CV - Computer Vision | ML - Machine Learning | RL - Reinforcement Learning | NLP Natural Language Processing
Subjects: cs.CV
1.Chupa: Carving 3D Clothed Humans from Skinned Shape Priors using 2D Diffusion Probabilistic Models

Title: Chupa: Sculpting 3D Clothed Humans from Skin Shape Priors Using 2D Diffusion Probability Models
作者:Byungjun Kim, Patrick Kwon, Kwangho Lee, Myunggi Lee, Sookwan Han, Daesik Kim, Hanbyul Joo
Article link: https://arxiv.org/abs/2305.11870

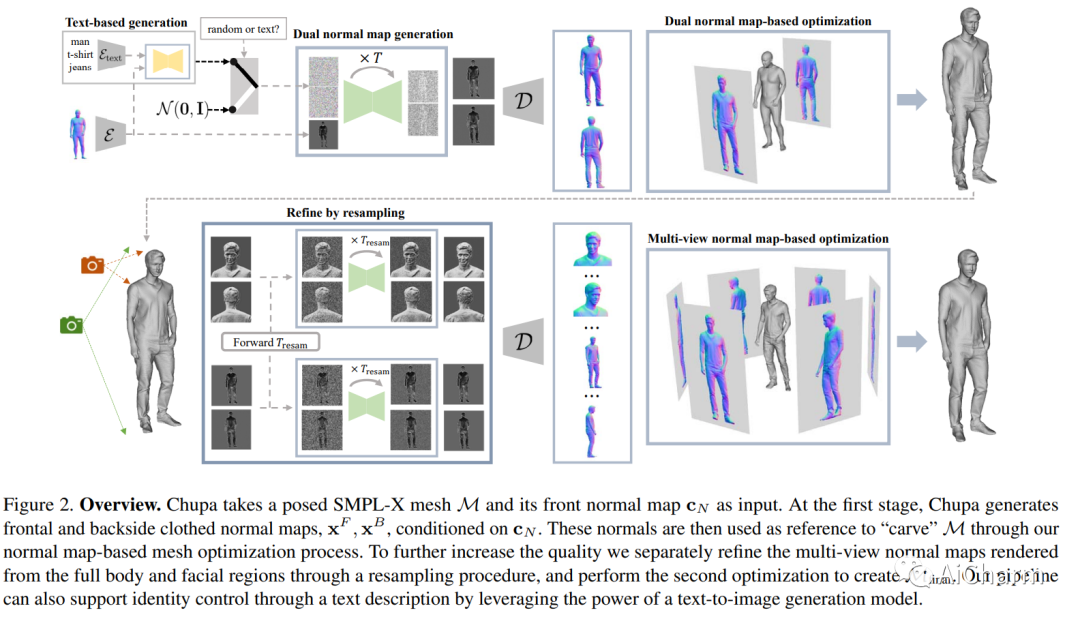
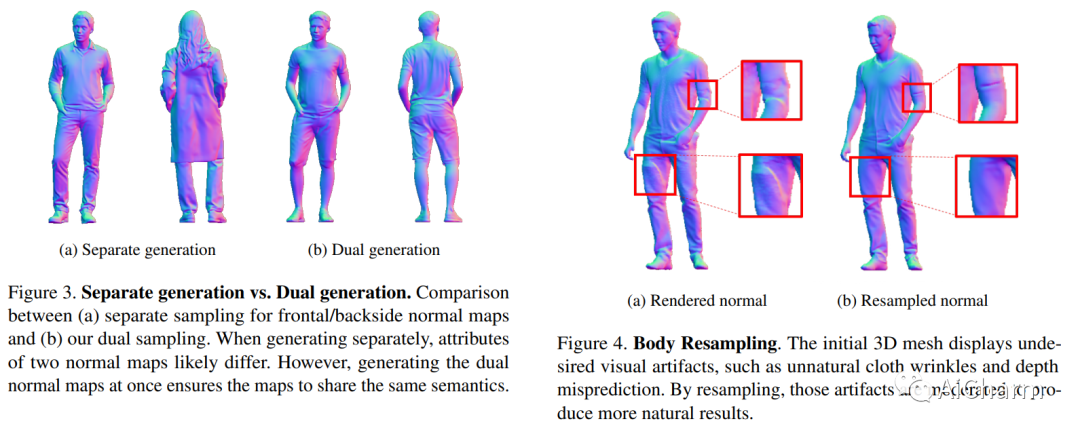

