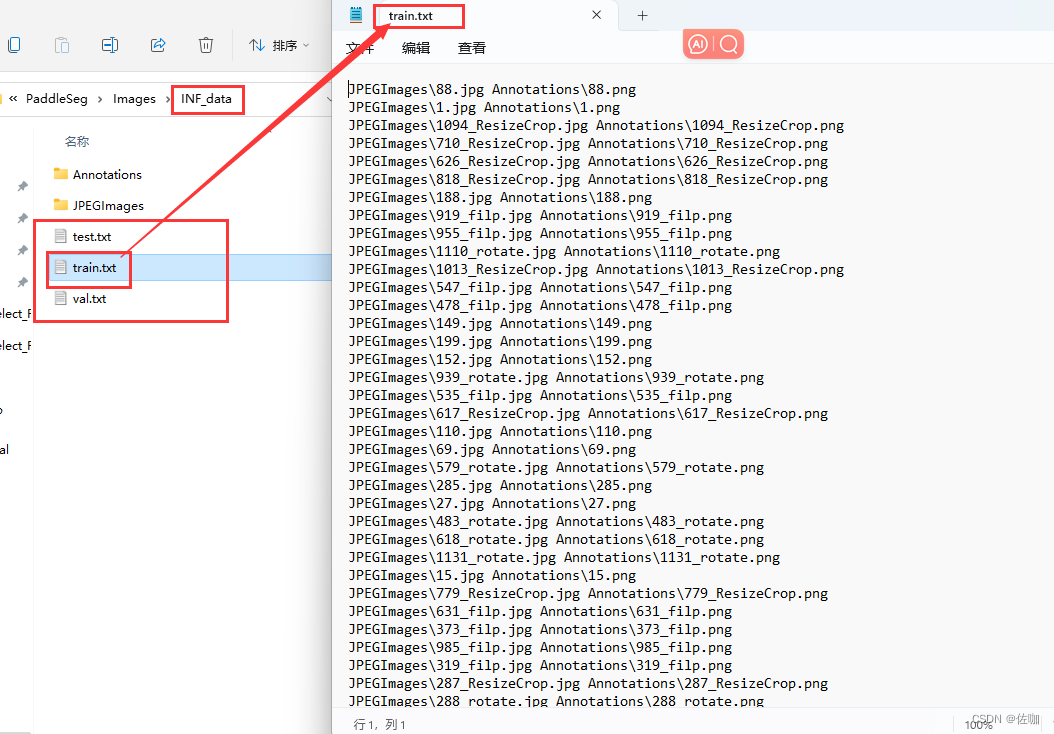
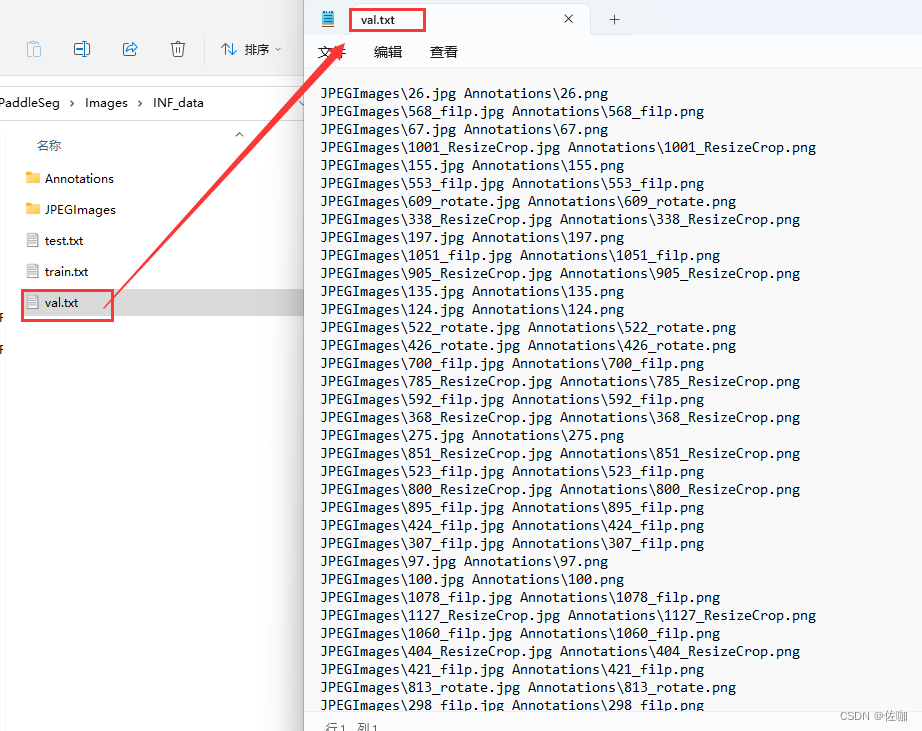
The above is the detailed division process of paddleseg data set custom ratio divided into test set test.txt, training set train.txt, and verification set val.txt, thank you!