In this review, we provide a comprehensive review of vision-based models, including typical architectural designs combining different modalities (visual, text, audio, etc.), training objectives (comparison, generation), pre-training datasets, fine-tuning mechanisms, and the common prompt mode.
Enter the NLP group —> join the NLP exchange group

论文:Foundational Models Defining a New Era in Vision: A Survey and Outlook
Address: https://arxiv.org/pdf/2307.13721.pdf
项目:https://https://github.com/awaisrauf/Awesome-CV-Foundational-Modelsesome-CV-Foundational-Models
The visual system for observing and reasoning about the compositional properties of visual scenes is fundamental to understanding our world. The complex relationships between objects and their positions, ambiguities, and changes in real-world environments can be better described in human language, naturally governed by grammatical rules and other modalities such as audio and depth.
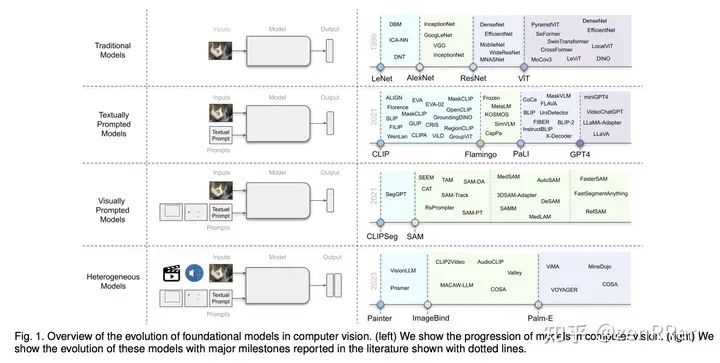
These models learn to bridge the gaps between these patterns and, combined with large-scale training data, facilitate contextual reasoning, generalization, and cueing at test time. These models are called base models.

The output of such models can be modified without retraining by human-provided cues, for example, by providing bounding boxes to segment specific objects, by asking questions about images or video scenes to engage in interactive dialogue, or by language instructions to Manipulate the behavior of the robot.
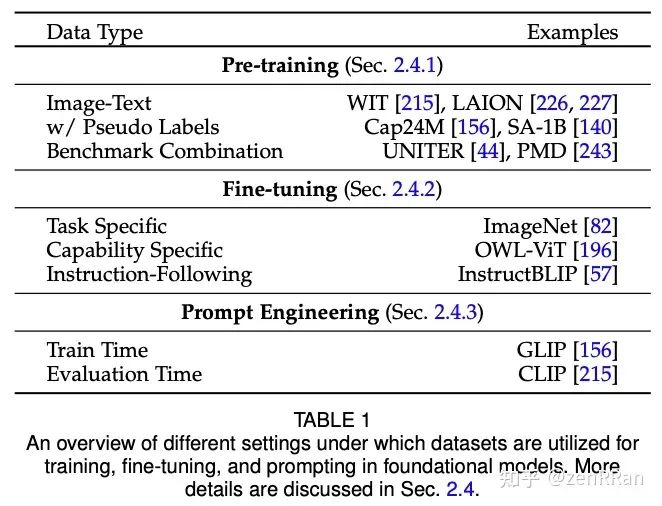
In this survey, we provide a comprehensive review of such emerging foundational models, including typical architectural designs combining different modalities (visual, textual, audio, etc.), training objectives (comparative, generative), pre-trained datasets, fine-tuning Mechanisms, and common modes of prompting; textual, visual, and heterogeneous.
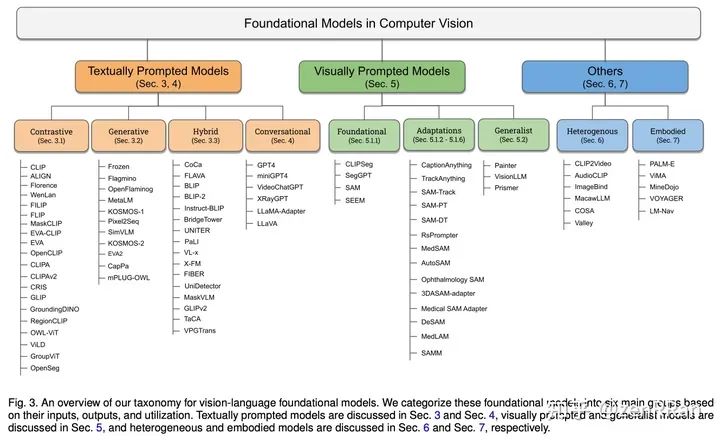

We discuss open challenges and research directions for fundamental models of computer vision, including difficulties in evaluation and benchmarking, gaps in real-world understanding, limitations in contextual understanding, biases, vulnerabilities to adversarial attacks, and interpretability issues.
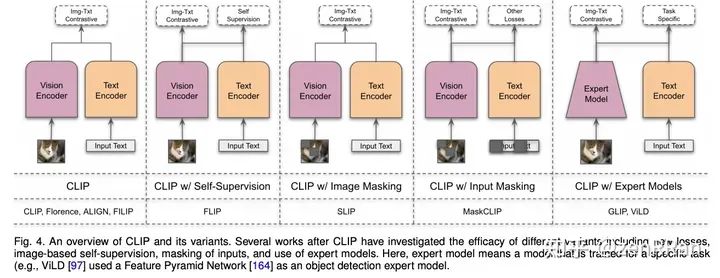
We review recent developments in the field, systematically and comprehensively covering a wide range of applications of the underlying models.

