Introduction
AbstractRoutingDataSourceIt is an abstract class in the Spring framework, which can realize dynamic switching and routing of multiple data sources to meet complex business requirements and improve system performance, scalability, and flexibility.
Application Scenario
- Multi-tenant support: For multi-tenant applications, select the corresponding data source according to the current tenant to achieve tenant-level isolation and data storage.
- Sub-database and sub-table: In order to improve performance and scalability, the data is dispersed into multiple databases or tables, and the correct data source is selected according to the sharding rules to realize sub-database and sub-table.
- Read-write separation: In order to improve the read-write performance of the database, read-write separation may be adopted, and an appropriate data source is selected according to the type of read-write operation to achieve read-write separation.
- Data source load balancing: Select the appropriate data source according to the load balancing strategy, evenly distribute requests to different data sources, and improve the overall performance and scalability of the system.
- Multi-database support: In some scenarios, it may be necessary to connect to multiple different types of databases at the same time, such as relational databases, NoSQL databases, etc. Select different types of data sources according to business needs to support multiple databases.
Realization principle
1.AbstractRoutingDataSourceImplemented DataSourcethe interface, as a data source encapsulation class, responsible for routing database requests to different target data sources
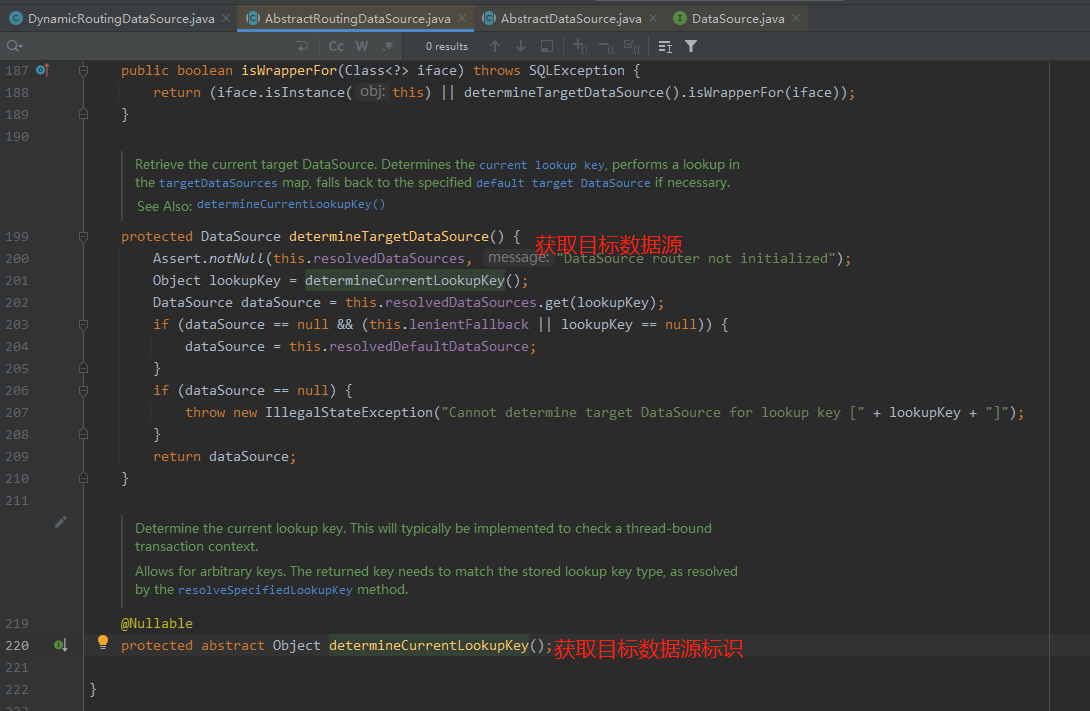
2. A method is defined in this class determineTargetDataSource, which will obtain the current target data source identifier, and then return the real data source;
It is worth noting that it determineCurrentLookupKeyis an abstract method, which is obviously intended to allow users to customize the business logic for obtaining the data source ID.
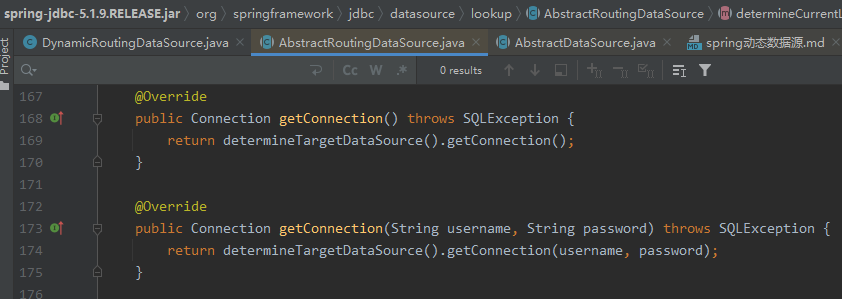
3. Before the system performs database operations, it will first obtain the data source link, that is, call getConnectionthe method. The rewritten getConnectionmethod of this class will obtain the real target data source, and then entrust the database operation to the target data source for processing.
