Table of contents
1 Overview of Regular Expressions
2.1 Regular expression syntax elements
2.2 Grouping operations of regular expressions
3 re module details and examples
4 Regular expression modifiers
Column guide

Column subscription address: https://blog.csdn.net/qq_35831906/category_12375510.html

1 Overview of Regular Expressions
What is python's regular expression, what are its contents, what are its functions, and how to use it?
Python's regular expressions are a powerful tool for manipulating strings, repowered by modules. Regular expressions allow you to match, search, replace, and extract text data based on specific patterns.
The basic components of a regular expression include:
- Literal characters: ordinary characters, such as 'a', 'b', etc., which directly match the corresponding characters.
- Metacharacters: Characters with special meanings, such as '.' matches any character, '\d' matches a number, etc.
- Qualifier: used to specify the number of matches of the pattern, for example, '*' matches 0 or more times, '+' matches 1 or more times, etc.
- Character class: used to match any character in a set of characters, for example '[abc]' matches 'a', 'b' or 'c'.
- Exclude characters: Use '^' in a character class to exclude specified characters.
- Escape character: used to match the special character itself, for example, use '.' to match the actual dot.
Regular expressions have many functions in text processing:
- Pattern Matching: Finds whether a string contains a specific pattern.
- Text Search: Searches for the first occurrence of a matching pattern in a string.
- Find All: Finds all occurrences of a matching pattern in a string and returns a list of all matching results.
- Split: Split a string into parts based on a pattern.
- Replace: Replaces the portion matching the pattern with the specified string.
Here is a simple example using regular expressions:
import re
pattern = r'\d+' # 匹配一个或多个数字
text = "There are 123 apples and 456 oranges."
# 搜索
search_result = re.search(pattern, text)
if search_result:
print("Found:", search_result.group())
# 查找所有
findall_result = re.findall(pattern, text)
print(findall_result) # Output: ['123', '456']
In the above code,
re.search()the function searches for the first matching number whilere.findall()the function finds all matching numbers in the string.When using regular expressions, you should ensure that the pattern can correctly match the target text, while taking care to handle possible exceptions. Proficient in regular expressions, can achieve efficient and flexible matching, search and replace operations in text processing
2 Regular expression syntax
2.1 Regular expression syntax elements
Line locators, metacharacters, qualifiers, character classes, exclusion characters, selection characters, and escape characters are the basic building blocks of regular expressions, which are used to describe and match patterns in strings.
row locator:
"^": Match the beginning of the string."$": Matches the end of the string.Metacharacters:
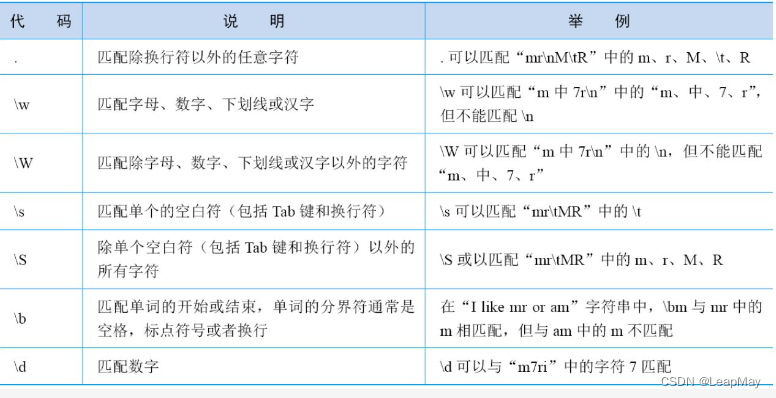
".": Matches any character (except newline)."\d": Matches any numeric character, equivalent to[0-9]."\D": Matches any non-numeric character, equivalent to[^0-9]."\w": Matches any letter, number or underscore character, equivalent to[a-zA-Z0-9_]."\W": Matches any non-alphanumeric or underscore character, equivalent to[^a-zA-Z0-9_]."\s": Matches any whitespace character, including spaces, tabs, newlines, etc."\S": Matches any non-blank character.Qualifier:
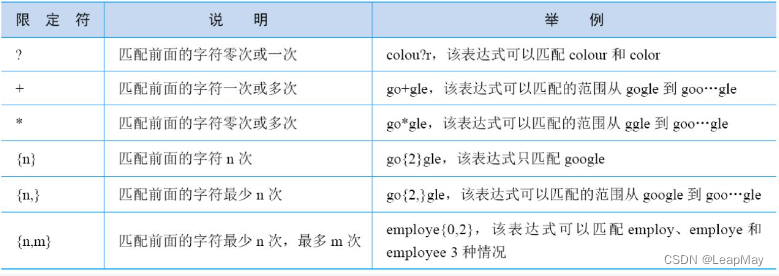
