Summary
Non-local patch based methods were until recently state-of-the-art for image denoising but are now outper formed by CNNs. Y et they are still the state-of-the-art for video denoising, as video redundancy is a key factor to attain high denoising performance. The problem is that CNN architectures are hardly compatible with the search for self-similarities. In this work we propose a new and efficient way to feed video self-similarities to a CNN. The non-locality is incorporated into the network via a first non-trainable layer which finds for each patch in the input image its most similar patches in a search region. The central values of these patches are then gathered in a feature vector which is assigned to each image pixel. This information is presented to a CNN which is trained to predict the clean image. We apply the proposed architecture to image and video denoising. For the latter patches are searched for in a 3D spatio-temporal volume. The proposed architecture achieves state-of-the-art results. To the best of our knowledge, this is the first successful application of a CNN to video denoising.
Non-local patch based methods were until recently the state-of-the-art for image denoising, but are now surpassed by CNNs. However, they are still state-of-the-art techniques for video denoising, since video redundancy is a key factor for high denoising performance. The problem is that CNN architectures are hardly compatible with searching for self-similarity. In this work, we propose a new and efficient method for feeding video self-similarity to CNNs. Nonlocality is incorporated into the network via a first non-trainable layer, which finds for each patch in the input image its most similar patch in the search region. The center values of these patches are then collected in feature vectors assigned to each image pixel. This information is presented to a CNN trained to predict clean images. We apply the proposed architecture to image and video denoising. For the latter, patches are searched in the 3D space-time volume. The proposed architecture achieves state-of-the-art results. To the best of our knowledge, this is the first successful application of CNNs to video denoising.
introduction
(1) In the case of limited exposure time, low signal-to-noise ratio is inevitable, and the noise is high
(2) By applying the denoising algorithm iteratively, therefore, it is important to reduce the running time
Image denoising related literature
(1)CNNs are amenable to efficient parallelization on GPUs potentially enabling real-time performance.
(2) two types of CNN approaches: trainable inference networks and black box networks. (trainable inference network models and models that do not require training)
2.1 The first one obtains results by imitating the iteration of some optimization algorithms, but it may lead to some different architectures and limit the design of network models
2.2 The second type regards it as a standard regression problem. Although it has not used too much research before, its technology is among the best, such as CNN
2.3 引出Although these architectures produce very good results,
for textures formed by repetitive patterns, non-local patch-based methods still perform better
Although these architectures produce very good results, for textures formed by repetitive patterns, non-local patch-based methods still perform better
Video denoising related literature
1. CNN is used in many aspects of video processing, but it is limited in video denoising.
2. In terms of output quality, the state-of-the-art is achieved by patch-based methods[16, 35, 3, 19, 9, 53]. They make great use of the self-similarity of natural images and videos, i.e. most patches are surrounded by several similar patches (spatial and temporal). Each patch is denoised using these similar patches, which are searched in the area around it. The search area is usually a space-time cube, but more complex search strategies involving optical flow are also used. Since such a wide search neighborhood is used, these methods are called non-local.
Advantages: perform very wellDisadvantages: computation-ally costly(Because of their complexity)
Not applicable to: high resolution video processing.
3. Patch-based methods usually follow three steps that can
be iterated: (1) search for similar patches, (2) denoise groups of similar patches, and (3) aggregate denoised patches to form denoised frames.
VBM3D [16] improves the image denoising algorithm BM3D [17] by using a "predictive search" strategy to search for similar patches in adjacent frames, speeding up the search and providing some temporal consistency. VBM4D [35] generalizes this idea to 3D patches. In VNLB [2], non-motion-compensated spatio-temporal patches are used to improve temporal consistency. In [19], a general search method extends each patch-based denoising algorithm to a global video denoising algorithm by extending the patch search to the entire video. SPTWO [9] and DDVD [8] use optical flow to warp adjacent frames to each target frame. Each block of the target frame is then denoised using a similar block from this volume using a Bayesian strategy similar to [29]. More recently, [53] proposed to use batches of frames to learn an adaptive optimal transformation
4. Patch-based methods also implement the state-of-the-art in frame-recursive methods [20, 4]. These methods only use the current noisy frame and the previous denoised frame to compute the current frame. They achieve lower results than non-recursive methods, but have a smaller memory footprint and are (possibly) less computationally expensive.
Contributions
a non-local architecture for image and video denoisingIn this work, we propose a non-local architecture that is not limited by trainable inference networks .
The method
first: computes for each image patch the most similar neighbors in a rectangular spatio-temporal search window and gathers the center pixel of each similar patch forming a feature vector which is assigned to each image location.
This results in an image with n channels, which is fed to a CNN trained to predict the clean image from this high dimensional vector.
First, the n most similar neighbors are computed for each image patch in a rectangular spatiotemporal search window, and the central pixels of each similar patch are collected to form a feature vector assigned to each image location.
This produces an image with n channels, which is fed to a CNN trained to predict a clean image from this high-dimensional vector.
We trained our network
for gray scale and color video denoising.
We train our network for grayscale and color video denoising. The actual training of such an architecture is via GPU-implemented patch search, which allows efficient computation of nearest neighbors. The temporally existing self-similarity in videos can achieve powerful denoising effects with our proposal.