Read-write separation implementation V1 version
- Configure master-slave database connection information in yml
spring:
datasource:
business-master:
url: jdbc:mysql://ip1:3306/xxx
username: c_username
password: p1
business-slaver:
url: jdbc:mysql://ip2:3306/xxx
username: c_username
password: p2
2. Read the master-slave data source configuration in yml
@Data
@ConfigurationProperties(prefix = "spring.datasource")
@Component
public class DataSourcePropertiesConfig {
/**
* 主库配置
*/
DruidDataSource businessMaster;
/**
* 从库配置
*/
DruidDataSource businessSlaver;
}
3. Customize the dynamic data source class DynamicRoutingDataSource, inherit AbstractRoutingDataSourcethe class, and rewrite determineCurrentLookupKeythe method to define the logic of obtaining the target data source ID.
The logic here is: define a DataSourceHolderclass, put the data source ID ThreadLocalin it, and get it ThreadLocalfrom it .
public class DynamicRoutingDataSource extends AbstractRoutingDataSource {
/**
* 获取目标数据源标识
*/
@Override
protected Object determineCurrentLookupKey() {
return DataSourceHolder.getDbName();
}
}
public class DataSourceHolder {
/**
* 当前线程使用的 数据源名称
*/
private static final ThreadLocal<String> THREAD_LOCAL_DB_NAME = new ThreadLocal<>();
/**
* 设置数据源名称
*/
public static void setDbName(String dbName) {
THREAD_LOCAL_DB_NAME.set(dbName);
}
/**
* 获取数据源名称,为空的话默认切主库
*/
public static String getDbName() {
String dbName = THREAD_LOCAL_DB_NAME.get();
if (StringUtils.isBlank(dbName)) {
dbName = DbNameConstant.MASTER;
}
return dbName;
}
/**
* 清除当前数据源名称
*/
public static void clearDb() {
THREAD_LOCAL_DB_NAME.remove();
}
}
4. Create a dynamic data source DynamicRoutingDataSourceobject and inject it into the container. Here, two data sources, the master and the slave, are created and initialized, and the data source identifiers are respectively set for them and placed in the DynamicRoutingDataSourceobject for later use.
If there are multiple data sources, you can refer to here for batch definition.
@Configuration
public class DataSourceConfig {
@Autowired
private DataSourcePropertiesConfig dataSourcePropertiesConfig;
/**
* 主库数据源
*/
public DataSource masterDataSource() throws SQLException {
DruidDataSource businessDataSource = dataSourcePropertiesConfig.getBusinessMaster();
businessDataSource.init();
return businessDataSource;
}
/**
* 从库数据源
*/
public DataSource slaverDataSource() throws SQLException {
DruidDataSource businessDataSource = dataSourcePropertiesConfig.getBusinessSlaver();
businessDataSource.init();
return businessDataSource;
}
/**
* 动态数据源
*/
@Bean
public DynamicRoutingDataSource dynamicRoutingDataSource() throws SQLException {
DynamicRoutingDataSource dynamicRoutingDataSource = new DynamicRoutingDataSource();
Map<Object, Object> targetDataSources = new HashMap<>(2);
targetDataSources.put("master", masterDataSource());
targetDataSources.put("slaver", slaverDataSource());
dynamicRoutingDataSource.setDefaultTargetDataSource(masterDS);
dynamicRoutingDataSource.setTargetDataSources(targetDataSources);
dynamicRoutingDataSource.afterPropertiesSet();
return dynamicRoutingDataSource;
}
}
5. Customize a comment and specify the database.
Some commonly used query interfaces can be automatically routed to the reading library to reduce the pressure on the main library.
@Documented
@Inherited
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface DataSourceSwitch {
/**
* 数据源名称,默认主库
*/
String dbName() default "master";
}
6. Define an aspect, intercept all Controllerinterfaces, and use DataSourceSwitchReadthe annotation method to uniformly route to the library query
@Aspect
@Component
@Slf4j
public class DataSourceAspect {
/**
* 切库,若为多个从库,可在这里添加负载均衡策略
*/
@Before(value = "execution ( * com.jd.gyh.controller.*.*(..))")
public void changeDb(JoinPoint joinPoint) {
Method m = ((MethodSignature) joinPoint.getSignature()).getMethod();
DataSourceSwitch dataSourceSwitch = m.getAnnotation(DataSourceSwitch.class);
if (dataSourceSwitch == null) {
DataSourceHolder.setDbName(DbNameConstant.MASTER);
log.info("switch db dbName = master");
} else {
String dbName = dataSourceSwitch.dbName();
log.info("switch db dbName = {}", dbName);
DataSourceHolder.setDbName(dbName);
}
}
}
Ministry of Industry and Information Technology: Do not provide network access services for unregistered apps Go 1.21 officially released Ruan Yifeng released " TypeScript Tutorial" Bram Moolenaar, the father of Vim, passed away due to illness The self-developed kernel Linus personally reviewed the code, hoping to calm down the "infighting" driven by the Bcachefs file system. ByteDance launched a public DNS service . Excellent, committed to the Linux kernel mainline this monthAuthor: Guo Yanhong, Jingdong Technology
Source: JD Cloud Developer Community