"*": Matches the preceding character zero or more times."+": Matches the previous character one or more times."?": Matches the preceding character zero or one time."{n}": Matches the previous character exactly n times."{n,}": Match the previous character at least n times."{n, m}": Match the previous character at least n times but not more than m times.character class:
"[...]": Match any character within the square brackets."[^...]": Match any character except the characters in square brackets.Exclude characters:
"^": Used within a character class to exclude specified characters.Select characters:
"|": Logical OR, matches one of the two patterns.escape character:
"\": Used to escape special characters so that they lose their special meaning, such as\.matching actual dotsThe combination of these metacharacters and special symbols forms the pattern of the regular expression, so that the regular expression can describe very complex string matching rules. To use regular expressions, you can use
refunctions provided by Python's modules for matching, searching, replacing, and more. Familiarity with these basic elements helps to write more powerful and flexible regular expressions.
Example:
import re
# 行定位符
pattern1 = r'^Hello' # 匹配以"Hello"开头的字符串
print(re.match(pattern1, "Hello, World!")) # Output: <re.Match object; span=(0, 5), match='Hello'>
pattern2 = r'World$' # 匹配以"World"结尾的字符串
print(re.search(pattern2, "Hello, World!")) # Output: <re.Match object; span=(7, 12), match='World'>
# 元字符
pattern3 = r'a.c' # 匹配"a"、任意字符、"c"
print(re.search(pattern3, "abc")) # Output: <re.Match object; span=(0, 3), match='abc'>
print(re.search(pattern3, "adc")) # Output: <re.Match object; span=(0, 3), match='adc'>
print(re.search(pattern3, "a,c")) # Output: <re.Match object; span=(0, 3), match='a,c'>
pattern4 = r'ab*' # 匹配"a"、"b"出现0次或多次
print(re.search(pattern4, "abbb")) # Output: <re.Match object; span=(0, 1), match='a'>
print(re.search(pattern4, "ac")) # Output: <re.Match object; span=(0, 0), match=''>
pattern5 = r'ab+' # 匹配"a"、"b"出现1次或多次
print(re.search(pattern5, "abbb")) # Output: <re.Match object; span=(0, 4), match='abbb'>
print(re.search(pattern5, "ac")) # Output: None
pattern6 = r'ab?' # 匹配"a"、"b"出现0次或1次
print(re.search(pattern6, "abbb")) # Output: <re.Match object; span=(0, 1), match='a'>
print(re.search(pattern6, "ac")) # Output: <re.Match object; span=(0, 0), match=''>
# 限定符
pattern7 = r'a{3}' # 匹配"a"出现3次
print(re.search(pattern7, "aaa")) # Output: <re.Match object; span=(0, 3), match='aaa'>
print(re.search(pattern7, "aaaa")) # Output: <re.Match object; span=(0, 3), match='aaa'>
print(re.search(pattern7, "aa")) # Output: None
pattern8 = r'a{3,5}' # 匹配"a"出现3次到5次
print(re.search(pattern8, "aaa")) # Output: <re.Match object; span=(0, 3), match='aaa'>
print(re.search(pattern8, "aaaaa")) # Output: <re.Match object; span=(0, 5), match='aaaaa'>
print(re.search(pattern8, "aaaaaa")) # Output: <re.Match object; span=(0, 5), match='aaaaa'>
# 字符类和排除字符
pattern9 = r'[aeiou]' # 匹配任意一个小写元音字母
print(re.search(pattern9, "apple")) # Output: <re.Match object; span=(0, 1), match='a'>
print(re.search(pattern9, "banana")) # Output: <re.Match object; span=(1, 2), match='a'>
print(re.search(pattern9, "xyz")) # Output: None
pattern10 = r'[^0-9]' # 匹配任意一个非数字字符
print(re.search(pattern10, "hello")) # Output: <re.Match object; span=(0, 1), match='h'>
print(re.search(pattern10, "123")) # Output: None
# 转义字符
pattern11 = r'\.' # 匹配句号
print(re.search(pattern11, "www.example.com")) # Output: <re.Match object; span=(3, 4), match='.'>
# 分组
pattern12 = r'(ab)+' # 匹配"ab"出现1次或多次作为一个整体
print(re.search(pattern12, "ababab")) # Output: <re.Match object; span=(0, 6), match='ababab'>
The output shows the start and end positions of the matched substring, as well as the actual string content of the match.