Architecture of the proposed method. The first module performs a block-wise nearest neighbor search on adjacent frames. Then, the feature vector fnl of the current frame and each pixel (nearest neighbor center pixel) is input into the network. The first four layers of the network perform 1×1 convolutions using 32 feature maps. The generated feature maps are the input of a simplified DnCNN [55] network with 15 layers.
Proposed method
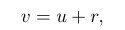
u represents the video, u(x,t) represents the value at position x in frame t, assuming that the observed v is a version of u added with Gaussian white noise. r(x, t) ∼ N (0, σ2).
Non-local features
Let Px,t be the patch centered at pixel x in frame t. The search module computes the distance between a block Px,t and a block in a 3D rectangular search region R of size ws*ws*wt centered at (x,t), where ws and wt are the spatial and temporal dimensions. The positions of these n similar blocks are (xi, ti) (sorted according to the criteria specified later). Note that (x1, t1) = (x, t).
The pixel values at these locations are collected as n-dimensional non-local feature vectors
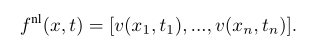
f is a 3D tensor with n channels. This is the input to the network. Note that the first channel of the feature image corresponds to the noise image v.
Network
Our network can be divided into two stages: a non-local stage and a local stage:
The non-local stage It consists of four 1×1 convolutional layers and 32 kernels. The rationale for these layers is to allow the network to compute pixel-wise features from the input raw non-local features f nl .
The second stageReceive the features computed in the first stage. It consists of 14 layers and 64 3 × 3 convolution kernels, followed by batch normalization and ReLU activation. The output layer is a 3×3 convolution. Its architecture is similar to the DnCNN network introduced in [55], albeit with 15 layers instead of 17 (as in [56]). For DnCNN, the network outputs a residual image, which must be subtracted from the noisy image to obtain a denoised image. The training loss is the average mean squared error between the residuals and the noise. For RGB video, we use the same number of layers, but triple the number of features per layer.
Training and dataset
omit
Experimental results
We will first show some experiments to highlight relevant aspects of the proposed method.
We then compare with the state-of-the-art
The untapped potential of non-locality.
The untapped potential of non-native law
Although the focus of this work is on video denoising, it is still interesting to study the performance of the proposed non-local CNN on images.