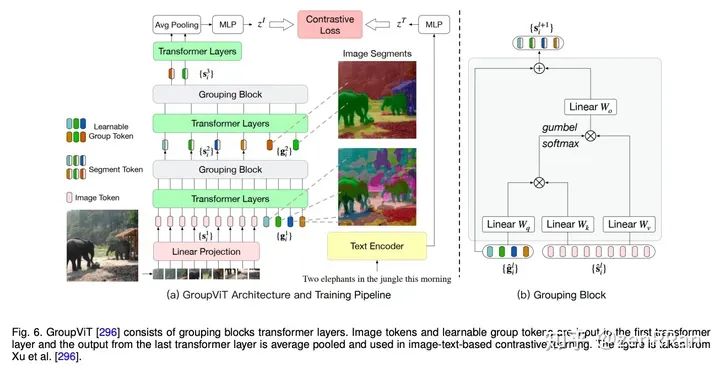
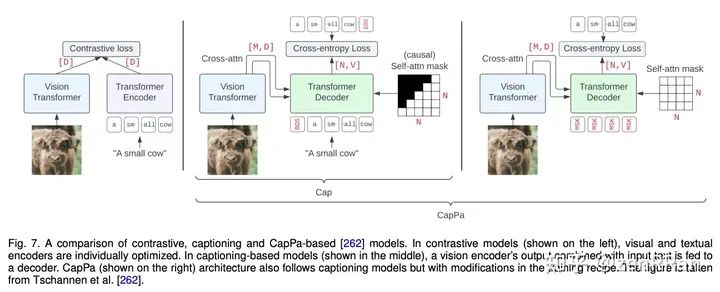
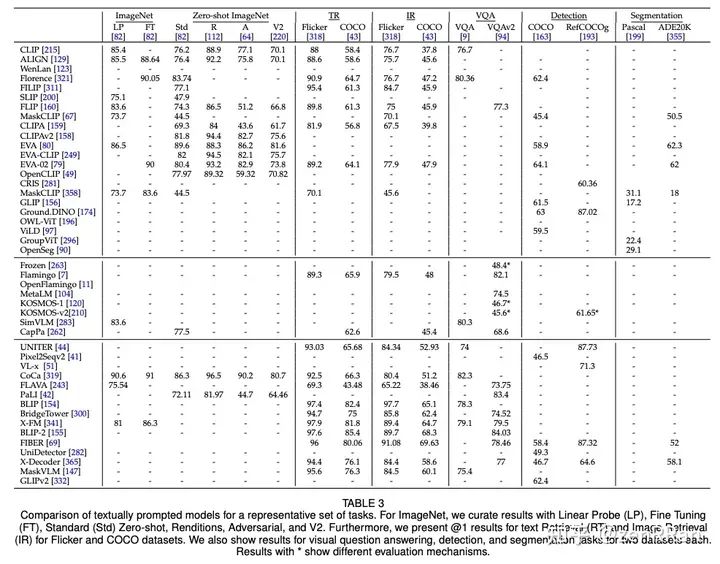
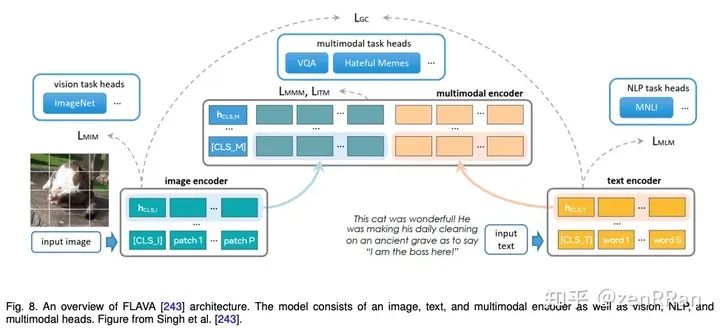
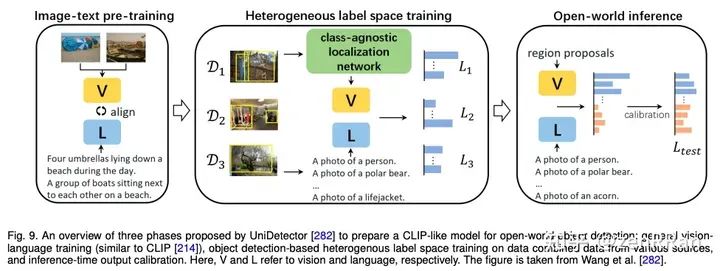
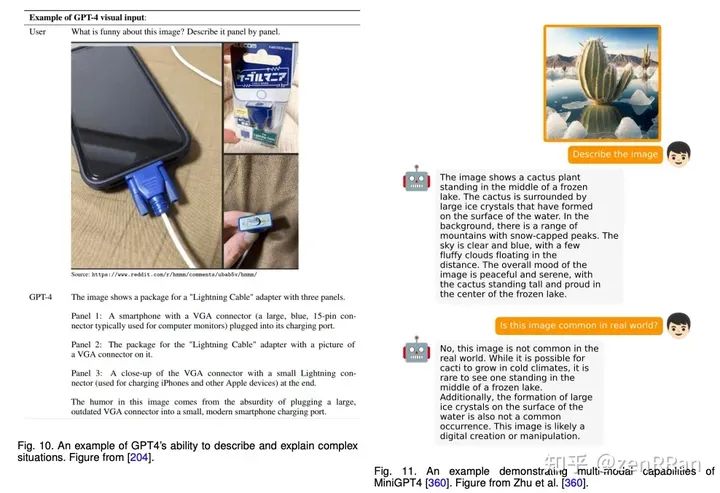
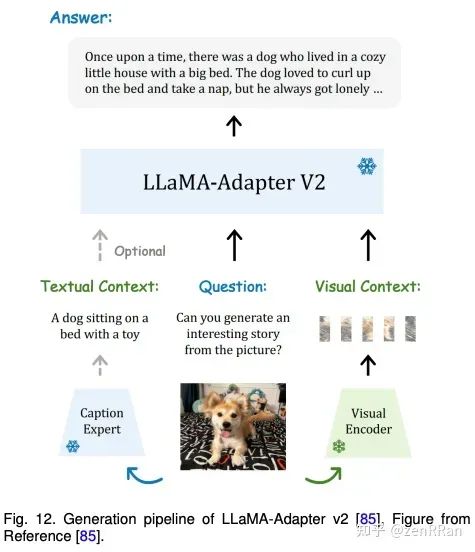
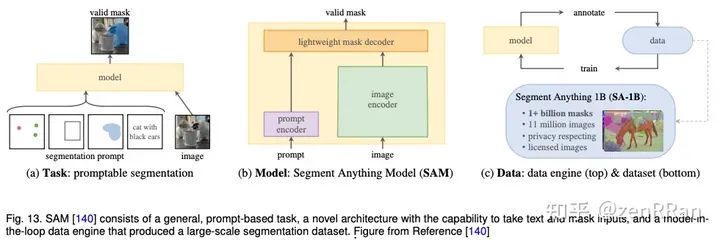
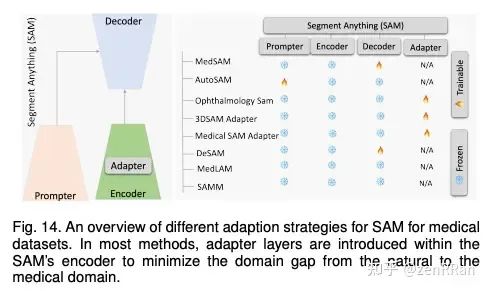