Common Metacharacters
common qualifier
2.2 Grouping operations of regular expressions
In regular expressions, grouping is a mechanism for combining multiple subpatterns and processing them individually. ()More complex matching and extraction operations can be achieved by using parentheses to create groupings.
Grouping functions include:
-
Priority control: Grouping can be used to change the priority of subpatterns to ensure correct matching order.
-
Subpattern reuse: You can name a subpattern and refer to the name in subsequent regular expressions to achieve reuse of the same pattern.
-
Sub-pattern extraction: Matching substrings can be extracted by grouping to facilitate further processing of the contents.
Example:
import re
text = "John has 3 cats and Mary has 2 dogs."
# 使用分组提取匹配的数字和动物名称
pattern = r'(\d+)\s+(\w+)' # 使用括号创建两个分组:一个用于匹配数字,另一个用于匹配动物名称
matches = re.findall(pattern, text) # 查找所有匹配的结果并返回一个列表
for match in matches:
count, animal = match # 将匹配结果拆分为两个部分:数字和动物名称
print(f"{count} {animal}")
# 使用命名分组
pattern_with_name = r'(?P<Count>\d+)\s+(?P<Animal>\w+)' # 使用命名分组,给子模式指定名称Count和Animal
matches_with_name = re.findall(pattern_with_name, text) # 查找所有匹配的结果并返回一个列表
for match in matches_with_name:
count = match['Count'] # 通过名称获取匹配结果中的数字部分
animal = match['Animal'] # 通过名称获取匹配结果中的动物名称部分
print(f"{count} {animal}")
The above code demonstrates how to use grouping to extract matched substrings in regular expressions. The first regular expression uses ordinary grouping to extract numbers and animal names separately through parentheses. The second regular expression uses named grouping, and
(?P<Name>...)the grammatical form used specifies the name for the subpattern, so that the corresponding substring can be obtained by the name in the matching result. This can make the code more readable and facilitate subsequent processing and use of the matching results.
The above code reports an error as follows
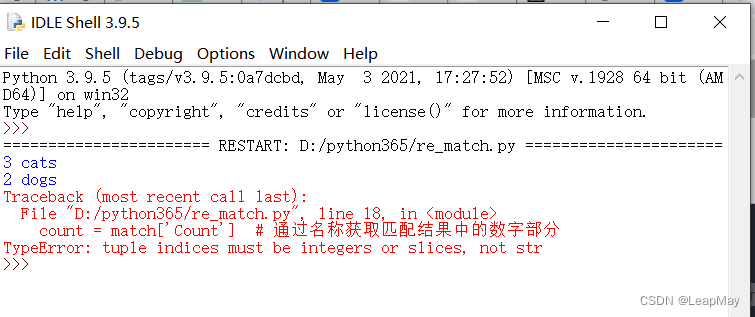
"TypeError: tuple indices must be integers or slices, not str" This error means that your code is trying to use strings as tuple indices, but tuple indices can only be integers or slices.