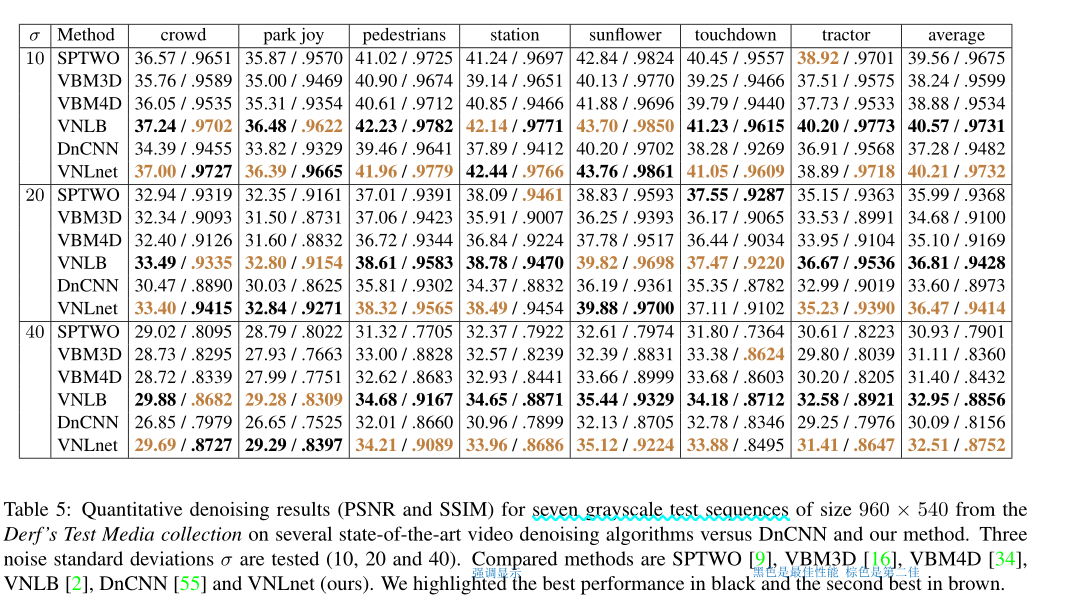
Figure 2 shows a comparison of a baseline CNN (a 15-layer version of DnCNN [55], as in our network) and a version of our method trained for static image denoising (which collects 9 neighbors by comparing 9 × 9 patches) . The results with and without non-local information are very similar, which is confirmed in Table 1. The only differences are visible on very self-similar parts, such as the shutters detailed in Figure 2.

Nonlocality has great potential to improve the results of CNNs. The average PSNR obtained by the oracle method is 31.85dB, which is 0.6dB higher than the baseline. However, this improvement is hampered by the difficulty of finding exact matches in the presence of noise. One way to reduce matching errors is to use larger patches. But on images, larger patches have fewer similar patches. Instead, as we will see below , the temporal redundancy of video allows very large patches to be used .
Parameter tuning parameter tuning
Non-local search has three main parameters: The patch size,`` the number of retained matches and the number of frames in the search region
Three parameters: patch size, number of matches to keep, and number of frames in the search region.

We obtain better and better results by increasing the patch size. The main reason is that the matching accuracy is improved because the influence of noise on the patch distance is reduced

We can see that the former clearly denoises better using large blocks, while the latter remains unaffected around motion regions. This shows that the network is able to determine when the non-local information provided is inaccurate, and falls back to DnCNN-like results in this case (single image denoising), [see Figure 6] Further increasing the patch size will lead to more Regions are processed as a single image. As a result, we see a rather small performance gain from 31×31 to 41×41. For such a large block, only matches of the same object from different frames are likely to be considered neighbors. So we go a step further and force matches to come from different frames, which slightly improves performance. This is shown in Figure 5 and Table 4. Note that the network is retrained as the patch distribution is affected. In fact, when no constraints are imposed, neighbors are ordered by increasing distance. Whereas in this variant, neighbors are sorted by frame index.
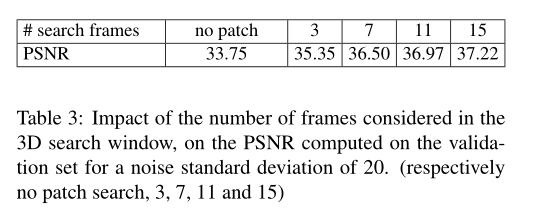


Summary: In the next experiments, we will use 41 × 41 blocks and 15 frames . Another parameter of the non-local search is the spatial width of the search window, which we set to 41 pixels (the center pixel of the test patch must lie within this region). We trained grayscale and color networks for AGWNs of σ 10, 20 and 40 . To emphasize the fact that CNN methods can adapt to multiple noise types, unlike traditional methods, we also train grayscale network box kernels for Gaussian noise correlated through 3 × 3 such that the final standard deviation is σ = 20, and 25% Uniform salt and pepper noise (removed pixels are replaced by random uniform noise).