Summary:
We propose a 3D generation pipeline that uses a diffusion model to generate realistic digital avatars of humans. Generation of 3D human meshes has been a challenging problem due to the diversity of human identities, poses, and random details. To address this, we decompose the problem into 2D normal map generation and normal map based 3D reconstruction. Specifically, we first use a pose-conditioned diffusion model to simultaneously generate realistic normal maps, called dual normal maps, for the front and back of a person wearing clothes. For 3D reconstruction, we "sculpt" the previous SMPL-X mesh into a detailed 3D mesh based on normal maps via mesh optimization. To further enhance high-frequency details, we propose a diffuse resampling scheme in body and face regions, thus encouraging the generation of realistic avatars. We also seamlessly integrate recent text-to-image diffusion models to support text-based human identity control. Our method, Chupa, is able to generate realistic 3D clothed people with better perceptual quality and identity diversity.
2.RoomDreamer: Text-Driven 3D Indoor Scene Synthesis with Coherent Geometry and Texture

Title: RoomDreamer: Text-Driven 3D Interior Scene Synthesis with Coherent Geometry and Textures
Authors: Liangchen Song, Liangliang Cao, Hongyu Xu, Kai Kang, Feng Tang, Junsong Yuan, Yang Zhao
Article link: https://arxiv.org/abs/2305.11337
Project code: https://www.youtube.com/watch?v=p4xgwj4QJcQ&feature=youtu.be


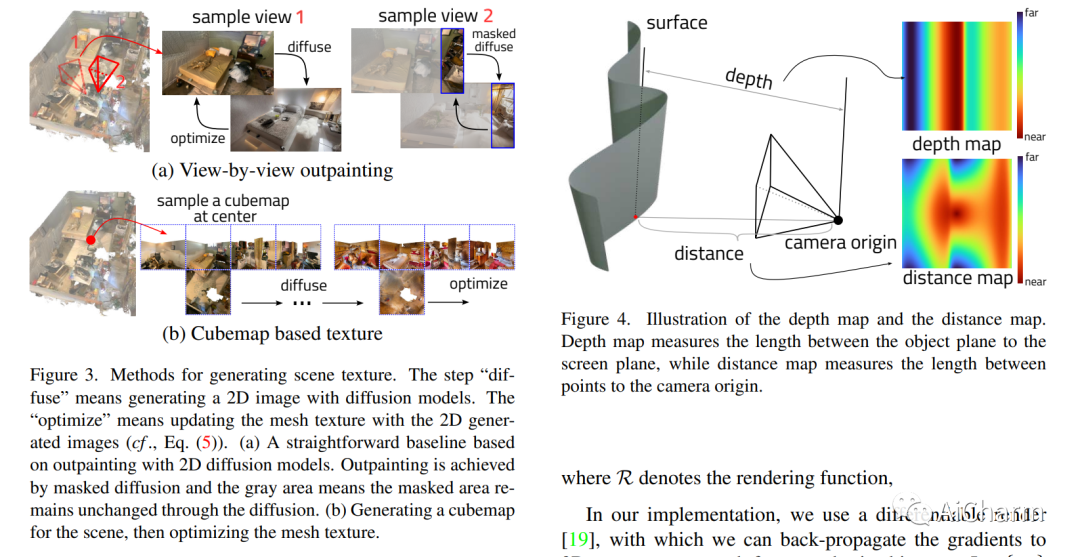

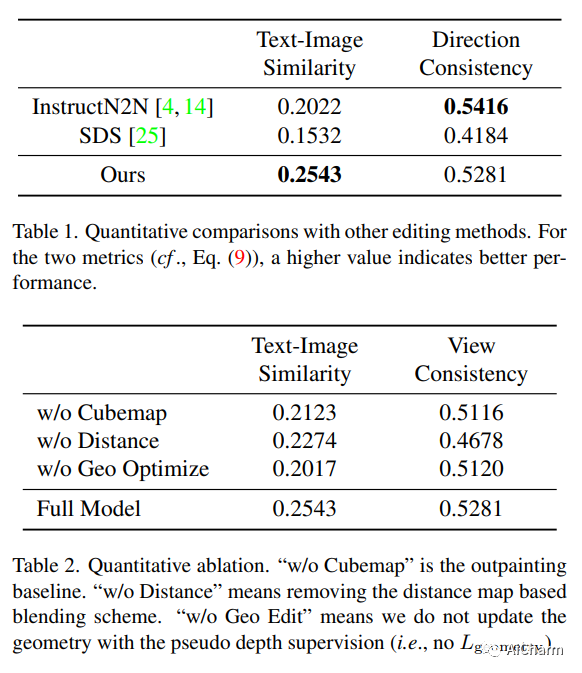
Summary:
Viewing 3D indoor scene capture techniques are widely used, but the resulting meshes leave much to be desired. In this paper, we propose "RoomDreamer", which exploits powerful natural language to synthesize a new room with different styles. Unlike existing image synthesis methods, our work addresses the challenge of simultaneously synthesizing geometry and texture aligned with input scene structure and cues. The key insight is that the scene should be considered as a whole, taking into account both scene texture and geometry. The proposed framework consists of two important components: geometry-guided diffusion and mesh optimization. Geometry Guided Diffusion for 3D Scene ensures the consistency of the scene style by applying the 2D prior to the entire scene at the same time. Together, mesh optimization improves geometry and texture, and removes artifacts in scanned scenes. To validate the proposed method, extensive experiments are conducted using real indoor scenes scanned by smartphones, through which the effectiveness of our method is demonstrated.
3.Any-to-Any Generation via Composable Diffusion