When using a tuple, you need to use integers or slices to get the elements in the tuple, such as:
my_tuple[0]ormy_tuple[1:3], these are legal indexing methods. But if you try to use strings to index elements in tuples, for example:my_tuple['key'], this is invalid, because tuples do not have key-value pairs associated with string indexes.
Correction: Get the content in the matching result with .re.finditer()替代第二个 re.findall(),用match.group()
更正后代码:
import re
text = "John has 3 cats and Mary has 2 dogs."
# 使用分组提取匹配的数字和动物名称
pattern = r'(\d+)\s+(\w+)' # 使用括号创建两个分组:一个用于匹配数字,另一个用于匹配动物名称
matches = re.findall(pattern, text) # 查找所有匹配的结果并返回一个列表
for match in matches:
count, animal = match # 将匹配结果拆分为两个部分:数字和动物名称
print(f"{count} {animal}")
# 使用命名分组
pattern_with_name = r'(?P<Count>\d+)\s+(?P<Animal>\w+)' # 使用命名分组,给子模式指定名称Count和Animal
matches_with_name = re.finditer(pattern_with_name, text) # 使用re.finditer()查找所有匹配的结果
for match in matches_with_name:
count = match.group('Count') # 通过名称获取匹配结果中的数字部分
animal = match.group('Animal') # 通过名称获取匹配结果中的动物名称部分
print(f"{count} {animal}")
Note:
re.findall()Bothre.finditer()are functions for regular expression matching in Python, and the difference between them is that the returned result types are different.
re.findall(pattern, string):findallThe function will return all the results matching the regular expressionpatternand return them in the form of a list. Each matching result will be stored as a string element in the list. If there is a group in the regular expression,findallonly the content in the group will be returned instead of the complete matching result.
re.finditer(pattern, string): The function also returns all the results matchingfinditerthe regular expression , but differently , it returns an iterator. Each iterator object represents a matching result, and the contents of the matching result can be obtained through the iterator method. If there are groups in the regular expression, methods can be used to access the contents of each group.patternfindallfinditergroup()group()To sum it up,
re.findall()a list is returned, whereasre.finditer()an iterator is returned. If you need to process multiple matching results, itfinditeris more flexible and efficient to use, because it will not return all matching results at once, but provide them on demand when needed.
3 re module details and examples
reThe module is a built-in module in Python for processing regular expressions, providing a series of functions for string matching, searching, replacing, and splitting. The following are rethe main functions of the module:
re.compile(pattern, flags=0): Compile the regular expression pattern and return a regular expression object. If you want to use the same regular expression multiple times, you can use this function to precompile to improve performance.
re.match(pattern, string, flags=0): Attempts to match the pattern from the beginning of the string, and returns a match object if the match is successful; otherwise returns None.
re.search(pattern, string, flags=0): Searches for the first occurrence of the matching pattern in the entire string, and returns a match object if the match is successful; otherwise returns None.
re.findall(pattern, string, flags=0): Finds all occurrences of a matching pattern in a string, returning a list of all matching results.
re.finditer(pattern, string, flags=0): Find all occurrences of the matching pattern in the string, return an iterator, you can get the matching object through the iterator.
re.split(pattern, string, maxsplit=0, flags=0): Split the string into multiple parts according to the pattern and return a list.
re.sub(pattern, replacement, string, count=0, flags=0): Replace the part matching the pattern with the specified string, and return the replaced string.
In the above functions, patternis the pattern of the regular expression, stringis the string to be matched or processed, flagsis an optional parameter, and is used to specify the modifier of the regular expression. Among them, flagsparameters can be combined using multiple modifiers, such as using re.IGNORECASE | re.MULTILINEto specify ignore case and multi-line matching.
The following examples demonstrate rethe use of various functions in the module and cover functions such as matching, searching, replacing, splitting, named grouping, etc.:
import re
text = "John has 3 cats, Mary has 2 dogs."