training results
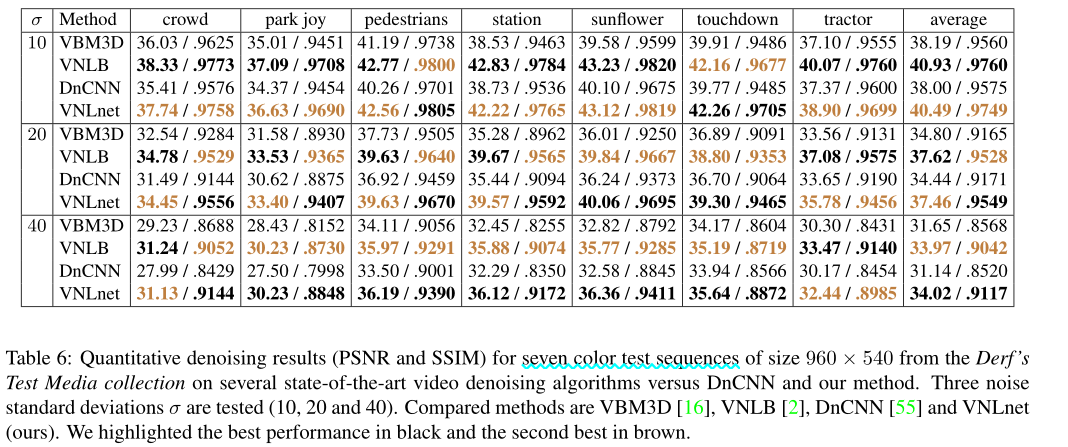
A note on running times: also compares CPU running times


The GPU runtimes in Table 11 indicate that on CPU, our method should be 10x slower than DnCNN. Non-local search is particularly costly since we search for a patch centered at each pixel of the image over 15 frames. By reducing the size of the 3D window using tricks explored in other papers, the patch search can be significantly sped up. For example, VBM3D focuses the search on each frame on a small window around the best match found in the previous frame. A related speedup is to use a search strategy based on PatchMatch [6].
Implementation details
Patch search requires computing the distance between each patch in the image and the patches in the search region . cost a lot
To reduce computational cost: A common approach is to search for nearest neighbors only in subgrids of the image. For example, BM3D processes 1/9 patches with default parameters. Since the processed patches overlap, the aggregation of the denoised patches covers the entire image.
Our proposed method does not have any aggregation. We compute the neighbors of all image patches, which is expensive. In the case of video, use large blocks and large search areas (temporal and spatial) for the best results. Therefore, we need an efficient patch search algorithm
Our implementation uses an optimized GPU core that searches for locations in parallel . For each patch, the best distance relative to all other patches in the search volume is kept in a table. We divide the calculation of the distance into two steps: first calculate the sum of squares across columns
To optimize the speed of the algorithm, we use GPU shared memory as a cache for memory accesses, thereby reducing bandwidth constraints. Also, to sort the distances, the ordered table is stored into GPU registers and only written to memory at the end of the computation. Computation of L2 distances and maintenance of ordered tables have about the same order of magnitude of computational cost. See Appendix A for more details on the implementation
in conclusion
We described a simple yet effective way of incorporating non-local information into a CNN for video denoising. The
proposed method computes for each image patch the n most similar neighbors on a spatio-temporal window and gathers
the value of the central pixel of each similar patch to form a non-local feature vector which is given to a CNN. Our
method yields a significant gain compared to using the single frame baseline CNN on each video frame.
We describe a simple yet effective method for incorporating non-local information into CNNs for video denoising. The proposed method computes the n most similar neighbors over a spatio-temporal window for each image patch, and collects the values of the central pixel of each similar patch to form a non-local feature vector, which is fed to a CNN. Our method yields significant gains compared to using a single-frame baseline CNN on each video frame.
We have seen the importance of having reliable matches: On the validation set, the best performing method used
patches of size 41 × 41 for the patch search. We have alsonoticed that on regions with non-reliable matches (complex
motion), the network reverts to a result similar to single image denoising. Thus we believe future works should fo-
cus on improving this area, by possibly adapting the size of the patch and passing information about the quality of the matches to the network.
We have already seen the importance of reliable matching: on the validation set, the best performing method uses patches of size 41 × 41 for patch search. We also notice that on regions with unreliable matches (complex motion), the network recovers to results similar to single image denoising. Therefore, we believe that future work should focus on improving this area, possibly adjusting the patch size and passing information about the matching quality to the network.