Title: Arbitrary Generation via Composable Diffusion
Authors: Zineng Tang, Ziyi Yang, Chenguang Zhu, Michael Zeng, Mohit Bansal
Article link: https://arxiv.org/abs/2305.11846
Project code: https://codi-gen.github.io/

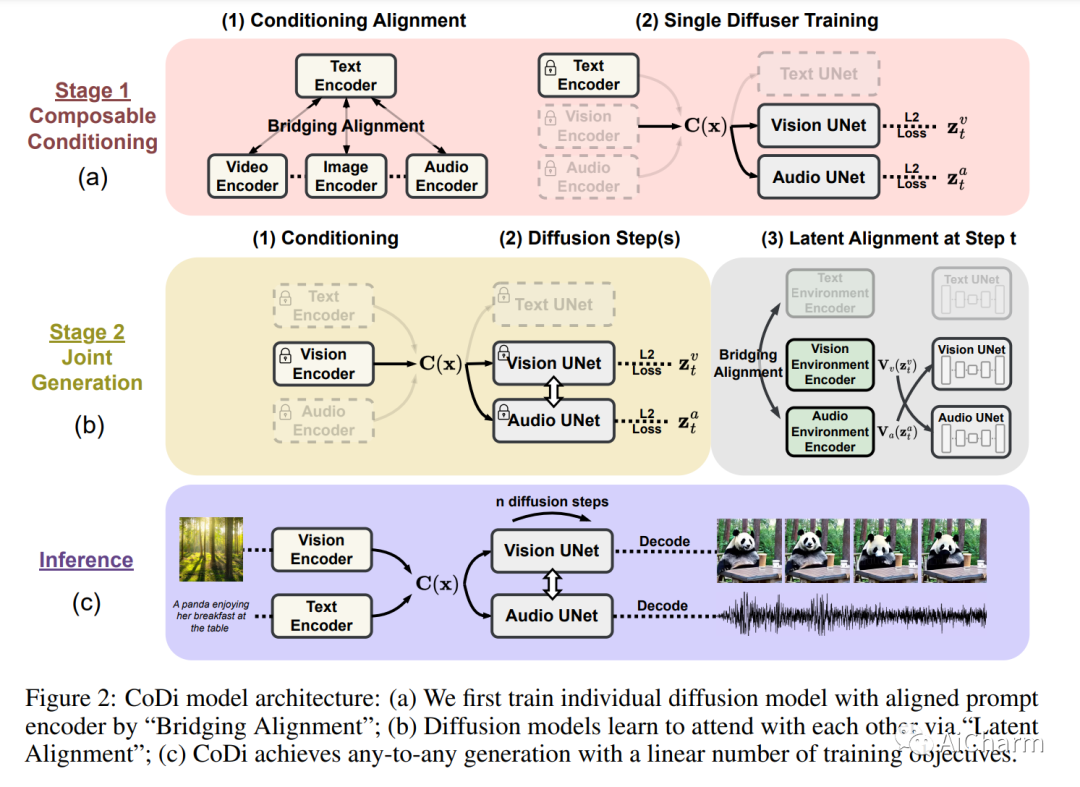



Summary:
We propose Composable Diffusion (CoDi), a novel generative model capable of generating any combination of output modalities, such as language, image, video, or audio, from any combination of input modalities. Unlike existing generative AI systems, CoDi can generate multiple modalities in parallel, and its input is not limited to a subset of modalities such as text or images. Despite the lack of training datasets for many modality combinations, we propose to align modalities in the input and output spaces. This allows CoDi to freely condition on any combination of inputs and generate any modal group, even if they are not present in the training data. CoDi employs a novel composable generation strategy that involves constructing a shared multimodal space by bridging alignments during diffusion, enabling simultaneous generation of interwoven modalities such as temporally aligned video and audio. Highly customizable and flexible CoDi achieves robust co-modal generation quality that outperforms or is comparable to single-modal state-of-the-art for single-modal synthesis. The project page with demo and code is at this https URL
More Ai information: Princess AiCharm