CV - Computer Vision | ML - Machine Learning | RL - Reinforcement Learning | NLP Natural Language Processing
Subjects: cs.CL
1.Not All Languages Are Created Equal in LLMs: Improving Multilingual Capability by Cross-Lingual-Thought Prompting

Title: Not All Languages Are Created Equal in LLM: Enhancing Multilingual Competency through Cross-Language Thought Prompts
Authors: Haoyang Huang, Tianyi Tang, Dongdong Zhang, Wayne Xin Zhao, Ting Song, Yan Xia, Furu Wei
Article link: https://arxiv.org/abs/2305.07004



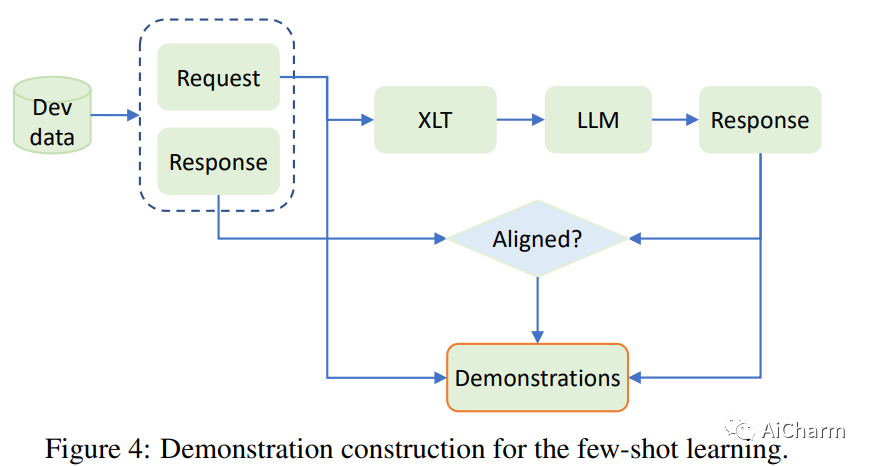


Summary:
Large language models (LLMs) have demonstrated impressive multilingual capabilities, but their performance varies widely across languages. In this work, we introduce a simple yet effective method, called cross-lingual thought prompting (XLT), to systematically improve the multilingual competence of LLMs. Specifically, XLT is a general template cue that stimulates cross-lingual and logical reasoning skills to improve cross-lingual task performance. We conduct comprehensive evaluations on seven typical benchmarks related to reasoning, comprehension and generation tasks, covering both high-resource and low-resource languages. Experimental results show that XLT not only significantly improves the performance of various multilingual tasks, but also significantly narrows the gap between the average performance and the best performance of each task in different languages. Notably, XLT brings an average improvement of more than 10 points in arithmetic reasoning and open-domain question answering tasks.
2.Active Retrieval Augmented Generation
Title: Active Retrieval Enhancement Generation
Authors: Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, Graham Neubig
Article link: https://arxiv.org/abs/2305.06983
Project code: https://github.com/jzbjyb/FLARE
Summary:
Despite their remarkable ability to understand and generate language, large language models (LMs) tend to hallucinate and produce output that doesn't match the truth. Augmenting LM by retrieving information from external knowledge resources is a promising solution. Most existing retrieval-enhanced LMs employ a retrieval-and-generation setting that only retrieves information once based on the input. However, this has limitations in more general cases involving the generation of long texts, where continuous collection of information throughout the generation process is essential. There have been some attempts in the past to retrieve information multiple times while generating output, mostly retrieving documents at regular intervals using the previous context as a query. In this work, we provide a generic view of active retrieval augmentation generation, methods that actively decide when and what to retrieve throughout the generation process. We propose Forward-Looking Active Retrieval-Enhanced Generation (FLARE), a general retrieval-augmented generation method that iteratively uses predictions of upcoming sentences to predict future content, which are then used as queries to retrieve relevant document to regenerate sentences if it contains low confidence tokens. We comprehensively test FLARE and baselines on 4 long-term knowledge-intensive generative tasks/datasets. FLARE achieves excellent or competitive performance on all tasks, demonstrating the effectiveness of our approach.
3.FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance

Title: FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
Authors: Lingjiao Chen, Matei Zaharia, James Zou
Article link: https://arxiv.org/abs/2305.05176
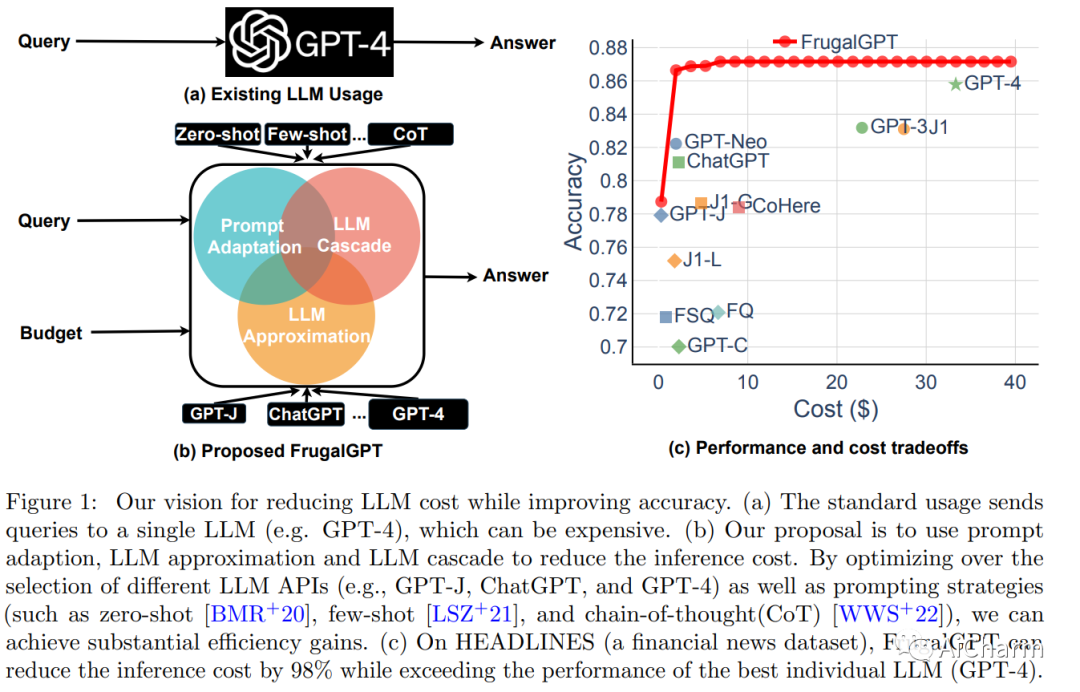



Summary:
The number of large language models (LLMs) that users can query for a fee is growing rapidly. We review the costs associated with querying popular LLM APIs, such as GPT-4, ChatGPT, J1-Jumbo, and find that these models have heterogeneous pricing structures, with fees that can vary by two orders of magnitude. In particular, using LLM on large numbers of queries and text can be expensive. Inspired by this, we outline and discuss three types of strategies that users can leverage to reduce the inference cost associated with using LLMs: 1) hint adaptation, 2) LLM approximation, and 3) LLM cascading. For example, we propose FrugalGPT, a simple yet flexible instance of LLM cascading that learns which combinations of LLMs to use for different queries to reduce cost and improve accuracy. Our experiments show that FrugalGPT can match the performance of the best single LLM (such as GPT-4) at up to 98% lower cost, or achieve 4% higher accuracy than GPT-4 at the same cost. The ideas and findings presented here provide the basis for sustainable and efficient use of LLM.
More Ai information: Princess AiCharm