# 使用re.search()搜索匹配模式的第一个出现
pattern_search = r'\d+\s+\w+'
search_result = re.search(pattern_search, text)
if search_result:
print("Search result:", search_result.group()) # Output: "3 cats"
# 使用re.findall()查找所有匹配模式的出现,并返回一个列表
pattern_findall = r'\d+'
findall_result = re.findall(pattern_findall, text)
print("Find all result:", findall_result) # Output: ['3', '2']
# 使用re.sub()将匹配模式的部分替换为指定的字符串
pattern_sub = r'\d+'
replacement = "X"
sub_result = re.sub(pattern_sub, replacement, text)
print("Sub result:", sub_result) # Output: "John has X cats, Mary has X dogs."
# 使用re.split()根据模式将字符串分割成多个部分
pattern_split = r'\s*,\s*' # 匹配逗号并去除前后空格
split_result = re.split(pattern_split, text)
print("Split result:", split_result) # Output: ['John has 3 cats', 'Mary has 2 dogs.']
# 使用命名分组
pattern_named_group = r'(?P<Name>\w+)\s+has\s+(?P<Count>\d+)\s+(?P<Animal>\w+)'
matches_with_name = re.finditer(pattern_named_group, text)
for match in matches_with_name:
name = match.group('Name')
count = match.group('Count')
animal = match.group('Animal')
print(f"{name} has {count} {animal}")
# 使用re.compile()预编译正则表达式
pattern_compile = re.compile(r'\d+')
matches_compiled = pattern_compile.findall(text)
print("Compiled findall result:", matches_compiled) # Output: ['3', '2']
The above examples demonstrate the use of
remodules for regular expression matching, searching, replacing, splitting, and named grouping. The comments explain the function and expected output of each step. Through the reasonable use of regular expressions, complex processing requirements for strings can be quickly realized.
4 Regular expression modifiers
In Python's regular expressions, modifiers (also known as flags or mode flags) are optional parameters that can be passed to functions when compiling the regular expression re.compile()or used directly in the regular expression string to change the matching behavior.
The following are commonly used regular expression modifiers:
re.IGNORECASEOrre.I: ignore case matching. After using this modifier, you can ignore the difference in case when matching.
re.MULTILINEOrre.M: Multi-line match. After using this modifier,^and$match the beginning and end of the string respectively, and can also match the beginning and end of each line in the string (each line is separated by a newline).
re.DOTALLOrre.S: Single-line match. When this modifier is used,.any character including newline will be matched.
re.ASCIIOrre.A: Make non-ASCII characters match only their ASCII counterparts. For example,\wwill only match ASCII letters, numbers, and underscores, but not non-ASCII characters.
re.UNICODEOrre.U: Use Unicode matching. In Python 3, regular expressions use Unicode matching by default.
re.VERBOSEOrre.X: use a "more readable" regular expression. Comments and whitespace can be added to the expression, which can make the regular expression more readable.
In Python, regular expression modifiers (also known as flags) are optional parameters used to adjust the matching behavior of regular expressions. Modifiers can be added at the end of a regular expression pattern to affect how the pattern is matched. The following are commonly used regular expression modifiers:
The following examples demonstrate the use of these modifiers:
import re
# 不区分大小写匹配
pattern1 = r'apple'
text1 = "Apple is a fruit."
match1 = re.search(pattern1, text1, re.I)
print(match1.group()) # Output: "Apple"
# 多行匹配
pattern2 = r'^fruit'
text2 = "Fruit is sweet.\nFruit is healthy."
match2 = re.search(pattern2, text2, re.M)
print(match2.group()) # Output: "Fruit"
# 点号匹配所有字符
pattern3 = r'apple.*orange'
text3 = "apple is a fruit.\noranges are fruits."
match3 = re.search(pattern3, text3, re.S)
print(match3.group()) # Output: "apple is a fruit.\noranges"
# 忽略空白和注释
pattern4 = r'''apple # This is a fruit
\s+ # Match one or more whitespace characters
is # followed by "is"
\s+ # Match one or more whitespace characters
a # followed by "a"
\s+ # Match one or more whitespace characters
fruit # followed by "fruit"'''
text4 = "Apple is a fruit."
match4 = re.search(pattern4, text4, re.X)
print(match4.group()) # Output: "apple is a fruit"