Experimental principle
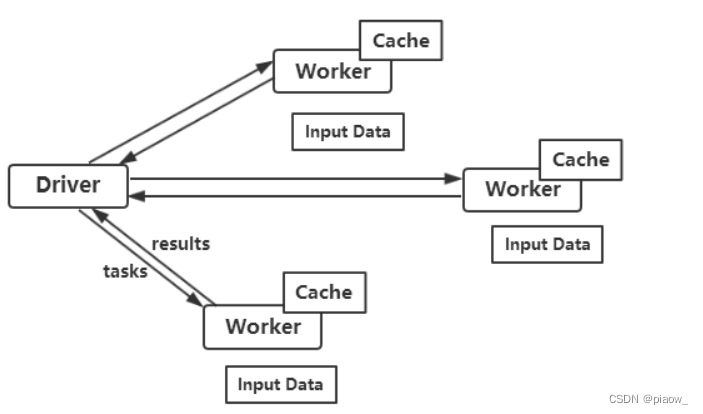
The core of Spark is RDD. All operations on RDD will be run on the Cluster. The Driver program starts many Workers. Workers read data in the (distributed) file system and convert it into RDD (elastic distributed data set), and then RDDs are cached and computed in memory.
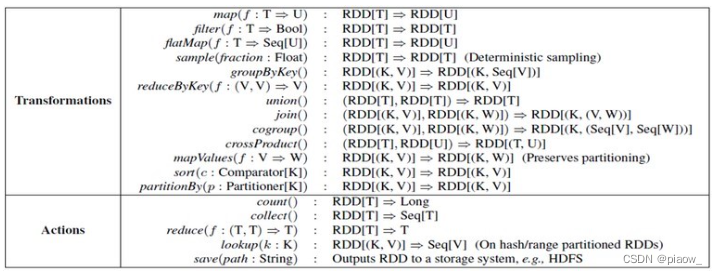
RDD has two types of operations, namely Action (returning values) and Transformations (returning a new RDD).
1. Data display and pre-preparation
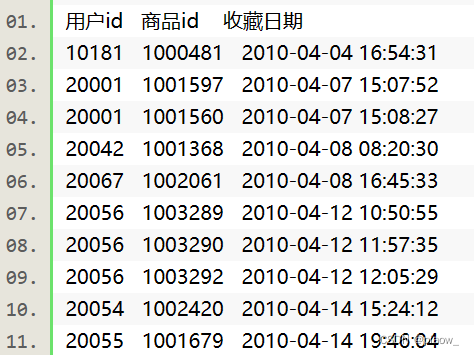
An e-commerce website records a large number of users' collection data of products, and stores the data in a file named buyer_favorite1. The data format and data content are as follows. Before performing
subsequent operations, please enable hadoop and spark services. You can use the jps command to check whether the process is fully enabled.
2. Create a scala project
1. Development environment: eclipse
Open Eclipse with the Scala plug-in installed, and create a new Scala project named spark4.
Create a new package name under the spark4 project and name it my.scala. Name the scala object ScalaWordCount.

2. Import the jar package required for running.
Right-click the project and create a folder named lib.
Import the jar package, right-click the jar package, and click Build Path=>Add to Build Path. (You can go to my resources to download spark1.x hadoop2.x)
3. Write a Scala statement, and count the number of items each user collects in the user collection data.
package my.scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object ScalaWordCount {
def main(args: Array[String]) {
//创建Spark的配置对象sparkConf,设置Spark程序运行时的配置信息;
val conf = new SparkConf()
conf.setMaster("local") .setAppName("scalawordcount")
//创建SparkContext对象,SparkContext是Spark程序所有功能的唯一入口,无论采用Scala、Java还是Python都必须有一个SparkContext;
val sc = new SparkContext(conf)
val rdd = sc.textFile("hdfs://localhost:9000/myspark/buyer_favorite1") //根据具体的数据来源,通过SparkContext来创建RDD;
//对初始的RDD进行Transformation级别的处理。(首先将每一行的字符串拆分成单个的单词,然后在单词拆分的基础上对每个单词实例计数为1;
//最后,在每个单词实例计数为1的基础上统计每个单词在文件出现的总次数)。
rdd.map(line => (line.split("\t")(0), 1))
.reduceByKey(_ + _)
.collect()
.foreach(println)
sc.stop()
}
}
The output results viewed in the control interface console.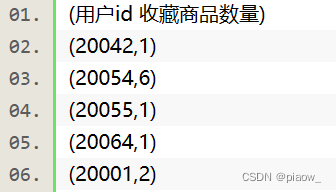
3. Create a Java project
Right-click the project name again, create a new package, and name the package my.java.
Right-click on the package my.java, create a new Class, and name it JavaWordCount.
1. Write Java code to count the number of items collected by each user in the user collection data.
package my.java;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.List;
import java.util.regex.Pattern;
public final class JavaWordCount {
private static final Pattern SPACE = Pattern.compile("\t");
public static void main(String[] args) throws Exception {
SparkConf sparkConf = new SparkConf().setMaster("local").setAppName("JavaWordCount");
JavaSparkContext ctx = new JavaSparkContext(sparkConf);
JavaRDD<String> lines = ctx.textFile("hdfs://localhost:9000/myspark/buyer_favorite1");
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String s) {
String word[]=s.split("\t",2);
return Arrays.asList(word[0]);
}
});
JavaPairRDD<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) {
return new Tuple2<String, Integer>(s, 1);
}
});
JavaPairRDD<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
List<Tuple2<String, Integer>> output = counts.collect();
System.out.println(counts.collect());
counts.saveAsTextFile("hdfs://localhost:9000/myspark/out");
ctx.stop();
}
}
2. View the output results in the linux terminal
Execute the following command to view the results, provided that the cluster has been started
hadoop fs -cat /myspark/out/part-00000
write at the end
It can be seen from this that the superiority of the scala language in writing spark programs is short and concise.