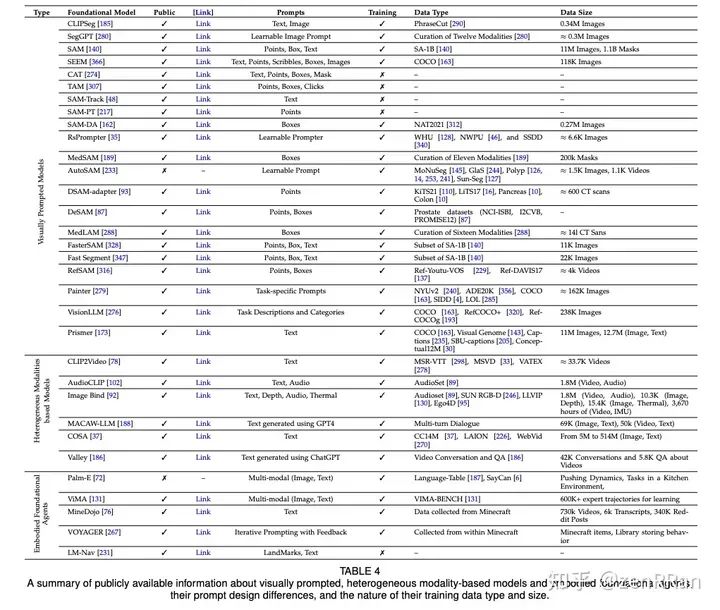
Enter the NLP group —> join the NLP exchange group